【Python】模拟登录上海西南某高校校园网 (jaccount)
好久没写东西了,最近学习了一下模拟登录,以校园网为例,作一记录。
去年的时候写过一篇模拟登录的文章,用的是登录后的cookies,这种操作比较傻瓜,也不智能,不够自动化,本质还是手动登录。
这次我尝试把登录过程用python进行,预先提供账号、密码即可。
众所周知(本校兄弟姐妹),本校所有身份认证现已完全由jaccount进行,只要通过了这一层验证,就相当于登录成功了。

以登录校园邮箱为例,先分析一下登录流程:
- 输入邮箱网址
mail....edu.cn - 跳转到jaccount验证页
- 输入账号、密码、验证码登录
- 跳转回邮箱页面,登录完成
难点分析:
- 跳转过程中有哪些数据需要携带?
- 验证码如何获取?如何识别?
刚开始想用requests解决所有问题,直到试了许多次也未能成功解决登录跳转的问题,只好放弃,转用更简单的selenium。selenium是一款可见即可得的自动化测试工具,在爬虫上用起来十分方便,它通过模拟人实际的操作实现对浏览器的控制,比如输入、点击、拖动等事件。
依次按照上述流程,进行编码(完整代码见文末):
步骤一、打开浏览器,输入邮箱网址
browser.get('https://mail.sjtu.edu.cn')
此时,会弹出浏览器,自动打开该网页,当然,也会自动跳转到jaccount验证页面。
步骤二、输入账号、密码、验证码
账号、密码都比较好搞定,自己预设好就行了。然后通过开发者工具定位文本框位置,由以下命令可以输入到相应的文本框内。

input_user = browser.find_element_by_id('user')
input_user.send_keys(user)
input_pass = browser.find_element_by_id('pass')
input_pass.send_keys(pswd)
麻烦的还是验证码。首先要找到验证码图片源,再通过OCR工具进行识别。
通过分析,发现验证码是由https://jaccount.sjtu.edu.cn/jaccount/captcha这个站点生成的。要获取到正确的验证码,需要传入相应的uuid参数,以及cookies。OCR工具目前比较好用的是tesseract,所幸我们这个验证码比较简单,识别率很高。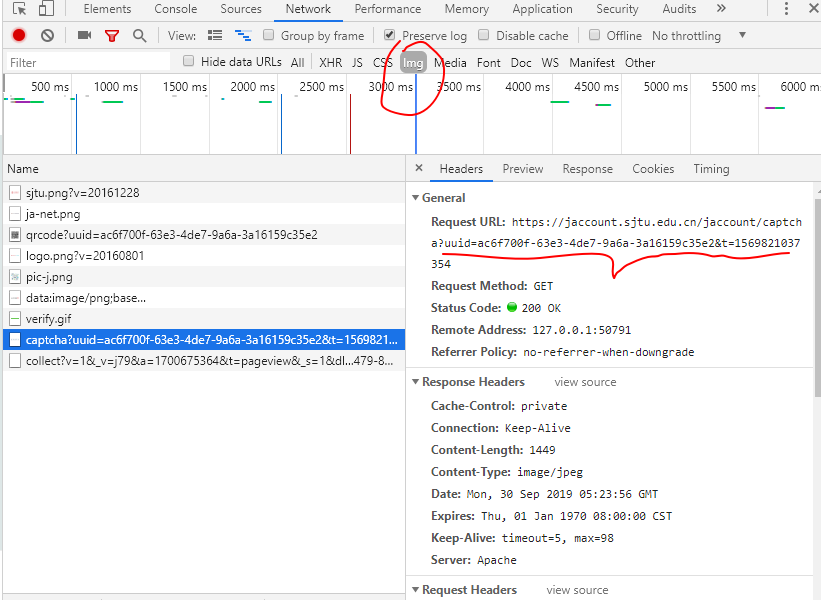
通过对源码进行搜索,终于找到uuid了,就在这个登录表单里,通过xpath获取一下,拿到value
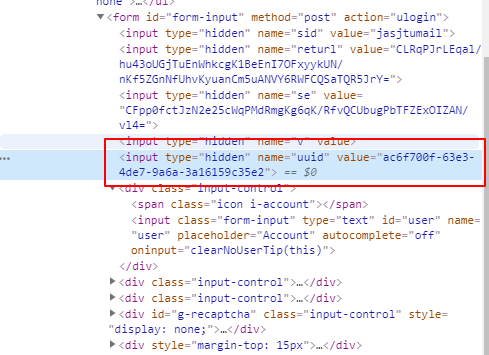
uuid = browser.find_element_by_xpath('//form/input[@name="uuid"]')
params = {
'uuid': uuid.get_attribute('value')
}
此处为了便捷,我使用requests进行验证码下载,而selenium的cookies也和requests不同,selenium是比较完整的信息,如下:
[{'domain': 'mail.sjtu.edu.cn', 'httpOnly': True, 'name': 'JSESSIONID', 'path': '/', 'secure': False, 'value': '12l9qesot3vw61sz8brl8i74ir'}, {'domain': 'mail.sjtu.edu.cn', 'httpOnly': True, 'name': 'ZM_AUTH_TOKEN', 'path': '/', 'secure': False, 'value': '0_7b1bfd5665cabda2816d04d7e4f8438022c54538_69643d33363a35373935373238652d346539362d346434372d383837332d6331666264356130343337643b6578703d31333a313536393836323130303632323b747970653d363a7a696d6272613b753d313a613b7469643d31303a323134323231343838363b76657273696f6e3d31333a382e382e395f47415f333031393b'}, {'domain': '.sjtu.edu.cn', 'expiry': 1569818955, 'httpOnly': False, 'name': '_gat', 'path': '/', 'secure': False, 'value': '1'}, {'domain': '.sjtu.edu.cn', 'expiry': 1569905295, 'httpOnly': False, 'name': '_gid', 'path': '/', 'secure': False, 'value': 'GA1.3.452166840.1569818896'}, {'domain': '.sjtu.edu.cn', 'expiry': 1632890895, 'httpOnly': False, 'name': '_ga', 'path': '/', 'secure': False, 'value': 'GA1.3.1066557857.1569818896'}]
而我们传入requests的只需要cookie名字和值即可,故可通过字典推导式,生成requests所需的cookies:
cookies = browser.get_cookies()
cookies = {i["name"]: i["value"] for i in cookies}
这样一来就可以获取验证码了,
response = requests.get(captcha_url, cookies=cookies, params=params)
with open('img.jpeg', 'wb+') as f:
f.writelines(response)
这样验证码就被保存到img.jpeg文件中,识别验证码只需要以下两行代码即可:
image = Image.open('img.jpeg')
code = pytesseract.image_to_string(image)
最后,输入验证码,并确定,就可以跳转回登录后的邮箱界面。
input_code = browser.find_element_by_id('captcha')
input_code.send_keys(code)
input_code.send_keys(Keys.ENTER)
如果你用的是可视化浏览器,这时候就可以看到自己的邮箱了。
可以再看看当前的url,是不是已经跳转回邮箱的url了呢?
print(browser.current_url)
成功登录之后,要爬取什么东西都很简单了,比如课程表、好大学在线的课件等等~
完整代码
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import requests
import pytesseract
from PIL import Image
browser = webdriver.Chrome()
url = "https://mail.sjtu.edu.cn/"
captcha_url = "https://jaccount.sjtu.edu.cn/jaccount/captcha"
user = 'ben'
pswd = '********'
def get_captcha(captcha_url, cookies, params):
response = requests.get(captcha_url, cookies=cookies, params=params)
with open('img.jpeg', 'wb+') as f:
f.writelines(response)
try:
browser.get(url)
cookies = browser.get_cookies()
cookies = {i["name"]: i["value"] for i in cookies}
uuid = browser.find_element_by_xpath('//form/input[@name="uuid"]')
params = {
'uuid': uuid.get_attribute('value')
}
get_captcha(captcha_url, cookies, params)
image = Image.open('img.jpeg')
code = pytesseract.image_to_string(image)
print(code)
input_user = browser.find_element_by_id('user')
input_user.send_keys(user)
input_pass = browser.find_element_by_id('pass')
input_pass.send_keys(pswd)
input_code = browser.find_element_by_id('captcha')
input_code.send_keys(code)
input_code.send_keys(Keys.ENTER)
print(browser.current_url)
finally:
print('success!')
【Python】模拟登录上海西南某高校校园网 (jaccount)的更多相关文章
- 【Python数据分析】Python模拟登录(一) requests.Session应用
最近由于某些原因,需要用到Python模拟登录网站,但是以前对这块并不了解,而且目标网站的登录方法较为复杂, 所以一下卡在这里了,于是我决定从简单的模拟开始,逐渐深入地研究下这块. 注:本文仅为交流学 ...
- 【py登陆】python模拟登录
用Python模拟登录网站 前面简单提到了 Python 模拟登录的程序,但是没写清楚,这里再补上一个带注释的 Python 模拟登录的示例程序.简单说一下流程:先用cookielib获取cookie ...
- 忘记秘密利用python模拟登录暴力破解秘密
忘记秘密利用python模拟登录暴力破解秘密: #encoding=utf-8 import itertools import string import requests def gen_pwd_f ...
- [Python] Python 模拟登录,并请求
Python 模拟登录,并请求 # encoding: utf- import requests import socket import time socket.setdefaulttimeout( ...
- Python模拟登录实战(三)
目标:模拟登录知乎 代码如下: #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'ziv·chan' import re impor ...
- Python模拟登录实战(二)
目标:1.模拟登录豆瓣,2.自动更改签名和发表说说. 代码如下: #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'ziv·chan ...
- Python模拟登录实战(一)
今天,学习了模拟登录新浪微博.模拟登录主要有两种方式,一.利用Cookie:二.模仿浏览器的请求,发送表单. 法一: Cookie:指某些网站为了辨别用户身份而储存在用户本地终端上的数据(通常经过加密 ...
- Python模拟登录的几种方法
目录 方法一:直接使用已知的cookie访问 方法二:模拟登录后再携带得到的cookie访问 方法三:模拟登录后用session保持登录状态 方法四:使用无头浏览器访问 正文 方法一:直接使用已知的c ...
- [Python] 模拟登录网站(。。为了之后操作数据。。)
我司的内部管理(Web)系统(日报)着实..(mafan).. 所以,就想自己动手增加一下便利性. 计划是, - 桌面程序 用来方便记录(按自己格式,数据随时保存到sqlite中,备用) 通过一览来确 ...
随机推荐
- Dubbo---注册中心
1.Multicast 注册中心 1.1 Multicast 注册中心 不需要启动 任何中心节点,只要广播地址一样,就可以互相发现. 1.2 1.3 配置 2.zookeeper 注册中心( ...
- Collections 工具类常见方法
Collections 工具类常用方法: 排序 查找,替换操作 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合) 排序操作 void reverse(List list) ...
- 「AHOI / HNOI2018」转盘 解题报告
「AHOI / HNOI2018」转盘 可能是我语文水平不太行... 首先可以猜到一些事实,这个策略一定可以被一个式子表示出来,不然带修修改个锤子. 然后我们发现,可以枚举起点,然后直接往前走,如果要 ...
- Shell5
sed文本编辑器(vim,notepad)非交互式的文本编辑器sed是逐行处理编辑器 sed [选项] ‘条件指令' 文件 #没有条件指令时,默认对全文所有进行修改sed的所有操作默认时在 ...
- 微信小程序 在使用wx.request时显示加载中
微信小程序中,向后台请求数据是,通常想给用户提示正在加载中,如下图: 我们可以用wx.showLoading(OBJECT),当请求服务器的地方多了,怎么才能不每次都要去调用函数,我们只要对wx.re ...
- tp5使用jwt生成token,做api的用户认证
首先 composer 安装 firebase/php-jwt github:https://github.com/firebase/php-jwt composer require firebas ...
- hexo next主题深度优化(一),加入pjax功能。
文章目录 背景: 进入正题 pjax初体验--instantclick 真正的pjax 第一步 第二步 第三步 第四步 专门基于hexo next主题的pjax(将丢失的js效果重现) 将下面讲到的提 ...
- UDP 两种丢包处理策略:丢包重传(ARQ) 和 前向纠错(FEC)
目录 1. 两种丢包处理策略 2. 前向纠错(FEC) 3. 丢包重传(ARQ) [参考文献] 1. 两种丢包处理策略 为了保证实时性,通常适应UDP协议来针对RTP数据进行传输,而UDP无法保证数据 ...
- 4.1 react 代码规范
关于 基础规范 组件结构 命名规范 jsx 书写规范 eslint-plugin-react 关于 在代码的设计上,每个团队可能都有一定的代码规范和模式,好的代码规范能够提高代码的可读性便于协作沟通, ...
- vbs 之 解决打开Excel文件格式与扩展名指定格式不一致的问题
' Q:解决打开Excel文件格式与扩展名指定格式不一致的问题' A: 使用工作簿saveAs时,往往忽略掉它的第二个参数FileFormat,添加即可. 比如: set bookDiff = oEx ...