C++ traits技法的一点理解
为了更好的理解traits技法。我们一步一步的深入。先从实际写代码的过程中我们遇到诸如下面伪码说起。
template< typename T,typename B>
void (T a,B c){
if(变量a 属于类型b){
//执行相应的代码
a+=c;
} else if(变量a 属于类型c){
//执行相应的代码
a-=c;
}
}
虽然这样的代码可以执行。但是有一点不好的地方:
(1)变量a的类型是在运行期间才会知道的。这样就会导致if和else if对应的执行代码都会编译到可执行文件中,导致编译后代码量增大。
为了更好的理解上述缺点。我们首先引入一段代码(必须看明白了 否则后面的不好理解了)。来说明上述代码是在运行时刻才会知道变量的类型的。
#include<iostream>
using namespace std; //声明两种类类型
struct Typeone{
//判断是否是该类类型
static const int typeFlag = ;
};
struct Typetwo{
//判断是否是该类类型
static const int typeFlag = ;
};
/****************文字解释的地方*****************/
template< typename T >
void _func(T a ){
if( == a.typeFlag ){ //@ 在运行期间才会确定a是哪个类型。
cout<<"接下来是任务1要做的事!"<<endl;
//具体要执行的代码
}
else if( == a.typeFlag ){ //@ 在运行期间才会确定a是哪个类型。
cout<<"接下来是任务2要做的事情!"<<endl;
//具体要执行的代码
} }
/*************************************************/ //主函数
int main(int argc ,char ** argv)
{
Typeone b;
Typetwo d;
_func( b );
_func( d ); return ;
}
上述代码运行结果:
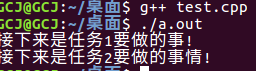
正如代码中标记@ 这个符号的地方所写。变量a是在运行期间通过if的判断才会确定a是哪个类型。虽然我们知道模板函数会对变量a的类型进行推导。也就是说在编译时刻就会把a推导为相应的类型。但是a.typeFlag与1的比较是在运行期,取出a.typeFlag变量的内容然后与1进行比较,当满足这个if条件后才会执行相应的代码。不知道你有没有发现一个问题。在编译程序的时候。if 和else if 对应的执行代码都会被编译到可执行文件中。这也就使得编译后的代码量增大。
上述代码和文字解释了最初那段伪码的缺点。为了解决上述问题我们有四个方案可供选择。
(1)直接函数重载
(2)声明内嵌类型或者叫做迭代器+函数重载
(3)Typeone和Typetwo类型以及内置类型转化为内嵌类型(普通迭代器)+函数重载
(4)traits技法 + 函数重载
先做一些准备工作,插入下面要说的名词代表的意思:
控制函数:
//控制函数(利用模板函数的参数推导功能)
template< typename T >
void _func(T a ){ //@@改变处
T b;
func(a,b);
}
Typeone类型对应的执行函数:
/*Typeone类型执行函数*/
template<typename T>
void func( T&t,Typeone ){
cout<<"接下来是Typeone要做的事!"<<endl;;
//具体要执行的代码
}
Typetwo类型对应的执行函数:
/*Typetwo类型执行函数*/
template<typename T>
void func( T&t,Typetwo ){
cout<<"接下来是Typetwo要做的事情!"<<endl;
//具体要执行的代码
}
int类型对应的执行函数:
/*int 类型执行函数*/
template<typename T>
void func(T&t,int){
cout<<"接下来是int要做的事情!"<<endl;
//具体要执行的代码
}
好了接下来进入正题。首先举一个例子来说明第一种方法:将上面代码修改为三个重载的模板函数,外加一个控制这些函数的模板函数即控制函数。如下代码以及运行结果图:
方法(1):直接函数重载:
#include<iostream>
using namespace std;
/*************************第二段代码***********************/
//声明两种类类型
struct Typeone{
//判断是否是该类类型
static const int typeFlag = ;
};
struct Typetwo{
//判断是否是该类类型
static const int typeFlag = ;
};
/*******************相比第一段代码更改处**********************/
//不同的重载函数
/*Typeone类型执行函数*/
template<typename T>
void func( T&t,Typeone ){
cout<<"接下来是Typeone要做的事!"<<endl;;
//具体要执行的代码
} /*Typetwo类型执行函数*/
template<typename T>
void func( T&t,Typetwo ){
cout<<"接下来是Typetwo要做的事情!"<<endl;
//具体要执行的代码
} /*int 类型执行函数*/
template<typename T>
void func(T&t,int){
cout<<"接下来是int要做的事情!"<<endl;
//具体要执行的代码
} //控制函数(利用模板函数的参数推导功能)
template< typename T >
void _func(T a ){ //@@改变处
T b;
func(a,b);
}
/*************************************************/ //主函数
int main(int argc ,char ** argv)
{
Typeone b;
Typetwo d;
int c; _func( b );
_func( d );
_func(c); return ;
}
上述代码运行结果图:
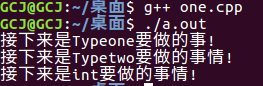
从代码上可以看出,在main主函数中,当我们分别输入Typeone、Typetwo、 int类型的变量时,都会通过控制重载函数去执行相应的函数,这样一来我们在编译的时刻就会减少了很多的代码(利用重载函数),并且在编译时刻就会知道控制函数中变量a b的类型(利用模板函数的参数类型推导功能)。到了这里就结束了吗?当然不是,如果到了这里就结束的话题目就没有必要说traits技法了。慢慢来。我们在更进一步的说明。从上面的代码可以看出,它对于内置类型和类类型还是有很强的适应性。试想一下。如果我们的需求变了,当我们要求控制函数_func()输入一个迭代器类型的变量,然后它对应的执行函数是迭代器内部类型对应的执行函数。比如myiterator<int> a ,我们要求_func(a)执行int类型对应的func()函数。目前的代码是不能够适应这个需求的。比如下面折叠的代码中就会出现编译错误,注意看主函数中增加的部分以及相比第二段代码更改处(代码中已标记),(因为e是一个迭代器,所以控制函数中T推导为myiterator<int>类型。然后调用函数func(a,b)时候,因为没有这种重载函数会编译出错,而且它本身也不符合我们要求的那样去调用int对应的执行函数)。错误代码如下:
#include<iostream>
using namespace std;
/*************************第三段代码***********************/
//声明两种类类型
struct Typeone{
//判断是否是该类类型
static const int typeFlag = ;
};
struct Typetwo{
//判断是否是该类类型
static const int typeFlag = ;
};
/*******************相比第二段代码更改处**********************/
template<typename T>
struct myiterator{
typedef T type;
};
/*************************************************/ //不同的重载函数
/*Typeone类型执行函数*/
template<typename T>
void func( T&t,Typeone ){
cout<<"接下来是Typeone要做的事!"<<endl;;
//具体要执行的代码
} /*Typetwo类型执行函数*/
template<typename T>
void func( T&t,Typetwo ){
cout<<"接下来是Typetwo要做的事情!"<<endl;
//具体要执行的代码
} /*int 类型执行函数*/
template<typename T>
void func(T&t,int){
cout<<"接下来是int要做的事情!"<<endl;
//具体要执行的代码
} //控制函数(利用模板函数的参数推导功能)
template< typename T >
void _func(T a ){ //@@改变处
T b;
func(a,b);
} //主函数
int main(int argc ,char ** argv)
{
Typeone b;
Typetwo d;
int c;
myiterator<int> e; //增加的部分 _func( b );
_func( d );
_func(c);
_func(e); //增加的部分 return ;
}
针对上面的错误代码,那么有没有其他方法能够解决呢?我们传统的思想是在控制函数内部在加一层判断是不是迭代器类型,之后在调用迭代器内部类型对应的执行函数。那么这样不仅是回到了原来伪码出现的问题(编译后的代码量会增加)。而且还修改了控制函数本身的结构。这破坏了控制函数代码的封装性(因为每加入一种类型就要变动函数内部的写法,这本身不符合函数封装性,而且影响了函数内部算法本身的适应性)。那么我们该如何更改呢?看了上述错误代码后你可能会想,我可以把控制函数内的T b 变为typename T::type_category b 这样就能很好的解决了上述的额外要求了!比如下面的折叠代码(主要看控制函数部分):
#include<iostream>
using namespace std;
/*************************第三段代码***********************/
//声明两种类类型
struct Typeone{
//判断是否是该类类型
static const int typeFlag = ;
};
struct Typetwo{
//判断是否是该类类型
static const int typeFlag = ;
};
/*******************相比第二段代码更改处**********************/
//迭代器或者内嵌类型
template<typename T>
struct myiterator{
typedef T type_category;
};
/*************************************************/ //不同的重载函数
/*Typeone类型执行函数*/
template<typename T>
void func( T&t,Typeone ){
cout<<"接下来是Typeone要做的事!"<<endl;;
//具体要执行的代码
} /*Typetwo类型执行函数*/
template<typename T>
void func( T&t,Typetwo ){
cout<<"接下来是Typetwo要做的事情!"<<endl;
//具体要执行的代码
} /*int 类型执行函数*/
template<typename T>
void func(T&t,int){
cout<<"接下来是int要做的事情!"<<endl;
//具体要执行的代码
} //控制函数(利用模板函数的参数推导功能)
template< typename T >
void _func(T a ){ //@@改变处
typename T::type_category b;
// T b;
func(a,b);
} //主函数
int main(int argc ,char ** argv)
{
Typeone b;
Typetwo d;
int c;
myiterator<int> e; /*相比第三段代码更改处*/
_func( b ); //注释掉
_func( d );
_func(c);
_func(e); return ;
}
但是这样真的能行吗?上面的代码也是会编译错误的。因为在主函数中Typeone Typetwo int 这三个类型的变量当调用控制函数_func()的时候。他们没有T::type_category这种形式。所以会编译错误。当我们注释掉主函数中_func(b)、_func(d)、_func(c)的时候,可以看出结果确实按照我们的要求执行int类型的执行函数了。注释后的代码以及运行结果如下:
这也是方法(2)声明内嵌类型或者叫做迭代器+函数重载
#include<iostream>
using namespace std;
/*************************第三段代码***********************/
//声明两种类类型
struct Typeone{
//判断是否是该类类型
static const int typeFlag = ;
};
struct Typetwo{
//判断是否是该类类型
static const int typeFlag = ;
};
/*******************相比第二段代码更改处**********************/
//迭代器或者内嵌类型
template<typename T>
struct myiterator{
typedef T type_category;
};
/*************************************************/ //不同的重载函数
/*Typeone类型执行函数*/
template<typename T>
void func( T&t,Typeone ){
cout<<"接下来是Typeone要做的事!"<<endl;;
//具体要执行的代码
} /*Typetwo类型执行函数*/
template<typename T>
void func( T&t,Typetwo ){
cout<<"接下来是Typetwo要做的事情!"<<endl;
//具体要执行的代码
} /*int 类型执行函数*/
template<typename T>
void func(T&t,int){
cout<<"接下来是int要做的事情!"<<endl;
//具体要执行的代码
} //控制函数(利用模板函数的参数推导功能)
template< typename T >
void _func(T a ){ //@@改变处
typename T::type_category b;
// T b;
func(a,b);
} //主函数
int main(int argc ,char ** argv)
{
Typeone b;
Typetwo d;
int c;
myiterator<int> e; /*相比第三段代码更改处*/
//_func( b ); //注释掉
//_func( d );
//_func(c);
_func(e); return ;
}
上述代码运行结果图:
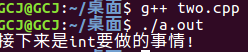
到了这里你也会发现方法(2)本身仅仅满足了迭代器类型的要求,对于传统内置类型却无能为力。而方法(1)解决了传统的内置类型,但是对迭代器类型也是无能为力。那么还有没有什么方法可以结合两种方法呢?方法(3)很好的解决了这个问题。
方法(3):Typeone和Typetwo类型以及内置类型转化为内嵌类型(普通迭代器)+函数重载
我们把所有基本类型以及自定义的类类型都用内嵌类型来表达,统一接口,都用myiterator<Typeone> b 这种方式来定义变量,然后在控制函数内部,定义变量b的时候修改为:typename T::type_category。这样是可以解决上面的问题的,如下代码以及运行结果图:
#include<iostream>
using namespace std;
/*************************第三段代码***********************/
//声明两种类类型
struct Typeone{};
struct Typetwo{};
/*******************相比第二段代码更改处**********************/
template<typename T>
struct myiterator{
typedef T type_category;
};
/*************************************************/ //不同的重载函数
/*Typeone类型执行函数*/
template<typename T>
void func( T&t,Typeone ){
cout<<"接下来是Typeone要做的事!"<<endl;;
//具体要执行的代码
} /*Typetwo类型执行函数*/
template<typename T>
void func( T&t,Typetwo ){
cout<<"接下来是Typetwo要做的事情!"<<endl;
//具体要执行的代码
} /*int 类型执行函数*/
template<typename T>
void func(T&t,int){
cout<<"接下来是int要做的事情!"<<endl;
//具体要执行的代码
} //控制函数(利用模板函数的参数推导功能)
template< typename T >
void _func(T a ){ //@@改变处
typename T::type_category b;
// T b;
func(a,b);
} //主函数
int main(int argc ,char ** argv)
{
//Typeone b;
//Typetwo d;
//int c;
/*相比第三段更改处,上面的类型用内嵌类型来表达*/
myiterator<Typeone>b;
myiterator<Typetwo>d;
myiterator<int >c;
myiterator<int> e; _func( b );
_func( d );
_func(c);
_func(e); return ;
}
上述代码运行结果图:
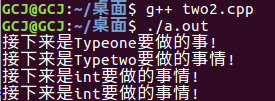
看了上面的代码,你有没有发现其实这样有一点不好,那就是我们在写代码的时候,对于这种方式:myiterator<Typeone>b,Typeone是想要的类型。调用函数_func()之前我们还要有意识的用上面的那种方式定义一个变量。即:
myiterator<Typeone>b;
_func(b)
那就是说这种函数本身的封装性能做的不好,不符合我们平时调用函数的习惯。重要的是我们之前没有考虑指针类型。那么对于指针类型,也就是说当我们要求对于输入int *这种指针类型变量时,对应要执行指针指向类型的执行函数,即:
int * b;
_func(b);
之后_func()函数会自动的调用int类型的执行函数。那么方法(3)也是无法做到的。只能通过在控制函数中添加一层判断语句才可以(这样又会导致了编译后代码量增大)。那么有没有两全其美的方法呢?那就是本文所说的traits技法。
方法(4):traits技法 + 函数重载
通过对指针类型做一个特化的版本(这是内嵌类型所不能做到的),如下面的代码和结果图(代码测试中加入了上面那部分代码所做的事情如:myiterator<Typeone> g;_func(g);这种不推荐的做法。目的是为了跟这种方式作比较Typeone b;_func(b);两种方法都能够执行相同的函数。但是traits技法更具封装性。符合我们调用代码的习惯。而且更重要的是下面的代码比上面的代码适应了指针类型。下面会有说明。):
#include<iostream>
using namespace std;
/*************************第三段代码*************************/
//声明两种类类型
struct Typeone{};
struct Typetwo{}; /*******************相比第二段代码更改处**********************/
//迭代器类型也叫做内嵌类型
template<typename T>
struct myiterator{
typedef T type_category;
};
/************************************************************/ /*******************相比第三段代码更改处**********************/ /***********特性萃取器-----------迭代器类型************/
template<typename unknown_type>
struct mytraits{
typedef typename unknown_type::type_category type_category;
};
/***********特性萃取器偏特化-----指针类型****************/
template<typename unknown_type>
struct mytraits<unknown_type *>{
typedef unknown_type type_category;
};
/***********特性萃取器偏特化-----常量指针类型************/
template<typename unknown_type>
struct mytraits<const unknown_type *>{
typedef const unknown_type type_category;
};
/***********特性萃取器特化-------int类型*****************/
template<>
struct mytraits<int >{
typedef int type_category;
};
/************特性萃取器-----Typeone类型********************/
template<>
struct mytraits<Typeone>{
typedef Typeone type_category;
};
/************特性萃取器-----Typetwo类型********************/
template<>
struct mytraits<Typetwo>{
typedef Typetwo type_category;
}; /*************************************************/ //不同的重载函数
/*Typeone类型执行函数*/
template<typename T>
void func( T&t,Typeone ){
cout<<"接下来是Typeone要做的事!"<<endl;;
//具体要执行的代码
} /*Typetwo类型执行函数*/
template<typename T>
void func( T&t,Typetwo ){
cout<<"接下来是Typetwo要做的事情!"<<endl;
//具体要执行的代码
} /*int 类型执行函数*/
template<typename T>
void func(T&t,int){
cout<<"接下来是int要做的事情!"<<endl;
//具体要执行的代码
} //控制函数(利用模板函数的参数推导功能)
template< typename T >
void _func(T a ){ //@@改变处
// typename T::type b;
// T b;
//通过traits 提取类型信息 并定义一个变量
typename mytraits<T>::type_category b;
func(a,b);
} //主函数
int main(int argc ,char ** argv)
{
Typeone b;
Typetwo d;
int c;
myiterator<int> e;
int *f;
myiterator<Typeone>g; _func( b ); //1、输出Typeone对应的执行函数
_func( d ); //2、输出Typetwo对应的执行函数
_func(c); //3、输出int 对应的执行函数
_func(e); //4、会输出int 对应的执行函数
_func(f); //5、会输出int对应的执行函数
_func(g); //6、会输出Typeone对应的函数 return ;
}
上述代码运行结果图:
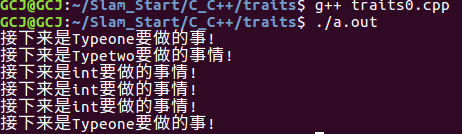
从代码中我们可以看出,相比方法(3)对应的代码,这里变动的地方就是多加了特性萃取器那部分的代码,然后在控制函数中,定义变量的时候用到了traits技术。实际上特性萃取器那部分的代码正是traits技法的核心,通过模板的特化(针对Typeone Typetwo int 等类型,其他类型也可以自己添加)和偏特化(int * 或者其他类型的指针类型),使其适应各种不同的类型变量。这里尤其说一下对于指针类型的说明。通过模板的偏特化当我们_func(指针变量如int*)的时候,在控制函数中通过模板的参数推导,在mytraits<T>::type_category中T被推导为了int *,通过特性提取。即对应mytraits模板类的偏特化--指针类型版本。使得mytraits<T>::type_category的类型为int ,所以在控制函数中变量b的类型就是int型,当调用func(a,b)的时候,我们仍然能够保持a的类型是指针类型int *,但是b是其指针指向的类型int。对于main函数中的Typeone Typetwo等等的类型,也是通过特性萃取器对应的特化版本来实现类型的提取。引用一篇博客的一句话:"当函数,类或者一些封装的通用算法中的某些部分会因为数据类型不同而导致处理或逻辑不同时,traits会是一种很好的解决方案。"。
总结:
对于上述伪码部分if else if带来的不好的地方,事先不知道变量的类型并且代码量会很多。我们用了函数重载以及模板函数的参数类型推导来解决了这个问题,但是当我们提出更高的要求时,控制函数本身算法不能动的前提下,我们想到了用内嵌类型将所有内置类型包装起来。也就是方法(3),但是又不符合我们平时调用函数的习惯。更重要的一点是内嵌类型或者说迭代器方法不能适用于指针类型就是方法(3)引用代码例子。为了更好的解决编译时刻即能确定类型。又能适应指针类型的要求时,我们引出了traits技术。优点是:编译时刻确定类型(而且能够确定 内置类型+指针类型+类类型) 并且结合重载函数可以在编译时刻确定具体要执行的代码。 也就是相当于#if #endif将需要的代码编译到可执行文件,其余无用的代码自动舍掉。通过上面的一步步的深入。你也就会明白这句话的意思了。如果上面某些话或者例子不对,希望读者留言。帮我加深对traits技法的理解。
参考资料:
1、http://www.cnblogs.com/mangoyuan/p/6446046.html
2、Effective C++
3、https://www.bbsmax.com/A/gAJGPLQX5Z/
4、http://blog.pfan.cn/rickone/32496.html
C++ traits技法的一点理解的更多相关文章
- 带你深入理解STL之迭代器和Traits技法
在开始讲迭代器之前,先列举几个例子,由浅入深的来理解一下为什么要设计迭代器. //对于int类的求和函数 int sum(int *a , int n) { int sum = 0 ; for (in ...
- opencv笔记5:频域和空域的一点理解
time:2015年10月06日 星期二 12时14分51秒 # opencv笔记5:频域和空域的一点理解 空间域和频率域 傅立叶变换是f(t)乘以正弦项的展开,正弦项的频率由u(其实是miu)的值决 ...
- 对socket的一点理解笔记
需要学web service,但是在视频中讲解到了socket套接字编程.以前貌似课上老师有提过,只是没用到也感觉乏味.现在遇到,自己看了些博客和资料.记录一点理解,不知正确与否. 首先说这个名字,叫 ...
- iOS 的一点理解(一) 代理delegate
做了一年的iOS,想记录自己对知识点的一点理解. 第一篇,想记录一下iOS中delegate(委托,也有人称作代理)的理解吧. 故名思议,delegate就是代理的含义, 一件事情自己不方便做,然后交 ...
- 关于web开发的一点理解
对于web开发上的一点理解 1 宏观上的一点理解 网页从请求第地址 到获得页面的过程:从客户端(浏览器)通过地址 从soket把请求报文封装发往服务端 服务端通过解析报文并处理报文最后把处理的结果 ...
- angular.js的一点理解
对angular.js的一点理解 2015-01-14 13:18 by MrGeorgeZhao, 317 阅读, 4 评论, 收藏, 编辑 最近一直在学习angular.js.不得不说和jquer ...
- C++中的Traits技法
Traits广泛应用于标准程序库.Traits classes使得"类型相关信息"在编译期可用. 认真读完下面的示例,你应该就懂了Traits技法,其实并不难. #include ...
- RxSwift 入坑好多天 - 终于有了一点理解
一.前言 江湖上都在说现在就要赶紧学 swift 了,即将是 swift 的天下了.在 api 变化不大的情况下,swift 作为一门新的语言,集众家之所长,普通编码确实比 oc 要好用的多了 老早就 ...
- rt-thread中动态内存分配之小内存管理模块方法的一点理解
@2019-01-18 [小记] rt-thread中动态内存分配之小内存管理模块方法的一点理解 > 内存初始化后的布局示意 lfree指向内存空闲区首地址 /** * @ingroup Sys ...
随机推荐
- 如何使用CSS3中的结构伪类选择器和伪元素选择器
结构伪类选择器介绍 结构伪类选择器是用来处理一些特殊的效果. 结构伪类选择器属性说明表 属性 描述 E:first-child 匹配E元素的第一个子元素. E:last-child 匹配E元素的最后一 ...
- Vue.js项目在apache服务器部署后,刷新404的问题
原因是vue-router 使用了路由的 history 模式,这种模式充分利用 history.pushState API 来完成 URL 跳转而无须重新加载页面. const router = n ...
- 《C++Primer》第五版习题答案--第一章【学习笔记】
C++Primer第五版习题解答---第一章 ps:答案是个人在学习过程中书写,可能存在错漏之处,仅作参考. 作者:cosefy Date: 2022/1/7 第一章:开始 练习1.3 #includ ...
- 密码 | 对称加密 - AES
一.AES 算法简介 高级加密标准(英语:Advanced Encryption Standard,缩写:AES),在密码学中又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准,用来替换 ...
- .Net Core - AgileHttp
2020年新年将至,先预祝.Net Core越来越好. 做了这么多年一线开发,经常跟Http打交道.比如调用三方的Webservice,比如集成微信支付的时候服务端发起Prepay支付.特别是现在分布 ...
- LinkedHashMap与HashMap的使用比较
现在由于项目需要,使用了LinkedHashMap,一开始由于很少用到Map,然后就直接使用了HashMap,在将数据成功存入之后取出来就出了问题,数据输出顺序没有按预期顺序输出,现在先看代码: 文件 ...
- KnockoutJs官网教程学习(一)
这一教程中你将会体验到一些用knockout.js和Model-View-ViewModel(MVVM)模式去创建一个Web UI的基础方式. 将学会如何用views(视图)和declarative ...
- Linux查看端口监听占用
# 查看所有 netstat -ntlp # 过滤PORT8080 netstat -ntlp | grep 8080 -t # 仅显示tcp相关选项 -u # 仅显示udp相关选项 -n # 拒绝显 ...
- 位运算上的小技巧 - AtCoder
Problem Statement There is an integer sequence of length 2N: A0,A1,…,A2N−1. (Note that the sequence ...
- MongoDB数据库备份和恢复
1.数据库备份 mogodbdump -h dbhost -d dbname -o dbdirectory -h: 服务器地址,也可以指定端口号 -d: 需要备份的数据库的名称 -o: 备份的数据库存 ...