Linux内核中双向链表的经典实现
概要
前面一章"介绍双向链表并给出了C/C++/Java三种实现",本章继续对双向链表进行探讨,介绍的内容是Linux内核中双向链表的经典实现和用法。其中,也会涉及到Linux内核中非常常用的两个经典宏定义offsetof和container_of。内容包括:
1. Linux中的两个经典宏定义
2. Linux中双向链表的经典实现
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3562146.html
更多内容: 数据结构与算法系列 目录
Linux中的两个经典宏定义
倘若你查看过Linux Kernel的源码,那么你对 offsetof 和 container_of 这两个宏应该不陌生。这两个宏最初是极客写出的,后来在Linux内核中被推广使用。
1. offsetof
1.1 offsetof介绍
定义:offsetof在linux内核的include/linux/stddef.h中定义。
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
说明:获得结构体(TYPE)的变量成员(MEMBER)在此结构体中的偏移量。
(01) ( (TYPE *)0 ) 将零转型为TYPE类型指针,即TYPE类型的指针的地址是0。
(02) ((TYPE *)0)->MEMBER 访问结构中的数据成员。
(03) &( ( (TYPE *)0 )->MEMBER ) 取出数据成员的地址。由于TYPE的地址是0,这里获取到的地址就是相对MEMBER在TYPE中的偏移。
(04) (size_t)(&(((TYPE*)0)->MEMBER)) 结果转换类型。对于32位系统而言,size_t是unsigned int类型;对于64位系统而言,size_t是unsigned long类型。
1.2 offsetof示例
代码(offset_test.c)
#include <stdio.h> // 获得结构体(TYPE)的变量成员(MEMBER)在此结构体中的偏移量。
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) struct student
{
char gender;
int id;
int age;
char name[];
}; void main()
{
int gender_offset, id_offset, age_offset, name_offset; gender_offset = offsetof(struct student, gender);
id_offset = offsetof(struct student, id);
age_offset = offsetof(struct student, age);
name_offset = offsetof(struct student, name); printf("gender_offset = %d\n", gender_offset);
printf("id_offset = %d\n", id_offset);
printf("age_offset = %d\n", age_offset);
printf("name_offset = %d\n", name_offset);
}
结果:
gender_offset =
id_offset =
age_offset =
name_offset =
说明:简单说说"为什么id的偏移值是4,而不是1"。我的运行环境是linux系统,32位的x86架构。这就意味着cpu的数据总线宽度为32,每次能够读取4字节数据。gcc对代码进行处理的时候,是按照4字节对齐的。所以,即使gender是char(一个字节)类型,但是它仍然是4字节对齐的!
1.3 offsetof图解
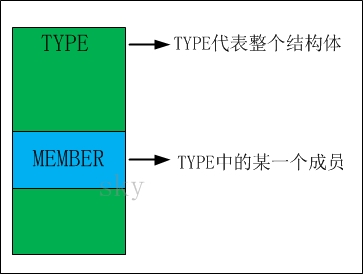
TYPE是结构体,它代表"整体";而MEMBER是成员,它是整体中的某一部分。
将offsetof看作一个数学问题来看待,问题就相当简单了:已知'整体'和该整体中'某一个部分',而计算该部分在整体中的偏移。
2. container_of
2.1 container_of介绍
定义:container_of在linux内核的include/linux/kernel.h中定义。
#define container_of(ptr, type, member) ({ \
const typeof( ((type *))->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
说明:根据"结构体(type)变量"中的"域成员变量(member)的指针(ptr)"来获取指向整个结构体变量的指针。
(01) typeof( ( (type *)0)->member ) 取出member成员的变量类型。
(02) const typeof( ((type *)0)->member ) *__mptr = (ptr) 定义变量__mptr指针,并将ptr赋值给__mptr。经过这一步,__mptr为member数据类型的常量指针,其指向ptr所指向的地址。
(04) (char *)__mptr 将__mptr转换为字节型指针。
(05) offsetof(type,member)) 就是获取"member成员"在"结构体type"中的位置偏移。
(06) (char *)__mptr - offsetof(type,member)) 就是用来获取"结构体type"的指针的起始地址(为char *型指针)。
(07) (type *)( (char *)__mptr - offsetof(type,member) ) 就是将"char *类型的结构体type的指针"转换为"type *类型的结构体type的指针"。
2.2 container_of示例
代码(container_test.c)
#include <stdio.h>
#include <string.h> // 获得结构体(TYPE)的变量成员(MEMBER)在此结构体中的偏移量。
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) // 根据"结构体(type)变量"中的"域成员变量(member)的指针(ptr)"来获取指向整个结构体变量的指针
#define container_of(ptr, type, member) ({ \
const typeof( ((type *))->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );}) struct student
{
char gender;
int id;
int age;
char name[];
}; void main()
{
struct student stu;
struct student *pstu; stu.gender = '';
stu.id = ;
stu.age = ;
strcpy(stu.name, "zhouxingxing"); // 根据"id地址" 获取 "结构体的地址"。
pstu = container_of(&stu.id, struct student, id); // 根据获取到的结构体student的地址,访问其它成员
printf("gender= %c\n", pstu->gender);
printf("age= %d\n", pstu->age);
printf("name= %s\n", pstu->name);
}
结果:
gender=
age=
name= zhouxingxing
2.3 container_of图解
type是结构体,它代表"整体";而member是成员,它是整体中的某一部分,而且member的地址是已知的。
将offsetof看作一个数学问题来看待,问题就相当简单了:已知'整体'和该整体中'某一个部分',要根据该部分的地址,计算出整体的地址。
Linux中双向链表的经典实现
1. Linux中双向链表介绍
Linux双向链表的定义主要涉及到两个文件:
include/linux/types.h
include/linux/list.h
Linux中双向链表的使用思想
它是将双向链表节点嵌套在其它的结构体中;在遍历链表的时候,根据双链表节点的指针获取"它所在结构体的指针",从而再获取数据。
我举个例子来说明,可能比较容易理解。假设存在一个社区中有很多人,每个人都有姓名和年龄。通过双向链表将人进行关联的模型图如下: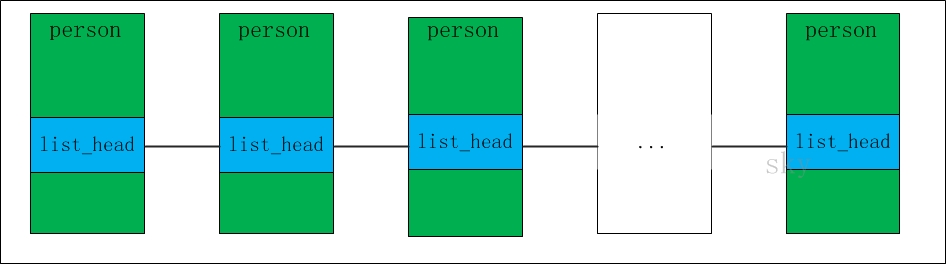
person代表人,它有name和age属性。为了通过双向链表对person进行链接,我们在person中添加了list_head属性。通过list_head,我们就将person关联起来了。
struct person
{
int age;
char name[];
struct list_head list;
};
2. Linux中双向链表的源码分析
(01). 节点定义
struct list_head {
struct list_head *next, *prev;
};
虽然名称list_head,但是它既是双向链表的表头,也代表双向链表的节点。
(02). 初始化节点
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
LIST_HEAD的作用是定义表头(节点):新建双向链表表头name,并设置name的前继节点和后继节点都是指向name本身。
LIST_HEAD_INIT的作用是初始化节点:设置name节点的前继节点和后继节点都是指向name本身。
INIT_LIST_HEAD和LIST_HEAD_INIT一样,是初始化节点:将list节点的前继节点和后继节点都是指向list本身。
(03). 添加节点
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
} static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
} static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
__list_add(new, prev, next)的作用是添加节点:将new插入到prev和next之间。在linux中,以"__"开头的函数意味着是内核的内部接口,外部不应该调用该接口。
list_add(new, head)的作用是添加new节点:将new添加到head之后,是new称为head的后继节点。
list_add_tail(new, head)的作用是添加new节点:将new添加到head之前,即将new添加到双链表的末尾。
(04). 删除节点
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
} static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
} static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
} static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
}
__list_del(prev, next) 和__list_del_entry(entry)都是linux内核的内部接口。
__list_del(prev, next) 的作用是从双链表中删除prev和next之间的节点。
__list_del_entry(entry) 的作用是从双链表中删除entry节点。
list_del(entry) 和 list_del_init(entry)是linux内核的对外接口。
list_del(entry) 的作用是从双链表中删除entry节点。
list_del_init(entry) 的作用是从双链表中删除entry节点,并将entry节点的前继节点和后继节点都指向entry本身。
(05). 替换节点
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
list_replace(old, new)的作用是用new节点替换old节点。
(06). 判断双链表是否为空
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
list_empty(head)的作用是判断双链表是否为空。它是通过区分"表头的后继节点"是不是"表头本身"来进行判断的。
(07). 获取节点
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
list_entry(ptr, type, member) 实际上是调用的container_of宏。
它的作用是:根据"结构体(type)变量"中的"域成员变量(member)的指针(ptr)"来获取指向整个结构体变量的指针。
(08). 遍历节点
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next) #define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
list_for_each(pos, head)和list_for_each_safe(pos, n, head)的作用都是遍历链表。但是它们的用途不一样!
list_for_each(pos, head)通常用于获取节点,而不能用到删除节点的场景。
list_for_each_safe(pos, n, head)通常删除节点的场景。
3. Linux中双向链表的使用示例
双向链表代码(list.h)
#ifndef _LIST_HEAD_H
#define _LIST_HEAD_H // 双向链表节点
struct list_head {
struct list_head *next, *prev;
}; // 初始化节点:设置name节点的前继节点和后继节点都是指向name本身。
#define LIST_HEAD_INIT(name) { &(name), &(name) } // 定义表头(节点):新建双向链表表头name,并设置name的前继节点和后继节点都是指向name本身。
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name) // 初始化节点:将list节点的前继节点和后继节点都是指向list本身。
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
} // 添加节点:将new插入到prev和next之间。
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
} // 添加new节点:将new添加到head之后,是new称为head的后继节点。
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
} // 添加new节点:将new添加到head之前,即将new添加到双链表的末尾。
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
} // 从双链表中删除entry节点。
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
} // 从双链表中删除entry节点。
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
} // 从双链表中删除entry节点。
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
} // 从双链表中删除entry节点,并将entry节点的前继节点和后继节点都指向entry本身。
static inline void list_del_init(struct list_head *entry)
{
__list_del_entry(entry);
INIT_LIST_HEAD(entry);
} // 用new节点取代old节点
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
} // 双链表是否为空
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
} // 获取"MEMBER成员"在"结构体TYPE"中的位置偏移
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) // 根据"结构体(type)变量"中的"域成员变量(member)的指针(ptr)"来获取指向整个结构体变量的指针
#define container_of(ptr, type, member) ({ \
const typeof( ((type *))->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );}) // 遍历双向链表
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next) #define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next) #define list_entry(ptr, type, member) \
container_of(ptr, type, member) #endif
双向链表测试代码(test.c)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "list.h" struct person
{
int age;
char name[];
struct list_head list;
}; void main(int argc, char* argv[])
{
struct person *pperson;
struct person person_head;
struct list_head *pos, *next;
int i; // 初始化双链表的表头
INIT_LIST_HEAD(&person_head.list); // 添加节点
for (i=; i<; i++)
{
pperson = (struct person*)malloc(sizeof(struct person));
pperson->age = (i+)*;
sprintf(pperson->name, "%d", i+);
// 将节点链接到链表的末尾
// 如果想把节点链接到链表的表头后面,则使用 list_add
list_add_tail(&(pperson->list), &(person_head.list));
} // 遍历链表
printf("==== 1st iterator d-link ====\n");
list_for_each(pos, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
printf("name:%-2s, age:%d\n", pperson->name, pperson->age);
} // 删除节点age为20的节点
printf("==== delete node(age:20) ====\n");
list_for_each_safe(pos, next, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
if(pperson->age == )
{
list_del_init(pos);
free(pperson);
}
} // 再次遍历链表
printf("==== 2nd iterator d-link ====\n");
list_for_each(pos, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
printf("name:%-2s, age:%d\n", pperson->name, pperson->age);
} // 释放资源
list_for_each_safe(pos, next, &person_head.list)
{
pperson = list_entry(pos, struct person, list);
list_del_init(pos);
free(pperson);
} }
运行结果:
==== 1st iterator d-link ====
name: , age:
name: , age:
name: , age:
name: , age:
name: , age:
==== delete node(age:) ====
==== 2nd iterator d-link ====
name: , age:
name: , age:
name: , age:
name: , age:
Linux内核中双向链表的经典实现的更多相关文章
- 红黑树(三)之 Linux内核中红黑树的经典实现
概要 前面分别介绍了红黑树的理论知识 以及 通过C语言实现了红黑树.本章继续会红黑树进行介绍,下面将Linux 内核中的红黑树单独移植出来进行测试验证.若读者对红黑树的理论知识不熟悉,建立先学习红黑树 ...
- Linux内核中的双向链表struct list_head
一.双向链表list_head Linux内核驱动开发会经常用到Linux内核中经典的双向链表list_head,以及它的拓展接口和宏定义:list_add.list_add_tail.list_de ...
- Linux中的两个经典宏定义:获取结构体成员地址,根据成员地址获得结构体地址;Linux中双向链表的经典实现。
倘若你查看过Linux Kernel的源码,那么你对 offsetof 和 container_of 这两个宏应该不陌生.这两个宏最初是极客写出的,后来在Linux内核中被推广使用. 1. offse ...
- Linux内核中常用的数据结构和算法(转)
知乎链接:https://zhuanlan.zhihu.com/p/58087261 Linux内核代码中广泛使用了数据结构和算法,其中最常用的两个是链表和红黑树. 链表 Linux内核代码大量使用了 ...
- Linux内核中锁机制之RCU、大内核锁
在上篇博文中笔者分析了关于完成量和互斥量的使用以及一些经典的问题,下面笔者将在本篇博文中重点分析有关RCU机制的相关内容以及介绍目前已被淘汰出内核的大内核锁(BKL).文章的最后对<大话Linu ...
- 大话Linux内核中锁机制之RCU、大内核锁
大话Linux内核中锁机制之RCU.大内核锁 在上篇博文中笔者分析了关于完成量和互斥量的使用以及一些经典的问题,下面笔者将在本篇博文中重点分析有关RCU机制的相关内容以及介绍目前已被淘汰出内核的大内核 ...
- Linux内核中链表实现
关于双链表实现,一般教科书上定义一个双向链表节点的方法如下: struct list_node{ stuct list_node *pre; stuct list_node *next; ElemTy ...
- 深度剖析linux内核万能--双向链表,Hash链表模版
我们都知道,链表是数据结构中用得最广泛的一种数据结构,对于数据结构,有顺序存储,数组就是一种.有链式存储,链表算一种.当然还有索引式的,散列式的,各种风格的说法,叫法层出不穷,但是万变不离其中,只要知 ...
- Linux内核中的算法和数据结构
算法和数据结构纷繁复杂,但是对于Linux Kernel开发人员来说重点了解Linux内核中使用到的算法和数据结构很有必要. 在一个国外问答平台stackexchange.com的Theoretica ...
随机推荐
- javascript设计模式与开发实践阅读笔记(9)——命令模式
命令模式:有时候需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是什么,此时希望用一种松耦合的方式来设计软件,使得请求发送者和请求接收者能够消除彼此之间的耦合关系. 说法很复 ...
- Python学习笔记(4):自定义时间类
Python的时间我实在无法接受,太难用了.我觉得C#的时间就非常完美,简单.好用.所以,自定义了自己的时间类: 用法: 一个小小的应用,我需要取出每天股市交易的分钟段,开始是这样的: 稍微改进一下, ...
- 在Windows下使用Nodist进行Node版本控制
完全卸载Node.js 首先卸载Node.js应用程序 确认在C:\Program Files中没有Nodejs目录 确认在C:\Program Files (x86)没有Nodejs目录 删除C:\ ...
- SoapUI Pro Project Solution Collection-DataSource(jdbc,excel)
here give a solution for excel file change the excel configuration these: Set Excel file path in cur ...
- j$(function() j$(document).ready 区别
$j(document).ready(function(){}); // 或者 $j(function(){}); 第一个是直接使用Jquery调用function,第二个是在文档加载完毕后才去调用 ...
- SVO实时全局光照优化(里程碑MK0):Sparse Voxel Octree based Global Illumination (SVO GI)
完全自主实现,bloat-free.再次声明,这不是UE.U3D.CE.KlayGE! 老规矩,先贴图.后面有时间再补充描述. 1. 支持多跳间接全局光照2. 支持vxao/so.vxdiff/spe ...
- 10分钟掌握XML、JSON及其解析
引言 NOKIA 有句著名的广告语:“科技以人为本”.任何技术都是为了满足人的生产生活需要而产生的.具体到小小的一个手机,里面蕴含的技术也是浩如烟海,是几千年来人类科技的结晶,单个人穷其一生也未必能掌 ...
- web开发必备-网络基础知识---记录一下
1.osi 7层网络模型 2.socket 套接字编程 PS:一个从事web开发的人来说,我们是使用http协议来和服务器来进行交互.后面会详细的分析这个过程.
- Apple开发者网站中一些比较有用的文档
支持IPv6 DNS64/NAT64网络 关于plist文件中的键与值 Apple各种审核准则以及设计准则
- [译]PostCSS介绍
PostCSS介绍 原文链接:http://www.smashingmagazine.com/2015/12/introduction-to-postcss/ 转自:http://www.zcfy.c ...