索引快速扫描(index fast full scan)
一、索引快速扫描(index fast full scan)
索引快速全扫描(INDEX FAST FULL SCAN)和索引全扫描(INDEX FULL SCAN)极为类似,它也适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。和索引全扫描一样,索引快速全扫描也需要扫描目标索引所有叶子块的所有索引行。
索引快速全扫描与索引全扫描相比有如下三点区别。
(1)索引快速全扫描只适用于CBO。
(2)索引快速全扫描可以使用多块读,也可以并行执行。
(3)索引快速全扫描的执行结果不一定是有序的。这是因为索引快速全扫描时Oracle是根据索引行在磁盘上的物理存储顺序来扫描,而不是根据索引行的逻辑顺序来扫描的,所以扫描结果才不一定有序(对于单个索引叶子块中的索引行而言,其物理存储顺序和逻辑存储顺序一致;但对于物理存储位置相邻的索引叶子块而言,块与块之间索引行的物理存储顺序则不一定在逻辑上有序)。
Fast full index scans are an alternative to a full table scan when the index contains all the columns that are needed for the query(组合索引中的列包含了需要查询的所有列), and at least one column in the index key has the NOT NULL constraint(至少有一个有非空约束). A fast full scan accesses the data in the index itself, without accessing the table. It cannot be used to eliminate a sort operation, because the data is not ordered by the index key. It reads the entire index using multiblock reads, unlike a full index scan, and can be parallelized.
You can specify fast full index scans with the initialization parameter OPTIMIZER_FEATURES_ENABLE or the INDEX_FFS hint. Fast full index scans cannot be performed against bitmap indexes.
A fast full scan is faster than a normal full index scan in that it can use multiblock I/O(一次可以读多个块,跟全表扫描一样) and can be parallelized just like a table scan.
二、例子
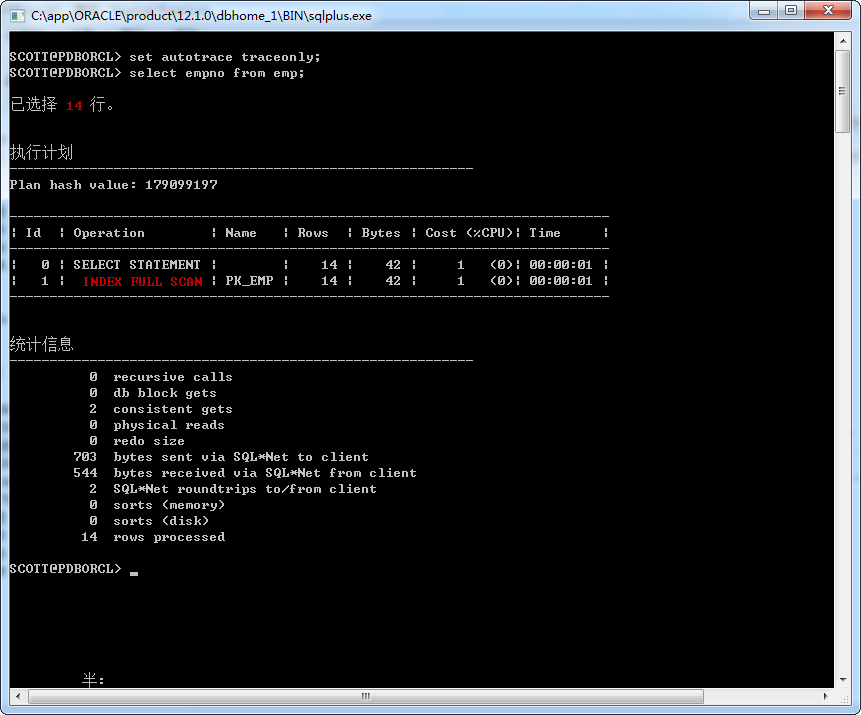
1、针对scott的emp表
select empno from emp;
继续插入数据
BEGIN
FOR I IN 0..1000 LOOP
INSERT INTO EMP(EMPNO,ENAME) VALUES(
I,CONCAT('TBL',I));
END LOOP;
END;
对表EMP及主键索引重新收集一下统计信息:
analyze table emp compute statistics for table for all columns for all indexes;
重新执行
select empno from emp;
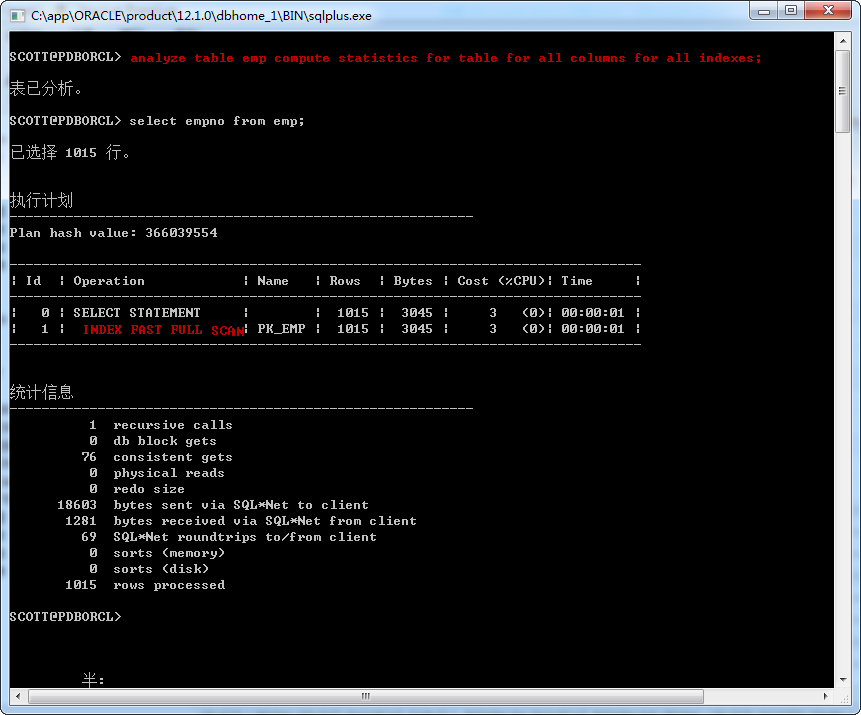
加载策略变成了Fast Full Index Scans
三、对比Index Fast Full Scans与Index Fast Full Scans
INDEX FULL SCAN 与 INDEX FAST FULL SCAN两个长相差不多,乃是一母同胞,因此既有其共性,也有其个性。两者来说其共性是不用扫描
表而是通过索引就可以直接返回所需要的所有数据。这对提高查询性能而言,无疑是一个难得的数据访问方式之一,因为索引中存储的数据通常
是远小于原始表的数据。下面具体来看看两者之间的异同。
我们对比一下 Index Fast Full Scans与Index Fast Full Scans
select /*+ index_ffs(emp pk_emp) */empno from emp;
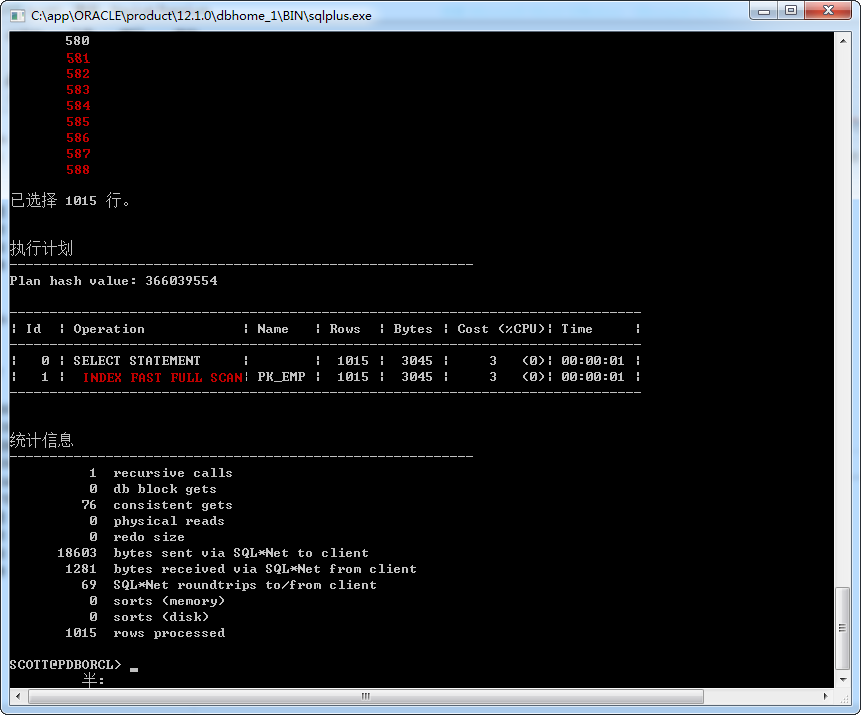
select /*+ index(emp pk_emp) */empno from emp;
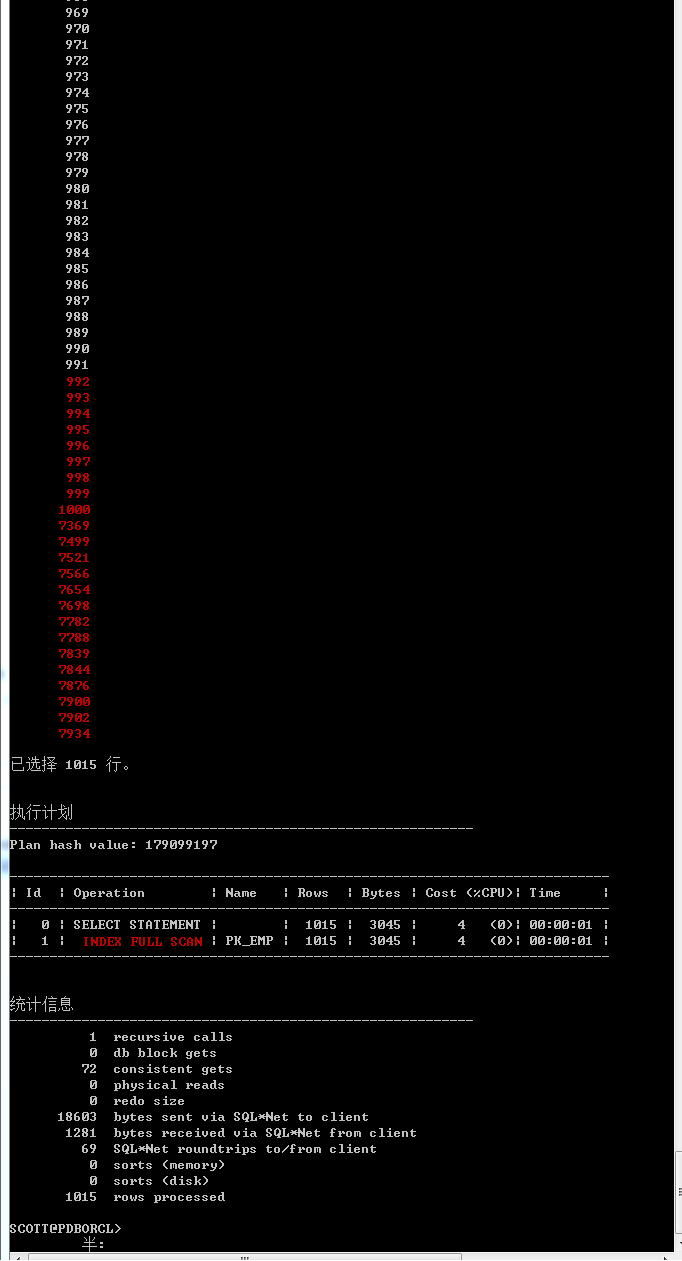
和index full scan不同,index fast full scan的执行结果并没有按照主键索引PK_EMP的索引键值前导列EMPNO来排序,即索引快速全扫描的执行结果确实不一定是有序的。
四、结论
- 当select和where中出现的列都存在索引是发生index full scan与index fast full scan的前提
- index fast full scan使用多块读的方式读取索引块,产生db file scattered reads 事件,读取时高效,但为无序读取
- index full scan使用单块读方式有序读取索引块,产生db file sequential reads事件,当采用该方式读取大量索引全扫描,效率低下
参考
INDEX FULL SCAN vs INDEX FAST FULL SCAN
索引快速扫描(index fast full scan)的更多相关文章
- 为什么不走INDEX FAST FULL SCAN呢
INDEX FULL SCAN 索引全扫描.单块读 .它扫描的结果是有序的,因为索引是有序的.它通常发生在 下面几种情况(注意:即使SQL满足以下情况 不一定会走索引全扫描) 1. SQL语句有ord ...
- INDEX FAST FULL SCAN和INDEX FULL SCAN
INDEX FULL SCAN 索引全扫描.单块读 .它扫描的结果是有序的,因为索引是有序的.它通常发生在 下面几种情况(注意:即使SQL满足以下情况 不一定会走索引全扫描) 1. SQL语句有ord ...
- index range scan,index fast full scan,index skip scan发生的条件
源链接:https://blog.csdn.net/robinson1988/article/details/4980611 index range scan(索引范围扫描): 1.对于unique ...
- index full scan和index fast full scan区别
触发条件:只需要从索引中就可以取出所需要的结果集,此时就会走索引全扫描 Full Index Scan 按照数据的逻辑顺序读取数据块,会发生单块读事件, Fast Full Index Scan ...
- Oracle 11G INDEX FULL SCAN 和 INDEX FAST FULL SCAN 对比分析
SQL> drop table test; 表已删除. SQL> create table test as select * from dba_objects where 1!=1; 表已 ...
- index full scan/index fast full scan/index range scan
**************************1************************************* 索引状态: valid. N/A . ...
- 索引唯一性扫描(INDEX UNIQUE SCAN)
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)的扫描,它仅仅适用于where条件里是等值查询的目标SQL.因为扫描的对象是唯一性索引,所 ...
- 索引范围扫描(INDEX RANGE SCAN)
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B树索引,当扫描的对象是唯一性索引时,此时目标SQL的where条件一定是范围查询(谓词条件为 BETWEEN.<.>等): ...
- oracle中索引快速全扫描和索引全扫描的区别
当进行index full scan的时候 oracle定位到索引的root block,然后到branch block(如果有的话),再定位到第一个leaf block, 然后根据leaf bloc ...
随机推荐
- ExpandoObject对象的JSON序列化
如果: dynamic expando = new ExpandoObject(); d.SomeProp=SomeValueOrClass; 然后,我们在控制器中: return new JsonR ...
- 生成模型(Generative Model)和 判别模型(Discriminative Model)
引入 监督学习的任务就是学习一个模型(或者得到一个目标函数),应用这一模型,对给定的输入预测相应的输出.这一模型的一般形式为一个决策函数Y=f(X),或者条件概率分布P(Y|X). 监督学习方法又可以 ...
- [转]Linux的SOCKET编程详解
From : http://blog.csdn.net/hguisu/article/details/7445768 1. 网络中进程之间如何通信 进 程通信的概念最初来源于单机系统.由于每个进程都在 ...
- Spring Data JPA 实现多表关联查询
本文地址:https://liuyanzhao.com/6978.html 最近抽出时间来做博客,数据库操作使用的是 JPA,相对比 Mybatis 而言,JPA 单表操作非常方便,增删改查都已经写好 ...
- Linear Regression总结
转自:http://blog.csdn.net/dongtingzhizi/article/details/16884215 Linear Regression总结 作者:洞庭之子 微博:洞庭之子-B ...
- MySql查询时间段的方法(转)
http://www.jb51.net/article/58668.htm 本文实例讲述了MySql查询时间段的方法.分享给大家供大家参考.具体方法如下: MySql查询时间段的方法未必人人都会,下面 ...
- docker service ps打印出来的错误信息被截断了怎么办?
[解决方法] 用Format属性: 这个其实解决不了截断的问题,不过可以显示更少的列,看起来更清楚. Formatting The formatting options (--format) pr ...
- jquery easyui tree异步加载子节点
easyui中的树可以从标记中建立,也可以通过指定一个URL属性读取数据建立.如果想建立一棵异步树,需要为每个节点指定一个id属性值,这样在加载数据时会自动向后台传递id参数. <ul id=& ...
- 编译安装openssl报错:POD document had syntax errors at /usr/bin/pod2man line 69. make: *** [install_docs]
错误如下: cms.pod around line 457: Expected text after =item, not a number cms.pod around line 461: Expe ...
- 解决IE兼容模式的方案
在html头 加标签 强制使用最新的ie渲染 <meta http-equiv="X-UA-Compatible" content="IE=edge"&g ...