Spark在MaxCompute的运行方式
一、Spark系统概述
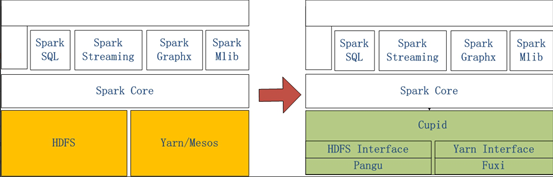
左侧是原生Spark的架构图,右边Spark on MaxCompute运行在阿里云自研的Cupid的平台之上,该平台可以原生支持开源社区Yarn所支持的计算框架,如Spark等。
二、Spark运行在客户端的配置和使用
2.1打开链接下载客户端到本地
2.2将文件上传的ECS上
2.3将文件解压
tar -zxvf spark-2.3.0-odps0.30.0.tar.gz

2.4配置Spark-default.conf
# spark-defaults.conf
# 一般来说默认的template只需要再填上MaxCompute相关的账号信息就可以使用Spark
spark.hadoop.odps.project.name =
spark.hadoop.odps.access.id =
spark.hadoop.odps.access.key =
# 其他的配置保持自带值一般就可以了
spark.hadoop.odps.end.point = http://service.cn.maxcompute.aliyun.com/api
spark.hadoop.odps.runtime.end.point = http://service.cn.maxcompute.aliyun-inc.com/api
spark.sql.catalogImplementation=odps
spark.hadoop.odps.task.major.version = cupid_v2
spark.hadoop.odps.cupid.container.image.enable = true
spark.hadoop.odps.cupid.container.vm.engine.type = hyper
2.5在github上下载对应代码
https://github.com/aliyun/MaxCompute-Spark
2.5将代码上传到ECS上进行解压
unzip MaxCompute-Spark-master.zip
2.6将代码打包成jar包(确保安装Maven)
cd MaxCompute-Spark-master/spark-2.x
mvn clean package
2.7查看jar包,并进行运行
bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \
MaxCompute-Spark-master/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
三、Spark运行在DataWorks的配置和使用
3.1进入DataWorks控制台界面,点击业务流程
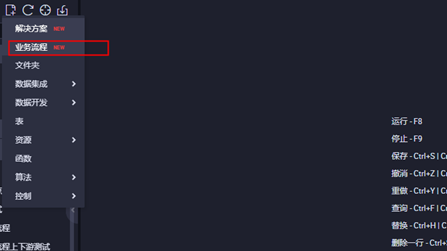
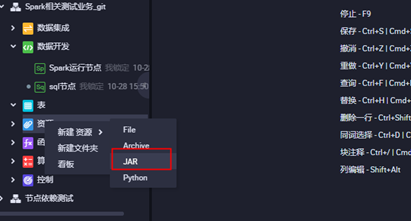
3.2打开业务流程,创建ODPS Spark节点
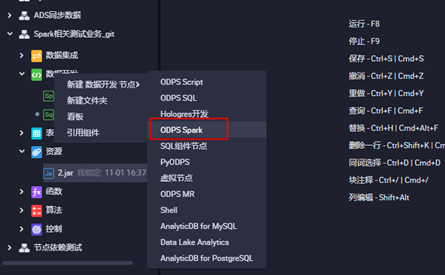
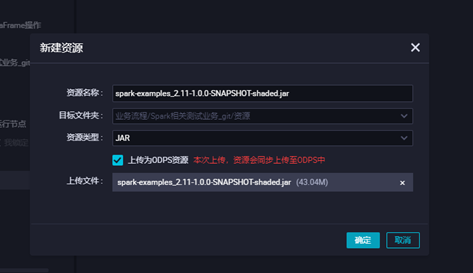
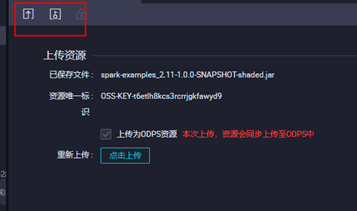
3.3上传jar包资源,点击对应的jar包上传,并提交
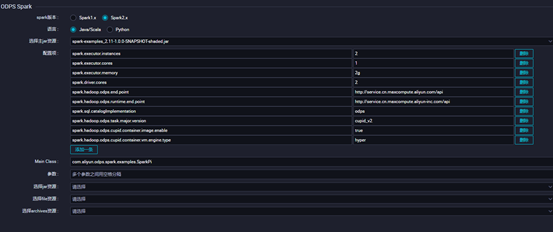
3.4配置对应ODPS Spark的节点配置点击保存并提交,点击运行查看运行状态
四、Spark在本地idea测试环境的使用
4.1下载客户端与模板代码并解压
模板代码:
https://github.com/aliyun/MaxCompute-Spark
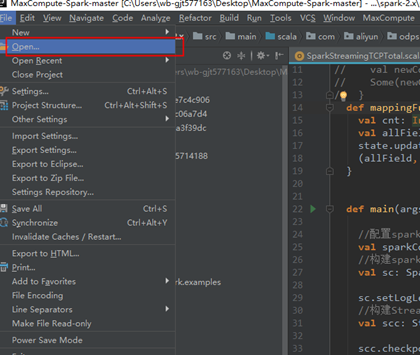
4.2打开idea,点击Open选择模板代码
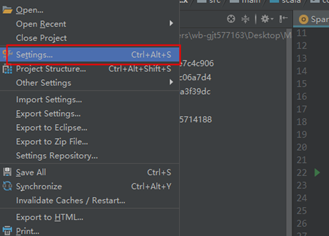
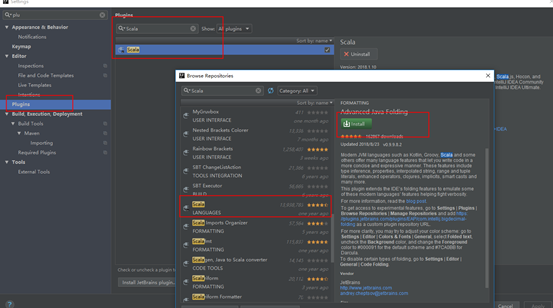
4.2安装Scala插件
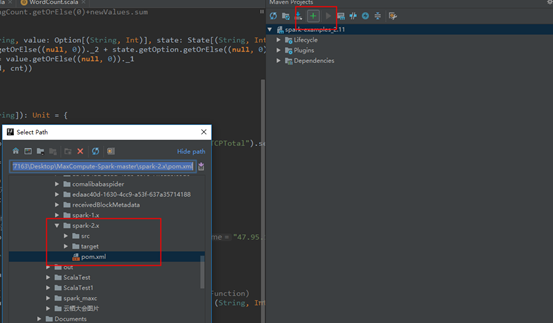
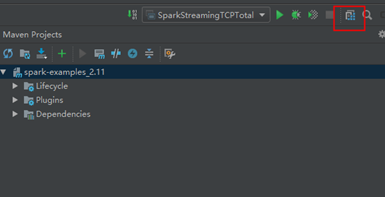
4.3配置maven
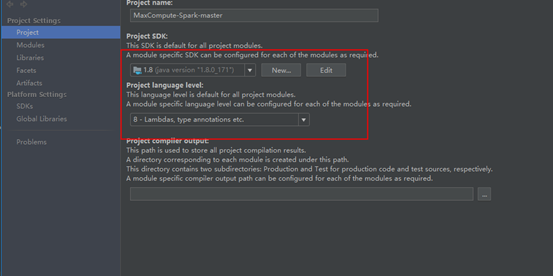
4.4配置JDK和相关依赖
本文作者:耿江涛
本文为云栖社区原创内容,未经允许不得转载。
Spark在MaxCompute的运行方式的更多相关文章
- 「Spark」Spark SQL Thrift Server运行方式
Spark SQL可以使用JDBC/ODBC或命令行接口充当分布式查询引擎.这种模式,用户或者应用程序可以直接与Spark SQL交互,以运行SQL查询,无需编写任何代码. Spark SQL提供两种 ...
- MaxCompute Spark开发指南
0. 概述 本文档面向需要使用MaxCompute Spark进行开发的用户使用.本指南主要适用于具备有Spark开发经验的开发人员. MaxCompute Spark是MaxCompute提供的兼容 ...
- MaxCompute问答整理之7月
本文是基于本人对MaxCompute产品的学习进度,再结合开发者社区里面的一些问题,进而整理成文.希望对大家有所帮助. 问题一.DataWorks V2.0简单模式和标准模式的区别?公司数仓的数据上云 ...
- 阿里云大数据计算服务 - MaxCompute (原名 ODPS)
MaxCompute 是阿里EB级计算平台,经过十年磨砺,它成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务.去年MaxCompute 做了哪些工作,这些工作背后的原因是什么?大数据市场进入 ...
- 一文快速了解MaxCompute
很多刚初次接触MaxCompute的用户,面对繁多的产品文档内容以及社区文章,往往很难快速.全面了解MaxCompute产品全貌.同时,很多拥有大数据开发经验的开发者,也希望能够结合自身的背景知识,将 ...
- spark学习(基础篇)--(第三节)Spark几种运行模式
spark应用执行机制分析 前段时间一直在编写指标代码,一直采用的是--deploy-mode client方式开发测试,因此执行没遇到什么问题,但是放到生产上采用--master yarn-clus ...
- 【互动问答分享】第10期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第10期互动问答分享] Q1:Spark on Yarn的运行方式是什么? Spark on Yarn的运行方式有两种:Client ...
- Hive数据如何同步到MaxCompute之实践讲解
摘要:本次分享主要介绍 Hive数据如何迁移到MaxCompute.MMA(MaxCompute Migration Assist)是一款MaxCompute数据迁移工具,本文将为大家介绍MMA工具的 ...
- MaxCompute新功能发布
2018年Q3 MaxCompute重磅发布了一系列新功能. 本文对主要新功能和增强功能进行了概述. 实时交互式查询:Lightning on MaxCompute 生态兼容:Spark on Max ...
随机推荐
- spring map获取同类型的bean
今天看博客怎么减少if else 方法, 才发现spring 还有很多功能我没有用到,以后真的得花时间学学spring,今天学到的东西如下: 1.定义一个接口 store public interfa ...
- 学习《Oracle PL/SQL 实例讲解 原书第5版》----创建账户
通过readme.pdf创建student账户. 以下用sys账户登录时都是sysdba. 一.PL/SQL 登录oracle. SYS/123 AS SYSDBA 账户名:sys:密码:123:作 ...
- 浅谈Java反射机制 之 使用类的 属性、方法和构造函数
前面两篇我们总结了Java反射机制如何获取类的字节码,如何获取构造函数,属性和方法, 这篇我们将进一步验证如何使用我们获取到的属性.方法以及构造函数 1.使用 反射 获取到的 属性 import ja ...
- 2019春第十一周作业Compile Summarize
这个作业属于那个课程 C语言程序设计II 这个作业要求在哪里 这里 我在这个课程的目标是 能按自己的想法解出题目 这个作业在那个具体方面帮助我实现目标 能朝着软件工程师方向发展 参考文献与网址 C语言 ...
- 配置Trunk接口
实验内容 本实验模拟某公司网络场景.公司规模较大,员工200余名,内部网络是-一个大的局域网.公司放置了多台接入交换机(如S1和S2)负责员工的网络接入.接入交换机之间通过汇聚交换机S3相连.公司通过 ...
- SpringMvc错误:HTTP Status 500 - Request processing failed; nested exception is org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.reflection.ReflectionException: There is n
HTTP Status 500 - Request processing failed; nested exception is org.mybatis.spring.MyBatisSystemExc ...
- [常用类]Number & Math 类(转载)
下面的表中列出的是 Number & Math 类常用的一些方法: 序号 方法与描述 1 xxxValue() 将 Number 对象转换为xxx数据类型的值并返回. 2 compareTo( ...
- [常用类]StringBuffer 类,以及 StringBuilder 类
线程安全,可变的字符序列. 字符串缓冲区就像一个String ,但可以修改. 在任何时间点,它包含一些特定的字符序列,但可以通过某些方法调用来更改序列的长度和内容. 字符串缓冲区可以安全地被多个线程使 ...
- 问题 B: 傻鸡抓大闸蟹
问题 B: 傻鸡抓大闸蟹 时间限制: 1 Sec 内存限制: 128 MB提交: 94 解决: 39[提交] [状态] [命题人:jsu_admin] 题目描述 背景又到了吃大闸蟹的季节,黄老师想 ...
- hihocoder1954 : 压缩树
传送门 首先求出缩一个点 $x$ 的贡献,就是缩 $x$ 的父亲的贡献加上 $x$ 的子树多减少的深度 假设此时缩父亲的贡献已经考虑过了,那么 $x$ 的子树多减少的深度就是子树的节点数 注意此时要满 ...