Flume协作框架
1.概述
-》flume的三大功能
collecting, aggregating, and moving
收集 聚合 移动
2.框图
3.架构特点
-》on streaming data flows
基于流式的数据
数据流:job-》不断获取数据
任务流:job1->job2->job3&job4
-》for online analytic application.
-》Flume仅仅运行在linux环境下
如果我的日志服务器是Windows?
-》非常简单
写一个配置文件,运行这个配置文件
source、channel、sink
-》实时架构
flume+kafka spark/storm impala
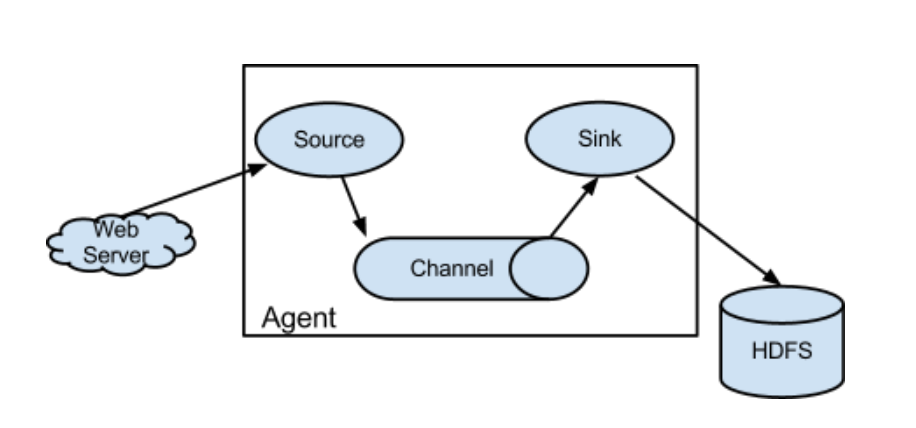
-》agent三大部分
-》source:采集数据,并发送给channel
-》channel:管道,用于连接source和sink的
-》sink:发送数据,用于采集channel中的数据
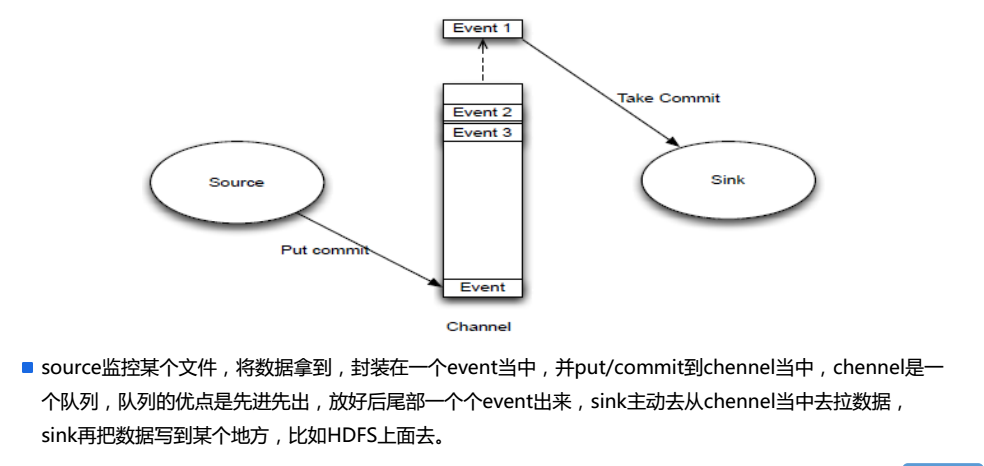
4.Event

5.Source/Channel/Sink
二:配置
1.下载解压
下载的是Flume版本1.5.0
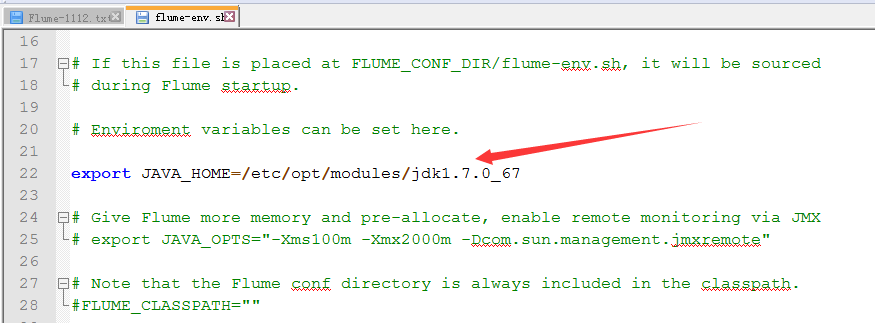
2.启用flume-env.sh

3.修改flume-env.sh
4.增加HADOOP_HOME
因为在env.sh中没有配置,选择的方式是将hdfs的配置放到conf目录下。

5.放入jar包
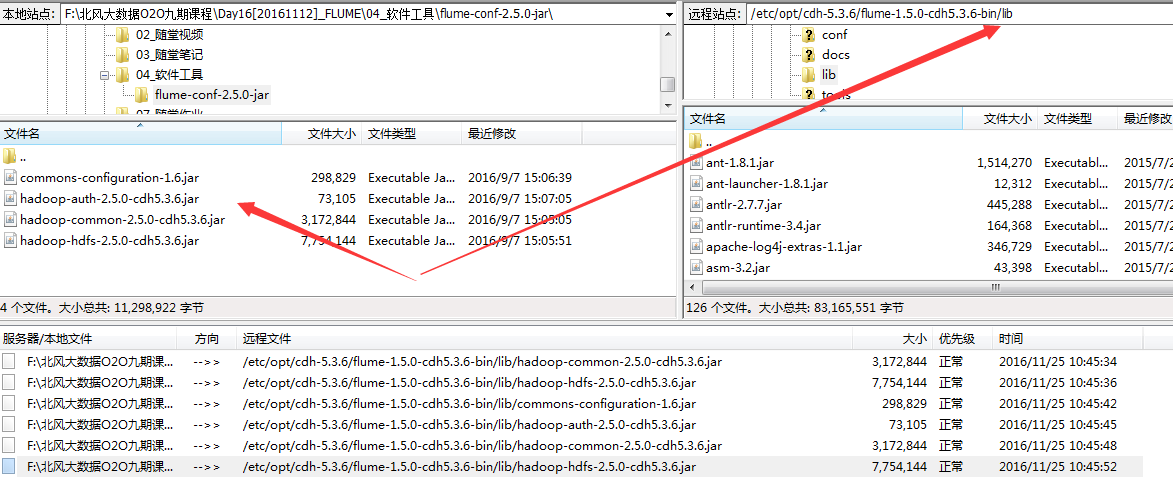
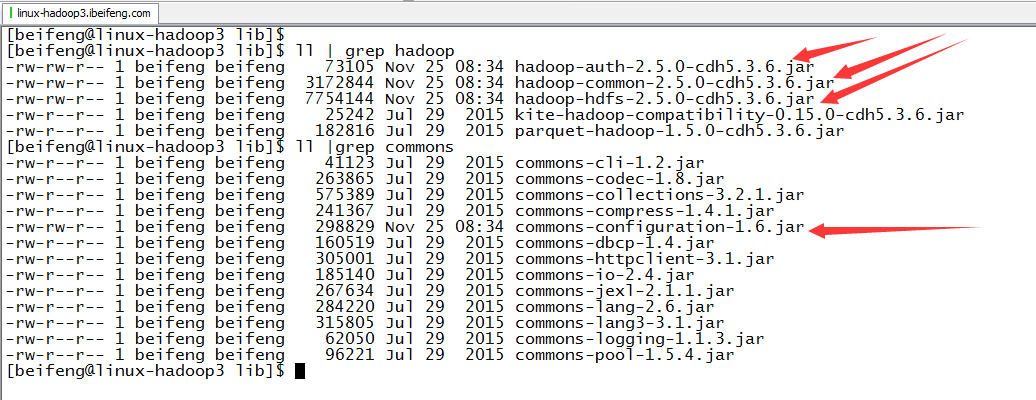
6.验证
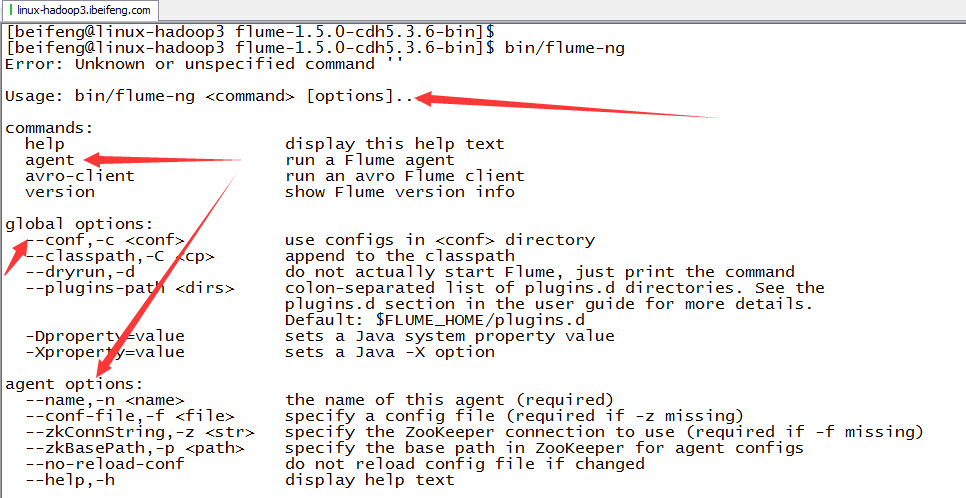
7.用法
三:Flume的使用

1.案例1
source:hive.log channel:mem sink:logger
2.配置
cp flume-conf.properties.template hive-mem-log.properties
3.配置hive-mem-log.properties
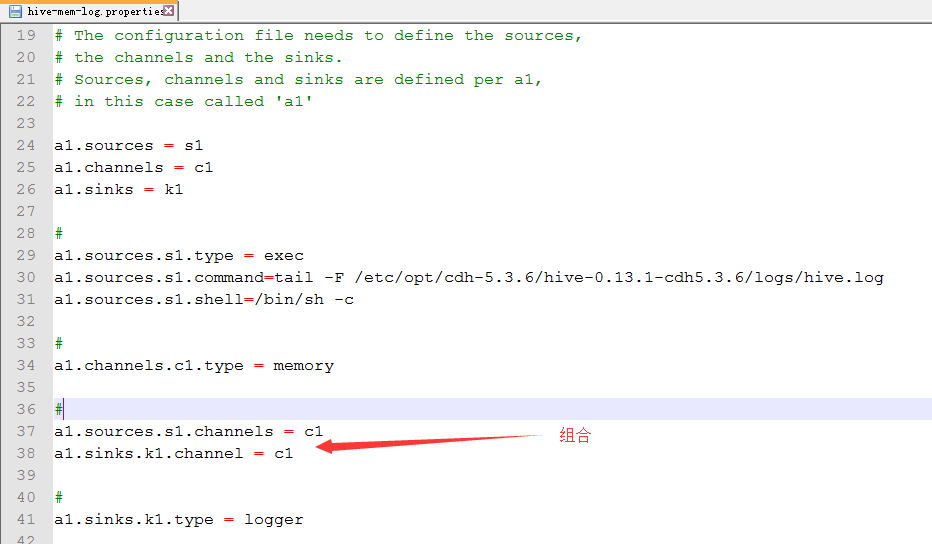
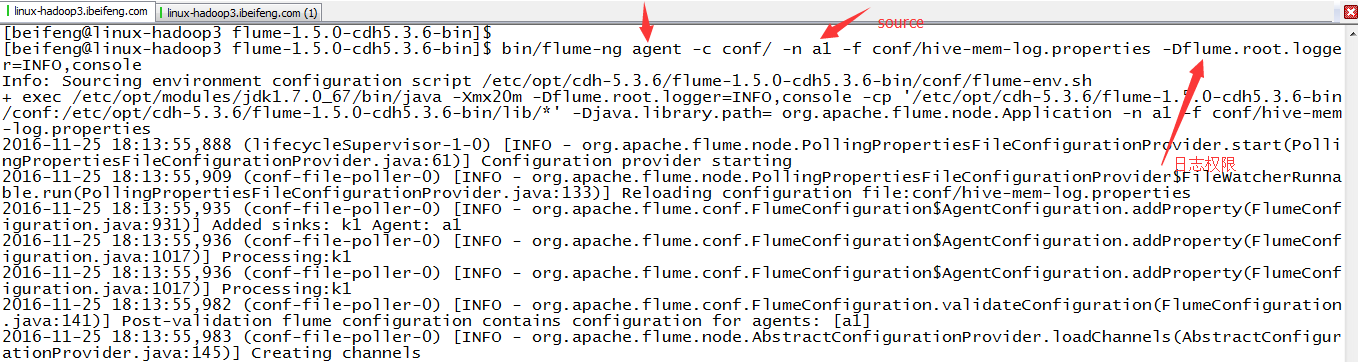
4.运行
那边是日志级别
5.注意点
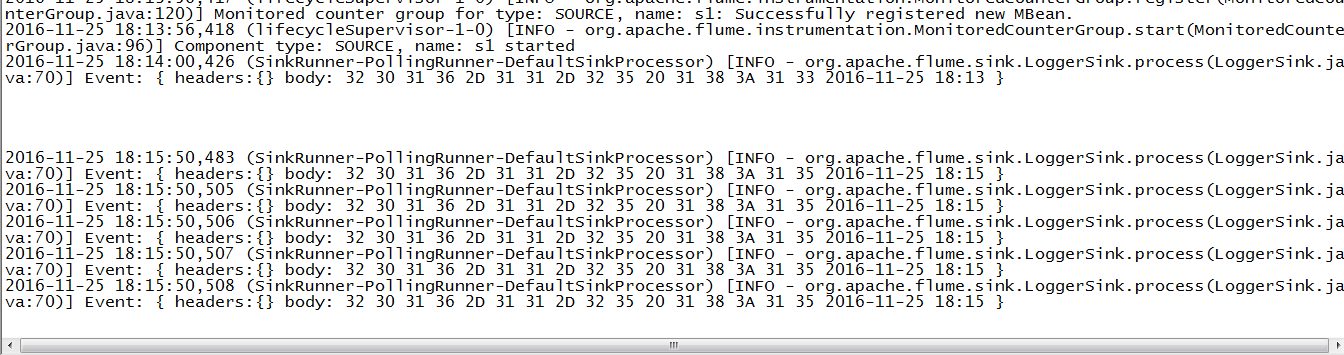
这边的属于实时采集,所以在控制台上的信息随着hive.log的变化在变化
6.案例二
source:hive.log channel:file sink:logger
7.配置
cp hive-mem-log.properties hive-file-log.properties
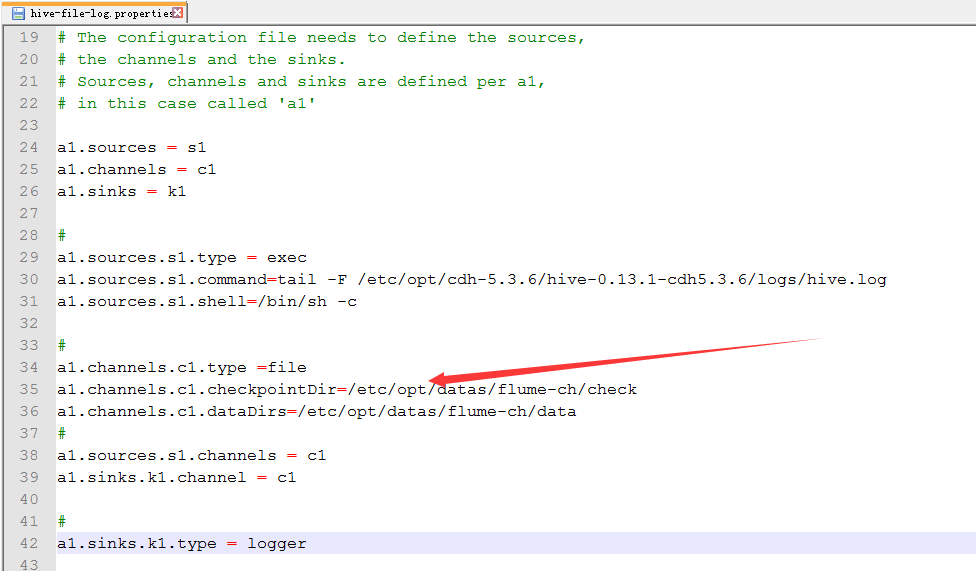
8.配置hive-file-log.properties
新建file的目录

配置
9.运行
10.结果
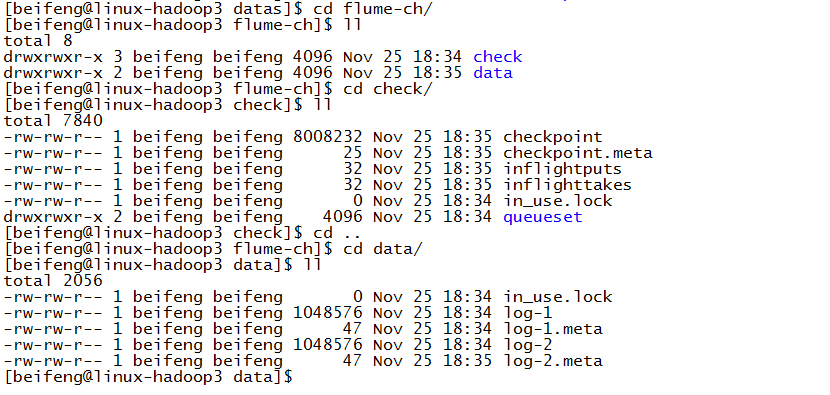
11.案例三
source:hive.log channel:mem sink:hdfs
12.配置
cp hive-mem-log.properties hive-mem-hdfs.properties
13.配置hive-mem-hdfs.properties
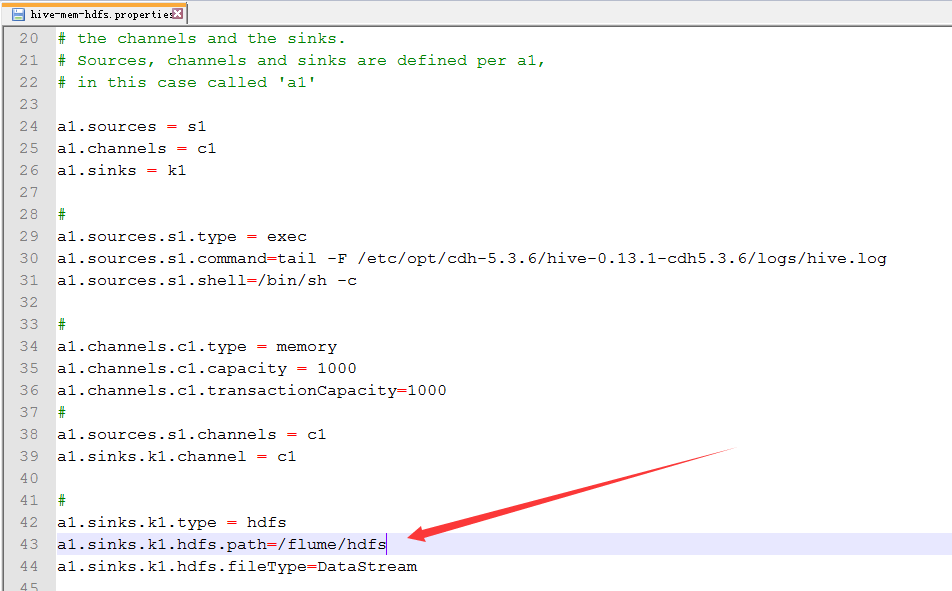
14.运行
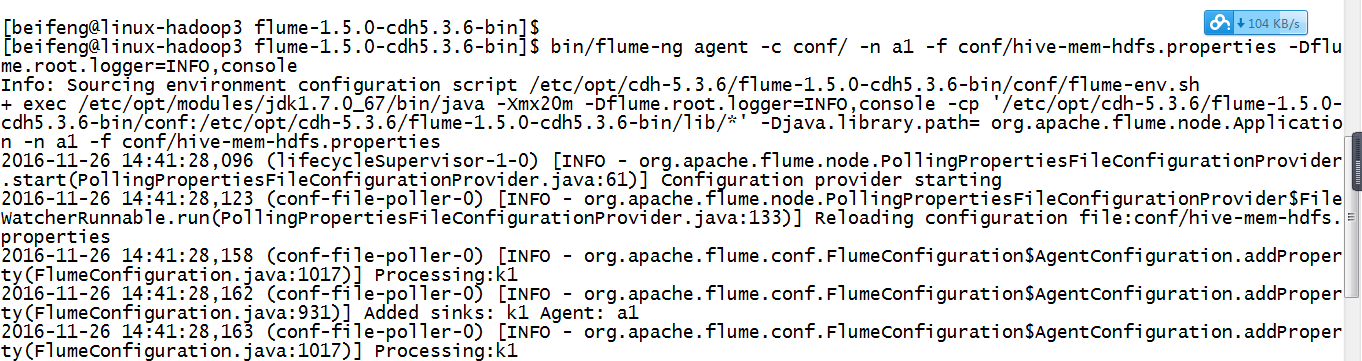
验证了,在配置文件中不需要有这个目录,会自动产生。

四:企业思考一
15.案例四
因为在hdfs上会生成许多小文件,文件的大小的设置。
16.配置
cp hive-mem-hdfs.properties hive-mem-size.properties
17.配置hive-mem-size.properties
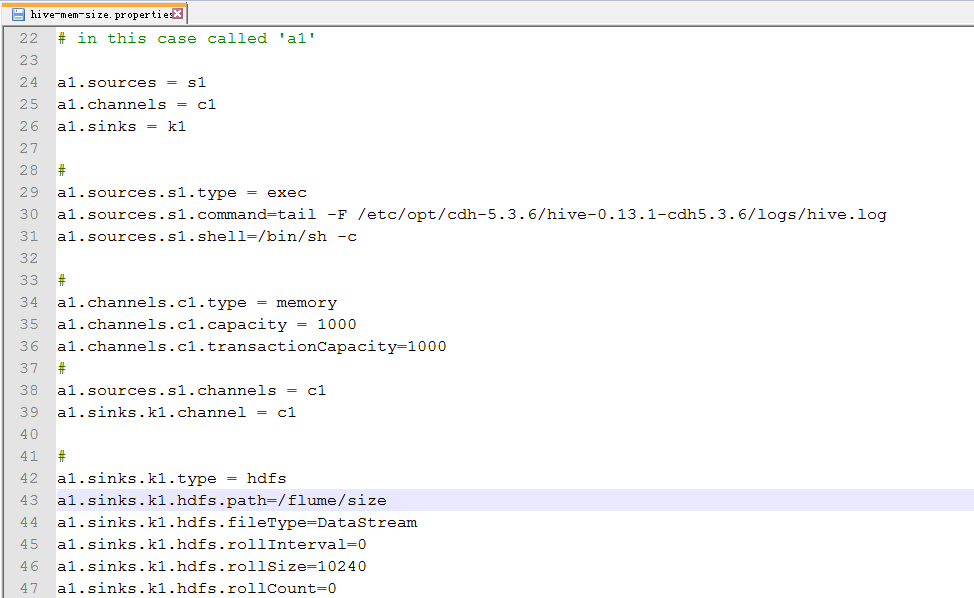
18.运行
19.结果
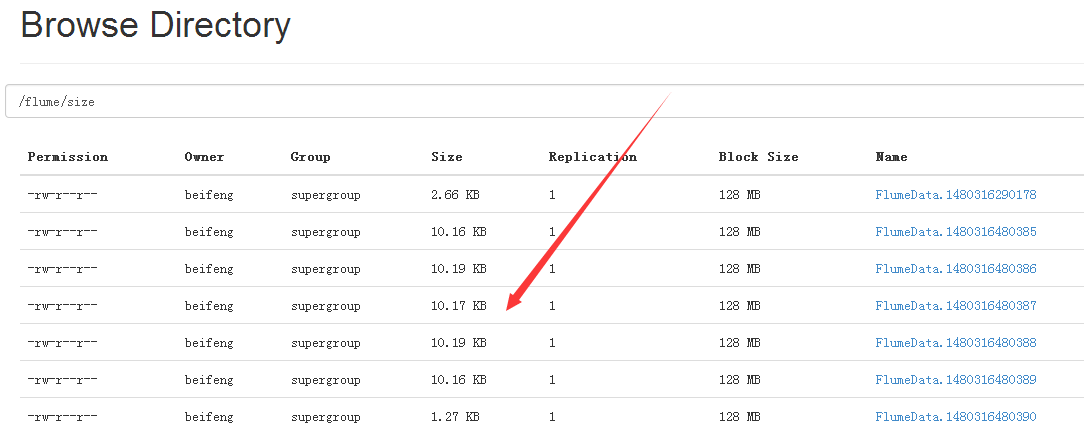
20.案例五
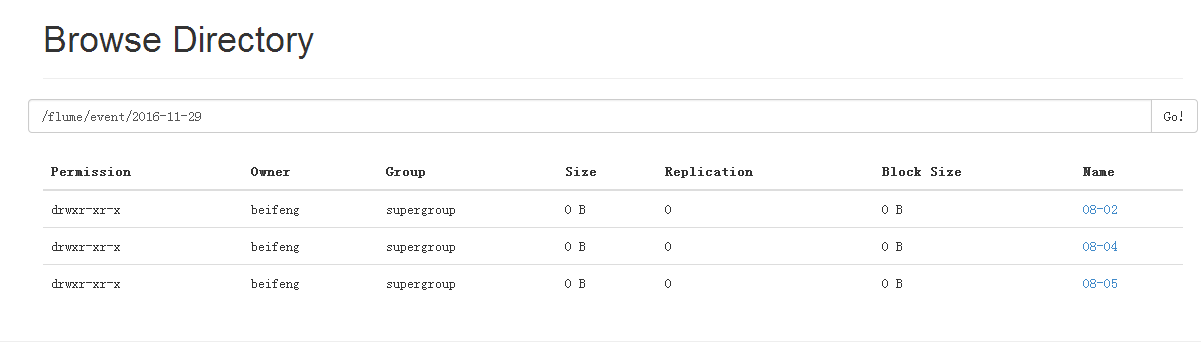
按时间进行分区
21.配置
cp hive-mem-hdfs.properties hive-mem-part.properties
22.配置hive-mem-part.properties
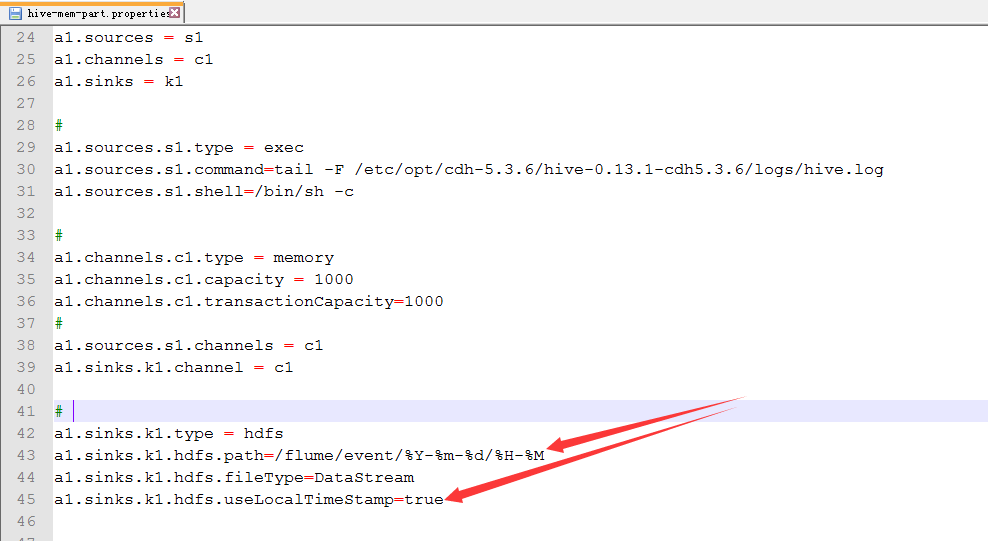
23.运行
bin/flume-ng agent -c conf/ -n a1 -f conf/hive-mem-part.properties -Dflume.root.logger=INFO,console
24.运行结果
25.案例六
自定义文件开头
26.配置hive-mem-part.properties
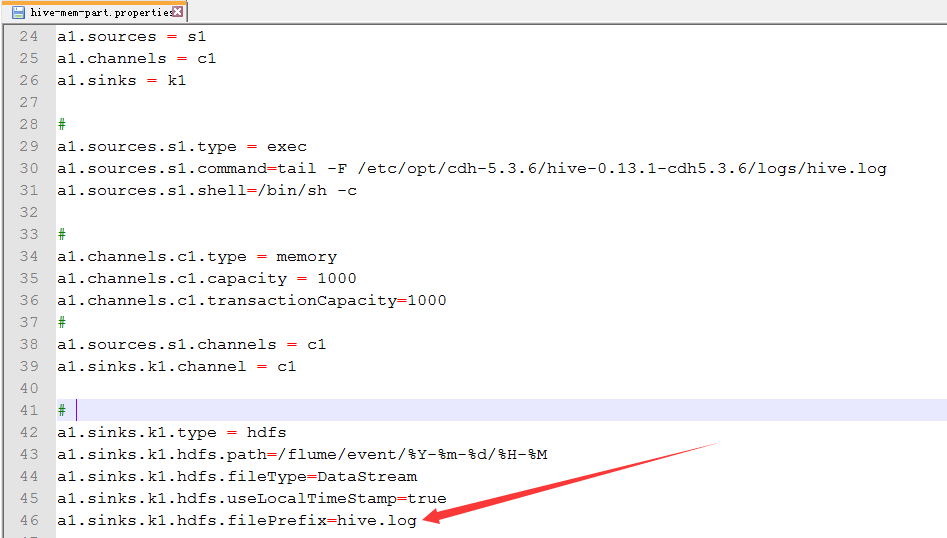
27.运行效果
五:企业思考二
1.案例七
source:用来监控文件夹
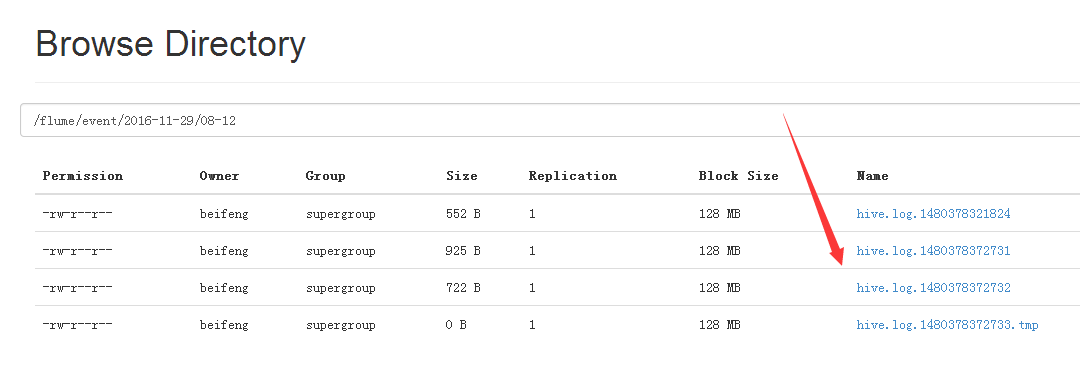
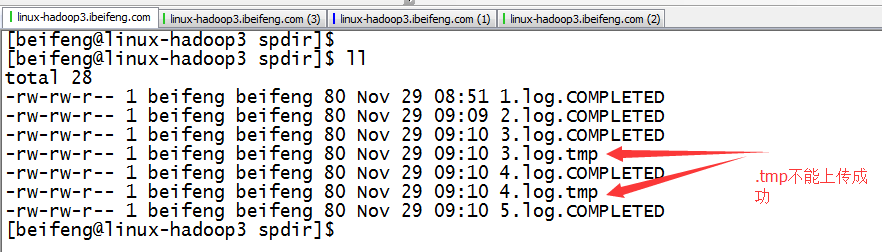
文件中先存在.tmp
到第二日出现新的.tmp文件。前一天的.tmp马上变成log结尾,这时监控文件夹时,马上发现出现一个新的文件,就被上传进HDFS
2.配置
cp hive-mem-hdfs.properties dir-mem-hdfs.properties
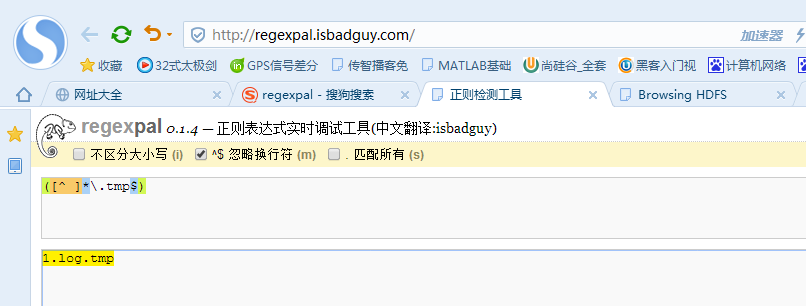
3.正则表达式忽略上传的.tmp文件
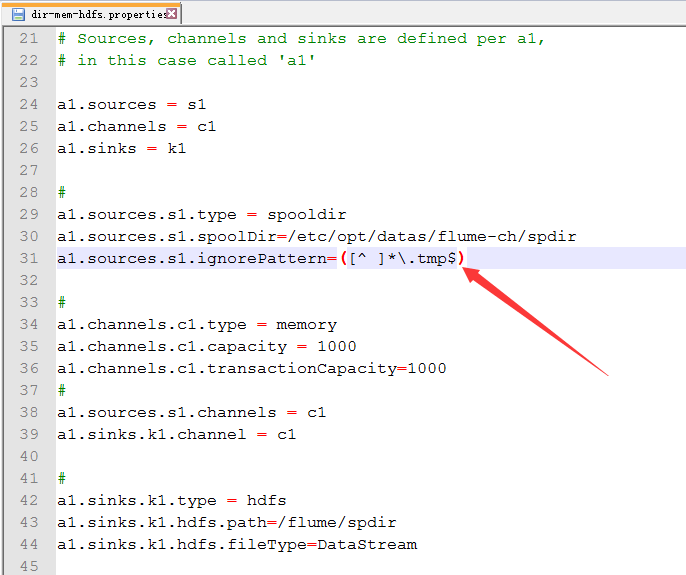
3.配置dir-mem-hdfs.properties
新建文件夹

配置
4.观察结果
5.案例二
source:监控文件夹下文件的不断动态追加
但是现在不是监控新出现的文件下,
这个配置将在下面讲解
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
六:企业实际架构
1.flume多sink
同一份数据采集到不同的框架
采集source:一份数据
管道channel:案例中使用两个管道
目标sink:多个针对于多个channel
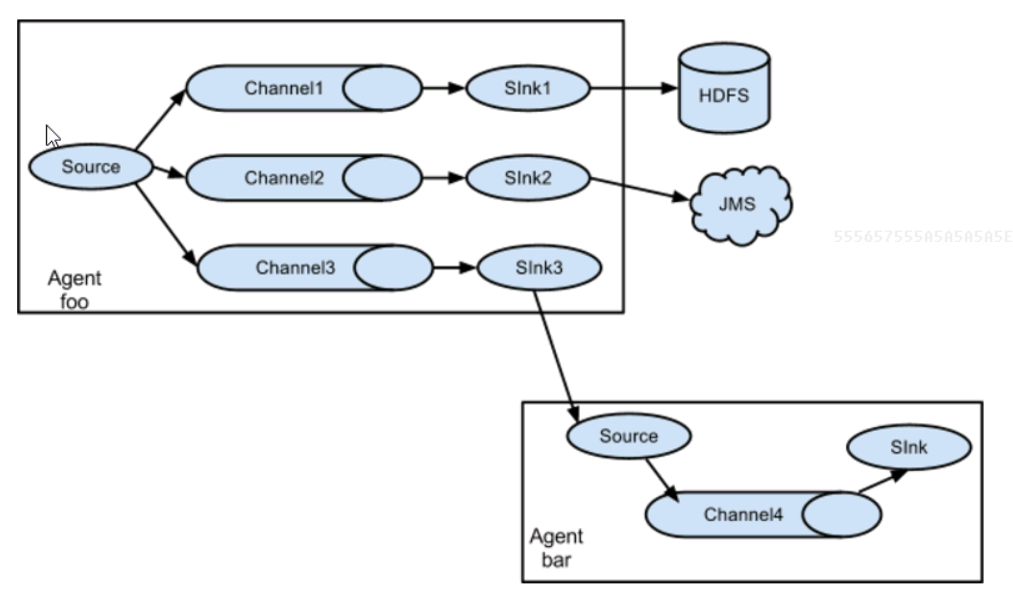
2.案例
source:hive.log channel:file sink:hdfs
3.配置
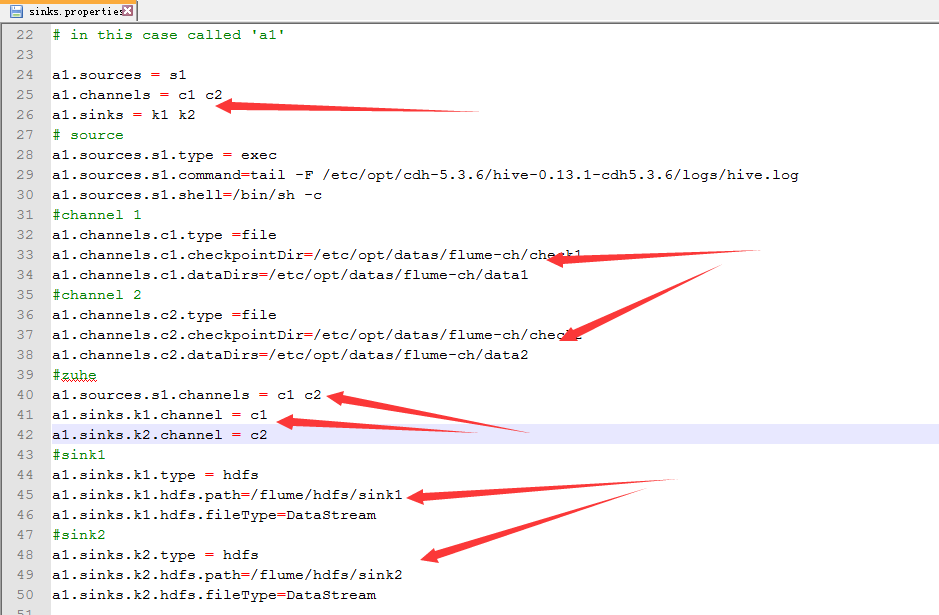
cp hive-mem-hdfs.properties sinks.properties
4.配置sink.properties
新建存储的文件
配置
5.效果

6.flume的collect

7.案例
启动三台机器,其中两台为agent,一台collect。
192.168.134.241:collect
192.168.134.242:agent
192.168.134.243:agent
8.情况
因为没有搭建cdh集群,暂时不粘贴
9.运行
运行:collect
bin/flume-ng agent -c conf/ -n a1 -f conf/avro-collect.properties -Dflume.root.logger=INFO,console
运行:agent
bin/flume-ng agent -c conf/ -n a1 -f conf/avro-agent.properties -Dflume.root.logger=INFO,console
七:关于文件夹中文件处于追加的监控
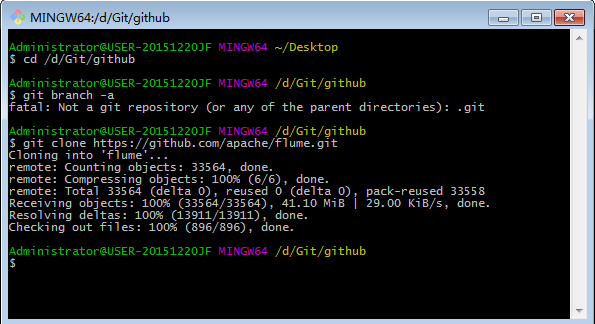
1.安装git
2.新建一个文件下
3.在git bash 中进入目录
4.在此目录下下载源码
5.进入flume目录
6.查看源码有哪些分支

7.切换分支
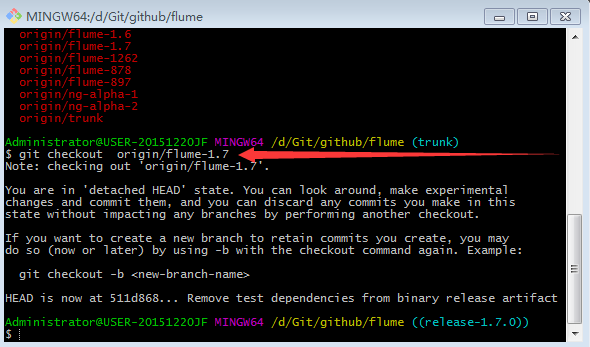
8.复制出flume-taildir-source
九。编译
1.pom文件
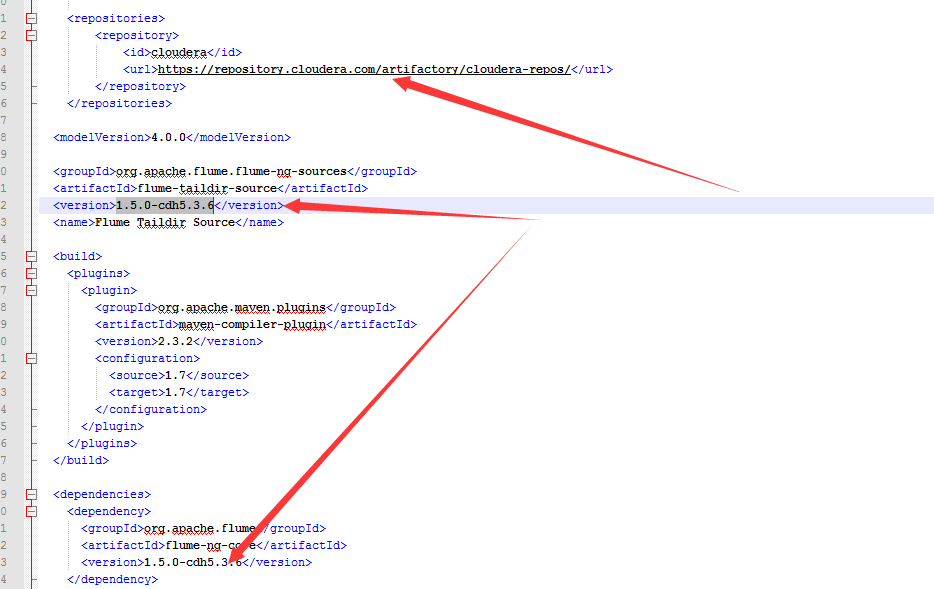
2.在1.5.0中添加一个1.7.0中的类
PollableSourceConstants
3.删除override

4.编译
run as -> maven build
goals -> skip testf
5.将jar包放在lib目录下
6.使用
因为这是1.7.0的源码,所以在1.5的文档中没有。
所以:可以看源码
或者看1.7.0的参考文档关于Tail的介绍案例
\flume\flume-ng-doc\sphinx\FlumeUserGuide
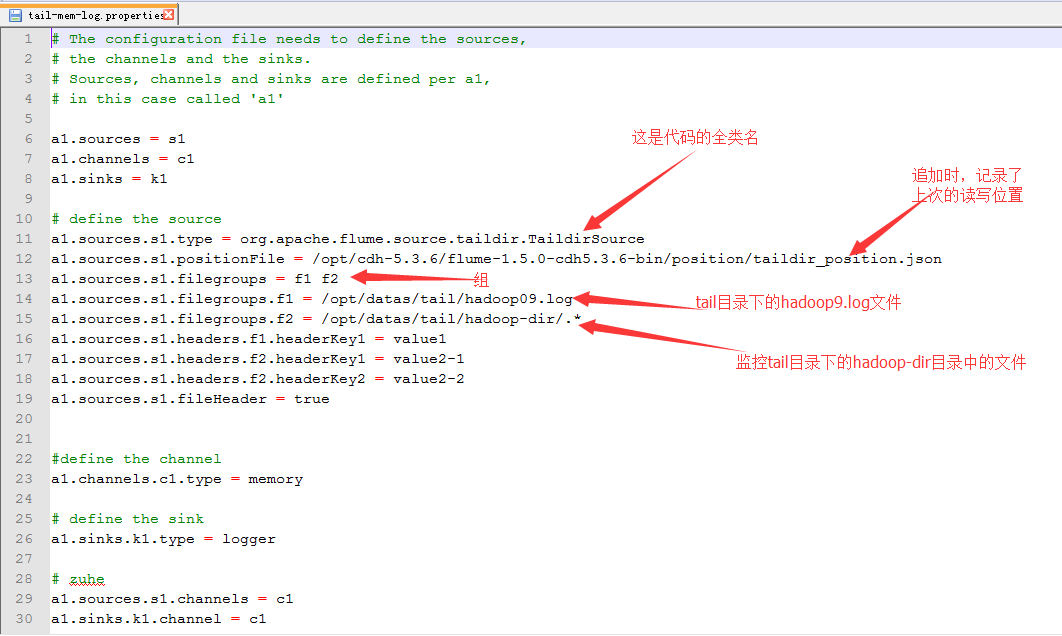
7.配置
Flume协作框架的更多相关文章
- 067 Flume协作框架
一:介绍 1.概述 ->flume的三大功能 collecting, aggregating, and moving 收集 聚合 移动 数据源:web service ...
- Oozie协作框架
一:概述 1.大数据协作框架 2.Hadoop的任务调度 3.Oozie的三大功能 Oozie Workflow jobs Oozie Coordinator jobs Oozie Bundle 4. ...
- Hue协作框架
http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/manual.html 一:框架 1.支持的框架 ->job ->yar ...
- 069 Hue协作框架
一:介绍 1.官网 官网:http://gethue.com/ 下载:http://archive.cloudera.com/cdh5/cdh/5/,只能在这里下载,不是Apache的 手册:http ...
- 【Hadoop 分布式部署 八:分布式协作框架Zookeeper架构功能讲解 及本地模式安装部署和命令使用 】
What is Zookeeper 是一个开源的分布式的,为分布式应用提供协作服务的Apache项目 提供一个简单的原语集合,以便与分布式应用可以在他之上构建更高层次的同步服务 设计非常简单易于编 ...
- 【Hadoop 分布式部署 九:分布式协作框架Zookeeper架构 分布式安装部署 】
1.首先将运行在本地上的 zookeeper 给停止掉 2.到/opt/softwares 目录下 将 zookeeper解压到 /opt/app 目录下 命令: tar -zxvf zoo ...
- Hadoop调度框架
大数据协作框架是一个桐城,就是Hadoop2生态系统中几个辅助的Hadoop2.x框架.主要如下: 1,数据转换工具Sqoop 2,文件搜集框架Flume 3,任务调度框架Oozie 4,大数 ...
- Sqoop框架基础
Sqoop框架基础 本节我们主要需要了解的是大数据的一些协作框架,也是属于Hadoop生态系统或周边的内容,比如: ** 数据转换工具:Sqoop ** 文件收集库框架:Flume ** 任务调度框架 ...
- 【转】Flume日志收集
from:http://www.cnblogs.com/oubo/archive/2012/05/25/2517751.html Flume日志收集 一.Flume介绍 Flume是一个分布式.可 ...
随机推荐
- 源码安装Memcached服务器及其2种PHP客户端
本文所用源码包皆为当时最新stable稳定版. 安装memcached服务器 先安装libevent, 最新版为2.0.21 tar -zxvf libevent-2.0.21-stable.tar. ...
- node相关--WebSocket
socket:socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信. ajax: 通过HTTP请求+响应模式的方式来发送和 ...
- 转 BHO API HOOK Wininet基于IE编程的一些资料
BHO原理:推荐vc base中的文章: 如何使用BHO定制你的Internet Explorer浏览器 API HOOK的基本原理:推荐C++ builder 研究中的文章: API Hook基 ...
- javascript继承扩展类方法实现
javascript没有原生的继承语法,这确实很让人困惑,但是广大人民群从的智慧是无穷的.最近呢,正尝到一点从源码中学习的甜头,不分享一下实在难以平复激动的心情.前不久改造视频播放插件的时候,找到了v ...
- 【BZOJ】2038: [2009国家集训队]小Z的袜子(hose)(组合计数+概率+莫队算法+分块)
http://www.lydsy.com/JudgeOnline/problem.php?id=2038 学了下莫队,挺神的orzzzz 首先推公式的话很简单吧... 看的题解是从http://for ...
- 【BZOJ】2002: [Hnoi2010]Bounce 弹飞绵羊(lct)
http://www.lydsy.com/JudgeOnline/problem.php?id=2002 (BZOJ挂了,还没在BZOJ测,先是在wikioi测过了,,) 囧.在军训时立志要学lct! ...
- 【BZOJ】1202: [HNOI2005]狡猾的商人(并查集+前缀和)
http://www.lydsy.com/JudgeOnline/problem.php?id=1202 用并查集+前缀和. 前缀和从后向前维护和,并查集从前往后合并 对于询问l, r 如果l-1和r ...
- BZOJ4012 [HNOI2015]开店
Description 风见幽香有一个好朋友叫八云紫,她们经常一起看星星看月亮从诗词歌赋谈到 人生哲学.最近她们灵机一动,打算在幻想乡开一家小店来做生意赚点钱.这样的 想法当然非常好啦,但是她们也发现 ...
- ext4 文件系统的一些记录
https://www.kernel.org/doc/Documentation/filesystems/ext4.txt ext4 权威说明 http://computer-forensics.sa ...
- SQL SERVER事务处理
SQL SERVER事务处理 一.事务定义: 事务是单个的工作单元.如果某一事务成功,则在该事务中进行的所有数据更改均会提交,成为数据库中的永久组成部分. 如果事务遇到错误且必须取消或回滚,则所有 ...