es 6.x scroll用法
我们可以使用from +size来获取所有数据,但是,如果数据量大的时候,这样的操作开销很大,这时候可以使用scroll操作
1.第一步发起一个scroll 的post请求,带上参数scroll=1m (1m的意思是1分钟的意思)
POST /twitter/_search?scroll=1m
{
"size": 100,
"query": {
"match" : {
"title" : "elasticsearch"
}
}
} 这一步会得到一个_scroll_id
2. 使用第一步得到的_scroll_id 来翻页,一直执行这个请求,就可以得到所有的数据了
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAA3okgWbkYzT1lBcjRUS0NmbkRnclY3bElmUQ=="
} 注意:
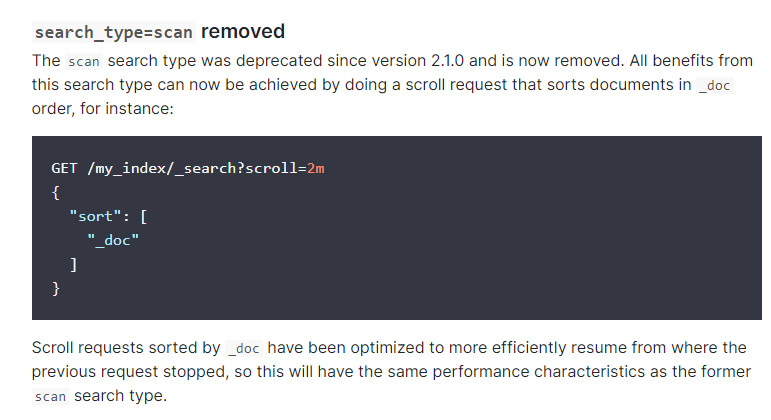
1. 如果想加快索引,第一步加上sort选项, 有些文章会说使用 search_type=scan ,但这个选项是要es 2.1版本之前才有用,之后的版本就被弃用了,改成sort选项了
GET /_search?scroll=1m
{
"sort": [
"_doc"
]
}
2.scroll参数说明,这个表示_scroll_id的有效期有多久,如果超过这个有效期,那再去翻页就会得到404 error,并且每次翻页都会重置有效期,所以这个有效期只需要大于前后两次翻页的时间(也就是你处理一页数据的时间)

3. scrapy去请求翻页,很有可能因为_scroll_id没有变化,造成请求重复而被放弃,一定要加上dont_filter=True
4.我在做这个测试的时候,发现window测试电脑用外网地址去请求centos服务器的ES数据很慢,而用内网中的linux计算机去请求同样的服务器数据,时间快了20倍
参考
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/breaking_50_search_changes.html
es 6.x scroll用法的更多相关文章
- ElasticSearch 学习记录之ES短语匹配基本用法
短语匹配 短语匹配故名思意就是对分词后的短语就是匹配,而不是仅仅对单独的单词进行匹配 下面就是根据下面的脚本例子来看整个短语匹配的有哪些作用和优点 GET /my_index/my_type/_sea ...
- ES模块的基本用法常见使用问题
本文作者:高峰,360奇舞团前端工程师,W3C WoT工作组成员. ES6中引入了模块(Modules)的概念,相信大家都已经挺熟悉的了,在日常的工作中应该也都有使用. 本文会简单介绍一下ES模块的优 ...
- jQuery之scroll用法实例
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- ElasticSearch - 解决ES的深分页问题 (游标 scroll)
https://www.jianshu.com/p/f4d322415d29 1.简介 ES为了避免深分页,不允许使用分页(from&size)查询10000条以后的数据,因此如果要查询第10 ...
- ES 入门之一 安装ElasticSearcha
安装ElasticSearcha 学习ES也有快一个月了,但是学习的时候一直没有总结.以前没有总结是因为感觉不会的很多,现在对ES有一点了解了.索性就从头从安装到使用ES做一个详细的总结,也分享给其他 ...
- ElasticSearch 学习记录之ES几种常见的聚合操作
ES几种常见的聚合操作 普通聚合 POST /product/_search { "size": 0, "aggs": { "agg_city&quo ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- ElasticSearch 学习记录之ES高亮搜索
高亮搜索 ES 通过在查询的时候可以在查询之后的字段数据加上html 标签字段,使文档在在web 界面上显示的时候是由颜色或者字体格式的 GET /product/_search { "si ...
- ElasticSearch 学习记录之ES查询添加排序字段和使用missing或existing字段查询
ES添加排序 在默认的情况下,ES 是根据文档的得分score来进行文档额排序的.但是自己可以根据自己的针对一些字段进行排序.就像下面的查询脚本一样.下面的这个查询是根据productid这个值进行排 ...
随机推荐
- Jekyll 摘要
在 Windows 上安装 Requirements Permalink Ruby version 2.4.0 or above, including all development headers ...
- ZooKeeper启动报错:My id 3 not in the peer list
错误描述: 解决方法:查看zookeeper-3.4.2/conf目录下 编辑zoo.cfg文件 发现第三行有问题修改
- gulp常用插件之gulp-size使用
更多gulp常用插件使用请访问:gulp常用插件汇总 gulp-size这是一款显示项目的大小插件. 更多使用文档请点击访问gulp-size工具官网. 安装 一键安装不多解释 npm install ...
- CF468A | 24 Game 找规律+打表
(翻译版本来自 Luogu by lonelysir ) 题目描述 小X一直很喜欢一个纸牌游戏:"24点",但最近他发现这个游戏太简单了,所以他发明了一个新游戏. 你有一个整数序列 ...
- 题解【洛谷P5767】[NOI1997]最优乘车
题面 一道很经典的最短路模型转换问题. 考虑如何建图. 我们可以发现,对于每一条公交线路,可以将这条线路上 可以到达的两个点 连一条权值为 \(1\) 的边. 获取一条公交线路上的每一个点可以使用读取 ...
- pythonCSV内置模块应用
一.Python内置模块CSV CSV,即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符.如下图所示: CSV类似于Excel格式 很多 ...
- H5_0012:js事件冒泡和捕获
捕获(capture)和冒泡(bubble)是事件传播过程中的两个概念, 比如用户单击某个元素, 但由于元素处于父元素内, 该父元素又处于document对象中, document对象又处于windo ...
- 深入浅出Mybatis系列四-配置详解之typeAliases别名(mybatis源码篇)
注:本文转载自南轲梦 注:博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 上篇文章<深入浅出Mybatis系列(三)---配置详解之properties ...
- 关闭Apache的目录浏览功能
一.默认情况 默认情况下,Apache的配置文件C:\web\apache2.4\conf/httpd.conf中有如下参数: 引用 <Directory "/var/www/html ...
- JavaDay2(中)
Java循环与分支练习 习题1: 输出1~100内前5个可以被3整除的数. public class Day2_Test1 { //输出1~100内前5个可以被3整除的数. public static ...