01_Flume基本架构及原理
Flume消息收集系统,在整个系统架构中的位置
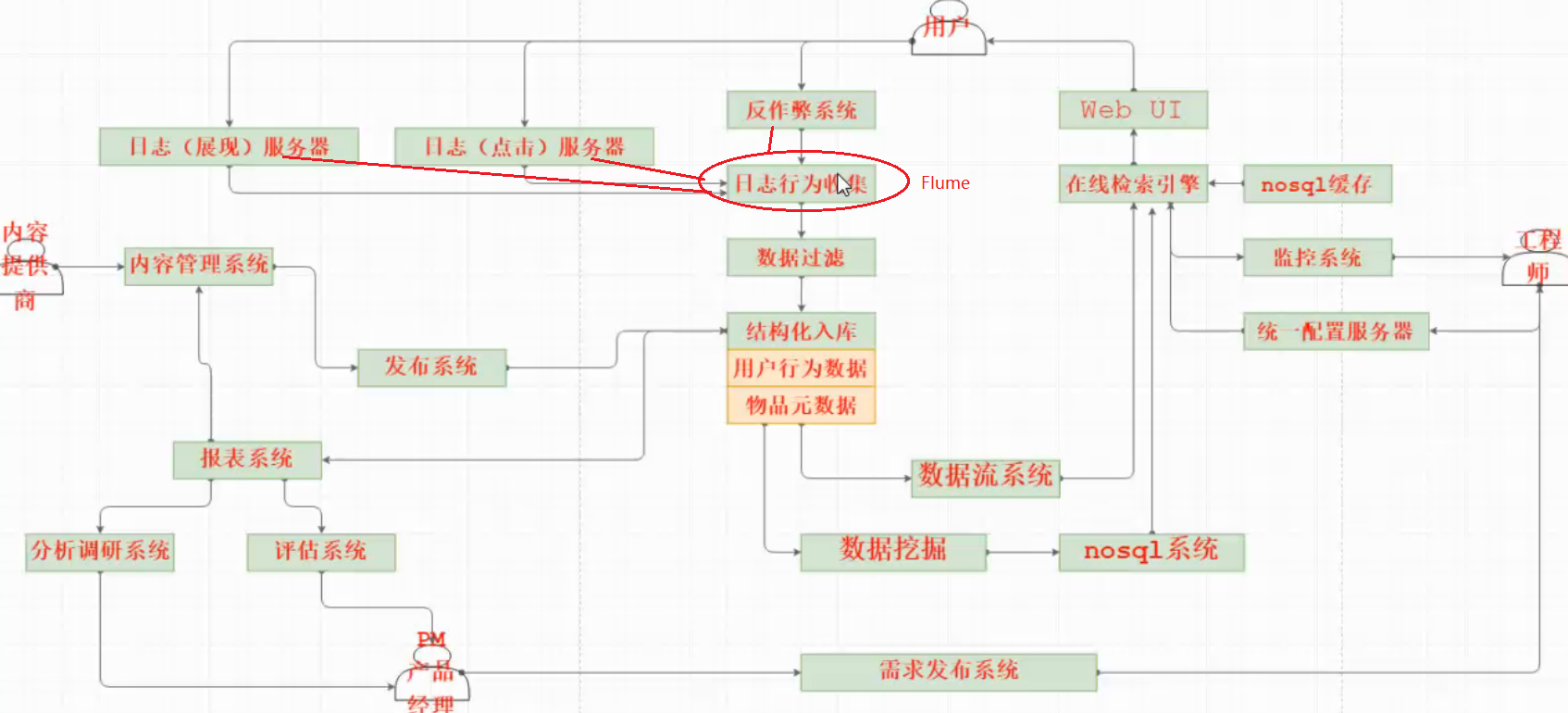
Flume概况
1) Apache软件基金会的顶级项目
2)存在两个大的版本:Flume 0.9.x(Flume-OG,original generation), Flume 1.x(Flume-NG,next generation)
3) 信息采集系统(分布式,支持水平扩展,事务机制保证消息event可靠传输,可定制的信息输入和信息输出,基于Java运行)
事务机制:下游agent将信息成功缓存后,上游agent才认为该信息传输成功
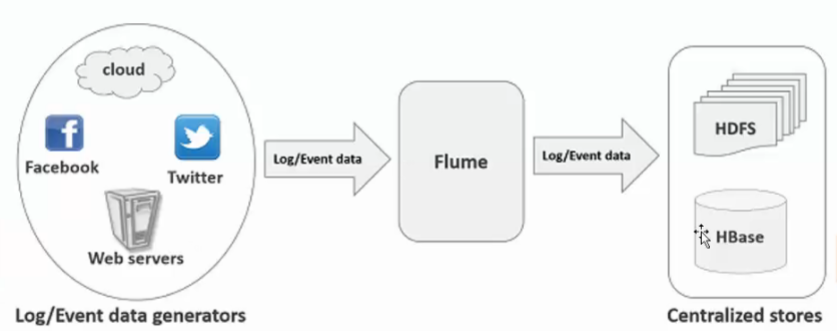
4)主要目的:deliver data from application to Apache Hadoop's ecosystem(HDFS,HBASE,HIVE,LocalFileSystem)
多管道接入(fan in),多管道输出(fan out),上下文路由(将event根据需求发送给不同的接收方)
5)运行环境:基于java编写,运行在unix-like系统(Ubuntu,CentOS, RHEL,SLES,Mac OS X)
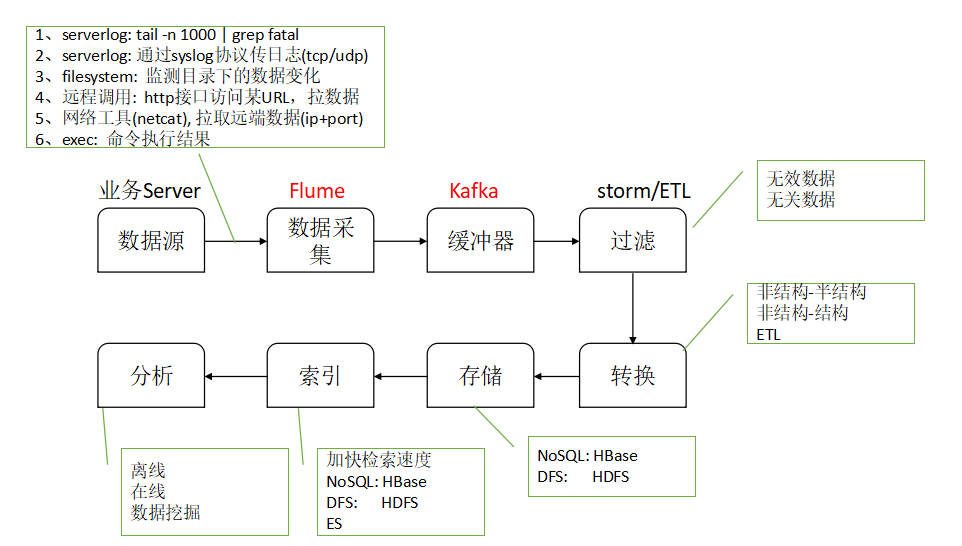
数据从产生到进入分析阶段的整个流程
Flume的输入数据和输出数据

Flume架构
打开Flume来看

一般来说,Agent和Collector分离部署:
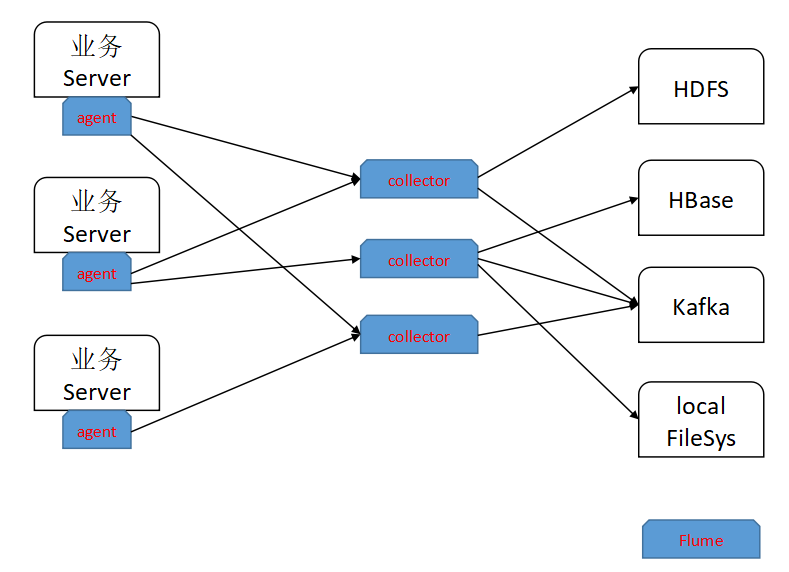
1)业务Server,只部署Agent, 尽量少的入侵业务系统
2)Collector可能会有多个,负责event汇聚的分发
3)Agent layer, Collector Layer, Storage Layer
打开Agent或者collector来看
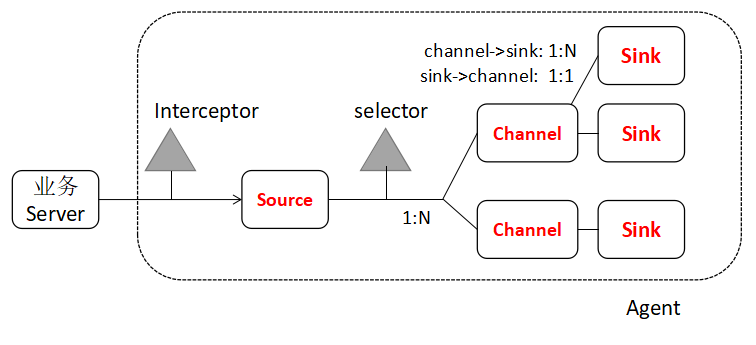
Agent或者Collector由3个必要组件,2个可选组件构成,Event是组件间的数据传递单位
1个Agent或者Collector,就是1个JVM进程
必要组件
1)Source:对接各种输入数据源(数据源直接发送event,或者Source将数据转换为event,Event由可选的Header和Byte净荷构成)

2) Channel:缓存event,直到event被Sink成功发送
最常用的是 memory(内存队列)和 file(本地文件),其他类型的channel还包括jdbc channel,kafka channel等
memory channel最大的问题是可能存在event丢失的风险,file可以持久化存储event但肯定就没有内存队列快
3) Sink: 将event送给下游Agent,或者将event送给下游存储
Agent间的级联,上游Sink必须为avro sink, 下游Source必须为avro source
可选组件
interceptor:干预器,主要用于向Event Header中注入一些附加信息(时间戳,主机信息,自定义信息,由于上下文路由)或者信息过滤(匹配正则的Event放行,匹配正则的Event丢弃)
1) timestamp interceptor: 在event的header中添加时间戳(处理该event的即时时间)
2) host interceptor: 在event的header中添加当前agent运行的主机的hostname或者IP地址
3) static interceptor: 在event的header中添加配置文件中指定的key,value
4) Regex Filtering: 将event的body中的内容和指定的正则表达式匹配,将匹配的event丢弃
5) Regex Extractor: 将event的body中的内容和指定的正则表达式匹配,将匹配的event放行,并添加header(指定的key, value为匹配的内容)
总结:interceptor可以级联,配置文件中通过空格分隔,前一个interceptor处理后的event,是后一个interceptor的输入event
selector: 选择器,主要用于选择Event将发往哪一个Channel(路由)
selector将event发送给channel有两种方式:复制Replicating(全部都发,默认方式), 复用Multiplexing(根据一定规则分发);
复用分发原理:selector根据event header中指定key的值来决定该event应该发给哪一个channel
Flume可靠性信息传递的原理(上下游协同,事务处理)
简单来说:下游agent将event成功缓存到channel后,上游agent才认为该event传输成功, 然后上游将该event从channel中删除
Flume的级联
1)多Agent级联

2) 多个Agent聚合级联
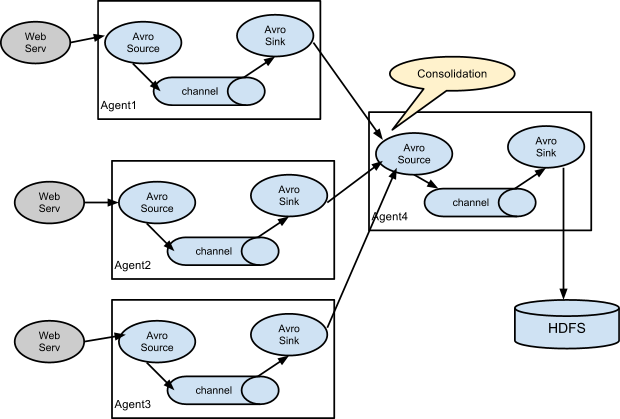
3) 复用分流

01_Flume基本架构及原理的更多相关文章
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- SQL Server AlwaysOn架构及原理
SQL Server AlwaysOn架构及原理 SQL Server2012所支持的AlwaysOn技术集中了故障转移群集.数据库镜像和日志传送三者的优点,但又不相同.故障转移群集的单位是SQL实例 ...
- 爱莲(iLinkIT)的架构与原理
随着移动互联网时代的到来,手机正在逐步替代其他的设备,手机是电话.手机是即时通讯,手机是相机,手机是导航仪,手机是钱包,手机是音乐播放器……. 除此之外,手机还是一个大大的U盘,曾几何时,我们用一根长 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- Oracle rac架构和原理
Oracle RAC Oracle Real Application Cluster (RAC,实时应用集群)用来在集群环境下实现多机共享数据库,以保证应用的高可用性:同时可以自动实现并行处理 ...
- storm架构及原理
storm 架构与原理 1 storm简介 1.1 storm是什么 如果只用一句话来描述 storm 是什么的话:分布式 && 实时 计算系统.按照作者 Nathan Marz 的说 ...
随机推荐
- Sqoop导入HBase,并借助Coprocessor协处理器同步索引到ES
1.环境 Mysql 5.6 Sqoop 1.4.6 Hadoop 2.5.2 HBase 0.98 Elasticsearch 2.3.5 2.安装(略过) 3.HBase Coprocessor实 ...
- [py]字符串/列表
去除str首尾空格(切片) ## str长度 循环,判断 ### [:i] [i:] 记录位置点 ## 方法1 def trim2(s): s2 = "" start = 0 en ...
- PAT 1074 Reversing Linked List[链表][一般]
1074 Reversing Linked List (25)(25 分) Given a constant K and a singly linked list L, you are suppose ...
- Oracle多关键字模糊查询
以前写SQL时,知道MySQL多字段模糊查询可以使用[charlist] 通配符,如: SELECT * FROM Persons WHERE City LIKE '[ALN]%'但是在Oracle中 ...
- 如何给Pycharm加上头行 # *_*coding:utf-8 *_*?
File>Setting>Editor>Code Style>File and Code Templates>Python Script 后面加上 # *_*codin ...
- C# winform webbrowser如何指定内核为IE11? 输出 this.webbrowser.Version 显示版本是IE11的,但实际版本不是啊! 网上打的修改注册表HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Internet Explorer\MAIN\FeatureControl\FEATURE_BROWSER_EMULA
最佳答案 1)假设你应用程序的名字为MyApplication.exe 2)运行Regedit,打开注册表,找到 HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\M ...
- itertools模块(收藏)
Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数. count().cycle().repeat() 首先,我们看看itertools提供的几个“无限”迭代器: > ...
- Leetcode: Repeated DNA Sequence
All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: "ACG ...
- 使用点击二分图传导计算query-document的相关性
之前的博客中已经介绍了Ranking Relevance的一些基本情况(Click Behavior,和Text Match):http://www.cnblogs.com/bentuwuying/p ...
- 【kafka学习之四】kafka集群性能测试
kafka集群的性能受限于JVM参数.服务器的硬件配置以及kafka的配置,因此需要对所要部署kafka的机器进行性能测试,根据测试结果,找出符合业务需求的最佳配置. 1.kafka broker j ...