小爬爬6: 网易新闻scrapy+selenium的爬取
国内国际,军事航空,无人机都是动态加载的,先不管其他我们最后再搞中间件
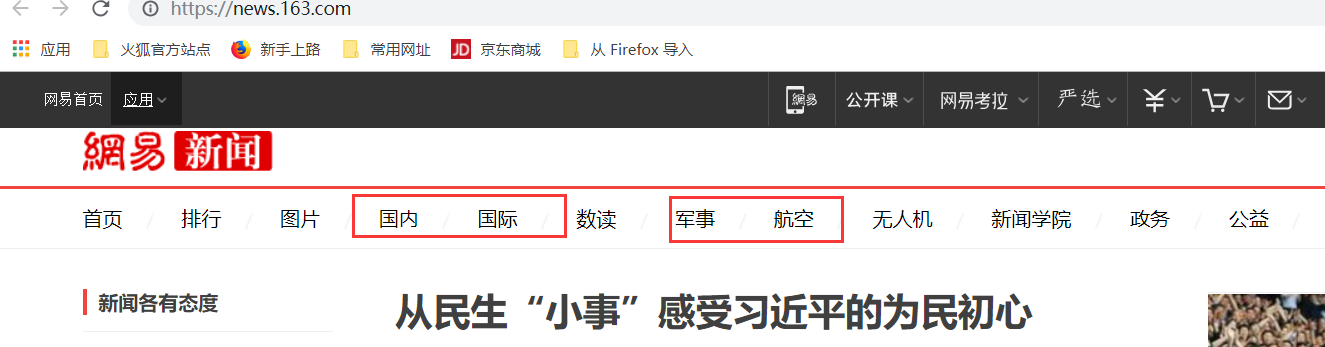
2.
我们可以查看到"国内"等板块的位置

新建一个项目,创建一个爬虫文件
下面,我们进行处理:
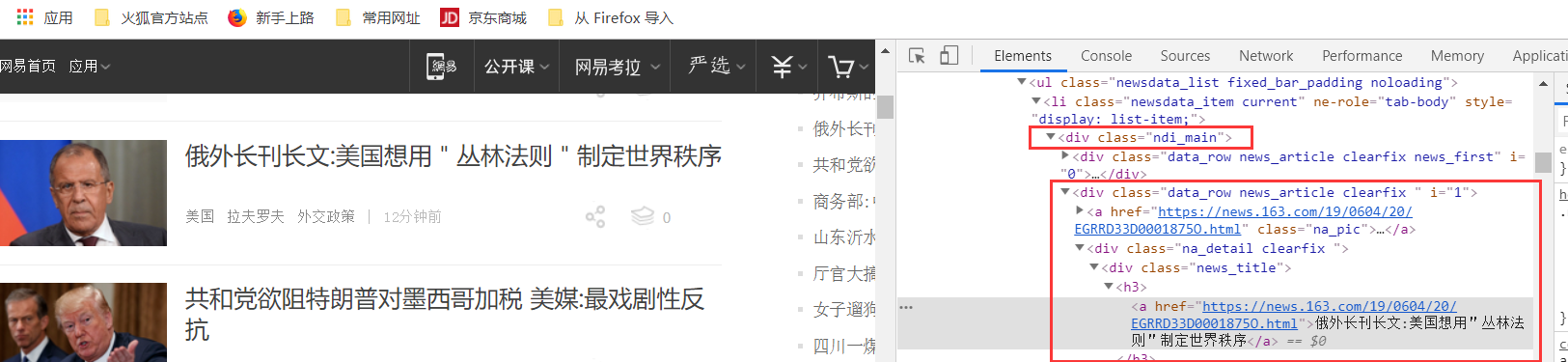
仔细查找二级标签的位置:
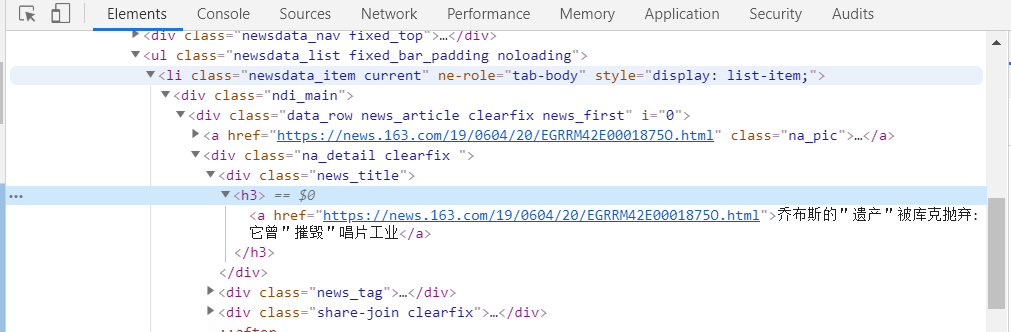
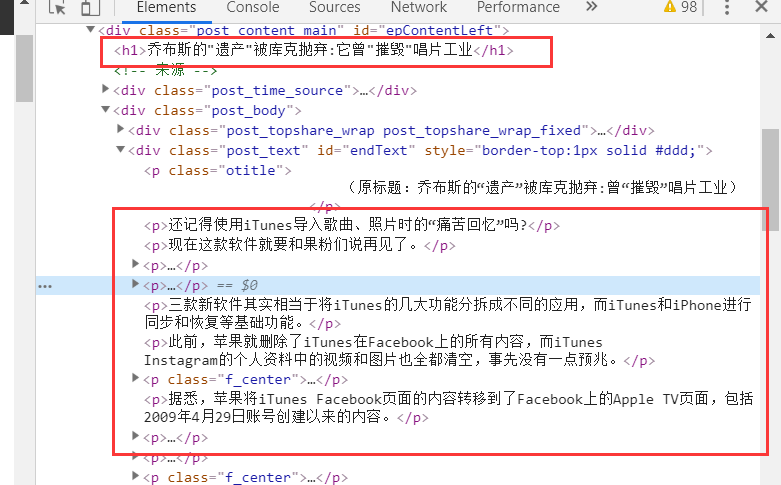
每一段的信息都储存在p标签内部
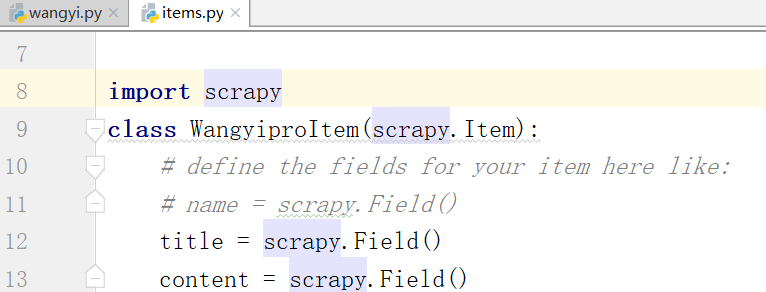
items.py写两个字段
导入下面的内容:
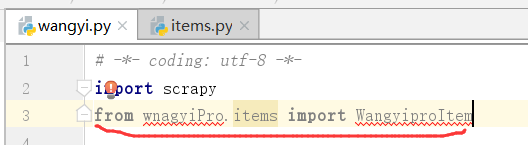
爬虫文件wangyi.py
# -*- coding: utf- -*-
import scrapy
from wnagyiPro.items import WangyiproItem class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://news.163.com/']
def parse(self, response):
li_list=response.xpath('//div[@class="ns_area"]/ul/li')
#拿到列表中的34678
for index in [,,,,]:
li=li_list[index]
new_url=li.xpath('./a/@href').extract_first()
#是五大版块对应的url进行请求发送
yield scrapy.Request(url=new_url,callback=self.parse_news)
#解析每个版块对应的数据
#是用来解析每一个版块对应的新闻数据(新闻的标题)
def parse_news(self,response):
div_list=response.xpath('//div[@class="ndi_main"]/div')
for div in div_list:
title=div.xpath("./div/div[1]/h3/a/text()").extract_first()
news_detail_url=div.xpath("./div/div[1]/h3/a/@href").extract_first() #实例化item对象将解析到的标题和内容存储到item对象中
item=WangyiproItem()
item['title']=title
#对详情页的url进行手动请求发送一遍回去新闻的内容
yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item})
def parse_detail(self,response):
item=response.meta['item'] #信息的传递
#通过response解析出新闻的内容
content=response.xpath('//div[@id="endText"]//text()').extract()
content=''.join(content)
item['content']=content
yield item
我们可以在管道中打印一下item
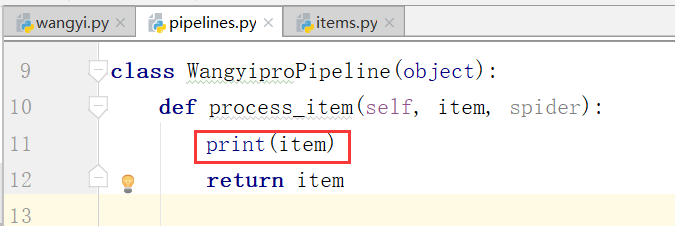
下面再在配置文件中开启管道


现在,我们存在的问题就是,没有动态加载出来的数据,怎么处理?
响应对象存在问题,我们需要修改,五大板块对应的响应对象,其他不需要修改,下面我们处理中间件文件
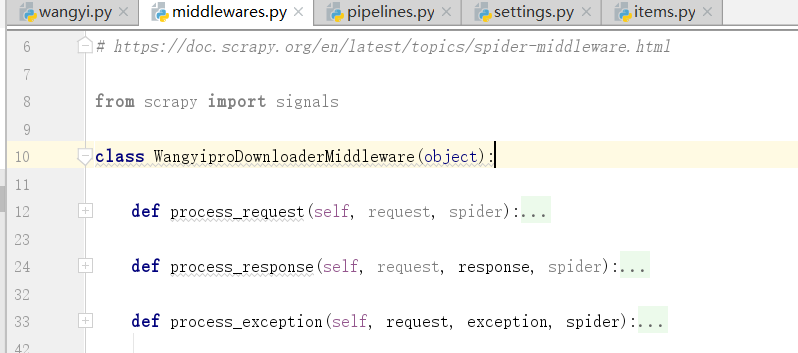
我们只需要保留这一个类中的三个process方法即可
我们需要对第一个页面中进行修改
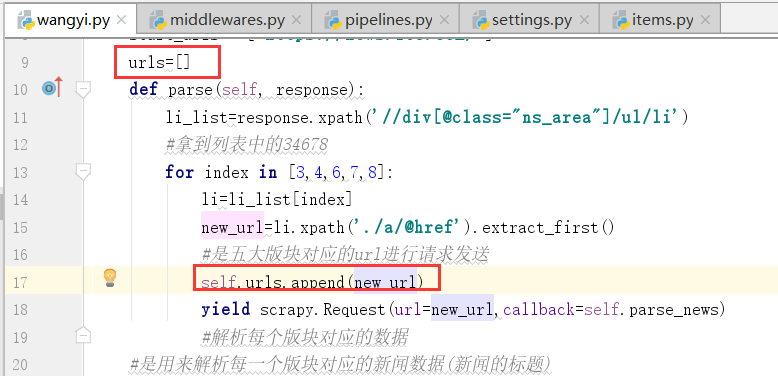
#上边的urls列表最终存放的就是五大板块对应的url
我们需要在中间件写新的response需要在爬虫文件继续写内容
开启中间件:

君子协定修改成False,

下面开始执行爬虫

重新复制首页的xpath
//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div
出现下面的错误需要进行修改下面的方法:

爬虫文件wangyi.py内容:
# -*- coding: utf- -*-
import scrapy
from wangyiPro.items import WangyiproItem
from selenium import webdriver class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://news.163.com/']
#浏览器实例化的操作只会被执行一次
bro=webdriver.Chrome(executable_path='chromedriver.exe')
urls=[] #最终存放的就是五个板块对应的url
def parse(self, response):
li_list=response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
#拿到列表中的34678
for index in [,,,,]:
li=li_list[index]
new_url=li.xpath('./a/@href').extract_first()
#是五大版块对应的url进行请求发送
self.urls.append(new_url)
yield scrapy.Request(url=new_url,callback=self.parse_news)
#解析每个版块对应的数据
#是用来解析每一个版块对应的新闻数据(新闻的标题)
def parse_news(self,response):
div_list=response.xpath('//div[@class="ndi_main"]/div')
for div in div_list:
title=div.xpath("./div/div[1]/h3/a/text()").extract_first()
news_detail_url=div.xpath("./div/div[1]/h3/a/@href").extract_first() #实例化item对象将解析到的标题和内容存储到item对象中
item=WangyiproItem()
item['title']=title
#对详情页的url进行手动请求发送一遍回去新闻的内容
yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item})
def parse_detail(self,response):
item=response.meta['item'] #信息的传递
#通过response解析出新闻的内容
content=response.xpath('//div[@id="endText"]//text()').extract()
content=''.join(content)
item['content']=content
yield item
def closed(self,spider): #关闭
print('爬虫整体结束!!!')
self.bro.quit()
中间件中的处理:
# -*- coding: utf- -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from scrapy.http import HtmlResponse
from time import sleep
class WangyiproDownloaderMiddleware(object): def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware. # Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
#拦截整个工程中所有的响应对象,一请求对应一响应
def process_response(self, request, response, spider):
if request.url in spider.urls:
#就要将其对应的响应对象进行处理
#获取了在爬虫类中定义号的浏览器对象
bro=spider.bro #包含动态加载出来的数据
bro.get(request.url) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep()
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep()
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep()
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep() #获取携带了新闻数据的页面源码数据
page_text=bro.page_source #spider.bro.current_url==request.url
new_response=HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request)
return new_response
else:
return response def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass

网易需求:
1.爬取五大板块对应的新闻
2.爬取新闻标题和内容,将数据存储到mysql 数据库中
3.创建一个表,三列id,title,content
4.notype可能是在解析标题时候出现的错误
scrapy中应用selenium的编码流程:
- 爬虫类中定义一个属性bro
- 爬虫类中重写父类的一个方法closed,在该方法中关闭bro
- 在中间件类的process_response中编写selenium自动化的相关操作
关键字的 提取:
百度AI:分类
点击控制台:
自然语言处理===>技术文档===>
对关键字进行处理
第四keyword&&第五是分类
其实是个时间的问题.
有时间再搞.(答辩)
小爬爬6: 网易新闻scrapy+selenium的爬取的更多相关文章
- scrapy+selenium 爬取淘宝商城商品数据存入到mongo中
1.配置信息 # 设置mongo参数 MONGO_URI = 'localhost' MONGO_DB = 'taobao' # 设置搜索关键字 KEYWORDS=['小米手机','华为手机'] # ...
- 小爬爬5:重点回顾&&移动端数据爬取1
1. ()什么是selenium - 基于浏览器自动化的一个模块 ()在爬虫中为什么使用selenium及其和爬虫之间的关联 - 可以便捷的获取动态加载的数据 - 实现模拟登陆 ()列举常见的sele ...
- scrapy中使用selenium来爬取页面
scrapy中使用selenium来爬取页面 from selenium import webdriver from scrapy.http.response.html import HtmlResp ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
- [python爬虫] Selenium定向爬取PubMed生物医学摘要信息
本文主要是自己的在线代码笔记.在生物医学本体Ontology构建过程中,我使用Selenium定向爬取生物医学PubMed数据库的内容. PubMed是一个免费的搜寻引擎,提供生物医学方 ...
- scrapy模拟浏览器爬取验证码页面
使用selenium模块爬取验证码页面,selenium模块需要另外安装这里不讲环境的配置,我有一篇博客有专门讲ubuntn下安装和配置模拟浏览器的开发 spider的代码 # -*- coding: ...
- 使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息 转载请注明出处. 爬取目标:每个电影的评分.名称.时长.主演.和类型 爬取思路: 源文件:(有注释) from selenium import webd ...
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页
Python3.x:Selenium+PhantomJS爬取带Ajax.Js的网页 前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但 ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
随机推荐
- Python+Django+Ansible Playbook自动化运维项目实战
Python+Django+AnsiblePlaybook自动化运维项目实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单 ...
- Mycat+MySQL 主从复制
一.主从复制搭建(新环境5.6.33)1.设置复制Master配置信息 [mysqld] #repl master库 server \logbin\mysql-bin max_binlog_size= ...
- CentOS 7 忘记root密码的修改方法
1.开机按esc 2.选择CentOS Linux (3.10.0-693.......) 按 e 键: 3.光标移动到 linux 16 开头的行,找到 ro 改为 rw init=sysr ...
- jquery校验是否为空
function lang(key) { mylang = { 'ls_input_myb': '请输入您的账户', 'ls_myb_email': '漫游币账户为邮箱地址', 'ls_login_p ...
- 关于SQL查询效率 主要针对sql server
1.关于SQL查询效率,100w数据,查询只要1秒,与您分享:机器情况p4: 2.4内存: 1 Gos: windows 2003数据库: ms sql server 2000目的: 查询性能测试,比 ...
- JQuery学习:事件绑定&入口函数&样式控制
1.基础语法学习: 1.事件绑定 2.入口函数 3.样式控制 <!DOCTYPE html> <html lang="en"> <head> & ...
- Luogu P4768 [NOI2018]归程(Dijkstra+Kruskal重构树)
P4768 [NOI2018]归程 题面 题目描述 本题的故事发生在魔力之都,在这里我们将为你介绍一些必要的设定. 魔力之都可以抽象成一个 \(n\) 个节点. \(m\) 条边的无向连通图(节点的编 ...
- sublime中用less实现css预编译
实现css预编译的方式有很多,听说glup很流行而且功能也很强大,但是就目前的工作而言,仅要css预编译和YUIcompress就够了,接下来切入正题 Less 是一门 CSS 预处理语言,它扩展了 ...
- java-多线程安全-锁
一 同步函数 1.1 一般的方法 同步的另一种体现形式:同步函数. 同步函数使用的锁是哪个?经过分析:大概猜的是this,因为函数必须被对象调用. 验证:写一个同步代码块,写一个同步函数,如果同步代码 ...
- NOIP模拟赛 6.29
2017-6-29 NOIP模拟赛 Problem 1 机器人(robot.cpp/c/pas) [题目描述] 早苗入手了最新的Gundam模型.最新款自然有着与以往不同的功能,那就是它能够自动行走, ...