train_test_split, 关于随机抽样和分层抽样
https://zhuanlan.zhihu.com/p/49991313
在将样本数据分成训练集和测试集的时候,应当谨慎地考虑一下是采用纯随机抽样,还是分层抽样。
通常,数据集如果足够大,纯随机抽样的方式,将样本数据分成两个子集是没有太大的问题。
如果不是,纯随机抽样肯可能会导致抽样数据偏差,影响训练效果,降低预测模型预测的准确性。
设想调查公司需要做1000份抽样调查,调查的问题和性别可能有较大的相关性。如果想让调查结果代表全国男性和女性对这些问题的看法,假设全国人口男女比例大致为60:40,那么在1000份问卷也应当尽量保持男女比例达到同样的比例,即参加问卷调查的男女数差不多是600和400。
这个就是分层抽样。
如果参加问卷的男女数比例很不一样,比如女性占到了60%或更多,那么调查结伦就会出现重大偏差。
使用sklearn.model_selection.train_test_split,参数stratify即用来指定按照某一特征进行分层抽样,生成训练集和测试集。
看一下随机抽样和分层抽样时,按照某一特征的取值,在训练集的占比情况。
income_count = housing['income_cat'].value_counts().sort_index()
print('\nAfter categorized:\n{}'.format(income_count))
income_count.plot.bar()
plt.show()
print('Overall dataset, distribution of each category: (%)')
print(income_count/len(housing)*100)
# random split
train_set, test_set = train_test_split(housing, random_state=42)
train_set_income_count = train_set['income_cat'].value_counts().sort_index()
print('\nRandom split train dataset, distribution: (%)')
print(train_set_income_count/len(train_set)*100)
# stratify split
train_set, test_set = train_test_split(housing,
stratify=housing['income_cat'], random_state=42)
train_set_income_count = train_set['income_cat'].value_counts().sort_index()
print('\nStartify split train dataset, distribution: (%)')
print(train_set_income_count/len(train_set)*100)
得到结果如下:
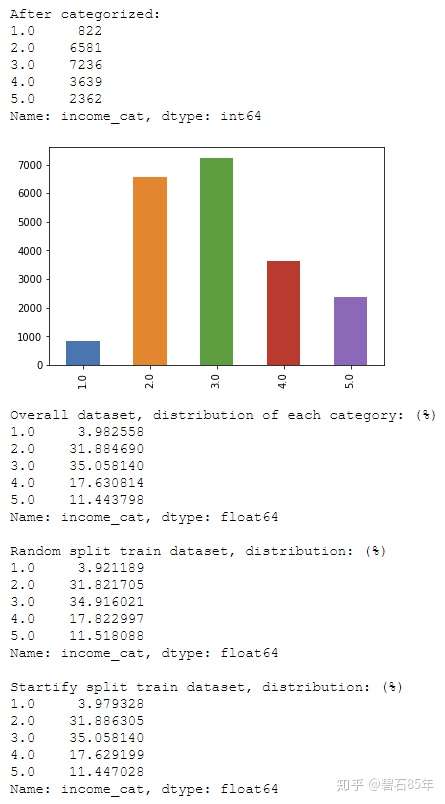
可以看到分层抽样所分出来的训练集(和测试集)数据在关键特征上具有和总体数据集上基本一致的分布。
因此采用分层抽样来生成训练集和测试集将会更严谨。
train_test_split, 关于随机抽样和分层抽样的更多相关文章
- (数据科学学习手札27)sklearn数据集分割方法汇总
一.简介 在现实的机器学习任务中,我们往往是利用搜集到的尽可能多的样本集来输入算法进行训练,以尽可能高的精度为目标,但这里便出现一个问题,一是很多情况下我们不能说搜集到的样本集就能代表真实的全体,其分 ...
- 【机器学习算法-python实现】採样算法的简单实现
1.背景 採样算法是机器学习中比較经常使用,也比較easy实现的(出去分层採样).经常使用的採样算法有下面几种(来自百度知道): 一.单纯随机抽样(simple random samp ...
- SAS随机抽样以及程序初始环境
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本来转载于SAS随机抽样 在统计研究中,针对容 ...
- 随机抽样一致性算法(RANSAC)示例及源代码
作者:王先荣 大约在两年前翻译了<随机抽样一致性算法RANSAC>,在文章的最后承诺写该算法的C#示例程序.可惜光阴似箭,转眼许久才写出来,实在抱歉.本文将使用随机抽样一致性算法来来检测直 ...
- 随机抽样一致性算法(RANSAC)
本文翻译自维基百科,英文原文地址是:http://en.wikipedia.org/wiki/ransac,如果您英语不错,建议您直接查看原文. RANSAC是"RANdom SAmple ...
- sklearn.model_selection 的 train_test_split作用
train_test_split函数用于将数据划分为训练数据和测试数据. train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train_data和test_data ...
- train_test_split数据切分
train_test_split 数据切分 格式: X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_d ...
- sklearn 的train_test_split
train_test_split函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签. 格式: from sklearn.model_selection imp ...
- 训练集测试集划分 train_test_split(X, y, stratify=y)
from sklearn.model_selecting import train_test_spilt() 参数stratify: 依据标签y,按原数据y中各类比例,分配给train和test,使得 ...
随机推荐
- scala中to和util操作
// Range:to:默认步进为1 val to1 = 1 to 10 println(to1) // 定义一个不进为2的Range val to2 = 1 to 10 by 2 println(t ...
- D盾 v2.0.6.42 测试记录
0x01 前言 之前发了一篇博客<Bypass D盾_IIS防火墙SQL注入防御(多姿势)>,D哥第一时间联系我,对问题进行修复.这段时间与D哥聊了挺多关于D盾这款产品的话题,实在是很佩服 ...
- 使用一条sql查询多个表中的记录数
方法一: select t1.num1,t2.num2,t3.num3 from (select count(*) num1 from table1) t1, (select count(*) num ...
- solr java demo 基础入门
<!--solr的maven依赖--> <dependencies> <dependency> <groupId>org.apache.solr&l ...
- MVC的简单初步学习(2)
今天似乎一切是正常的,我们的课依旧在进行着,但是恍惚脑海中并没有那样的平静,不知道在想些什么?而且今天是学习MVC的初步开始,我应该认真地学习才是正确的啊.但是我并不糊涂,今天是周一,也就是刚开始上课 ...
- 使用css制作倒影
-webkit-mask 这个属性是相当强大的,所以详细的介绍超出了本文的范畴,它非常值得深入研究,因为它可以在实际应用中为你省掉很多时间. -webkit-mask让为一个元素添加蒙板成为可能,从而 ...
- 在MyEclipse(2015)中上传项目到github的步骤(很详细)
(图文)在MyEclipse(2015)中上传项目到github的步骤(很详细) git|smartGit使用详解 SmartGit使用教程
- C#设计模式--装饰器模式
0.C#设计模式-简单工厂模式 1.C#设计模式--工厂方法模式 2.C#设计模式--抽象工厂模式 3.C#设计模式--单例模式 4.C#设计模式--建造者模式 5.C#设计模式--原型模式 6.C# ...
- DRM in Android详解--转
DRM,英文全称为Digital Rights Management,译为数字版权管理.它是目前业界使用非常广泛的一种数字内容版权保护技术.随着知识产权保护受重视的程度日益提高,快速攻城略地得Andr ...
- sencha touch 在线实战培训 第一期 第一节
经过忙碌的准备,终于在2013.12.28晚上8点开了第一节课. 第一次讲课有些小紧张,讲的内容也比较基础,不过算是开了一个好头. 本期培训一共八节,前三堂免费,后面的课程需要付费才可以观看. 本节内 ...