CDH搭建大数据集群(5.10.0)
纠结了好久,还是花钱了3个4核8G的阿里云主机,且行且珍惜,想必手动搭建过Hadoop集群的完全分布式、HBase的完全分布式的你(当然包括我,哈哈),一定会抱怨如此多的配置,而此时CDH正是解决我们烦恼的时候。
下面安装过程比较长,所以一定要有耐心。
一、CDH介绍
以下是官网给的介绍:个人感觉就是对hadoop环境的封装

二、为什么选择CDH?
Cloudera 常年坚持季度发型update版本,年度发行Release版本,更新速度比Aapche官方快,而且在实际使用过程中CDH表现无比稳定。
CDH支持yum/apt包,tar包,rpm包,cloudera manager四种方式安装。可以获取最新特性和最新Bug修复,安装维护方便,节省运维时间。另外集群搭建更加方便。
• 版本划分清晰
• 版本更新速度快
• 支持Kerberos安全认证
• 文档清晰
• 支持多种安装方式(Cloudera Manager方式)
三、CDH的版本选择
CDH4.x--->4.8.6
CDH5.x :优选5.4.8 5.8.0 5.12.0 不建议选择5.11.0,有坑(这里我选用5.10.0)
四、安装准备
1.节点准备
由于是个人测试环境,所以购买了3台阿里云的主机,主要配置如下:
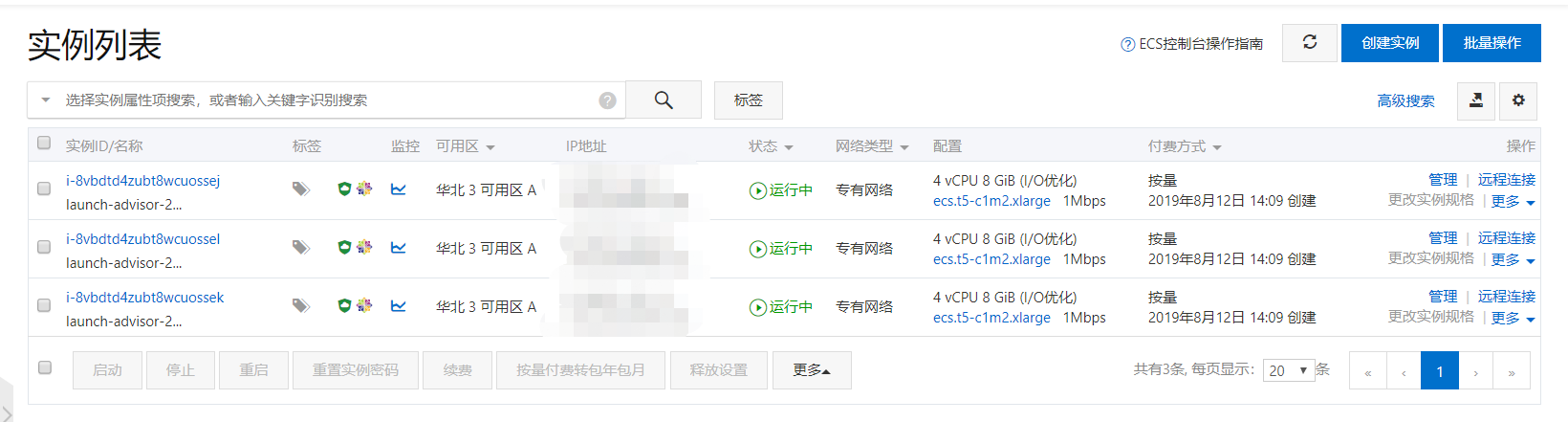
2.节点规划
hadoop001:mysql cm-server cm-agent Namenode DataNode ResourceManager NodeManager ZK
hadoop002:cm-agent Datanode SecondaryNameNode NameNode ZK
hadoop003:cm-agent DataNode NodeManager ZK
3.下载parcels文件
地址:http://archive.cloudera.com/cdh5/parcels/
选择5.10.0:http://archive.cloudera.com/cdh5/parcels/5.10.0/
下载以下三个内容:
①http://archive.cloudera.com/cdh5/parcels/5.10.0/CDH-5.10.0-1.cdh5.10.0.p0.41-el6.parcel
②http://archive.cloudera.com/cdh5/parcels/5.10.0/CDH-5.10.0-1.cdh5.10.0.p0.41-el6.parcel.sha1
③http://archive.cloudera.com/cdh5/parcels/5.10.0/manifest.json
4.tarball下载
地址:http://archive.cloudera.com/cm5/repo-as-tarball
选择5.10.0:http://archive.cloudera.com/cm5/repo-as-tarball/5.10.0/
下载:http://archive.cloudera.com/cm5/repo-as-tarball/5.10.0/cm5.10.0-centos6.tar.gz
5.准备以下内容:

五、系统初始化
1.关闭防火墙(3个节点)
临时关闭:service iptables stop 验证:service iptables status
永久关闭:chkconfig iptables off 验证:chkconfig --list | grep iptable

2.配置主机名(3个节点)
执行命令:vim /etc/sysconfig/network
修改完成以后重启:reboot

3.修改hosts文件(3个节点)
执行命令:vim /etc/hosts
添加以下内容(3个节点的内容一致),这里是我使用的是内网ip
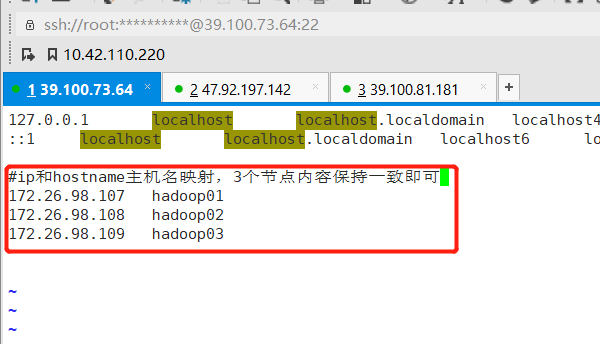
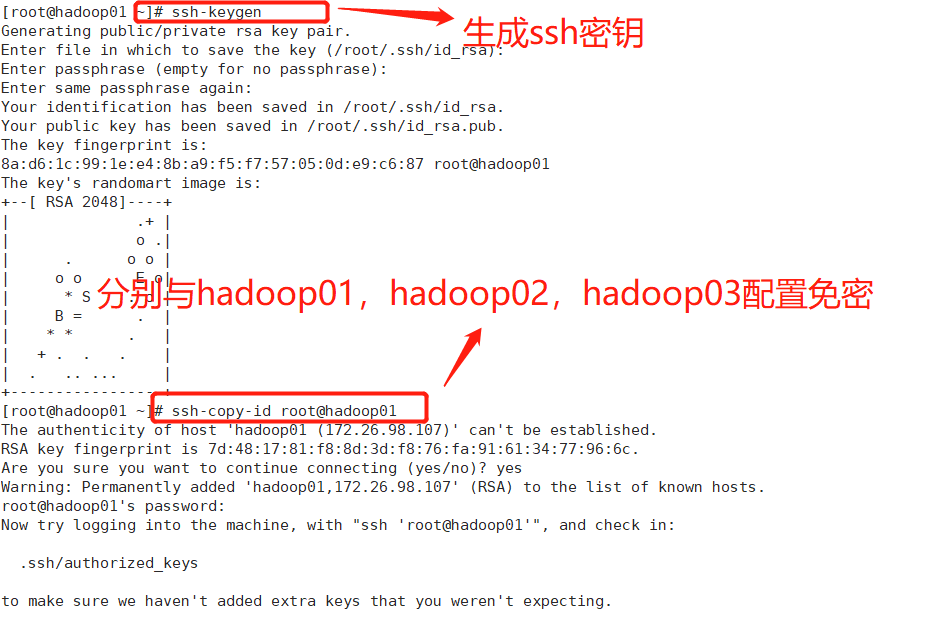
4.配置免密登录(3个节点)
执行命令:ssh-keygen
执行命令: ssh-copy-id root@hadoop01、 ssh-copy-id root@hadoop02、 ssh-copy-id root@hadoop03
5.安装JDK(3个节点)
我这里本地已经下载好文件:通过rz命令本地上传(yum install lrzsz)
注意:JDK的安装目录一定是/usr/java,否则CDH启动失败!!!!!!(鄙人走过的坑)
解压命令:
[root@hadoop03 java]# tar -xvf jdk-8u181-linux-x64.tar.gz
配置环境变量:
[root@ java]# vim /etc/profile
配置以下内容:
#jdk的环境变量配置
export JAVA_HOME=/usr/java/jdk1.8.0_181 //这里的路径一定是/usr/java,否则CDH启动失败!!!!!!
export PATH=.:$JAVA_HOME/bin:$PATH
执行命令使配置文件生效:[root@hadoop03 java]# source /etc/profile
通过scp命令将JDK的压缩包发给其他节点:[root@hadoop03 java]# scp jdk-8u181-linux-x64.tar.gz root@hadoop01:/usr/java/
最后通过:java -version命令查看JDK是否安装成功。
6.检查Python版本(3个节点)
执行命令:python --version
注:建议是2.6.6,如果使用的cdh版本是4.x,使用2.7.x版本的python会造成hdfs的ha不兼容
虚拟机如果用的是centos7.x的话,要用python7.x的版本
7.检查服务器之间的时间是否同步(3个节点)
执行命令:grep ZONE /etc/sysconfig/clock(应该都是上海时间)
六、安装mysql(hadoop01节点)
1、安装并解压
这里数据库的版本是mysql-5.6.23-linux-glibc2.5-x86_64.tar.gz,将mysql安装包上传到服务器,或者从官网上下载mysql安装包.
解压mysql安装包:tar xzvf mysql-5.6.23-linux-glibc2.5-x86_64.tar.gz
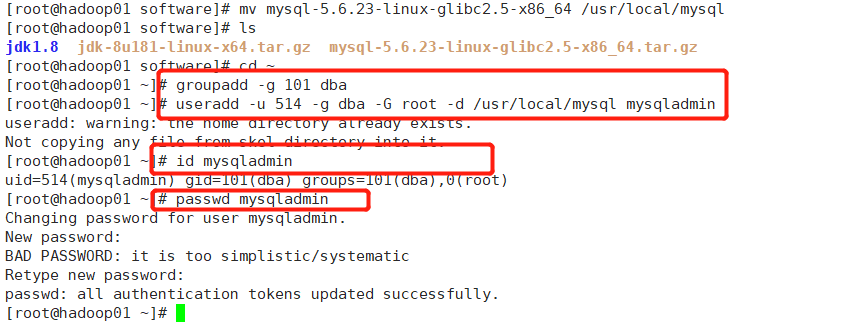
解压完毕之后,将解压后的目录移动到/usr/local目录下(固定目录),并改名为mysql:mv mysql-5.6.23-linux-glibc2.5-x86_64 /usr/local/mysql
2、改变mysql的用户组
将mysql添加到mysqladmin的dba用户组里,执行以下命令:
[root@hadoop01 software]# cd ~
[root@hadoop01 ~]# groupadd -g 101 dba
[root@hadoop01 ~]# useradd -u 514 -g dba -G root -d /usr/local/mysql mysqladmin
[root@hadoop01 ~]# id mysqladmin(查看用户)
[root@hadoop01 ~]# passwd mysqladmin(修改密码)
3、将环境变量配置文件拷贝到mysqladmin用户的home目录下
执行命令:cp /etc/skel/.* /usr/local/mysql
4、创建mysql的配置文件
执行以下命令:
[root@hadoop01 ~]# cd /etc/
[root@hadoop01 etc]# vim my.cnf
进入到my.cnf文件之后,将里面的全部内容删除,之后将以下的配置拷贝到my.cnf中:
[client]
port = 3306
socket = /usr/local/mysql/data/mysql.sock [mysqld]
port = 3306
socket = /usr/local/mysql/data/mysql.sock skip-external-locking
key_buffer_size = 256M
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 4M
query_cache_size= 32M
max_allowed_packet = 16M
myisam_sort_buffer_size=128M
tmp_table_size=32M table_open_cache = 512
thread_cache_size = 8
wait_timeout = 86400
interactive_timeout = 86400
max_connections = 600 thread_concurrency = 32 default-storage-engine = INNODB
transaction-isolation = READ-COMMITTED server-id = 1
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
pid-file = /usr/local/mysql/data/hostname.pid log-warnings
sysdate-is-now binlog_format = MIXED
log_bin_trust_function_creators=1
log-error = /usr/local/mysql/data/hostname.err
log-bin=/usr/local/mysql/arch/mysql-bin innodb_data_home_dir = /usr/local/mysql/data/
innodb_data_file_path = ibdata1:500M:autoextend
innodb_log_group_home_dir = /usr/local/mysql/arch
innodb_log_files_in_group = 2
innodb_log_file_size = 200M innodb_buffer_pool_size = 1024M
innodb_additional_mem_pool_size = 50M
innodb_log_buffer_size = 16M innodb_lock_wait_timeout = 100
innodb_flush_log_at_trx_commit = 1
innodb_locks_unsafe_for_binlog=1 performance_schema
innodb_read_io_threads=4
innodb-write-io-threads=4
innodb-io-capacity=200
innodb_purge_threads=1
innodb_use_native_aio=on innodb_file_per_table = 1
lower_case_table_names=1 [mysqldump]
quick
max_allowed_packet = 16M [mysql]
no-auto-rehash [mysqlhotcopy]
interactive-timeout [myisamchk]
key_buffer_size = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M
5、修改my.cnf文件的属性和权限
依次执行以下命令:
[root@hadoop01 etc]# chown mysqladmin:dba /etc/my.cnf
[root@hadoop01 etc]# chmod 640 /etc/my.cnf
[root@hadoop01 etc]# chown -R mysqladmin:dba /usr/local/mysql
[root@hadoop01 etc]# chmod -R 755 /usr/local/mysql
[root@hadoop01 etc]# su - mysqladmin
[mysqladmin@hadoop01 ~]$ pwd
/usr/local/mysql
[mysqladmin@hadoop01 ~]$ mkdir arch backup
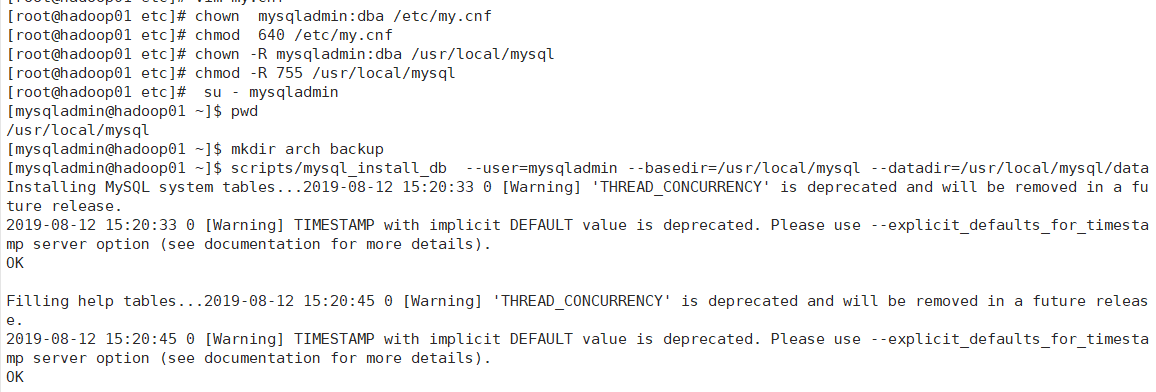
执行初始化脚本,打印的日志没有报错,说明运行ok:
[mysqladmin@hadoop01 ~]$
初始化脚本命令:scripts/mysql_install_db --user=mysqladmin --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
6、配置mysql服务和自启动
在root用户下执行:
[mysqladmin@hadoop01 ~]$ su root
Password:
[root@hadoop01 mysql]#
[root@hadoop01 mysql]# cd /usr/local/mysql
[root@hadoop01 mysql]# cp /usr/local/mysql/support-files/mysql.server /etc/rc.d/init.d/mysql
[root@hadoop01 mysql]# chmod +x /etc/rc.d/init.d/mysql
[root@hadoop01 mysql]# chkconfig --del mysql
[root@hadoop01 mysql]# chkconfig --add mysql
[root@hadoop01 mysql]# chkconfig --level 345 mysql on
[root@hadoop01 mysql]# vim /etc/rc.local(将里面的内容都删掉,拷贝以下内容)
#!/bin/sh
#
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff. touch /var/lock/subsys/local su - mysqladmin -c "/etc/init.d/mysql start --federated"
7、启动mysql并监听进程
执行以下命令:
[root@hadoop01 mysql]# su - mysqladmin
[mysqladmin@hadoop01 ~]$ mysqld_safe &
[1] 1888
重新打开一个连接执行:
ps -ef|grep mysqld(查看mysql的进程是否运行)
service mysql status(查看mysql的运行状态)

出现上图代表启动ok
8、修改mysql的密码
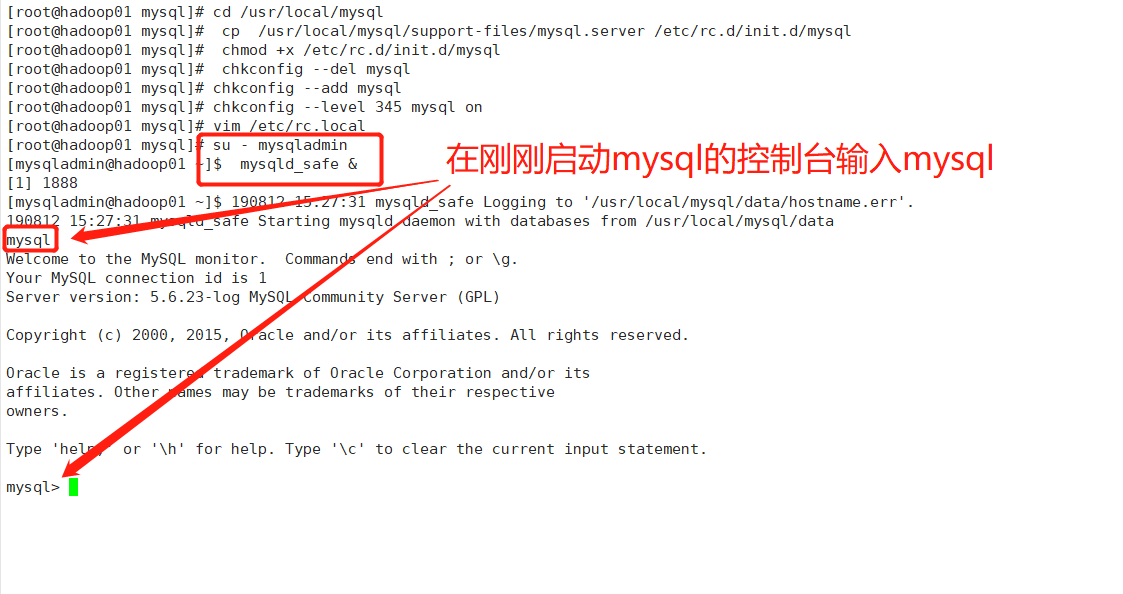
执行以下命令:
mysql> use mysql
mysql> update user set password=password('root') where user='root';
mysql> select host,user,password from user;
mysql> delete from user where user='';
mysql> flush privileges;

9、更改.bash_profile文件
进入到mysql目录中,执行vim ./.bash_profile,拷贝以下内容:
[root@hadoop01 mysql]# cd /usr/local/mysql/
[root@hadoop01 mysql]# vim .bash_profile
# .bash_profile
# Get the aliases and functions if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi # User specific environment and startup programs
MYSQL_BASE=/usr/local/mysql
export MYSQL_BASE
PATH=${MYSQL_BASE}/bin:$PATH
export PATH unset USERNAME #stty erase ^H
set umask to 022
umask 022
PS1=`uname -n`":"'$USER'":"'$PWD'":>"; export PS1
七.安装http和启动http服务
1.安装http服务
切换到root用户:
[root@hadoop01 mysql]# rpm -qa|grep httpd
[root@hadoop01 mysql]# yum install -y httpd
[root@hadoop01 mysql]# chkconfig --list|grep httpd
日志显示:httpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
[root@hadoop01 mysql]# chkconfig httpd on
[root@hadoop01 mysql]# chkconfig --list|grep httpd
日志显示:httpd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
[root@hadoop01 mysql]# service httpd start

2.创建parcels文件
执行以下命令:
[root@hadoop01 mysql]# cd /var/www/html
[root@hadoop01 html]# mkdir parcels
将开始下载的三个文件上传至此文件夹下:
①http://archive.cloudera.com/cdh5/parcels/5.10.0/CDH-5.10.0-1.cdh5.10.0.p0.41-el6.parcel
②http://archive.cloudera.com/cdh5/parcels/5.10.0/CDH-5.10.0-1.cdh5.10.0.p0.41-el6.parcel.sha1
③http://archive.cloudera.com/cdh5/parcels/5.10.0/manifest.json
[root@hadoop01 parcels]# mkdir /opt/rpminstall
[root@hadoop01 parcels]# cd /opt/rpminstall
将下载的tarball上传:cm5.10.0-centos6.tar.gz至当前目录下
解压:[root@hadoop01 rpminstall]# tar -xzvf cm5.10.0-centos6.tar.gz -C /var/www/html/
[root@hadoop01 rpminstall]# cd /var/www/html
[root@hadoop01 html]# ll
创建和官网相同的目录:
[root@hadoop01 html]# mkdir -p cm5/redhat/6/x86_64/
[root@hadoop01 html]# mv cm cm5/redhat/6/x86_64/
3.配置本地yum源(3个节点)
[root@hadoop01 ~]# vi /etc/yum.repos.d/cloudera-manager.repo
粘贴以下内容:ip地址为当前机器的ip地址,如果集群在内网中则配置内网ip即可,该文件每台服务器都要配置一个,保存退出!
[cloudera-manager]
name = Cloudera Manager, Version 5.10.0
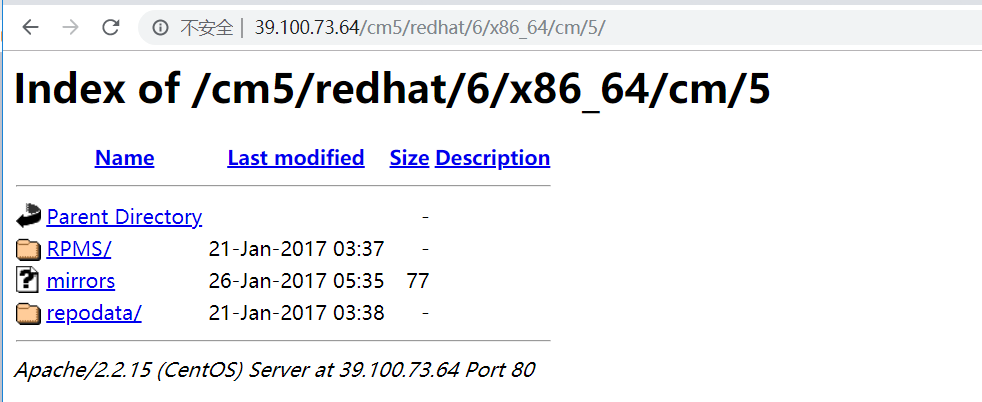
baseurl = http://39.100.73.64/cm5/redhat/6/x86_64/cm/5/
gpgcheck = 0
浏览器查看下面两个网址是否出来,假如有,就配置成功(以下ip为公网ip)
http://39.100.73.64/parcels/
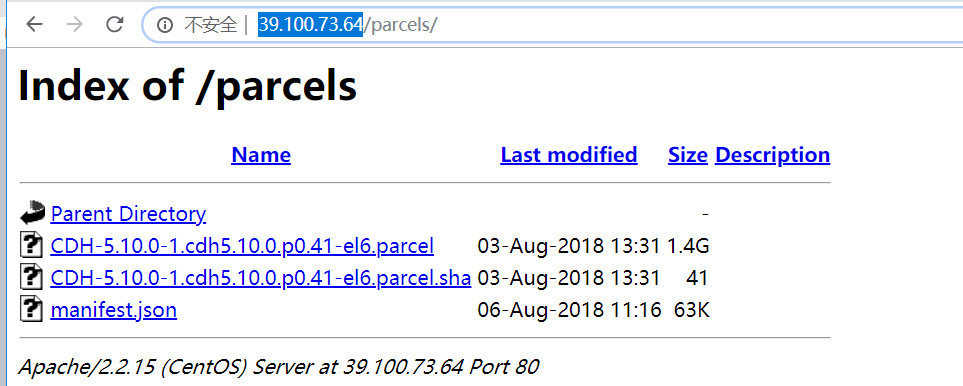
http://39.100.73.64/cm5/redhat/6/x86_64/cm/5/
八.安装并启动CM服务
1、执行以下命令
[root@hadoop01 ~]# cd /var/www/html/cm5/redhat/6/x86_64/cm/5/RPMS/x86_64
[root@hadoop01 x86_64]# yum install -y cloudera-manager-daemons-5.10.0-1.cm5100.p0.85.el6.x86_64.rpm
[root@hadoop01 x86_64]# yum install -y cloudera-manager-server-5.10.0-1.cm5100.p0.85.el6.x86_64.rpm
顺序不能错,只装这两个
[root@hadoop01 x86_64]# mkdir /usr/share/java
[root@hadoop01 x86_64]# cd /usr/share/java/
将mysql-connector-java.jar上传到该目录下:.jar包名称必须为mysql-connector-java.jar
2、进入到mysql中,创建元数据
执行以下命令:
[root@hadoop01 java]# su - mysqladmin
hadoop01:mysqladmin:/usr/local/mysql:>cd bin
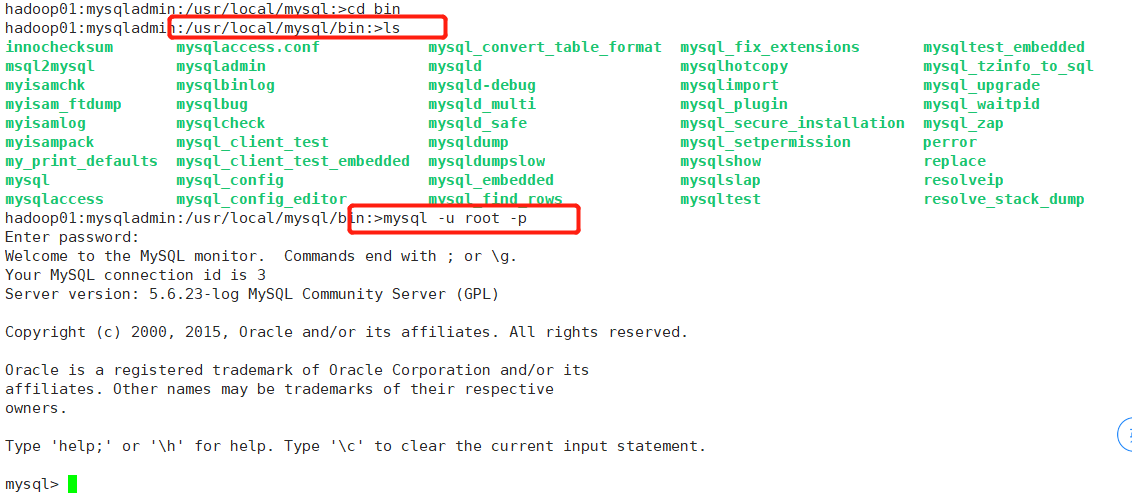
3、进入数据库后,执行以下命令:
mysql> create database cmf DEFAULT CHARACTER SET utf8;
mysql> grant all on cmf.* TO 'cmf'@'%' IDENTIFIED BY 'root';
mysql> create database amon DEFAULT CHARACTER SET utf8;
mysql> grant all on amon.* TO 'amon'@'%' IDENTIFIED BY 'root';
mysql> grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
mysql> flush privileges;
切换到root用户:
[root@hadoop01 ~]# cd /etc/cloudera-scm-server/
[root@hadoop01 cloudera-scm-server]# vi db.properties(按照下图中进行配置)
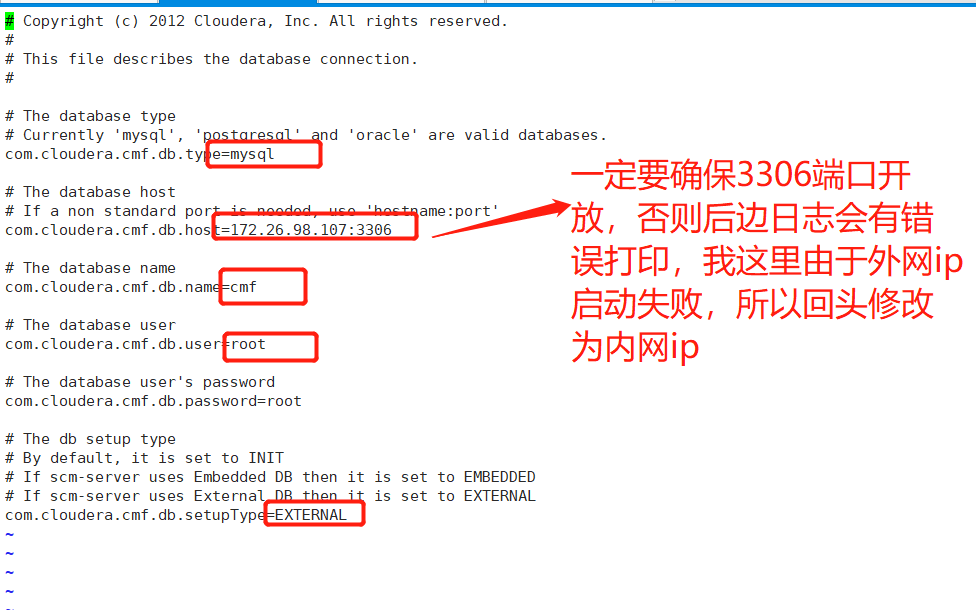
标注内容从上往下分别代表:数据库类型,数据库所在的主机ip:端口,数据库名称,数据库用户,数据库设置类型
标注要和你之前的配置匹配
配置好后,保存退出
4、启动CM服务
执行以下命令:
[root@hadoop01 jdk1.8.0_181]# service cloudera-scm-server start
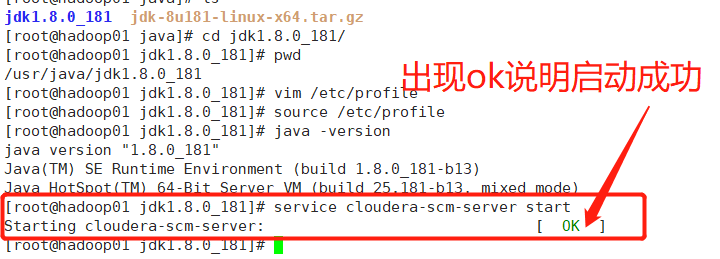
查看日志:
[root@hadoop01 jdk1.8.0_181]# cd /var/log/cloudera-scm-server/
[root@hadoop01 cloudera-scm-server]# tail -f cloudera-scm-server.log
没有错误日志提示,说明启动成功~~~~~
九.CDH配置
1、登录CDH配置界面
http://39.100.73.64:7180(ip为公网ip),用户名和密码都是admin,下面正式开始我们的页面配置过程。(需要进入阿里云控制台,将公网ip的端口开放:7180)
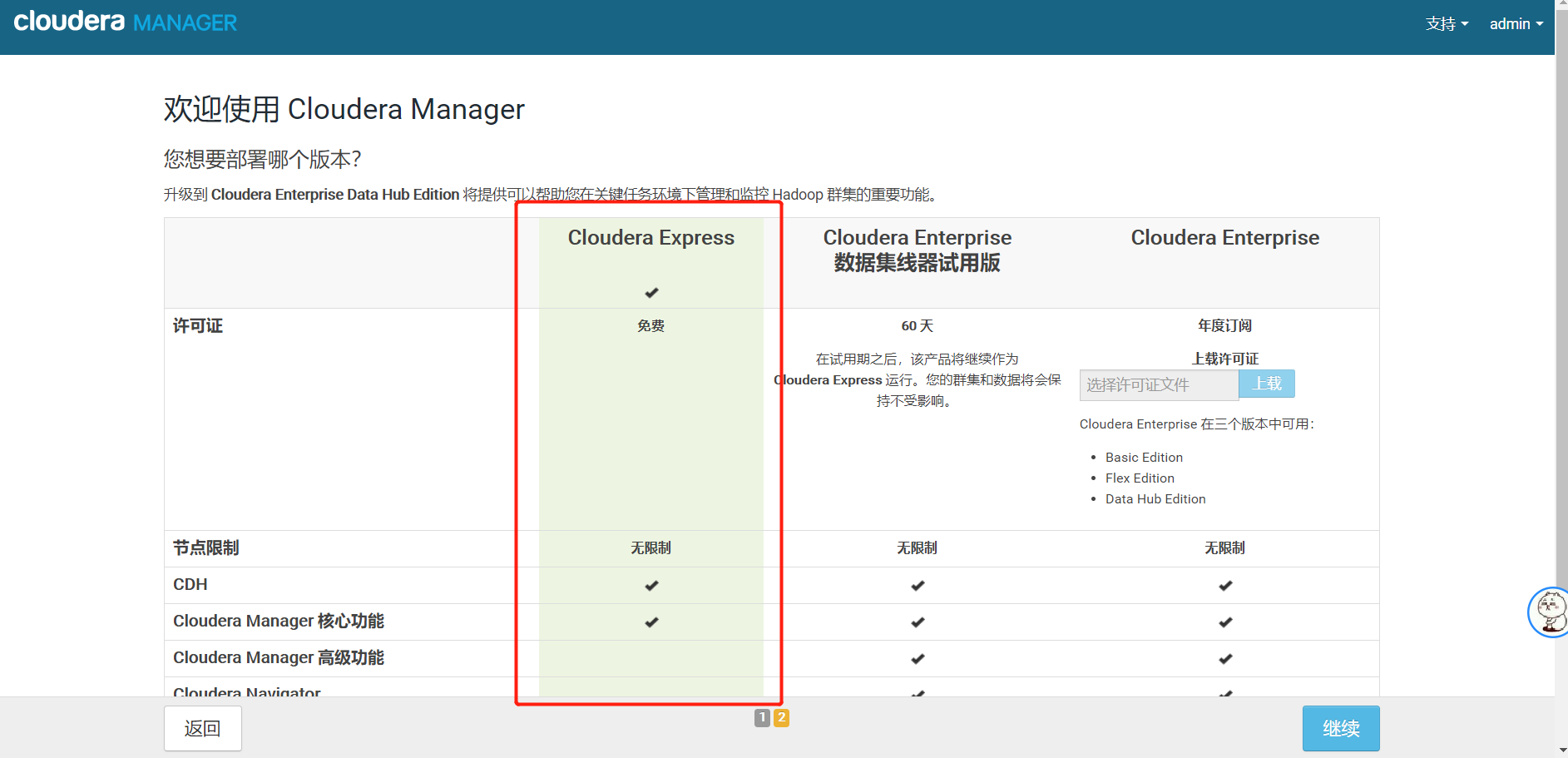
2、选择免费
3、配置CDH集群
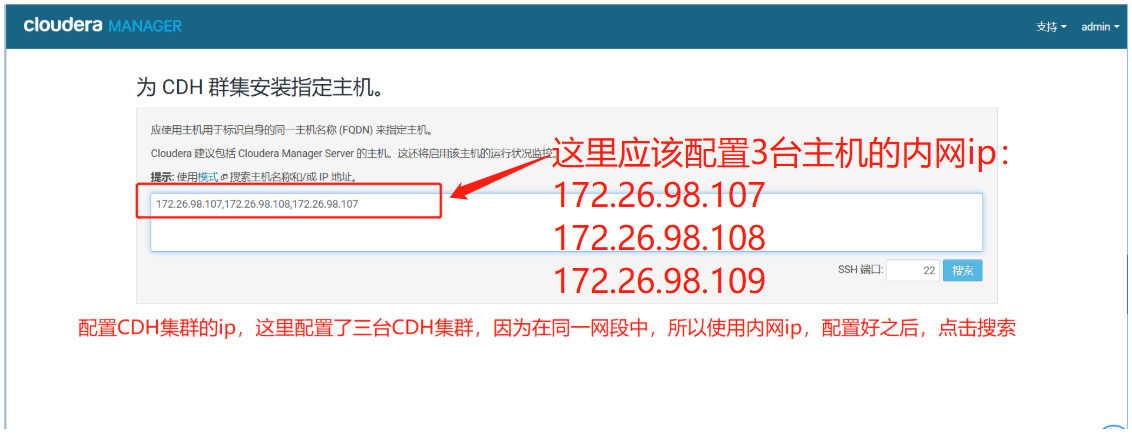
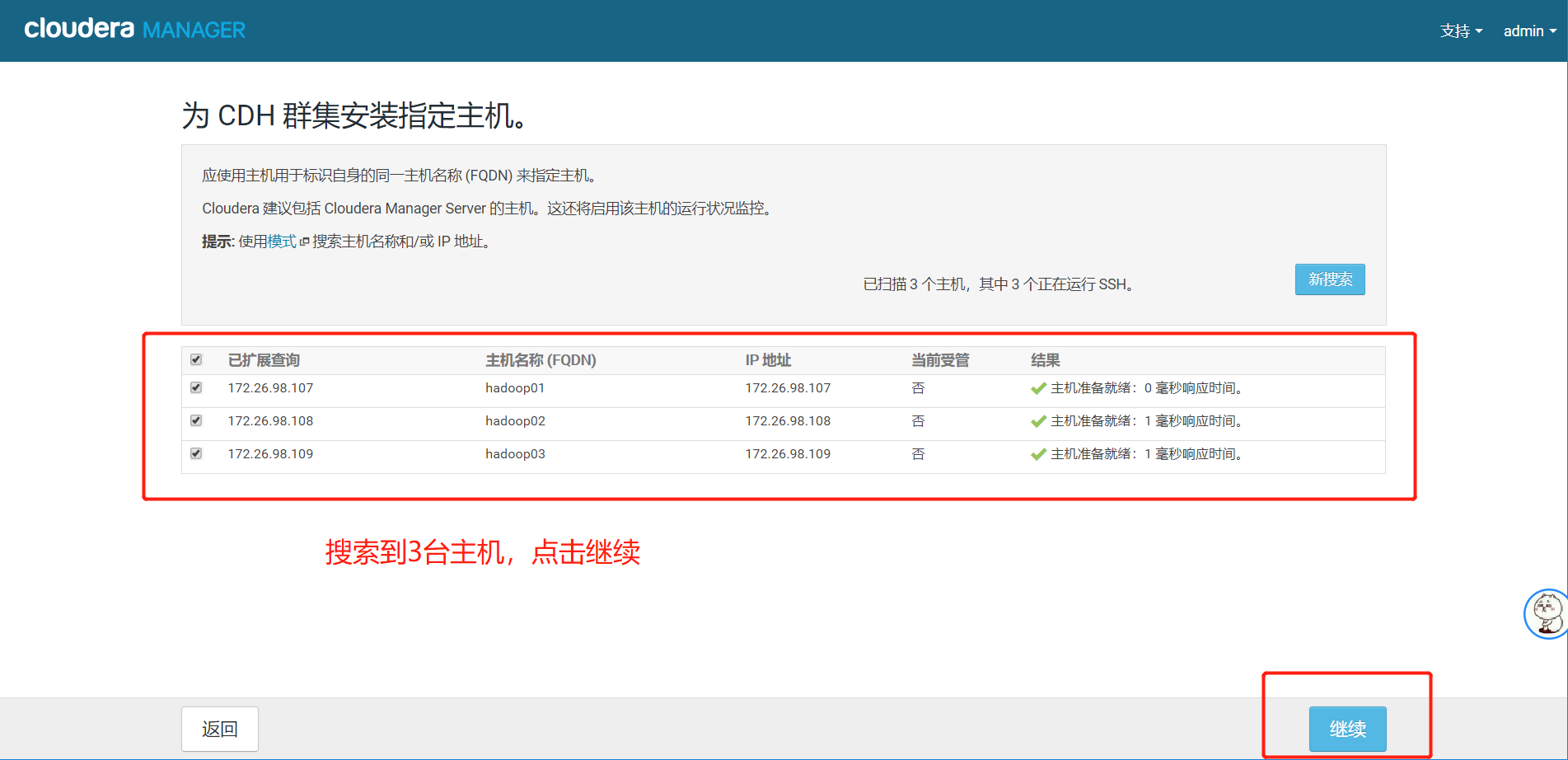
4、点击搜索
出现这个页面,代表集群能连接上,当前受管这一栏全部为否,如果有是的话,代表之前已经安装好并且没有卸载干净,需要卸载干净后重启服务后在进入到该页面。
5、配置parcels文件
5.1、点击更多选项

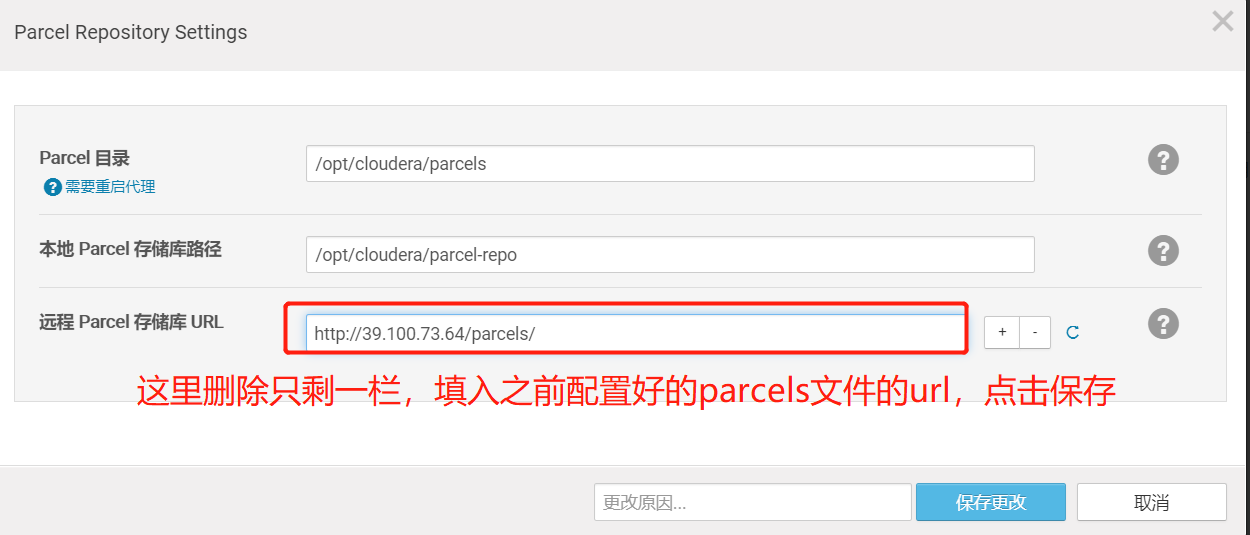
5.2、配置远程 Parcel 存储库 URL
进入到该页面中,远程 Parcel 存储库 URL这一栏删掉只留下一个,将内容更改为之前配置过的parcel地址,这里用的是内网的ip,所以是http://39.100.73.64/parcels/,点击保存
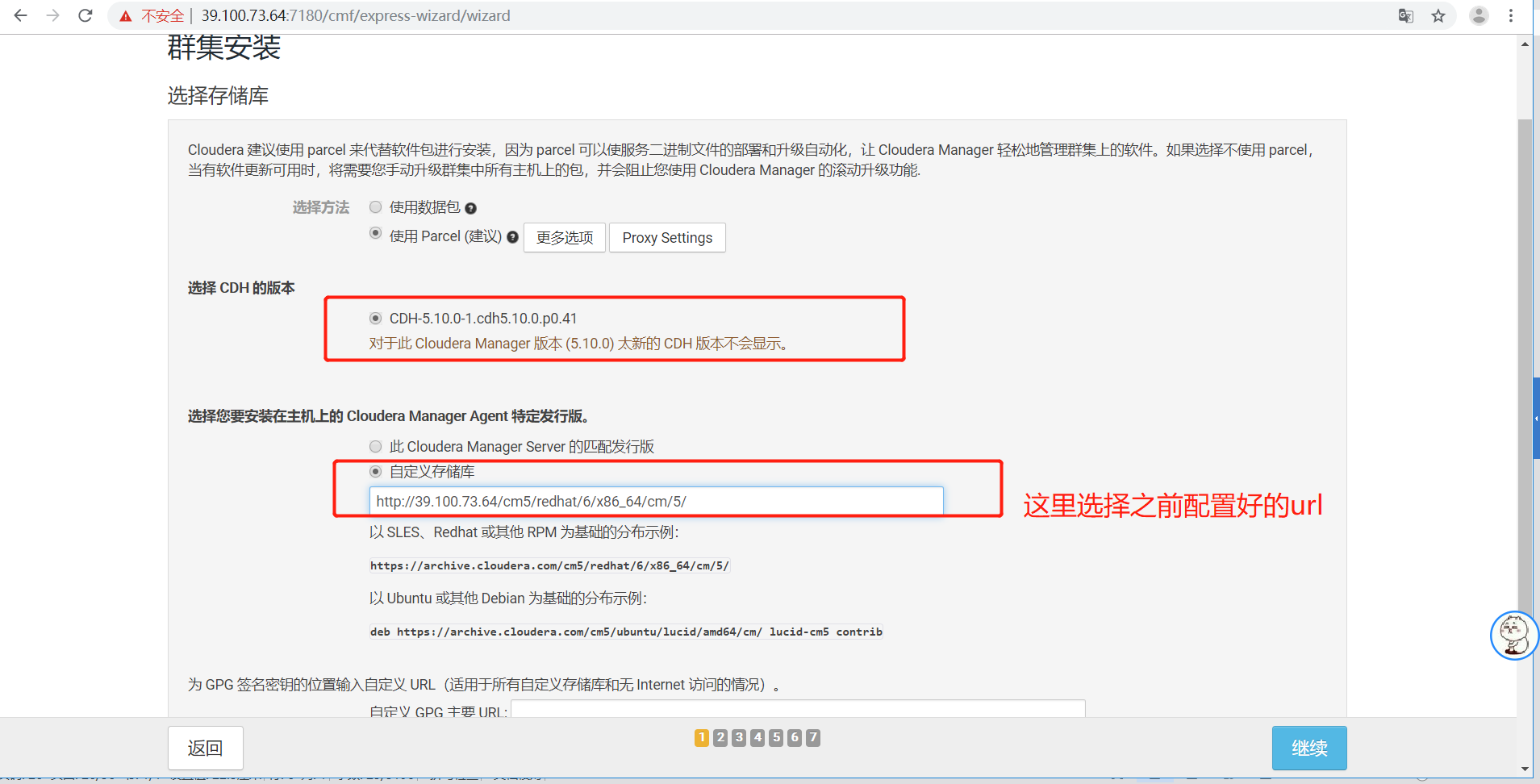
5.3、选择版本和自定义存储库
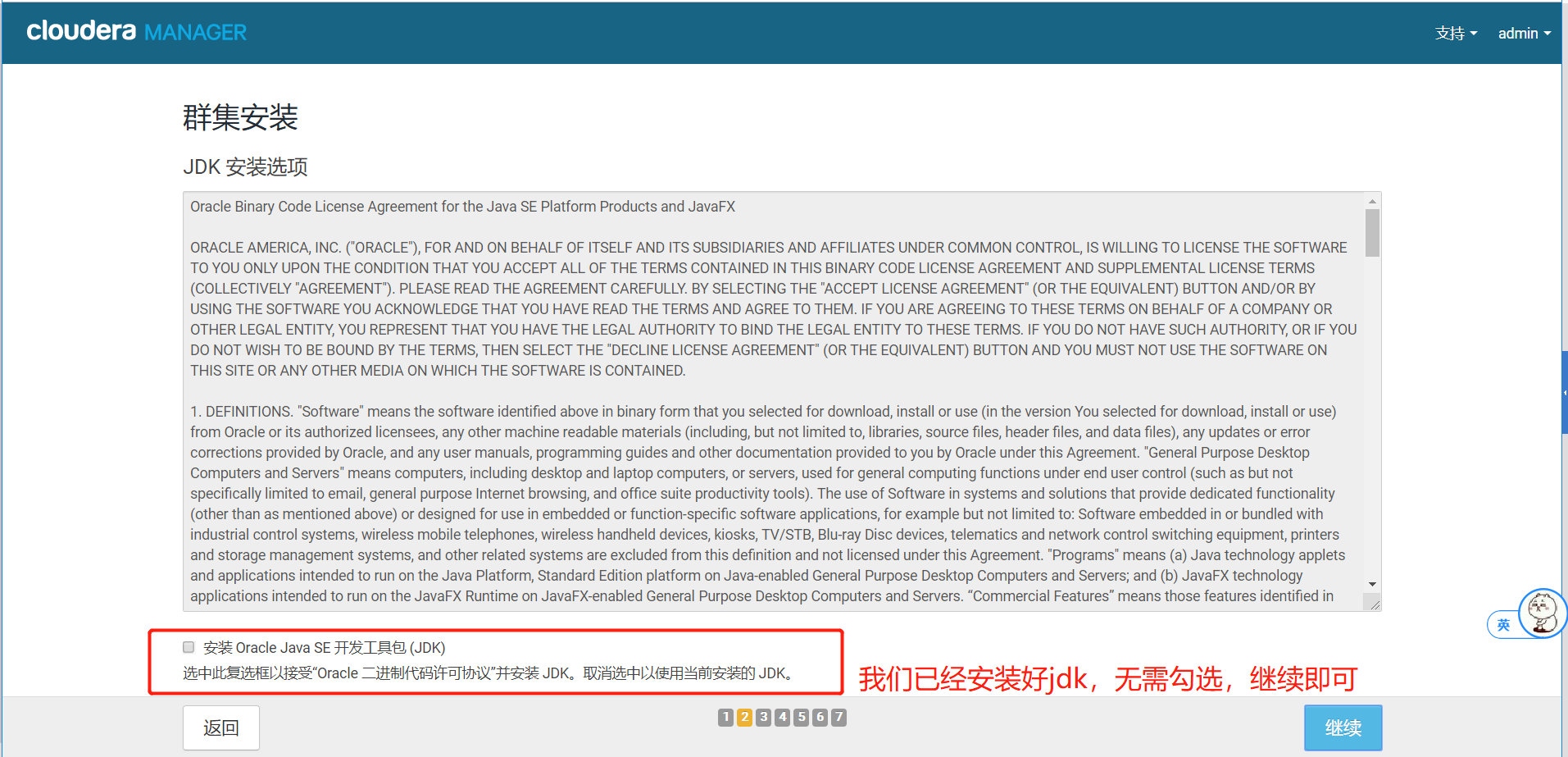
5.4、不勾选JDK
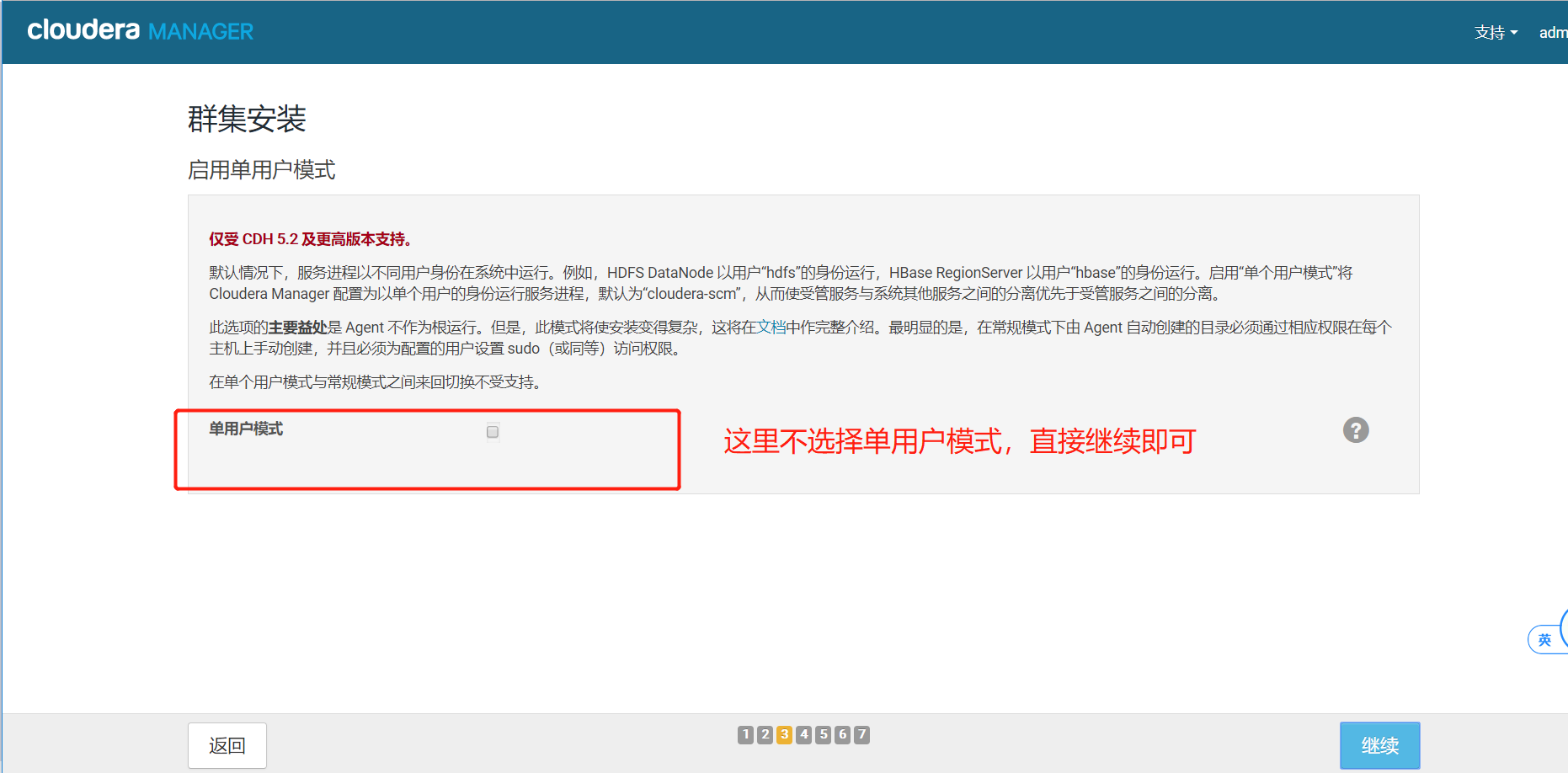
5.5、不勾选单用户模式
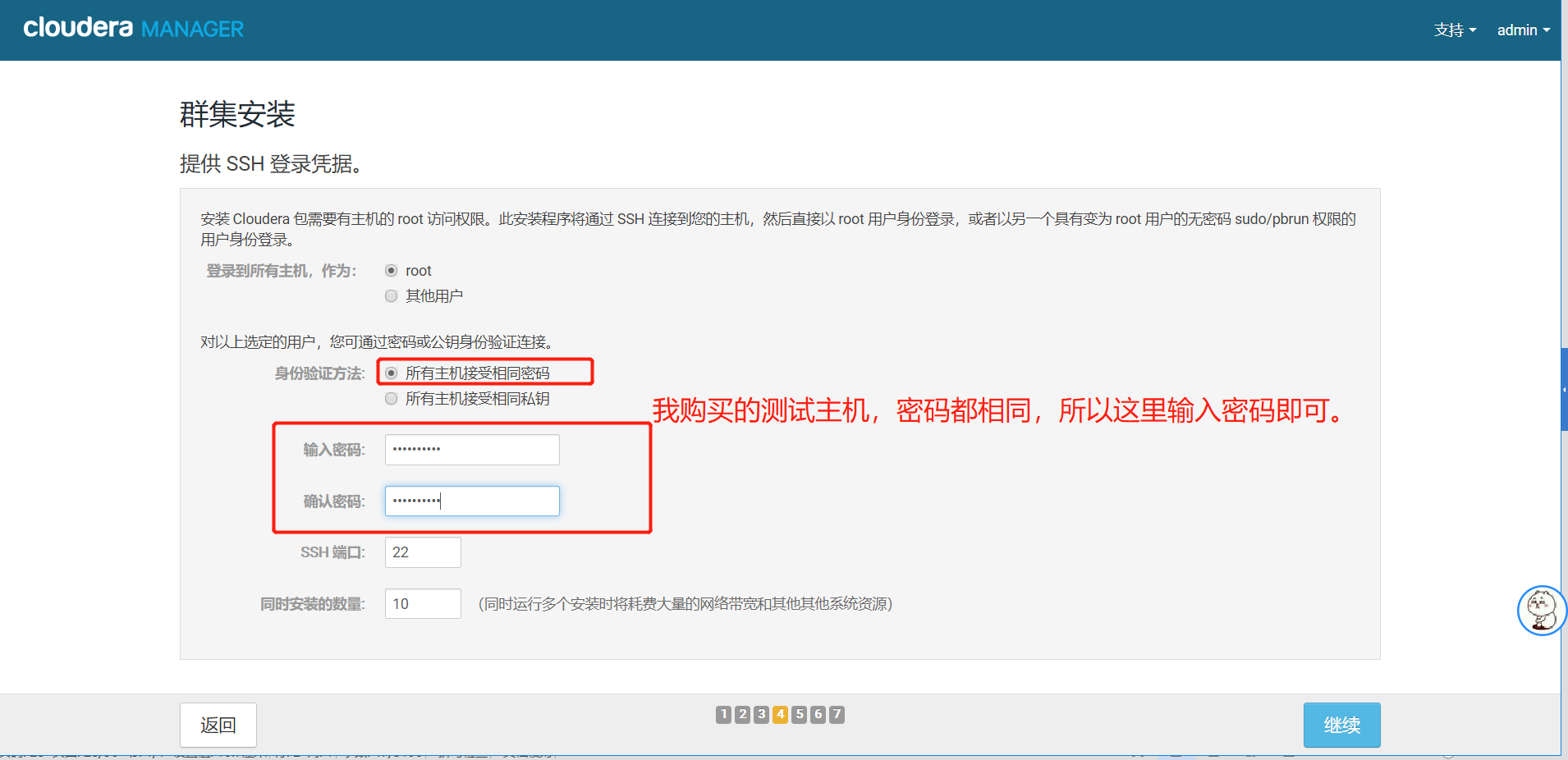
5.6、设置主机密码
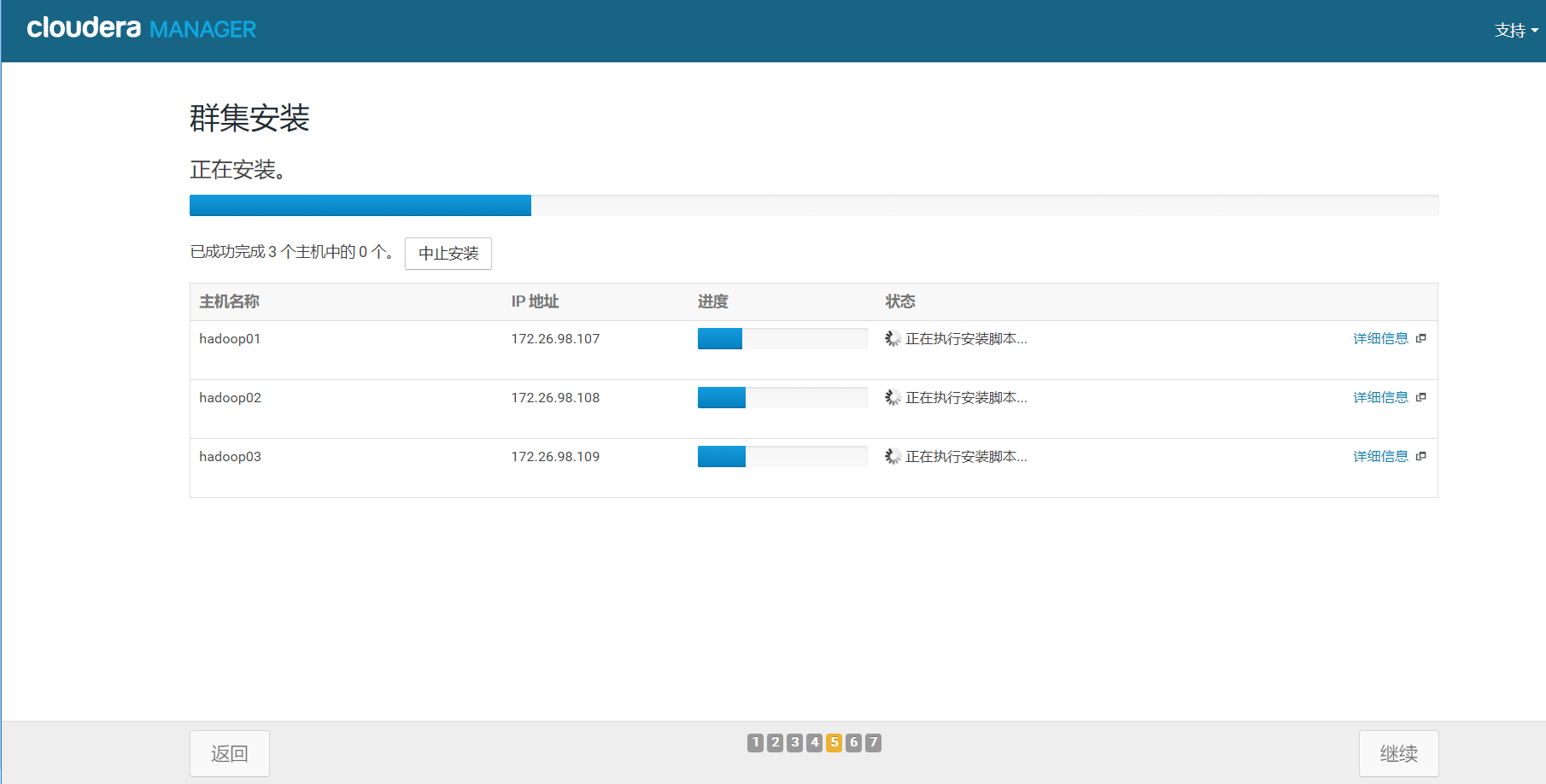
5.7、gent客户端安装
等待agent客户端安装,这一步可能会出现各种问题,通过点击出现问题的服务器的详细信息查看出现问题的地方并更改之后重启服务重新安装
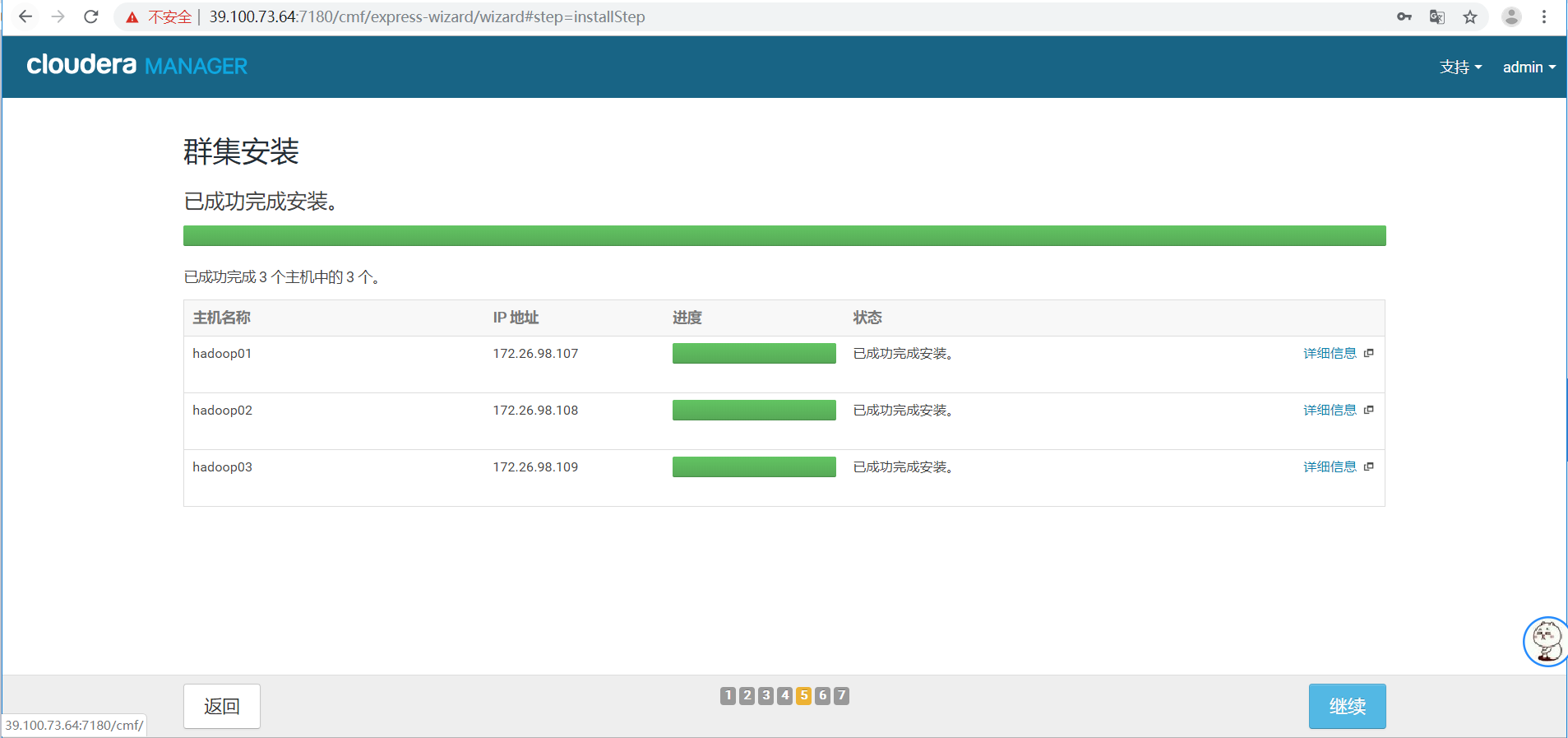
6.等待安装完成后,点击继续
7.等待安装分配完成后,点击继续
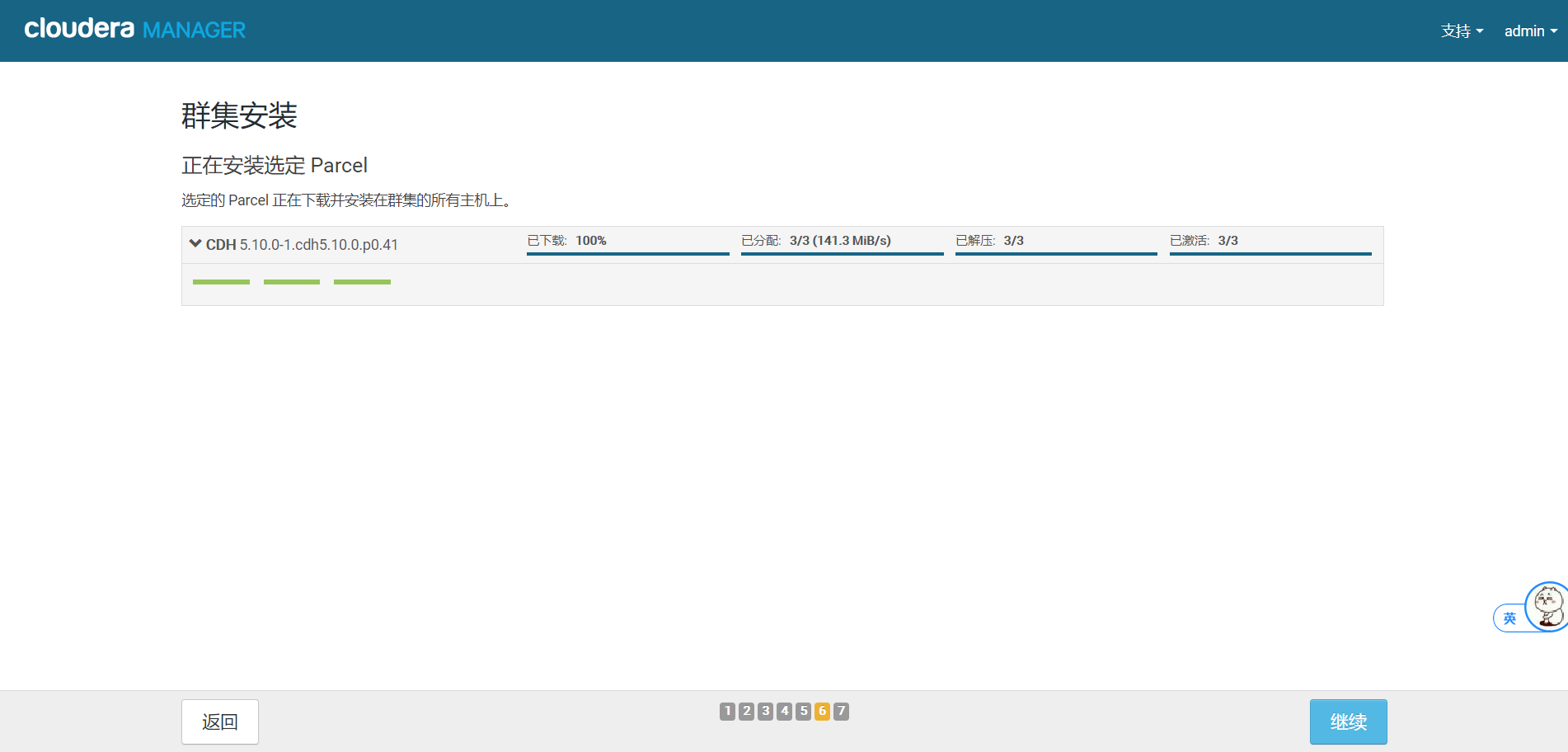
8.继续等待检查主机
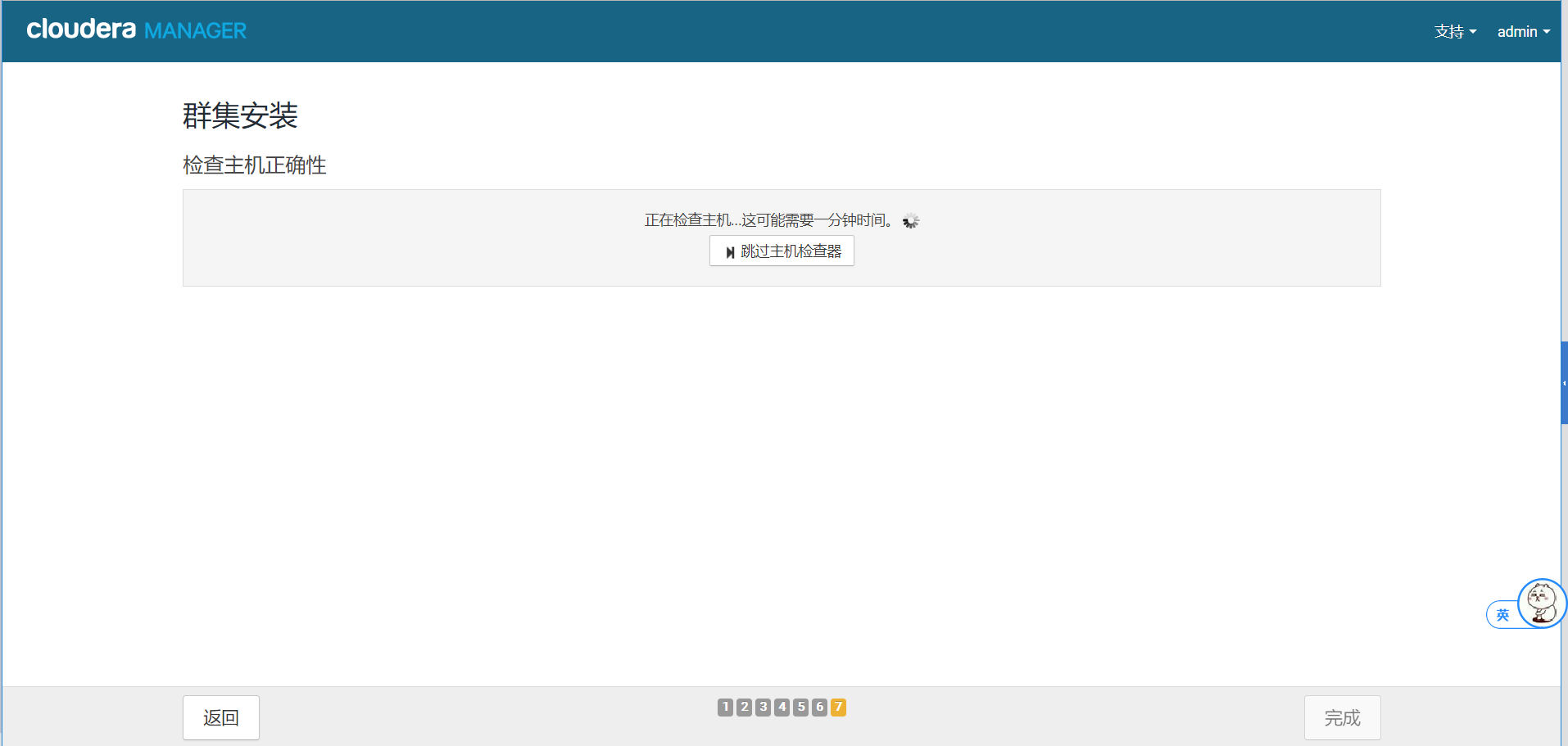
9.这里出现了警告,下面解决警告
透明大页面和swap值需要更改
将每台机器关闭大页面
执行以下命令:
在每个节点执行以下命令:
[root@hadoop01 cloudera-scm-server]# echo never > /sys/kernel/mm/transparent_hugepage/defrag
[root@hadoop01 cloudera-scm-server]# echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@hadoop01 cloudera-scm-server]# echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag'>> /etc/rc.local
[root@hadoop01 cloudera-scm-server]# echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled'>> /etc/rc.local
[root@hadoop01 cloudera-scm-server]# echo 'vm.swappiness = 10' >> /etc/sysctl.conf
[root@hadoop01 cloudera-scm-server]# sysctl –p

10.配置好以上命令以后,点击重新运行
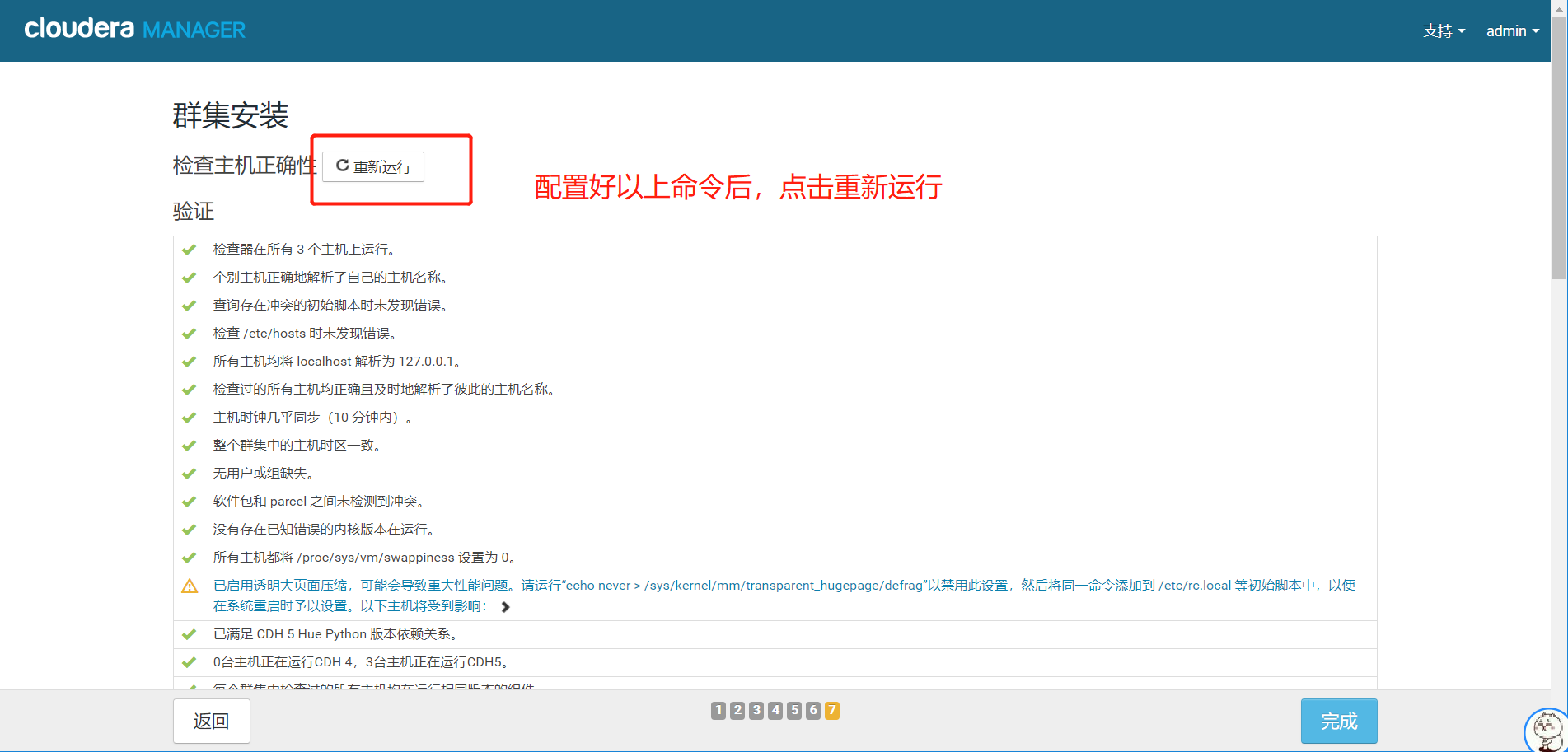
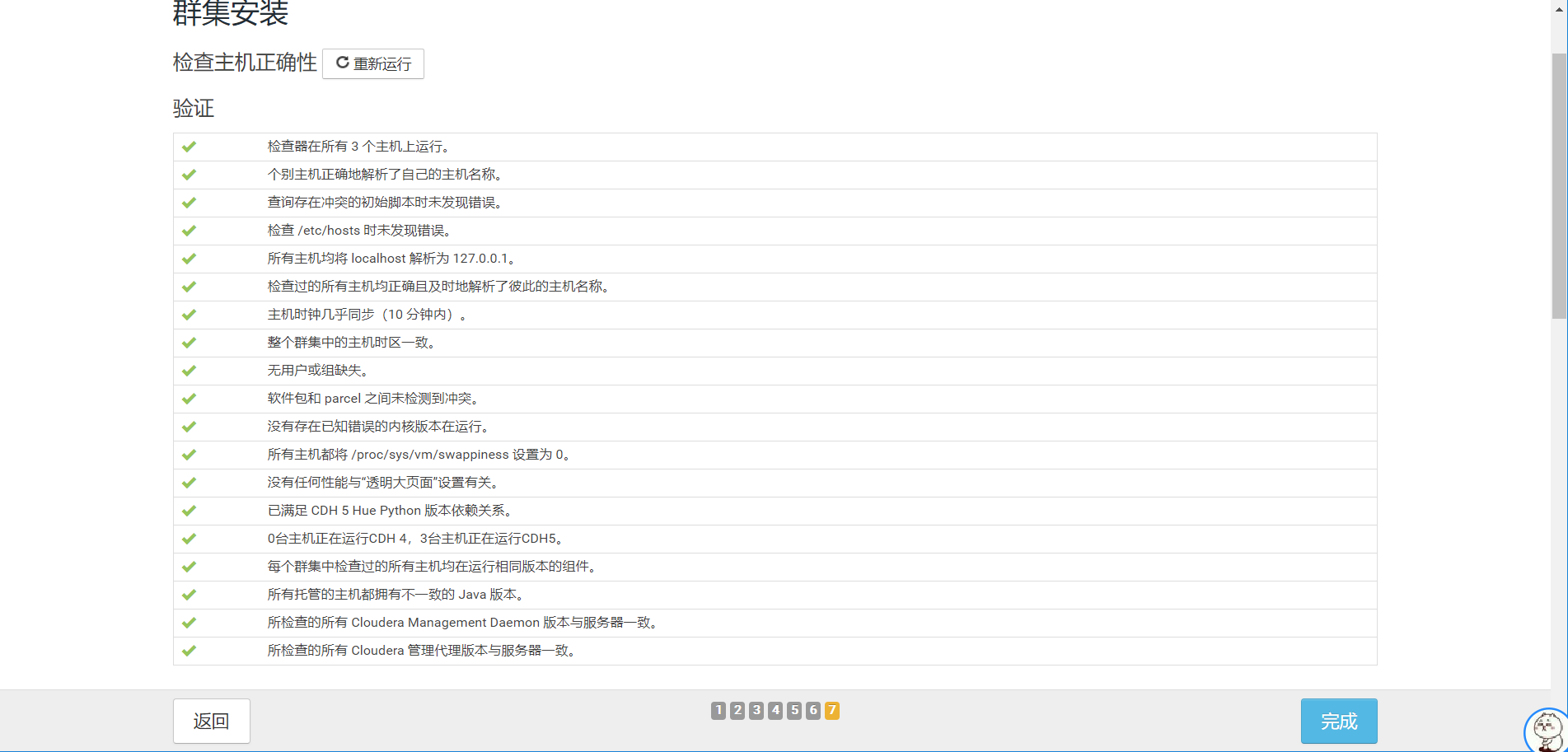
11.至此验证完成,点击完成按钮
12.集群设置
选择自定义服务,这里安装HDFS,YARN和Zookeeper,勾选好后点击继续。
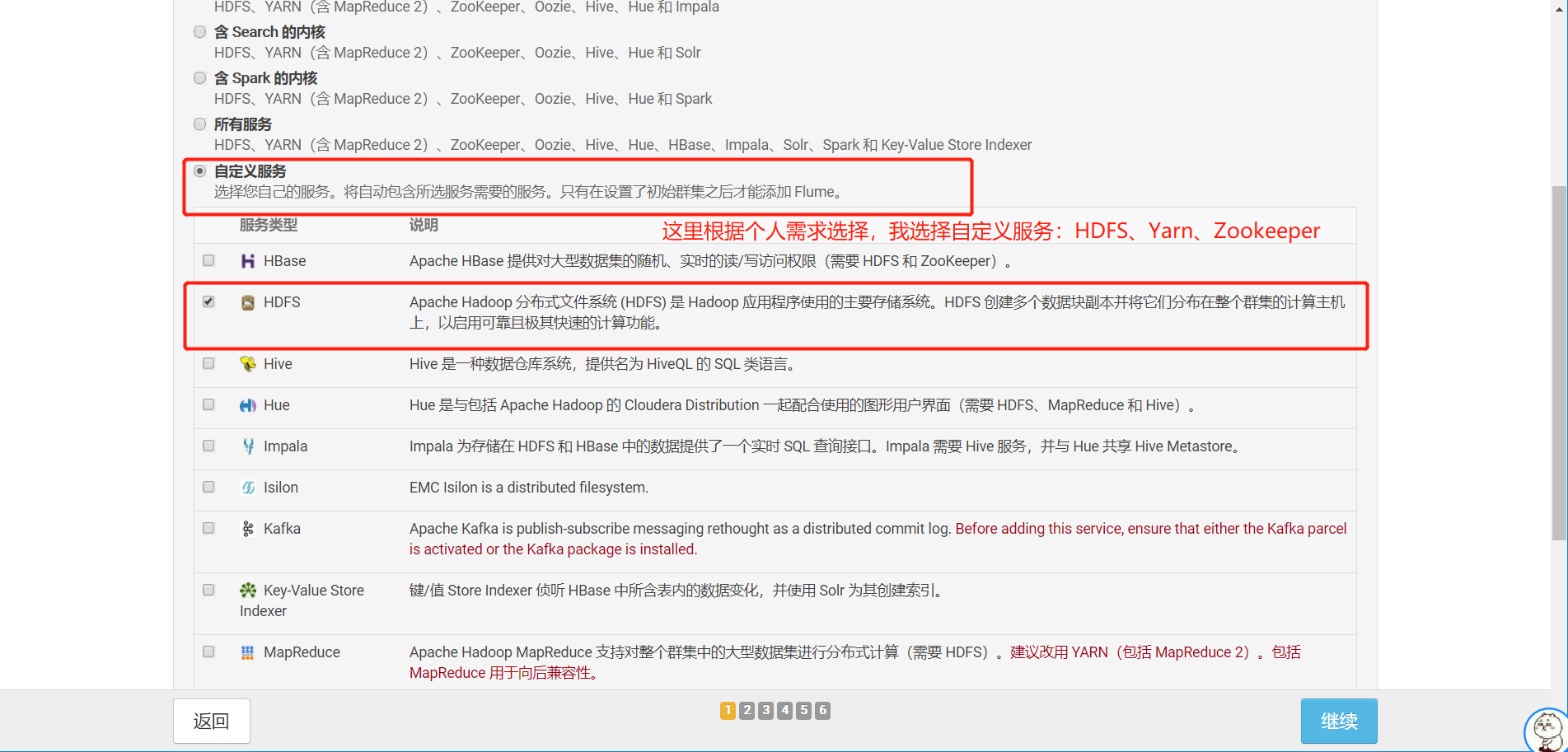
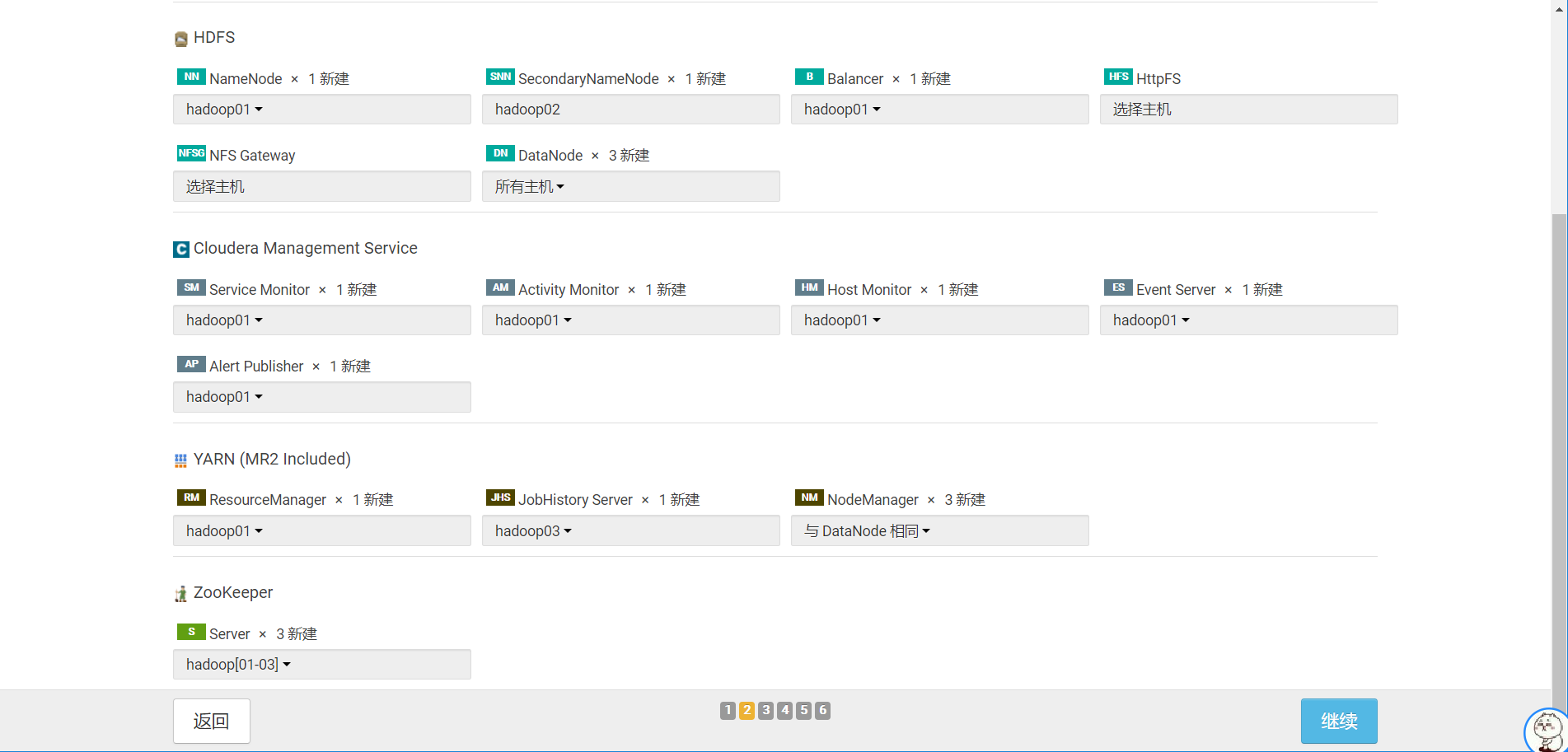
13.角色分配
根据我们之前的配置计划,选择好安装的节点有哪些(这是我的节点规划,仅供参考,实际以个人需求为主),之后点击继续。
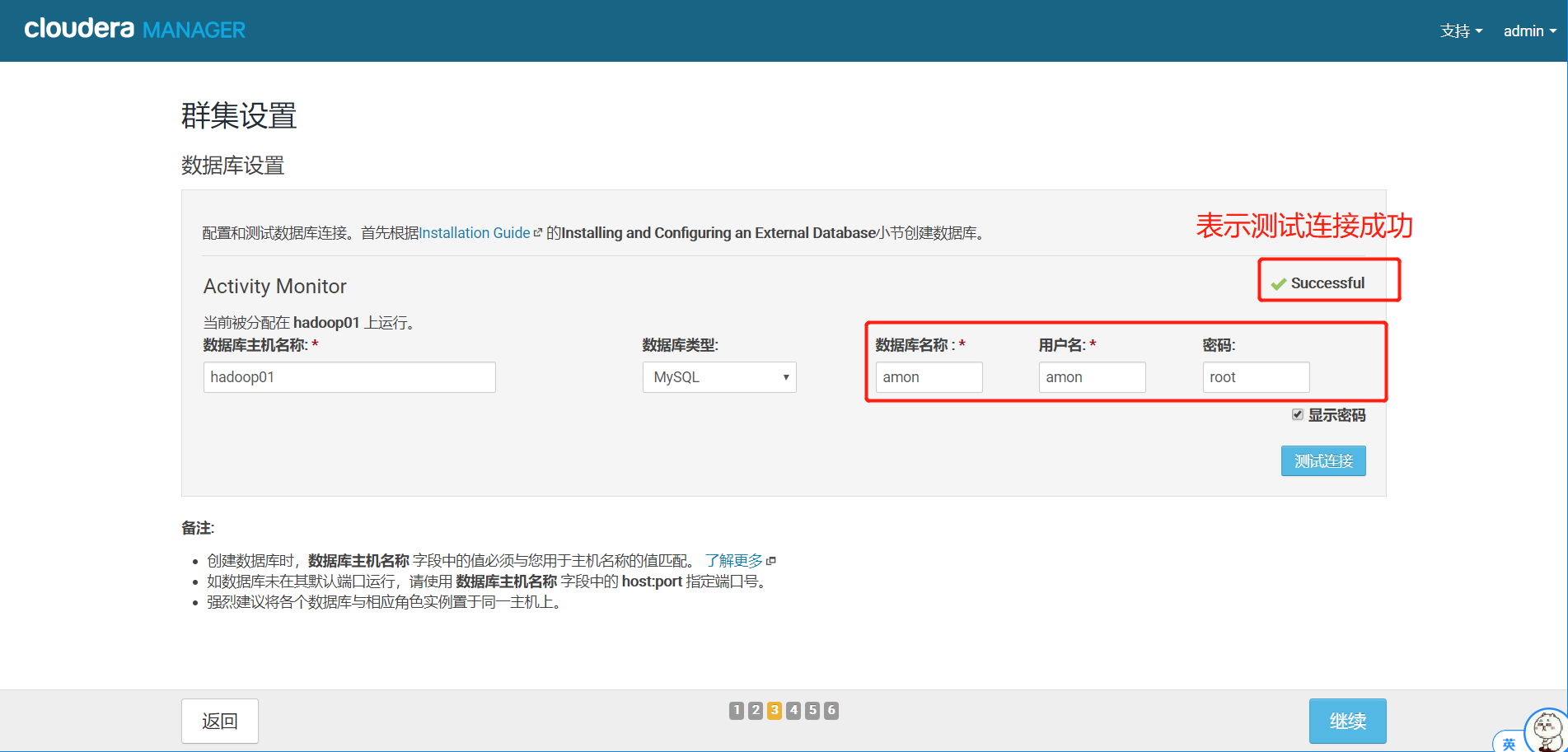
14.选择数据库
这里匹配我们之前建好的amon数据库,点击测试连接,测试成功以后,点击继续。
15.审核更改
全部默认,不要动,点击继续

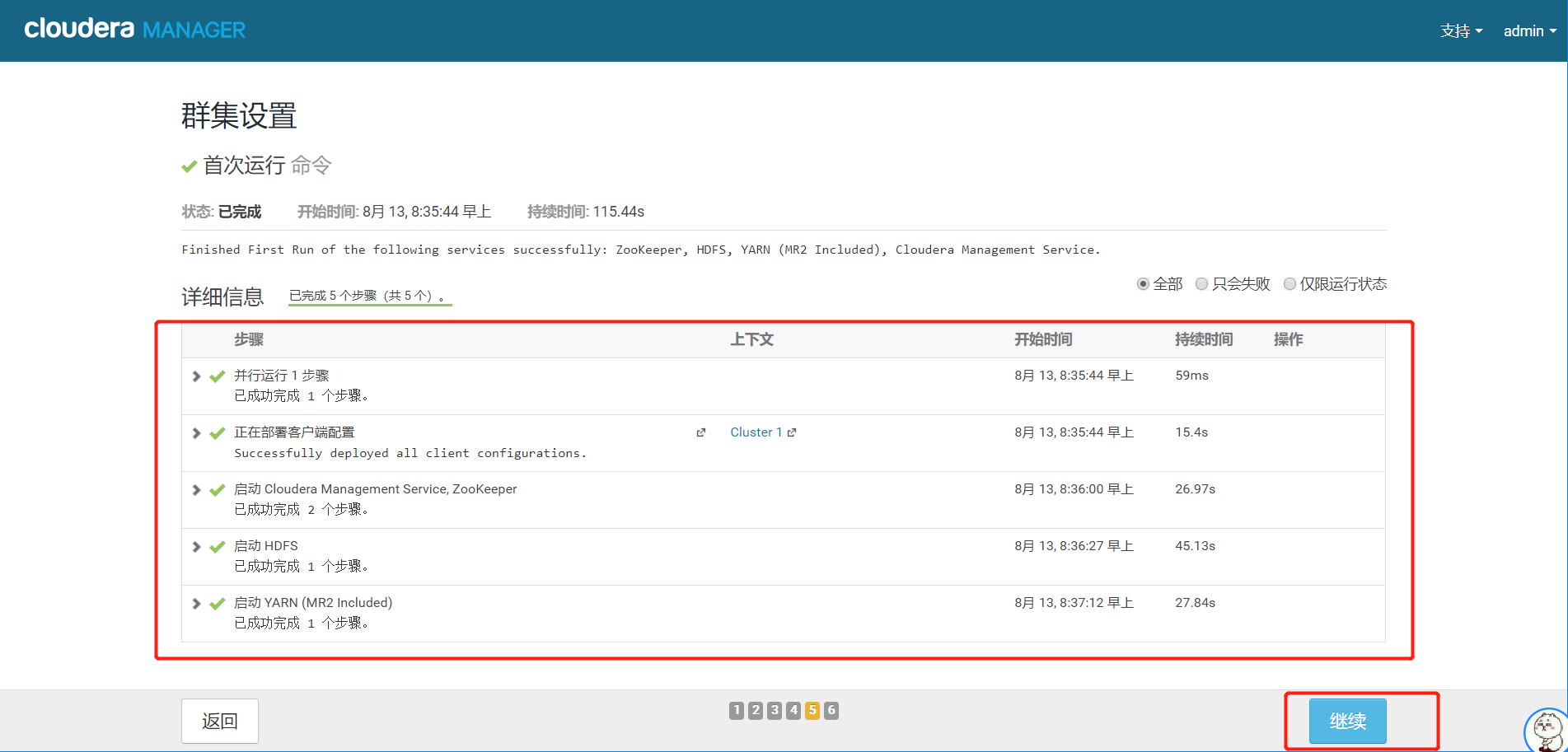
16.首次运行命令
这里根据我们的设置进行安装相关的服务等,继续等待最后的安装,安装完成后,点击继续。
17.出现以下界面,说明cdh搭建大数据平台成功!
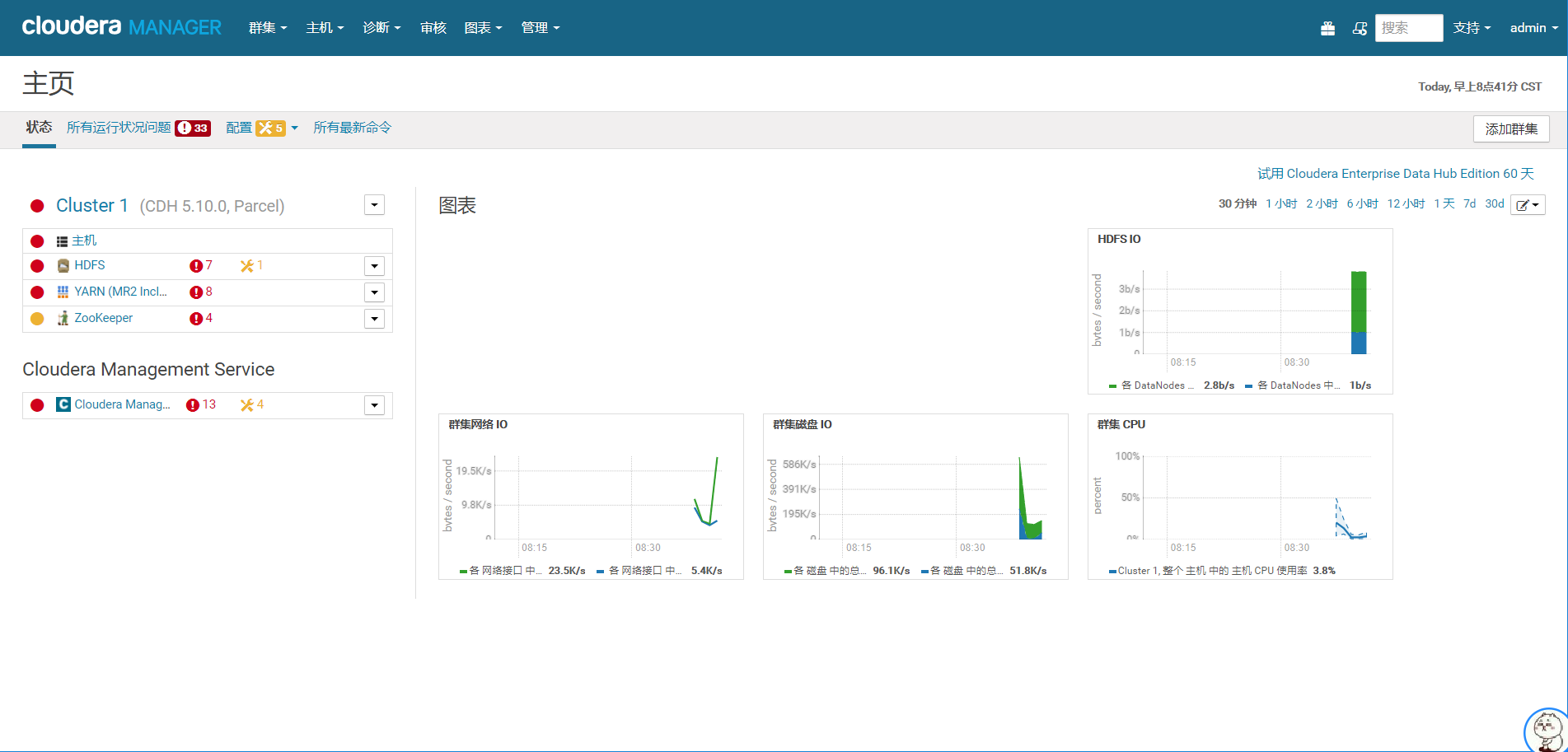
18.进入主页
这里就是安装完成后的可视化界面,在此可以通过界面来安装其他服务,比如:HBase、Spark等等;也可以看每个节点的运行状态等。
最后,很感谢大家能看到这里,如果有什么问题,我们大家一起留言讨论一下!
CDH搭建大数据集群(5.10.0)的更多相关文章
- CDH版本大数据集群下搭建的Hue详细启动步骤(图文详解)
关于安装请见 CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主推荐) Hue的启动 也就是说,你Hue ...
- Docker搭建大数据集群 Hadoop Spark HBase Hive Zookeeper Scala
Docker搭建大数据集群 给出一个完全分布式hadoop+spark集群搭建完整文档,从环境准备(包括机器名,ip映射步骤,ssh免密,Java等)开始,包括zookeeper,hadoop,hiv ...
- 关于在真实物理机器上用cloudermanger或ambari搭建大数据集群注意事项总结、经验和感悟心得(图文详解)
写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentOS6.5版本)和clo ...
- 基于Docker搭建大数据集群(七)Hbase部署
基于Docker搭建大数据集群(七)Hbase搭建 一.安装包准备 Hbase官网下载 微云下载 | 在 tar 目录下 二.版本兼容 三.角色分配 节点 Master Regionserver cl ...
- 基于Docker搭建大数据集群(一)Docker环境部署
本篇文章是基于Docker搭建大数据集群系列的开篇之作 主要内容 docker搭建 docker部署CentOS 容器免密钥通信 容器保存成镜像 docker镜像发布 环境 Linux 7.6 一.D ...
- 基于Docker搭建大数据集群(六)Hive搭建
基于Docker搭建大数据集群(六)Hive搭建 前言 之前搭建的都是1.x版本,这次搭建的是hive3.1.2版本的..还是有一点细节不一样的 Hive现在解析引擎可以选择spark,我是用spar ...
- CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主推荐)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- CDH6.2.0 搭建大数据集群
1. 资料准备 现在官网https://www.cloudera.com 需要注册账号,未来可能会收费等问题,十分麻烦,这里有一份我自己百度云的备份 链接: https://pan.baidu.com ...
- CDH版本大数据集群下搭建Avro(hadoop-2.6.0-cdh5.5.4.gz + avro-1.7.6-cdh5.5.4.tar.gz的搭建)
下载地址 http://archive.cloudera.com/cdh5/cdh/5/avro-1.7.6-cdh5.5.4.tar.gz
随机推荐
- C#对config.ini文件进行读取和修改
C#对config.ini文件进行读取和修改: public partial class Patrolcar : Form之后可以加入如下类: #region public class IniFile ...
- 【荐】CSS实现漂亮实用带箭头的流程图
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- ts中的类
TypeScript 除了实现了所有 ES6 中的类的功能以外,还添加了一些新的用法(部分ES7). 一.ES6中类的主要用法: 1.使用 class 定义类,使用 constructor 定义构造函 ...
- C#处理不同的JSON数据
https://blog.csdn.net/dayu9216/article/details/78465681 网络中数据传输经常是xml或者json,现在做的一个项目之前调其他系统接口都是返回的xm ...
- HBase 中读 HDFS 调优
HDFS Read调优 在基于 HDFS 存储的 HBase 中,主要有两种调优方式: 绕过RPC的选项,称为short circuit reads 开启让HDFS推测性地从多个datanode读数据 ...
- Django_模板
1. 模板变量 小插曲 2. 模板点语法和标签 2.1 获取属性 2.2 调用方法 2.3 获取索引 2.4 获取字典中的值 3. 模板中的标签 3.1 if 3.2 for 3.3 注释 乘除 整除 ...
- JavaScript错误-throw、try和catch
try 语句测试代码块的错误. catch 语句处理错误. throw 语句创建自定义错误. finally 语句在 try 和 catch 语句之后,无论是否有触发异常,该语句都会执行. JavaS ...
- Nginx可以做什么
Nginx能做什么 ——反向代理 ——负载均衡 ——HTTP服务器(动静分离) ——正向代理 反向代理 反向代理应该是Nginx做的最多的一件事了,什么是反向代理呢,以下是百度百科的说法:反向代理(R ...
- 百炼OJ - 1003 - Hangover
题目链接 思路 求一个数列的前n项和(1/2, 1/3, ...., 1/n)大于所给数所需的项数. #include<stdio.h> int main() { float a; whi ...
- Wx-公众号-关闭内置浏览器页面,返回公众号橱窗
方法一: pushHistory(); function pushHistory() { var state = { title: "title", url: "#&qu ...