Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation
原文:Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
什么是聚合(Aggregation)
1、 elasticsearch 除了搜索以外,提供的针对ES数据进行统计分析的功能
实时性高、Hadoop(T+1)
2、通过聚合,我们会得到一个数据的概览,是分析和总结全套的数据,而不是寻找单个文档
3、高性能,只需要一套语句,就可以从Elasticsearch得到分析结果(无需在客户端自己去实现分析逻辑)
集合的分类
Aggregation共分为三种:Metric Aggregations、Bucket Aggregations、 Pipeline Aggregations、Matrix Aggregations。

Metric Aggregations 主要是做 一系列的统计,Bucket Aggregations相当于分组。
准备测试数据:
-
PUT zhifou/_doc/1
-
{
-
"name":"顾老二",
-
"age":30,
-
"from": "gu",
-
"desc": "皮肤黑、武器长、性格直",
-
"tags": ["黑", "长", "直"]
-
}
-
-
PUT zhifou/_doc/2
-
{
-
"name":"大娘子",
-
"age":18,
-
"from":"sheng",
-
"desc":"肤白貌美,娇憨可爱",
-
"tags":["白", "富","美"]
-
}
-
-
PUT zhifou/_doc/3
-
{
-
"name":"龙套偏房",
-
"age":22,
-
"from":"gu",
-
"desc":"mmp,没怎么看,不知道怎么形容",
-
"tags":["造数据", "真","难"]
-
}
-
-
-
PUT zhifou/_doc/4
-
{
-
"name":"石头",
-
"age":29,
-
"from":"gu",
-
"desc":"粗中有细,狐假虎威",
-
"tags":["粗", "大","猛"]
-
}
-
-
PUT zhifou/_doc/5
-
{
-
"name":"魏行首",
-
"age":25,
-
"from":"广云台",
-
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
-
"tags":["闭月","羞花"]
-
}
Bucket Aggregations 的api 介绍
下面例子使用 term是 进行分桶

分组查询
现在我想要查询所有人的年龄段,并且按照15~20,20~25,25~30分组,并且算出每组的平均年龄。
分析需求,首先我们应该先把分组做出来。
-
GET zhifou/_search
-
{
-
"size": 0,
-
"query": {
-
"match_all": {}
-
},
-
"aggs": {
-
"age_group": {
-
"range": {
-
"field": "age",
-
"ranges": [
-
{
-
"from": 15,
-
"to": 20
-
},
-
{
-
"from": 20,
-
"to": 25
-
},
-
{
-
"from": 25,
-
"to": 30
-
}
-
]
-
}
-
}
-
}
-
}
Metric Aggregations 的api 介绍
1 Avg Aggregation #计算出字段平均值
做聚合分析,应该讲size 设置为0,否则会返回查询结果。写20,aggs的相关结果会出现在比较后面而已
现在的需求是查询from是gu的人的平均年龄。
-
POST zhifou/_search
-
{
-
"size": 0,
-
"query": {
-
"match": {
-
"from": "gu"
-
}
-
},
-
"aggs": {
-
"age_ave": {
-
"avg": {
-
"field": "age"
-
}
-
}
-
}
-
}
上例中,首先匹配查询from是gu的数据。在此基础上做查询平均值的操作,这里就用到了聚合函数,其语法被封装在aggs中,而age_ave则是为查询结果起个别名,封装了计算出的平均值。那么,要以什么属性作为条件呢?是age年龄,查年龄的什么呢?是avg,查平均年龄。
2 Max Aggregation #求最大值
-
GET zhifou/_search
-
{
-
"aggs": {
-
"my_max": {
-
"max": {
-
"field": "age"
-
}
-
}
-
},
-
"size": 0
-
}
3 Min Aggregation #求最小值
-
GET zhifou/_search
-
{
-
"aggs": {
-
"my_min": {
-
"min": {
-
"field": "age"
-
}
-
}
-
},
-
"size": 0
-
}
4 Sum Aggregation #求和
-
"aggs" : {
-
"intraday_return" : { "sum" : { "field" : "change" } }
-
}
5 Stats Aggregation #最大、最小、和、平均值。一起求出来
-
GET zhifou/_search
-
{
-
"aggs": {
-
"my_stats": {
-
"stats": {
-
"field": "age"
-
}
-
}
-
},
-
"size": 0
-
}
6 Extended Stats Aggregation #字段的其他属性,包括最大最小,方差等等。
-
GET zhifou/_search
-
{
-
"aggs": {
-
"my_extended_stats": {
-
"extended_stats": {
-
"field": "age"
-
}
-
}
-
},
-
"size": 0
-
}
7 Cardinality Aggregation#计算出字段的唯一值。相当于sql中的distinct
-
{
-
"aggs" : {
-
"author_count" : {
-
"cardinality" : {
-
"field" : "author"
-
}
-
}
-
}
-
}
8 Geo Bounds Aggregation
计算出所有的地理坐标将会落在一个矩形区域。比如说朝阳区域有很多饭店,我就可以用一个矩形把这些饭店都圈起来,看看范围。
-
{
-
"query" : {
-
"match" : { "business_type" : "shop" }
-
},
-
"aggs" : {
-
"viewport" : {
-
"geo_bounds" : {
-
"field" : "location",
-
"wrap_longitude" : true
-
}
-
}
-
}
-
}
9 Geo Centroid Aggregation
计算出所有文档的大概的中心点。比如说某个地区盗窃犯罪很多,那我这样就可以看到这片区域到底哪个点(街道)偷盗事件最猖狂。
-
{
-
"query" : {
-
"match" : { "crime" : "burglary" }
-
},
-
"aggs" : {
-
"centroid" : {
-
"geo_centroid" : {
-
"field" : "location"
-
}
-
}
-
}
-
}
10 Percentiles Aggregation
百分比统计。可以看出你网站的所有页面。加载时间的差异
-
{
-
"aggs" : {
-
"load_time_outlier" : {
-
"percentiles" : {
-
"field" : "load_time"
-
}
-
}
-
}
-
}
11 Percentile Ranks Aggregation
看看15毫秒和30毫秒内大概有多少页面加载完。
-
{
-
"aggs" : {
-
"load_time_outlier" : {
-
"percentile_ranks" : {
-
"field" : "load_time",
-
"values" : [15, 30]
-
}
-
}
-
}
-
}
12 Top hits Aggregation
-
{
-
"aggs": {
-
"top-tags": {
-
"terms": {
-
"field": "tags",
-
"size": 3
-
},
-
"aggs": {
-
"top_tag_hits": {
-
"top_hits": {
-
"sort": [
-
{
-
"last_activity_date": {
-
"order": "desc"
-
}
-
}
-
],
-
"_source": {
-
"include": [
-
"title"
-
]
-
},
-
"size" : 1
-
}
-
}
-
}
-
}
-
}
-
}
13 alue Count Aggregation #数量统计,看看这个字段一共有多少个不一样的数值。
-
{
-
"aggs" : {
-
"grades_count" : { "value_count" : { "field" : "grade" } }
-
}
-
}
嵌套
在kabana导入 航空信息
-
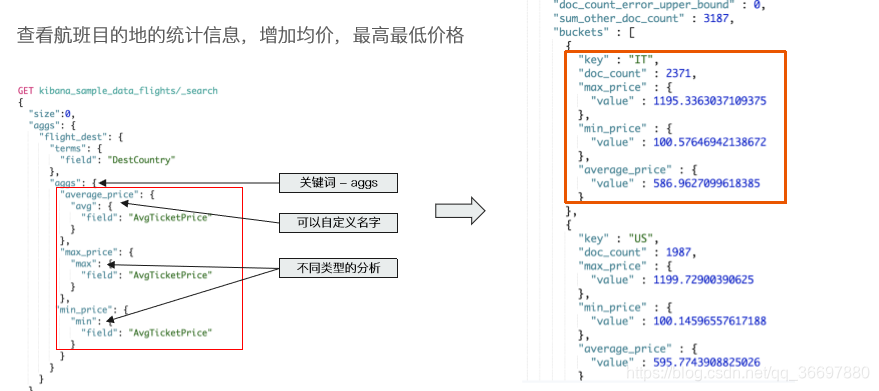
#查看航班目的地的统计信息,增加平均,最高最低价格
-
GET kibana_sample_data_flights/_search
-
{
-
"size": 0,
-
"aggs":{
-
"flight_dest":{
-
"terms":{
-
"field":"DestCountry"
-
},
-
"aggs":{
-
"avg_price":{
-
"avg":{
-
"field":"AvgTicketPrice"
-
}
-
},
-
"max_price":{
-
"max":{
-
"field":"AvgTicketPrice"
-
}
-
},
-
"min_price":{
-
"min":{
-
"field":"AvgTicketPrice"
-
}
-
}
-
}
-
}
-
}
-
}
-
-
#价格统计信息+天气信息
-
GET kibana_sample_data_flights/_search
-
{
-
"size": 0,
-
"aggs":{
-
"flight_dest":{
-
"terms":{
-
"field":"DestCountry"
-
},
-
"aggs":{
-
"stats_price":{
-
"stats":{
-
"field":"AvgTicketPrice"
-
}
-
},
-
"wather":{
-
"terms": {
-
"field": "DestWeather",
-
"size": 5
-
}
-
}
-
-
}
-
}
-
}
-
}
Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation的更多相关文章
- Elasticsearch7.X 入门学习第一课笔记----基本概念
原文:Elasticsearch7.X 入门学习第一课笔记----基本概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https: ...
- Elasticsearch7.X 入门学习第二课笔记----基本api操作和CRUD
原文:Elasticsearch7.X 入门学习第二课笔记----基本api操作和CRUD 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链 ...
- Es学习第九课, 聚合查询和复合查询
ES除了实现前几课的基本查询,也可以实现类似关系型数据库的聚合查询,如平均值sum.最小值min.最大值max等等 我们就用上一课的数据作为参考来举例 聚合查询 sum聚合 sum是一个求累加值的聚合 ...
- Elasticsearch7.X 入门学习第八课笔记-----索引模板和动态模板
原文:Elasticsearch7.X 入门学习第八课笔记-----索引模板和动态模板 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接: ...
- Elasticsearch7.X 入门学习第七课笔记-----Mapping多字段与自定义Analyzer
原文:Elasticsearch7.X 入门学习第七课笔记-----Mapping多字段与自定义Analyzer 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处 ...
- Elasticsearch7.X 入门学习第五课笔记---- - Mapping设定介绍
原文:Elasticsearch7.X 入门学习第五课笔记---- - Mapping设定介绍 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本 ...
- Elasticsearch7.X 入门学习第四课笔记---- Search API之(Request Body Search 和DSL简介)
原文:Elasticsearch7.X 入门学习第四课笔记---- Search API之(Request Body Search 和DSL简介) 版权声明:本文为博主原创文章,遵循CC 4.0 BY ...
- Elasticsearch7.X 入门学习第三课笔记----search api学习(URI Search)
原文:Elasticsearch7.X 入门学习第三课笔记----search api学习(URI Search) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出 ...
- iOS 阶段学习第九天笔记(内存管理)
iOS学习(C语言)知识点整理 一.内存管理 1)malloc , 用于申请内存; 结构void *malloc(size_t),需要引用头文件<stdlib.h>:在堆里面申请内存,si ...
随机推荐
- zabbix监控A主机到B主机的网络质量
采用zabbix自带的icmp ping即可进行监控: 1.安装fping 2.将fping安装后链接到/usr/sbin/fping下,设置组为zabbix; 3.增加监控项:icmpping[ip ...
- 【leetcode】1104. Path In Zigzag Labelled Binary Tree
题目如下: In an infinite binary tree where every node has two children, the nodes are labelled in row or ...
- Spring源码构建
1.下载spring源码并解压 https://codeload.github.com/spring-projects/spring-framework/zip/v5.0.2.RELEASE 打开bu ...
- 错误: 找不到或无法加载主类 org.sang.BlogserverApplication
错误: 找不到或无法加载主类 org.sang.BlogserverApplication
- mybatis动态update语句
- Android and HTML5 开发手机应用(转载)
作为一个WEB开发者,HTML5让我兴奋,因为它可以将桌面应用程序功能带入浏览器中.但在国内,看着到处横行的IE8版本以下的浏览器,觉得到能大规模使用HTML5技术的那天,还遥遥无期.但面对iOS及A ...
- 学习日记15-1布局页同时引用多个model
@model Tuple<model1,model2> mvc布局页同时引用多个model 使用m.Item1.xxx m.Item2.xxx
- [CSP-S模拟测试]:超级树(DP)
题目传送门(内部题5) 输入格式 一行两个整数$k$.$mod$,意义见上. 输出格式 一行一个整数,代表答案. 样例 样例输入1: 2 100 样例输出1: 样例输入2: 3 1000 样例输出2: ...
- postgresql获取表最后更新时间(通过表磁盘存储文件时间)
一.创建获取表更新时间的函数 --获取表记录更新时间(通过表磁盘存储文件时间) create or replace function table_file_access_info( IN schema ...
- Matlab 读取文件夹里所有的文件
(image = dir('D:\gesture\*.*'); % dir是指定文件夹得位置,他与dos下的dir用法相同. 用法有三种: 1. dir 是指工作在当前文件夹里 2. dir name ...