解密OpenTSDB的表存储优化【转】
https://yq.aliyun.com/articles/54785
摘要: 本篇文章会详细讲解OpenTSDB的表结构设计,在理解它的表结构设计的同时,分析其采取该设计的深层次原因以及优缺点。它的表结构设计完全贴合HBase的存储模型,而表格存储(TableStore、原OTS)与HBase有类似的存储模型,理解透OpenTSDB的表结构设计后,我们也能够对这类数据库的存储
摘要
OpenTSDB是一个分布式的、可伸缩的时间序列数据库,在DB-engines的时间序列数据库排行榜上排名第五。它的特点是能够提供最高毫秒级精度的时间序列数据存储,能够长久保存原始数据并且不失精度。它拥有很强的数据写入能力,支持大并发的数据写入,并且拥有可无限水平扩展的存储容量。
它的强大的数据写入能力与存储能力得益于它底层依赖的HBase数据库,也得益于它在表结构设计上做的大量的存储优化。
本篇文章会详细讲解其表结构设计,在理解它的表结构设计的同时,分析其采取该设计的深层次原因以及优缺点。它的表结构设计完全贴合HBase的存储模型,而表格存储(TableStore、原OTS)与HBase有类似的存储模型,理解透OpenTSDB的表结构设计后,我们也能够对这类数据库的存储模型有一个更深的理解。
存储模型
在解析OpenTSDB的表结构设计前,我们需要先对其底层的HBase的存储模型有一个理解。
表分区
HBase会按Rowkey的范围,将一张大表切成多个region,每个region会由一个region server加载并提供服务。Rowkey的切分与表格存储的分区类似,一个良好设计的表,需要保证读写压力能够均匀的分散到表的各个region,这样才能充分发挥分布式集群的能力。
存储结构
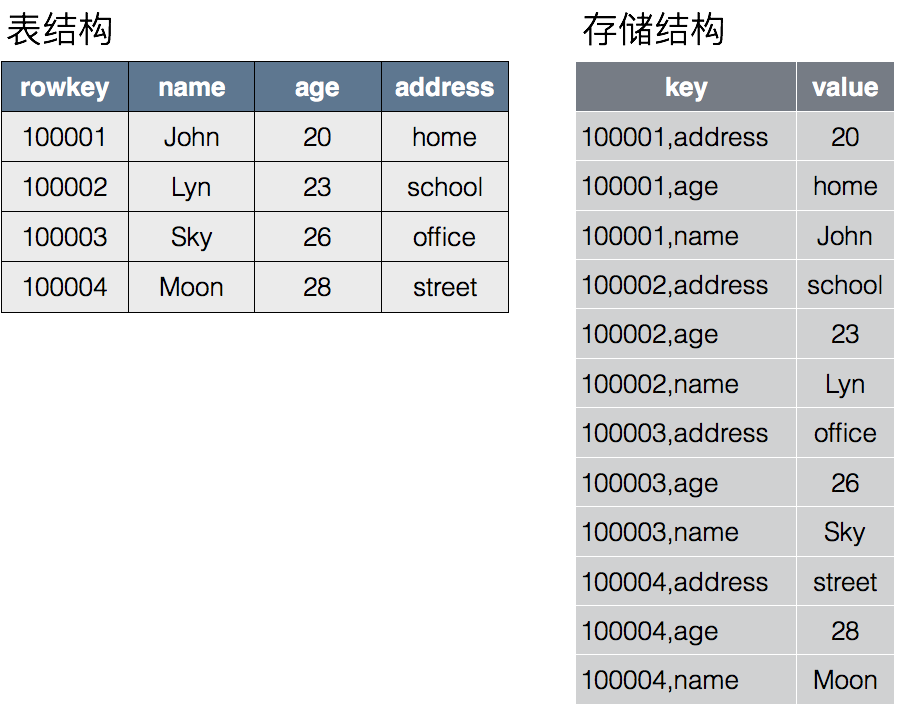
OpenTSDB的基本概念
OpenTSDB定义每个时间序列数据需要包含以下属性:
1. 指标名称(metric name)
2. 时间戳(UNIX timestamp,毫秒或者秒精度)
3. 值(64位整数或者单精度浮点数)
4. 一组标签(tags,用于描述数据属性,至少包含一个或多个标签,每个标签由tagKey和tagValue组成,tagKey和tagValue均为字符串)
举个例子,在监控场景中,我们可以这样定义一个监控指标:
指标名称:
sys.cpu.user
标签:
host = 10.101.168.111
cpu = 0
指标值:
0.5指标名称代表这个监控指标是对用户态CPU的使用监控,引入了两个标签,分别标识该监控位于哪台机器的哪个核。
OpenTSDB支持的查询场景为:指定指标名称和时间范围,给定一个或多个标签名称和标签的值作为条件,查询出所有的数据。
以上面那个例子举例,我们可以查询:
a. sys.cpu.user (host=*,cpu=*)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,所有机器的所有CPU核上的用户态CPU消耗。
b. sys.cpu.user (host=10.101.168.111,cpu=*)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,某台机器的所有CPU核上的用户态CPU消耗。
c. sys.cpu.user (host=10.101.168.111,cpu=0)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,某台机器的第0个CPU核上的用户态CPU消耗。
OpenTSDB的存储优化
了解了OpenTSDB的基本概念后,我们来尝试设计一下表结构。
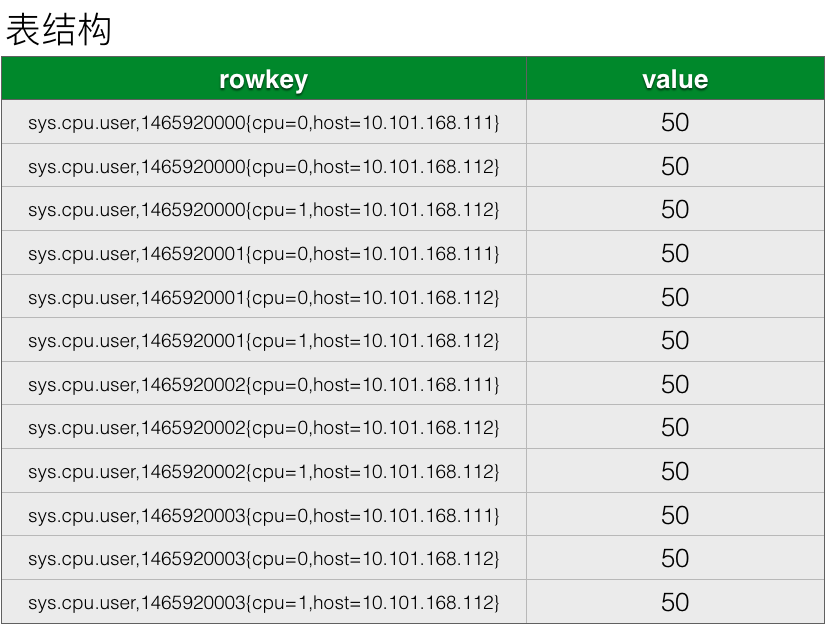
如上图是一个简单的表结构设计,rowkey采用metric name + timestamp + tags的组合,因为这几个元素才能唯一确定一个指标值。
这张表已经能满足我们的写入和查询的业务需求,但是OpenTSDB采用的表结构设计远没有这么简单,我们接下来一项一项看它对表结构做的一些优化。
优化一:缩短row key
观察这张表内存储的数据,在rowkey的组成部分内,其实有很大一部分的重复数据,重复的指标名称,重复的标签。以上图为例,如果每秒采集一次监控指标,cpu为2核,host规模为100台,则一天时间内sys.cpu.user这个监控指标就会产生17280000行数据,而这些行中,监控指标名称均是重复的。如果能将这部分重复数据的长度尽可能的缩短,则能带来非常大的存储空间的节省。
OpenTSDB采用的策略是,为每个metric、tag key和tag value都分配一个UID,UID为固定长度三个字节。
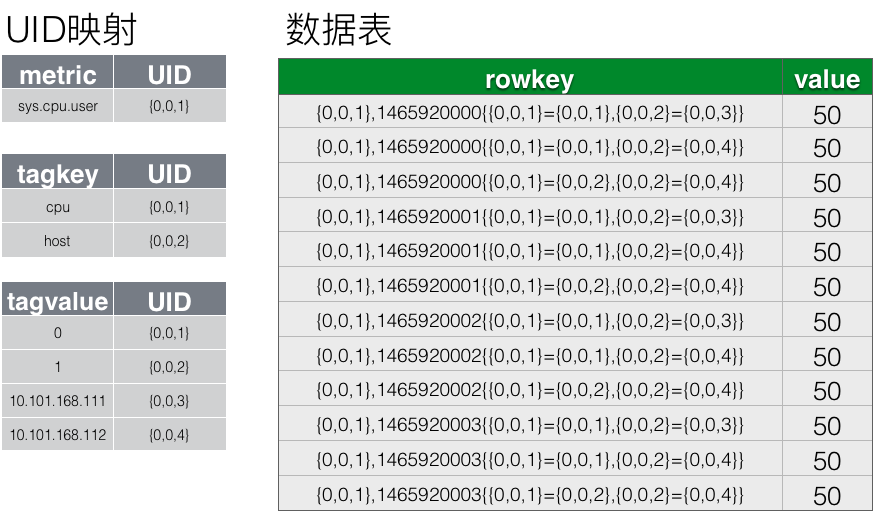
上图为优化后的存储结构,可以看出,rowkey的长度大大的缩短了。rowkey的缩短,带来了很多好处:
a. 节省存储空间
b. 提高查询效率:减少key匹配查找的时间
c. 提高传输效率:不光节省了从文件系统读取的带宽,也节省了数据返回占用的带宽,提高了数据写入和读取的速度。
d. 缓解Java程序内存压力:Java程序,GC是老大难的问题,能节省内存的地方尽量节省。原先用String存储的metric name、tag key或tag value,现在均可以用3个字节的byte array替换,大大节省了内存占用。
优化二:减少Key-Value数
优化一是OpenTSDB做的最核心的一个优化,很直观的可以看到存储的数据量被大大的节省了。原理也很简单,将长的变短。但是是否还可以进一步优化呢?
在上面的存储模型章节中,我们了解到。HBase在底层存储结构中,每一列都会以Key-Value的形式存储,每一列都会包含一个rowkey。如果要进一步缩短存储量,那就得想办法减少Key-Value的个数。
OpenTSDB分了几个步骤来减少Key-Value的个数:
1. 将多行合并为一行,多行单列变为单行多列。
2. 将多列合并为一列,单行多列变为单行单列。
多行单列合并为单行单列
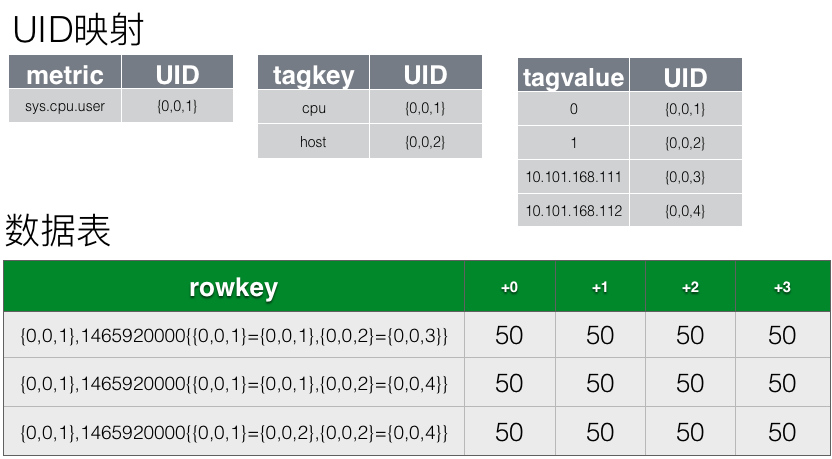
OpenTSDB将同属于一个时间周期内的具有相同TSUID(相同的metric name,以及相同的tags)的数据合并为一行存储。OpenTSDB内默认的时间周期是一个小时,也就是说同属于这一个小时的所有数据点,会合并到一行内存储,如图上所示。合并为一行后,该行的rowkey中的timestamp会指定为该小时的起始时间(所属时间周期的base时间),而每一列的列名,则记录真实数据点的时间戳与该时间周期起始时间(base)的差值。
这里列名采用差值而不是真实值也是一个有特殊考虑的设计,如存储模型章节所述,列名也是会存在于每个Key-Value中,占用一定的存储空间。如果是秒精度的时间戳,需要4个字节,如果是毫秒精度的时间戳,则需要8个字节。但是如果列名只存差值且时间周期为一个小时的话,则如果是秒精度,则差值取值范围是0-3600,只需要2个字节;如果是毫秒精度,则差值取值范围是0-360000,只需要4个字节;所以相比存真实时间戳,这个设计是能节省不少空间的。
单行多列合并为单行单列
多行合并为单行后,并不能真实的减少Key-Value个数,因为总的列数并没有减少。所以要达到真实的节省存储的目的,还需要将一行的列变少,才能真正的将Key-Value数变少。
OpenTSDB采取的做法是,会在后台定期的将一行的多列合并为一列,称之为『compaction』,合并完之后效果如下。

同一行中的所有列被合并为一列,如果是秒精度的数据,则一行中的3600列会合并为1列,Key-Value数从3600个降低到只有1个。
优化三:并发写优化
上面两个优化主要是OpenTSDB对存储的优化,存储量下降以及Key-Value个数下降后,除了直观的存储量上的缩减,对读和写的效率都是有一定提升的。
时间序列数据的写入,有一个不可规避的问题是写热点问题,当某一个metric下数据点很多时,则该metric很容易造成写入热点。OpenTSDB采取了和这篇文章中介绍的一样的方法,允许将metric预分桶,可通过『tsd.storage.salt.buckets』配置项来配置。

总结
解密OpenTSDB的表存储优化【转】的更多相关文章
- 追踪app崩溃率、事件响应链、Run Loop、线程和进程、数据表的优化、动画库、Restful架构、SDWebImage的原理
1.如何追踪app崩溃率,如何解决线上闪退 当 iOS设备上的App应用闪退时,操作系统会生成一个crash日志,保存在设备上.crash日志上有很多有用的信息,比如每个正在执行线程的完整堆栈 跟踪信 ...
- 海量路由表能够使用HASH表存储吗-HASH查找和TRIE树查找
千万别! 非常多人这样说,也包括我. Linux内核早就把HASH路由表去掉了.如今就仅仅剩下TRIE了,只是我还是希望就这两种数据结构展开一些形而上的讨论. 1.hash和trie/radix ha ...
- MySQL优化之表结构优化的5大建议(数据类型选择讲的很好)
殊不知,在N年前被奉为"圣经"的数据库设计3范式早就已经不完全适用了.这里我整理了一些比较常见的数据库表结构设计方面的优化技巧,希望对大家有用. 由于MySQL数据库是基于行(Ro ...
- MySQL优化三 表结构优化
由于MySQL数据库是基于行(Row)存储的数据库,而数据库操作 IO 的时候是以 page(block)的方式,也就是说,如果我们每条记录所占用的空间量减小,就会使每个page中可存放的数据行数增大 ...
- hbase存储优化
1.上面的2张图主要说明hbase的存储特点 (1).每个值(每条记录的每一个列的值)的存储,都完整的存储了rowkey.column family.column.版本(时间戳),以及该列的值. 这样 ...
- MySQL性能优化方法二:表结构优化
原文链接:http://isky000.com/database/mysql-perfornamce-tuning-schema 很多人都将 数据库设计范式 作为数据库表结构设计“圣经”,认为只要按照 ...
- MySQL慢查询优化、索引优化、以及表等优化总结
MySQL优化概述 MySQL数据库常见的两个瓶颈是:CPU和I/O的瓶颈. CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据时候. 磁盘I/O瓶颈发生在装入数据远大于内存容量的时候,如果应 ...
- INNODB与MyISAM两种表存储引擎区别
mysql数据库分类为INNODB为MyISAM两种表存储引擎了,两种各有优化在不同类型网站可能选择不同,下面小编为各位介绍mysql更改表引擎INNODB为MyISAM技巧. 常见的mysql表引擎 ...
- MySQL优化之表结构优化的5大建议
很多人都将 数据库设计范式 作为数据库表结构设计“圣经”,认为只要按照这个范式需求设计,就能让设计出来的表结构足够优化,既能保证性能优异同时还能满足扩展性要求殊不知,在N年前被奉为“圣经”的数据库设计 ...
随机推荐
- sqlserver的convert函数
定义和用法 CONVERT() 函数是把日期转换为新数据类型的通用函数. CONVERT() 函数可以用不同的格式显示日期/时间数据. 语法 CONVERT(data_type(length),dat ...
- SqlServer整库备份还原脚本
最近领导要求定时备份数据库(不是我的作业), 搜了一下资料还不少, 先mark一下, 得空再验证吧!!! 以下内容为转载 转自:https://www.cnblogs.com/want990/p/74 ...
- java struts2入门学习---中文验证、对错误消息的分离、结果(result)类型细节配置
一.需求 利用struts2实现中文验证并对错误消息的抽离. 详细需求:用户登录-->不填写用户名-->页面跳转到用户登录页面,提示用户名必填(以英文和中文两种方式提示)-->填写英 ...
- 基于 CADisplayLink 的 FPS 指示器详解
前言 之前在开发中有使用到计时器NSTimer,后来了解到iOS中不同的计时方法,其中就包括了CADisplayLink.基于CADisplayLink以屏幕刷新频率同步绘图的特性,尝试根据这点去实现 ...
- Lua队列问题
今天看到Lua程序设计第11章了,表示按照书中的例子打出来,但是不知道正确写用: List = {} function List.new () return {first = 0, last = -1 ...
- MySQL备份与还原详细过程示例
MySQL备份与还原详细过程示例 一.MySQL备份类型 1.热备份.温备份.冷备份 (根据服务器状态) 热备份:读.写不受影响: 温备份:仅可以执行读操作: 冷备份:离线备份:读.写操作均中止: 2 ...
- 安卓listView实现下拉刷新上拉加载滑动仿QQ的删除功能
大家对这些功能都是看的多了,然后对上拉刷新和下拉加载的原理都是非常清楚的,所以实现这功能其实也就是为了让大家能够从众多的同行们来进行比较学习而已,虽然即使是这样,但是面试的时候面试官还是会问你上拉和下 ...
- 【Android】Android 8种对话框(Dialog)
1.写在前面 Android提供了丰富的Dialog函数,本文介绍最常用的8种对话框的使用方法,包括普通(包含提示消息和按钮).列表.单选.多选.等待.进度条.编辑.自定义等多种形式,将在第2部分介绍 ...
- MongoDB Linux环境安装及配置[转]
CentOS 6.5系统中使用yum安装MongoDB 2.6 教程 CentOS 6.5系统中使用yum安装MongoDB 2.6 教程,本文共分5个步骤完成MongoDB的安装.下面我们在Cent ...
- MongoDB学习笔记(11) --- 聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*) aggregate() 方法 MongoDB中聚 ...