JDK8 Stream 数据流效率分析
JDK8 Stream 数据流效率分析
Stream 是Java SE 8类库中新增的关键抽象,它被定义于 java.util.stream (这个包里有若干流类型: Stream<T> 代表对象引用流,此外还有一系列特化流,如 IntStream,LongStream,DoubleStream等 ),Java 8 引入的的Stream主要用于取代部分Collection的操作,每个流代表一个值序列,流提供一系列常用的聚集操作,可以便捷的在它上面进行各种运算。集合类库也提供了便捷的方式使我们可以以操作流的方式使用集合、数组以及其它数据结构;
stream 的操作种类
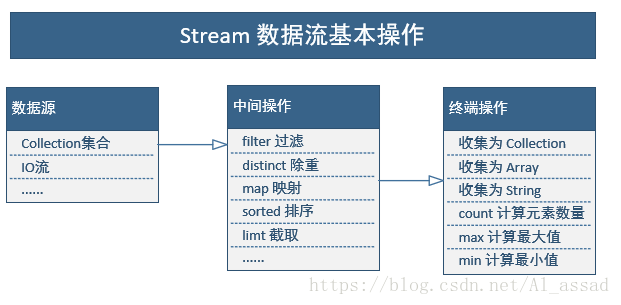
①中间操作
- 当数据源中的数据上了流水线后,这个过程对数据进行的所有操作都称为“中间操作”;
- 中间操作仍然会返回一个流对象,因此多个中间操作可以串连起来形成一个流水线;
- stream 提供了多种类型的中间操作,如 filter、distinct、map、sorted 等等;
②终端操作
- 当所有的中间操作完成后,若要将数据从流水线上拿下来,则需要执行终端操作;
- stream 对于终端操作,可以直接提供一个中间操作的结果,或者将结果转换为特定的 collection、array、String 等;
这一部分详细的说明可以参见:JDK8 Stream 详细使用
stream 的特点
①只能遍历一次:
数据流的从一头获取数据源,在流水线上依次对元素进行操作,当元素通过流水线,便无法再对其进行操作,可以重新在数据源获取一个新的数据流进行操作;
②采用内部迭代的方式:
对Collection进行处理,一般会使用 Iterator 遍历器的遍历方式,这是一种外部迭代;
而对于处理Stream,只要申明处理方式,处理过程由流对象自行完成,这是一种内部迭代,对于大量数据的迭代处理中,内部迭代比外部迭代要更加高效;
stream 相对于 Collection 的优点
- 无存储:流并不存储值;流的元素源自数据源(可能是某个数据结构、生成函数或I/O通道等等),通过一系列计算步骤得到;
- 函数式风格:对流的操作会产生一个结果,但流的数据源不会被修改;
- 惰性求值:多数流操作(包括过滤、映射、排序以及去重)都可以以惰性方式实现。这使得我们可以用一遍遍历完成整个流水线操作,并可以用短路操作提供更高效的实现;
- 无需上界:不少问题都可以被表达为无限流(infinite stream):用户不停地读取流直到满意的结果出现为止(比如说,枚举 完美数 这个操作可以被表达为在所有整数上进行过滤);集合是有限的,但流可以表达为无线流;
- 代码简练:对于一些collection的迭代处理操作,使用 stream 编写可以十分简洁,如果使用传统的 collection 迭代操作,代码可能十分啰嗦,可读性也会比较糟糕;
stream 和 iterator 迭代的效率比较
好了,上面 stream 的优点吹了那么多,stream 函数式的写法是很舒服,那么 steam 的效率到底怎样呢?
先说结论:
- 传统 iterator (for-loop) 比 stream(JDK8) 迭代性能要高,尤其在小数据量的情况下;
- 在多核情景下,对于大数据量的处理,parallel stream 可以有比 iterator 更高的迭代处理效率;
我分别对一个随机数列 List (数量从 10 到 10000000)进行映射、过滤、排序、规约统计、字符串转化场景下,对使用 stream 和 iterator 实现的运行效率进行了统计,测试代码 基准测试代码链接
测试环境如下:
System:Ubuntu 16.04 xenial
CPU:Intel Core i7-8550U
RAM:16GB
JDK version:1.8.0_151
JVM:HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
JVM Settings:
-Xms1024m
-Xmx6144m
-XX:MaxMetaspaceSize=512m
-XX:ReservedCodeCacheSize=1024m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=100
1. 映射处理测试
把一个随机数列(List<Integer>)中的每一个元素自增1后,重新组装为一个新的 List<Integer>,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
-
//stream
-
List<Integer> result = list.stream()
-
.mapToInt(x -> x)
-
.map(x -> ++x)
-
.boxed()
-
.collect(Collectors.toCollection(ArrayList::new));
-
//iterator
-
List<Integer> result = new ArrayList<>();
-
for(Integer e : list){
-
result.add(++e);
-
}
-
//parallel stream
-
List<Integer> result = list.parallelStream()
-
.mapToInt(x -> x)
-
.map(x -> ++x)
-
.boxed()
-
.collect(Collectors.toCollection(ArrayList::new));

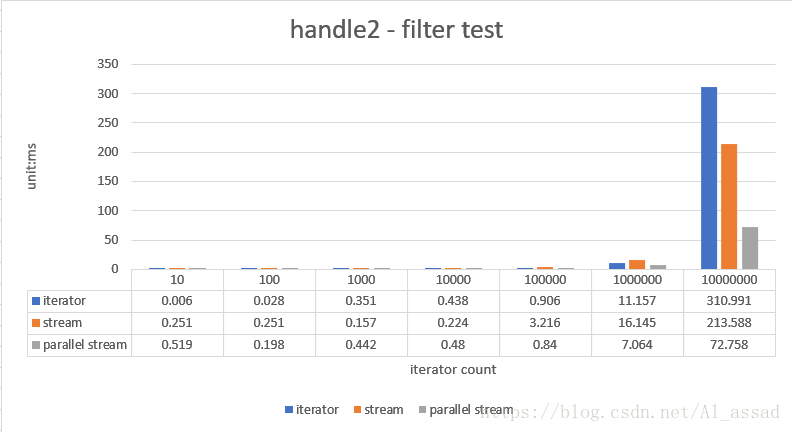
2. 过滤处理测试
取出一个随机数列(List<Integer>)中的大于 200 的元素,并组装为一个新的 List<Integer>,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
-
//stream
-
List<Integer> result = list.stream()
-
.mapToInt(x -> x)
-
.filter(x -> x > 200)
-
.boxed()
-
.collect(Collectors.toCollection(ArrayList::new));
-
//iterator
-
List<Integer> result = new ArrayList<>(list.size());
-
for(Integer e : list){
-
if(e > 200){
-
result.add(e);
-
}
-
}
-
//parallel stream
-
List<Integer> result = list.parallelStream()
-
.mapToInt(x -> x)
-
.filter(x -> x > 200)
-
.boxed()
-
.collect(Collectors.toCollection(ArrayList::new));
3. 自然排序测试
对一个随机数列(List<Integer>)进行自然排序,并组装为一个新的 List<Integer>,iterator 使用的是 Collections # sort API(使用归并排序算法实现),测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
-
//stream
-
List<Integer> result = list.stream()
-
.mapToInt(x->x)
-
.sorted()
-
.boxed()
-
.collect(Collectors.toCollection(ArrayList::new));
-
//iterator
-
List<Integer> result = new ArrayList<>(list);
-
Collections.sort(result);
-
//parallel stream
-
List<Integer> result = list.parallelStream()
-
.mapToInt(x->x)
-
.sorted()
-
.boxed()
-
.collect(Collectors.toCollection(ArrayList::new));

4. 归约统计测试
获取一个随机数列(List<Integer>)的最大值,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
-
//stream
-
int max = list.stream()
-
.mapToInt(x -> x)
-
.max()
-
.getAsInt();
-
//iterator
-
int max = -1;
-
for(Integer e : list){
-
if(e > max){
-
max = e;
-
}
-
}
-
//parallel stream
-
int max = list.parallelStream()
-
.mapToInt(x -> x)
-
.max()
-
.getAsInt();

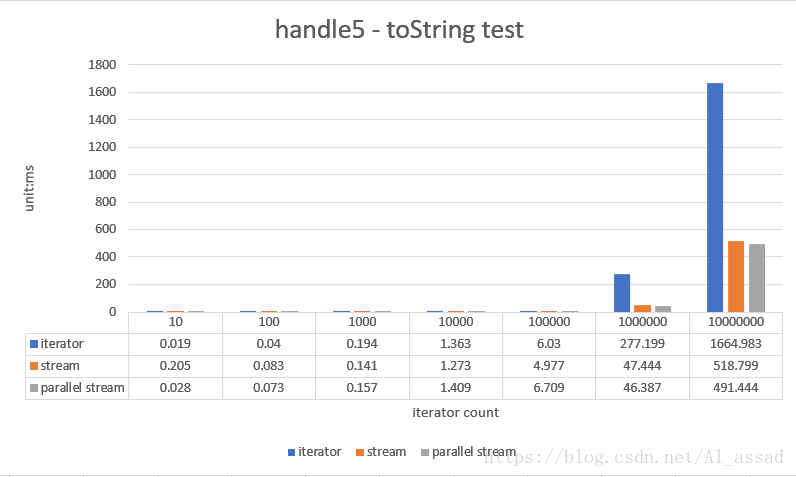
5. 字符串拼接测试
获取一个随机数列(List<Integer>)各个元素使用“,”分隔的字符串,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
-
//stream
-
String result = list.stream().map(String::valueOf).collect(Collectors.joining(","));
-
//iterator
-
StringBuilder builder = new StringBuilder();
-
for(Integer e : list){
-
builder.append(e).append(",");
-
}
-
String result = builder.length() == 0 ? "" : builder.substring(0,builder.length() - 1);
-
//parallel stream
-
String result = list.stream().map(String::valueOf).collect(Collectors.joining(","));
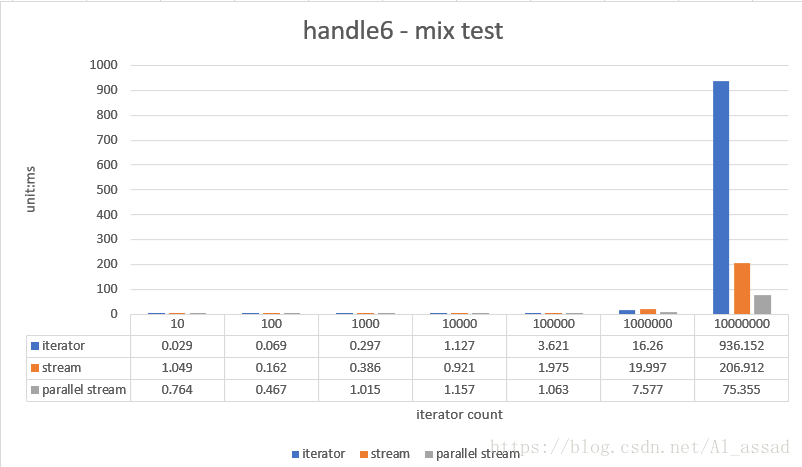
6. 混合操作测试
对一个随机数列(List<Integer>)进行去空值,除重,映射,过滤,并组装为一个新的 List<Integer>,测试的随机数列容量从 10 - 10000000,跑10次取平均时间;
-
//stream
-
List<Integer> result = list.stream()
-
.filter(Objects::nonNull)
-
.mapToInt(x -> x + 1)
-
.filter(x -> x > 200)
-
.distinct()
-
.boxed()
-
.collect(Collectors.toCollection(ArrayList::new));
-
//iterator
-
HashSet<Integer> set = new HashSet<>(list.size());
-
for(Integer e : list){
-
if(e != null && e > 200){
-
set.add(e + 1);
-
}
-
}
-
List<Integer> result = new ArrayList<>(set);
-
//parallel stream
-
List<Integer> result = list.parallelStream()
-
.filter(Objects::nonNull)
-
.mapToInt(x -> x + 1)
-
.filter(x -> x > 200)
-
.distinct()
-
.boxed()
-
.collect(Collectors.toCollection(ArrayList::new));
实验结果总结
从以上的实验来看,可以总结处以下几点:
- 在少低数据量的处理场景中(size<=1000),stream 的处理效率是不如传统的 iterator 外部迭代器处理速度快的,但是实际上这些处理任务本身运行时间都低于毫秒,这点效率的差距对普通业务几乎没有影响,反而 stream 可以使得代码更加简洁;
- 在大数据量(szie>10000)时,stream 的处理效率会高于 iterator,特别是使用了并行流,在cpu恰好将线程分配到多个核心的条件下(当然parallel stream 底层使用的是 JVM 的 ForkJoinPool,这东西分配线程本身就很玄学),可以达到一个很高的运行效率,然而实际普通业务一般不会有需要迭代高于10000次的计算;
- Parallel Stream 受引 CPU 环境影响很大,当没分配到多个cpu核心时,加上引用 forkJoinPool 的开销,运行效率可能还不如普通的 Stream;
使用 Stream 的建议
- 简单的迭代逻辑,可以直接使用 iterator,对于有多步处理的迭代逻辑,可以使用 stream,损失一点几乎没有的效率,换来代码的高可读性是值得的;
- 单核 cpu 环境,不推荐使用 parallel stream,在多核 cpu 且有大数据量的条件下,推荐使用 paralle stream;
- stream 中含有装箱类型,在进行中间操作之前,最好转成对应的数值流,减少由于频繁的拆箱、装箱造成的性能损失;
原文地址:https://blog.csdn.net/Al_assad/article/details/82356606
JDK8 Stream 数据流效率分析的更多相关文章
- 大型网站技术架构(四)--核心架构要素 开启mac上印象笔记的代码块 大型网站技术架构(三)--架构模式 JDK8 stream toMap() java.lang.IllegalStateException: Duplicate key异常解决(key重复)
大型网站技术架构(四)--核心架构要素 作者:13GitHub:https://github.com/ZHENFENG13版权声明:本文为原创文章,未经允许不得转载.此篇已收录至<大型网站技 ...
- Java List去重以及效率分析
List去重无非几种方法: 下面文章提供的两种: https://blog.csdn.net/u012156163/article/details/78338574, 以及使用List.stream. ...
- in和exists的区别与SQL执行效率分析
可总结为:当子查询表比主查询表大时,用Exists:当子查询表比主查询表小时,用in SQL中in可以分为三类: 1.形如select * from t1 where f1 in ('a','b'), ...
- mssql分页原理及效率分析
下面是常用的分页,及其分页效率分析. 1.分页方案一:(利用Not In和SELECT TOP分页) 语句形式: SELECT TOP 10 * FROM TestTable WHERE (ID NO ...
- 浅谈stream数据流
汴水流,泗水流,流到瓜州古渡头, 吴山点点愁. 我们知道水是源源不断的, 抽刀断水水更流, 斩不断, 理还乱, 是水流.(技术贴, 本文权当读者没学过古诗). 在一些语言里, 我们的前辈把数据 ...
- 团队工作效率分析工具gitstats
如果你是团队领导,关心团队的开发效率和工作激情:如果你是开源软件开发者,维护者某个repo:又或者,你关心某个开源软件的开发进度,那么你可以试一试gitstats. gitstats 是一个git仓库 ...
- [LeetCode] 295. Find Median from Data Stream ☆☆☆☆☆(数据流中获取中位数)
295. Find Median from Data Stream&数据流中的中位数 295. Find Median from Data Stream https://leetcode.co ...
- 声笔飞码GB2312单字效率分析
-----------------------声笔飞码强字方式单字效率分析-------------------------- 2 keys: 567 items, 381900209 ...
- Flash和js交互的效率分析
Flash和js交互的效率分析 AS代码: var time:int = getTimer(); for (var i:int = 0; i < 50000; i++) { External ...
随机推荐
- 如何做系列(1)- mybatis 如何实现分页?
第一个做法,就是直接使用我们的sql语句进行分页,也就是在mapper里面加上分页的语句就好了. <select id="" parameterType="&quo ...
- Luogu P3007 [USACO11JAN]大陆议会The Continental Cowngress
P3007 [USACO11JAN]大陆议会The Continental Cowngress 题意 题意翻译 简述:给出\(n\)个法案,\(m\)头牛的意见,每头牛有两个表决格式为"支持 ...
- UDP和TCP的区别?
区别总结: 1.TCP面向连接,UDP的面向无连接的,即发送数据之前不需要建立简介. 2.TCP提供可靠的数据传输,有发送应答机制,超时重传机制,错误校验机制,流量控制机制保证传输的安全,不丢失,不重 ...
- touch滑动事件---简单小案例
html: <!--导航栏头部--><div class="type_nav"> <ul class="clearfix " v- ...
- 汇总下几个IP计算/转换的shell小脚本-转
原文:http://blog.chinaunix.net/uid-20788470-id-1841646.html 1. IP转换为整数> vi ip2num.sh#!/bin/bash# ...
- 免费提取百度文库 doc 文件
首先说明,今天要推荐的这款软件,不能不能不能免费提取百度文库里 PDF 格式的文件. 对于其他的格式,无论收费与否都能免费提取. 只是口头说说免不了耍流氓的嫌疑,举栗如下: 百度文库里<喜迎党的 ...
- 公司jar包提交到集群的方法
yarn -jar xx.jar 此时包会提交到集群上运行 也可以把jar包放到hbase 的lib下面用hbase jar 方式调用
- Oracle时间日期处理方法
https://www.cnblogs.com/plmm/p/7381496.html 1.用于截取年.月.日.时.分.秒 extract()函数 extract(year from sysdate) ...
- 针对老式浏览器(主要是IE6、7、8)的css3-mediaqueries.js自适应布局
<meta name="viewport" content="width=device-width, initial-scale=1" /> vie ...
- Javascript-循环输出菱形,并可菱形自定义大小
var Cen = 6;//定义菱形中部为第几行(起始值为0) //for循环输出菱形 document.write("<button onclick='xh()'>点我for循 ...