Python爬虫黑科技(经验)
"作为一名爬虫工程师,你最需要关注的,是数据的来源"
原文:https://www.jb51.net/article/90114.htm
霍夫曼编码压缩算法
1.最基本的抓站
- import urllib2
- content = urllib2.urlopen('http://XXXX').read()
2.使用代理服务器
这在某些情况下比较有用,比如IP被封了,或者比如IP访问的次数受到限制等等。
|
1 2 3 4 5 |
|
3.需要登录的情况 cookie 表单
- import urllib
- postdata=urllib.urlencode({
- 'username':'XXXXX',
- 'password':'XXXXX',
- 'continueURI':'http://www.verycd.com/',
- 'fk':fk,
- 'login_submit':'登录'
- })
3.伪装浏览器
- import urllib2
- import random
- url = "http://www.itcast.cn"
- #注意是列表
- ua_list = [
- "Mozilla/5.0 (Windows NT 6.1; ) Apple.... ",
- "Mozilla/5.0 (X11; CrOS i686 2268.111.0)... "
- ]
- #随机选择
- user_agent = random.choice(ua_list)
- request = urllib2.Request(url)
- #也可以通过调用Request.add_header() 添加/修改一个特定的header
- request.add_header("User-Agent", user_agent)
- # 第一个字母大写,后面的全部小写
- request.get_header("User-agent")
- response = urllib2.urlopen(req)
- html = response.read()
- print html
3.反‘反盗链’
某些站点有所谓的反盗链设置,其实说穿了很简单,就是检查你发送请求的header里面,referer站点是不是他自己,所以我们只需要像3.3一样,把headers的referer改成该网站即可,以黑幕著称地cnbeta为例:
|
1 2 3 |
|
4.多线程并发抓取
单线程太慢的话,就需要多线程了,这里给个简单的线程池模板 这个程序只是简单地打印了1-10,但是可以看出是并发地。
队列还要加强学习
- from threading import Thread
- from Queue import Queue
- from time import sleep
- #q是任务队列
- #NUM是并发线程总数
- #JOBS是有多少任务
- q = Queue()
- NUM = 2
- JOBS = 10
- #具体的处理函数,负责处理单个任务
- def do_somthing_using(arguments):
- print arguments
- #这个是工作进程,负责不断从队列取数据并处理
- def working():
- while True:
- arguments = q.get()
- do_somthing_using(arguments)
- sleep(1)
- q.task_done()
- #fork NUM个线程等待队列
- for i in range(NUM):
- t = Thread(target=working)
- t.setDaemon(True)
- t.start()
- #把JOBS排入队列
- for i in range(JOBS):
- q.put(i)
- #等待所有JOBS完成
- q.join()
5.验证码的处理
碰到验证码咋办?这里分两种情况处理:
1、google那种验证码,凉拌
2、简单的验证码:字符个数有限,只使用了简单的平移或旋转加噪音而没有扭曲的,这种还是有可能可以处理的,一般思路是旋转的转回来,噪音去掉,然后划分单个字符,划分好了以后再通过特征提取的方法(例如PCA)降维并生成特征库,然后把验证码和特征库进行比较。这个比较复杂
6 gzip/deflate支持
现在的网页普遍支持gzip压缩,这往往可以解决大量传输时间,以 VeryCD 的主页为例,未压缩版本247K,压缩了以后45K,为原来的1/5。这就意味着抓取速度会快5倍。
然而python的urllib/urllib2默认都不支持压缩,要返回压缩格式,必须在request的header里面写明'accept-encoding',然后读取response后更要检查header查看是否有'content-encoding'一项来判断是否需要解码,很繁琐琐碎。如何让urllib2自动支持gzip, defalte呢?
7. 更方便地多线程
总结一文的确提及了一个简单的多线程模板,但是那个东东真正应用到程序里面去只会让程序变得支离破碎,不堪入目。在怎么更方便地进行多线程方面我也动了一番脑筋。先想想怎么进行多线程调用最方便呢?
1、用twisted进行异步I/O抓取
事实上更高效的抓取并非一定要用多线程,也可以使用异步I/O法:直接用twisted的getPage方法,然后分别加上异步I/O结束时的callback和errback方法即可。
- from twisted.web.client import getPage
- from twisted.internet import reactor
- links = [ 'http://www.verycd.com/topics/%d/'%i for i in range(5420,5430) ]
- def parse_page(data,url):
- print len(data),url
- def fetch_error(error,url):
- print error.getErrorMessage(),url
- # 批量抓取链接
- for url in links:
- getPage(url,timeout=5) \
- .addCallback(parse_page,url) \ #成功则调用parse_page方法
- .addErrback(fetch_error,url) #失败则调用fetch_error方法
- reactor.callLater(5, reactor.stop) #5秒钟后通知reactor结束程序
8. 一些琐碎的经验
opener.open和urllib2.urlopen一样,都会新建一个http请求。通常情况下这不是什么问题,因为线性环境下,一秒钟可能也就新生成一个请求;然而在多线程环境下,每秒钟可以是几十上百个请求,这么干只要几分钟,正常的有理智的服务器一定会封禁你的。
然而在正常的html请求时,保持同时和服务器几十个连接又是很正常的一件事,所以完全可以手动维护一个 HttpConnection 的池,然后每次抓取时从连接池里面选连接进行连接即可。
这里有一个取巧的方法,就是利用squid做代理服务器来进行抓取,则squid会自动为你维护连接池,还附带数据缓存功能,而且squid本来就是我每个服务器上面必装的东东,何必再自找麻烦写连接池呢
2、设定线程的栈大小
栈大小的设定将非常显著地影响python的内存占用,python多线程不设置这个值会导致程序占用大量内存,这对openvz的vps来说非常致命。stack_size必须大于32768,实际上应该总要32768*2以上
3、设置失败后自动重试
- def get(self,req,retries=3):
- try:
- response = self.opener.open(req)
- data = response.read()
- except Exception , what:
- print what,req
- if retries>0:
- return self.get(req,retries-1)
- else:
- print 'GET Failed',req
- return ''
- return data
4、设置超时
- import socket
- socket.setdefaulttimeout(10) #设置10秒后连接超时
Python爬虫防封杀方法集合
爬虫与浏览器对比
相同点
本质上都是通过 http/https 协议请求互联网数据
不同点
爬虫一般为自动化程序,无需用用户交互,而浏览器不是
运行场景不同;浏览器运行在客户端,而爬虫一般都跑在服务端
能力不同;浏览器包含渲染引擎、javascript 虚拟机,而爬虫一般都不具备这两者。
编码
其实编码问题很好搞定,只要记住一点:
####任何平台的任何编码 都能和 Unicode 互相转换
UTF-8 与 GBK 互相转换,那就先把UTF-8转换成Unicode,再从Unicode转换成GBK,反之同理。
decode的作用是将其他编码的字符串转换成 Unicode 编码
encode的作用是将 Unicode 编码转换成其他编码的字符串
一句话:UTF-8是对Unicode字符集进行编码的一种编码方式
- #coding=utf-8
- # 这是一个 UTF-8 编码的字符串
- utf8Str = "你好地球"
- print utf8Str
- # 1. 将 UTF-8 编码的字符串 转换成 Unicode 编码
- unicodeStr = utf8Str.decode("UTF-8")
- print unicodeStr
- # 2. 再将 Unicode 编码格式字符串 转换成 GBK 编码
- gbkData = unicodeStr.encode("GBK")
- print gbkData
- # 1. 再将 GBK 编码格式字符串 转化成 Unicode
- unicodeStr = gbkData.decode("gbk")
- # 2. 再将 Unicode 编码格式字符串转换成 UTF-8
- utf8Str = unicodeStr.encode("UTF-8")
- print utf8Str
- 你好地球
- 你好地球
- ��õ���
- 你好地球
网页内容
内容一般分为两部分,非结构化的数据 和 结构化的数据。
- 非结构化数据:先有数据,再有结构,
- 结构化数据:先有结构、再有数据
非结构化的数据处理
文本、电话号码、邮箱地址
- 正则表达式
HTML 文件
- 正则表达式
- XPath
- CSS选择器
结构化的数据处理
JSON 文件
- JSON Path
- 转化成Python类型进行操作(json类)
XML 文件
- 转化成Python类型(xmltodict)
- XPath
- CSS选择器
- 正则表达式
态度:
让编程改变世界
Change the world by program
虚拟环境
- 创建虚拟环境 pip install virtualenv
- 新建虚拟环境 virtualenv -p "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\python.exe" env1
- 虚拟环境位置:
- New python executable in C:\Users\Administrator\env1\Scripts\python.exe
- 激活虚拟环境
- 1、进入虚拟环境: cd env1
- 2、进入脚本目录: cd Scripts
- 3、运行activate.bat activate.bat
- 4、退出虚拟环境 deactivate.bat
- 虚拟环境高级版
- 安装 virtualenvwrapper
- 创建 mkvirtualenv env2
- 列出所有虚拟环境 lsvirtualenv
- 激活虚拟环境 workon env2
- 进入虚拟环境目录 cdvirtualenv
- 进入虚拟环境的site-packages目录 cdsitepackages
- 列出site-packages目录的所有软件包 lssitepackages
- 停止虚拟环境 deactivate
- 删除虚拟环境 rmvitualenv env2
- 总结:
- 创建:mkvirtualenv [虚拟环境名称]
- 删除:rmvirtualenv [虚拟环境名称]
- 进入:workon [虚拟环境名称]
- 退出:deactivate
- 1、冻结环境
- 所谓冻结(freeze) 环境,就是将当前环境的软件包等固定下来:
- pip freeze >packages.txt # 安装包列表保存到文件packages.txt中
- 2、重建环境
- 重建(rebuild) 环境就是在部署的时候,在生产环境安装好对应版本的软件包,不要出现版本兼容等问题:
- pip install -r packages.txt
- 配合pip,可以批量安装对应版本的软件包,快速重建环境,完成部署。
- 位置:
- New python executable in C:\Users\Administrator\Envs\env2\Scripts\python.exe
- 打包应用:
然后自动生成和安装requirements.txt依赖
生成requirements.txt文件
pip freeze > requirements.txt安装requirements.txt依赖
pip install -r requirements.txt文件编码
input文件(gbk, utf-8...) ----decode-----> unicode -------encode------> output文件(gbk, utf-8...)
代替这繁琐的操作就是codecs.open,例如
文件读尽量用下面方法:
>>> import codecs
>>> fw = codecs.open('test1.txt','a','utf-8')
>>> fw.write(line2)
开源许可证
大概有上百种。很少有人搞得清楚它们的区别。即使在最流行的六种----GPL、BSD、MIT、Mozilla、Apache和LGPL
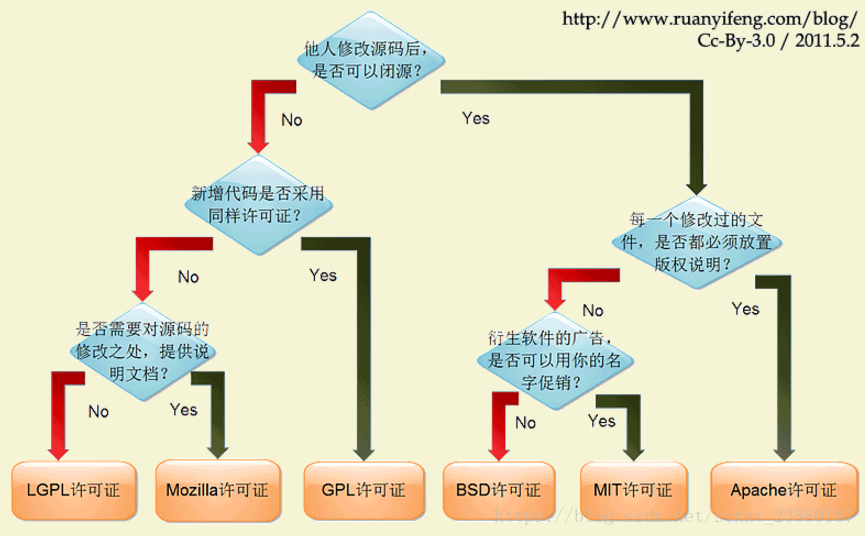
模块(Module)和包(Package)
在Python中,一个.py文件就称之为一个模块
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。(包由很多模块组成,包就是命名空间)
每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码
- mycompany #包
- ├─ __init__.py
- ├─ abc.py #模块
- └─ xyz.py
if __name__ == '__main__'详解
其中 if __name__ =='__main__': 确保服务器只会在该脚本被 Python 解释器直接执行的时候才会运行,而不是作为模块导入的时候。
其中__name__属性的意思:
1、__name__是一个变量。前后加了双下划线是因为是因为这是系统定义的名字。普通变量不要使用此方式命名变量。
2、__name__就是标识模块的名字的一个系统变量。这里分两种情况:假如当前模块是主模块(也就是调用其他模块的模块),那么此模块名字就是__main__,通过if判断这样就可以执行“__mian__:”后面的主函数内容;假如此模块是被import的,则此模块名字为文件名字(不加后面的.py),通过if判断这样就会跳过“__mian__:”后面的内容。
通过上面方式,python就可以分清楚哪些是主函数,进入主函数执行;并且可以调用其他模块的各个函数等等。
神级总结:
one.py
- #coding=utf-8
- # file one.py
- # 在使用自身的时候,就是main,比如你执行:
- # python one.py
- # 此时在one.py里面的name就是main
- # 如果你在two中import one,那么name就是文件名
- def func():
- print("func() in one.py")
- print("top-level in one.py")
- if __name__ == "__main__":
- print("one.py is being run directly")
- else: #其他导入会执行,类似测试吧
- print("one.py is being imported into another module")
two.py
- #coding=utf-8
- # file two.py
- import one #导入就会自动执行,知道是当前的还是以前的
- print("top-level in two.py")
- one.func()
- if __name__ == "__main__":
- print("two.py is being run directly")
- else:
- print("two.py is being imported into another module")
所有规范就多写函数,变量别乱放。
Python爬虫黑科技(经验)的更多相关文章
- python 爬虫 黑科技
1.最基本的抓站 import urllib2 content = urllib2.urlopen('http://XXXX').read() 2.使用代理服务器 这在某些情况下比较有用,比如IP被封 ...
- Python实用黑科技——解包元素(2)
需求: 前面的文章讲的是使用变量的个数需要和迭代器数据变量的元素个数相同的方法,但更多的时候确实不想根据元素个数n来定义相应多的变量,而是希望用较少的变量( def drop_first_last(g ...
- Python实用黑科技——解包元素(1)
需求: 很多时候手上已经有了一个具有n个元素的列表或者元组,你打算把这些元素单独取出来(解包)放入n个变量组成的集合(这里的集合和Python自己的set不同)中. 方法: 显然,最好的办法就是直接用 ...
- 爬虫黑科技,我是怎么爬取indeed的职位数据的
最近在学习nodejs爬虫技术,学了request模块,所以想着写一个自己的爬虫项目,研究了半天,最后选定indeed作为目标网站,通过爬取indeed的职位数据,然后开发一个自己的职位搜索引擎,目前 ...
- Python实用黑科技——以某个字段进行分组
需求: 当前有个字典实例,你想以某个字段比如”日期”对整个字典里面的元素进行分组. 方法: itertools.groupby()函数是专门用来干这个活的.请看下面这个例子,这里有一个列表构成的字典, ...
- Python实用黑科技——找出最大/最小的n个元素
需求: 快速的获取一个列表中最大/最小的n个元素. 方法: 最简便的方法是使用heapq模组的两个方法nlargest()和nsmallest(),例如: In [1]: import heapqIn ...
- Python实用黑科技——找出序列里面出现次数最多的元素
需求: 如何从一个序列中快速获取出现次数最多的元素. 方法: 利用collections.Counter类可以解决这个问题,特别是他的most_common()方法更是处理此问题的最快途径.比如,现在 ...
- Python爬虫突破封禁的6种常见方法
转 Python爬虫突破封禁的6种常见方法 2016年08月17日 22:36:59 阅读数:37936 在互联网上进行自动数据采集(抓取)这件事和互联网存在的时间差不多一样长.今天大众好像更倾向于用 ...
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
随机推荐
- 【Linux 网络编程】滑动窗口协议
<1>通知接受窗口(rwnd): 预防应用程序发送的数据超过对方的缓冲区.接收方使用的流量控制<2>拥塞窗口(cwnd): 预防应用程序发送的数据超过网络所承受的能力.发送方使 ...
- wget断点续传下载需要登录的网站上的大文件
1 举个例子 xcode 2 方法 wget --load-cookies=cookies.txt -c url -c是断点续传,如果网络断了,再运行该命令会接着最新的下载继续下载. --load- ...
- Linux系统装mycat
最近在Linux系统中装载了一下mycut,记录过程以及所遇到的异常 首先是mycut的压缩包,直接放到linux中解压即可 链接:https://pan.baidu.com/s/1qo7z4tNvk ...
- [洛谷P4183][USACO18JAN]Cow at Large P
题目链接 Bzoj崩了之后在洛谷偶然找到的点分好题! 在暴力的角度来说,如果我们$O(n)$枚举根节点,有没有办法在$O(n)$的时间内找到答案呢? 此时如果用树形$dp$的想法,发现是可做的,因为可 ...
- HTTPS为什么是安全的?
学习自https://www.cnblogs.com/zhangsanfeng/p/9125732.html,感谢博主 超文本传输协议HTTP被用于在web浏览器和网站服务器之间传递信息,但以明文方式 ...
- python中魔法方法__str__与__repr__的区别
提出问题 当我们自定义一个类时,打印这个类对象或者在交互模式下直接输入这个类对象按回车,默认显示出来的信息好像用处不大.如下所示 In [1]: class People: ...: def __in ...
- 2018icpc宁夏邀请赛网络赛_G_Trouble of Tyrant
题意 一列\(n\)个点,给定一个特殊的图,有两种边\(E(1,i)\)和\(E(i-1,i)\),多个询问,每次给一个\(d\),求所有路径长度加上\(d\)后1到\(n\)的最短路. 分析 首先这 ...
- sql server 函数详解(3)数据类型转换函数和文本图像函数
数据类型转换函数 文本和图像函数 --在同时处理不同数据类型的值时,SQL Server一般会自动进行隐士类型转换.对于数据类型相近的值是有效的,比如int和float,但是对于其它数据类型,例如整型 ...
- vue-element-ui upload组件调用两次接口
在使用upload中,默认是自动上传,会发现会调用两次接口,一次是Request Method: OPTIONS且不带任何参数(群里大佬说是跨域 预检测),一次是Request Method: POS ...
- React Native 底部导航栏
首先安装:npm install react-native-tab-navigator 然后再引入文件中 import TabNavigator from 'react-native-tab ...