基于Tesseract实现图片文字识别
一.简介
Tesseract是一个开源的文本识别【OCR】引擎,可通过Apache 2.0许可获得。它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言。该软件包包含一个ORC引擎【libtesseract】和一个命令行程序【tesseract】。Tesseract4添加了一个新的基于LSTM的OCR引擎,该引擎专注于行识别,但仍支持Tesseract 3的传统Tesseract OCR引擎,该引擎通过识别字符模式进行工作。通过使用传统OCR引擎模式【--oem 0】,可以与Tesseract 3兼容。它还需要训练好的数据文件对旧引擎进行支持,例如tessdata目录下的数据文件。
特点:
1.具有Unicode【UTF-8】支持,并且可以“开箱即用”地识别100多种语言。
2.支持各种输出格式,纯文本,hOCR【HTML】,PDF,仅不可见文本的PDF,TSV。Master分支还对ALTO【XML】输出提供实验性支持。
3.在许多情况下,要想获得更好的OCR结果,需要提高提供给Tesseract的图像的质量。
二.在python环境中安装pytesseract

安装成功!
三.在Windows系统下安装Tesseract
配置环境变量:

备注:最新的为4.1.0,建议安装4.x版本,根据一可知,版本4有重大升级,系统性能显著提升,特别是在对中文的识别上更是明显!
四.python代码实现
# -*- coding: utf-8 -*-
"""
Spyder Editor This is a temporary script file.
""" import pytesseract
from PIL import Image #打开验证码图片
image = Image.open('E:\\testData\\tess\\1.png')
#加载一下图片防止报错,此处可以省略
#image.load()
#调用show来展示图片,调试用此处可以省略
#image.show()
text = pytesseract.image_to_string(image,lang='chi_sim')
print(text)
五.Python环境执行结果【无数据清洗】
20
a
志
口
吴
吊
5
达
吊
园 康 阮 随 阮 随 随 阮 隆 随 阮 阮 庞
应 阮 院 阮 阮 际 阮 阮 院 院 阮 庞 宇
B
B
B
B
B
B
B
B
B
B
E 胡
胡
胡
胡
胡
胡
胡
胡
胡
胡
脱 医 剧 澈 剖 剖 亨 亨 定 亨 宣 河 宇
B
B
B
B
E
E
E
E
E
E
振 产 莲 主
主
主
主
主
主
主
主
主
主
生 交 E
E
E
E
E
E
E
E
E
E
E35653 职
职
职
职
职
职
职
职
职
职
E E
E
E
E
E
E
E
E
E
E
093
部分示例:

可知对中文的识别一塌糊涂,因此建议还是使用版本4进行识别!

六.使用Java程序调用ImageIO进行数据预处理
package zhen;
import java.awt.Color;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException; import javax.imageio.ImageIO; public class LineMark{
public static void clean(String fromPath,String toPath) throws IOException{
File file1 = new File(fromPath);
BufferedImage image = ImageIO.read(file1); BufferedImage sourceImg =ImageIO.read(new FileInputStream(file1)); // 获取图片的长宽
int width = sourceImg.getWidth();
int height = sourceImg.getHeight(); /**
* 创建3维数组用于保存图片rgb数据
*/
int[][][] array = new int[width][height][3];
for(int i=0;i<width;i++){ // 获取图片中所有像素点的rgb
for(int j=0;j<height;j++){
int pixel = image.getRGB(i, j); //获得坐标(i,j)的像素
int red = (pixel & 0xff0000) >> 16;
int green = (pixel & 0xff00) >> 8;
int blue = (pixel & 0xff); //通过坐标(i,j)的像素值获得r,g,b的值
array[i][j][0] = red;
array[i][j][1] = green;
array[i][j][2] = blue;
}
} /**
* 清除表格线:
* 竖线:绝大多数点的x值都为255
*/
for(int i=0;i<width;i++){
int nums = 0;
for(int j=0;j<height;j++){
if(array[i][j][0]<128 && array[i][j][1]<128 && array[i][j][2]<128){
nums += 1;
}
}
if(nums > height * 0.8){
for(int n=0;n<height;n++){
array[i][n][0] = 255;
array[i][n][1] = 255;
array[i][n][2] = 255;
}
}
}
/**
* 清除表格线:
* 横线:绝大多数点的y值都为255
*/
for(int j=0;j<height;j++){
int nums = 0;
for(int i=0;i<width;i++){
if(array[i][j][0]<128 && array[i][j][1]<128 && array[i][j][2]<128){
nums += 1;
}
}
if(nums > height * 0.8){
for(int n=0;n<width;n++){
array[n][j][0] = 255;
array[n][j][1] = 255;
array[n][j][2] = 255;
}
}
}
/**
* 大点
*/
for(int i=0;i<width;i++){
for(int j=0;j<height;j++){
int cover = new Color(array[i][j][0],array[i][j][1],array[i][j][2]).getRGB();
image.setRGB(i,j,cover);
}
}
File file2 = new File(toPath);
ImageIO.write(image, "png", file2);
} /**
* 测试
* @param args
*/
public static void main(String[] args){
String fromPath = "E:\\testData\\tess\\111.png";
String toPath = "E:\\testData\\tess\\112.png";
try {
LineMark.clean(fromPath,toPath);
} catch (IOException e) {
e.printStackTrace();
}
}
}
七.执行结果
处理之前:
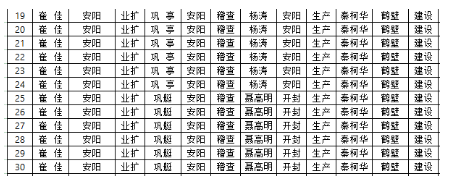
处理之后:


八.使用Tesseract 4 API进行文字识别
package zhen;
import java.awt.Rectangle;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import javax.imageio.ImageIO;
import net.sourceforge.tess4j.*;
import org.apache.poi.xssf.usermodel.*; public class RP {
private String a0=""; public void toExcel(int i,XSSFWorkbook wb,XSSFSheet sheet,int len) //将文字信息做成表格
{
for(int j=0;j<len;j++){
String[] array = this.a0.split("\n"); // 分行
for(int k=0;k<array.length;k++){
XSSFRow row = sheet.createRow(k); // 创建一行
String[] array2 = array[k].split(" ");
for(int m=0;m<array2.length;m++){
row.createCell(m).setCellValue(array2[m]);
}
}
}
}
public static void main(String[] args) throws IOException {
RP rp = new RP();
int num = 1; File root = new File("E:\\testData\\tess2");//存放处理后的图片,imgs文件夹
File res = new File("E:\\testData\\tess");//源图片位置,res文件夹下 ITesseract instance = new Tesseract();
instance.setLanguage("chi_sim"); //使用训练好中文字库识别 XSSFWorkbook wb = new XSSFWorkbook();
XSSFSheet sheet = wb.createSheet("信息汇总");
try {
File[] ress = res.listFiles();
int i=0;
for(File file : ress){
i++;
LineMark.clean(file.getAbsolutePath(),"E:\\testData\\tess2\\"+i+".png");
} //去除源图片表格线,处理后的图片放到img文件夹 File[] files = root.listFiles();
for (File file : files) { //对去除水印后的图片逐个处理
BufferedImage sourceImg =ImageIO.read(new FileInputStream(file)); // 获取图片的长宽
int width = sourceImg.getWidth();
int height = sourceImg.getHeight();
Rectangle ret = new Rectangle(0,0,width,height); //识别全部数据 String result = instance.doOCR(file, ret); //开始采用doOCR(file)效率很低,因为图片内容太多
int len = 0;
if(result != null){
len = result.split(" ").length;
rp.a0 = result;
}
System.out.print(result);
rp.toExcel(num,wb,sheet,len); //调用toExcel函数,将提取到的信息写入
num++;
}
} catch (TesseractException e) {
System.err.println(e.getMessage());
} try {
FileOutputStream fout = new FileOutputStream("D:\\software\\company.xlsx");
wb.write(fout);
fout.close();
} catch (IOException e) {
e.printStackTrace();
} //把写好信息的表输出
} }
九.不数据清洗执行结果

十.数据清洗执行结果

经过对比可以明显看出,表格线对识别的影响很大【其它形式的干扰也同样如此,例如:验证码上的干扰线、图案等】,因此,数据清洗必不可少!

十一.分析
从上面的执行结果可知,在使用Tesseract 4时,在数据尽可能的清晰的情况下,大部分汉字还是能识别出来的,只是在【数字0】和【标点符号。】,【英语g】和【数字9】等外形相识的地方识别不清楚!当然,模型还有提升的空间,下一步将提升对存在格式倾斜或拍照的图片进行识别的能力!
基于Tesseract实现图片文字识别的更多相关文章
- Python识别验证码,基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[li ...
- 基于Python37配置图片文字识别
以管理员权限打开cmd控制台. 1.如何安装PIL 输入下面命令:pip install Pillow 参考:https://www.cnblogs.com/mrgavin/p/8177841.htm ...
- 基于Tesseract组件的OCR识别
基于Tesseract组件的OCR识别 背景以及介绍 欲研究C#端如何进行图像的基本OCR识别,找到一款开源的OCR识别组件.该组件当前已经已经升级到了4.0版本.和传统的版本(3.x)比,4.0时代 ...
- 【图片识别】java 图片文字识别 ocr (转)
http://www.cnblogs.com/inkflower/p/6642264.html 最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为 ...
- java 图片文字识别 ocr
最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的 ...
- JAVA的图片文字识别技术
从2013年的记录看,JAVA中图片文字识别技术大部分采用ORC的tesseract的软件功能,后来渐渐开放了java-api调用接口. 图片文字识别技术,还是采用训练的方法.并未从根本上解决图片与文 ...
- 小试Office OneNote 2010的图片文字识别功能(OCR)
原文:小试Office OneNote 2010的图片文字识别功能(OCR) 自Office 2003以来,OneNote就成为了我电脑中必不可少的软件,它集各种创新功能于一身,可方便的记录下各种类型 ...
- 一篇文章搞定百度OCR图片文字识别API
一篇文章搞定百度OCR图片文字识别API https://www.jianshu.com/p/7905d3b12104
- python3 图片文字识别
最近用到了图片文字识别这个功能,从网上搜查了一下,决定利用百度的文字识别接口.通过测试发现文字识别率还可以.下面就测试过程简要说明一下 1.注册用户 链接:https://login.bce.baid ...
随机推荐
- mysql之case..when ..then..else..end as..用法
1.示例1 查询1: SELECT CASE main_xm_sam31 WHEN '02' THEN 2 ELSE 1 END AS SPDJ FROM SR_MAIN_BG A WHERE A.P ...
- mybatis-plus - 初识
一. 集成 pom.xml <dependency> <groupId>com.alibaba</groupId> <artifactId>druid& ...
- nvalidSchema: Missing dependencies for SOCKS support
首先需要安装pip3 1. 安装 setuptools wget --no-check-certificate https://pypi.python.org/packages/source/s/se ...
- html 未选择复选框不上传
问题 之前就遇到类似的问题,在一个列表中,如果有复选框,并且不选中 会导致这个复选框不上传,导致后台接收不到复选框数据 解决方法我想到的就是 <td> <input type=&qu ...
- hdu:2089 ( 数位dp入门+模板)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2089 数位dp的模板题,统计一个区间内不含62的数字个数和不含4的数字个数,直接拿数位dp的板子敲就行 ...
- 题解 P2146 [NOI2015]软件包管理器
P2146 [NOI2015]软件包管理器 感觉代码比其他题解更简洁qwq 树链剖分模板题 install x:将1~x的路径上的节点全部变成1(安装x需要先安装1~x) uninstall x:将x ...
- Redis读写分离的简单配置
Master进行写操作,可能只需要一台Master.进行写操作,关闭数据持久化. Slave进行读操作,可能需要多台Slave.进行读操作,打开数据持久化. 假设初始配置有Master服务器为A,sl ...
- 第二十一篇 Linux中的环境变量简单介绍
环境变量之 PATH 定义解释器搜索用户执行命令的路径 获取PATH变量的值: echo $PATH /usr/local/bin:/usr/local/sbin:/usr/bin:/us ...
- 优化 : Oracle数据库Where条件执行顺序 及Where子句的条件顺序对性能的影响
.Oracle数据库Where条件执行顺序: 由于SQL优化起来比较复杂,并且还会受环境限制,在开发过程中,写SQL必须必须要遵循以下几点的原则: 1.ORACLE采用自下而上的顺序解析WHERE子句 ...
- Stylus-import
Stylus Import Disclaimer: In all places the @import is used with Stylus sheets, the @require could b ...