solr学习(一)安装与部署
经过测试,同步MongoDB数据到Solr的时候,Solr版本为8.4.0会出现连接不上的错误,8.3.0未经测试不知,博主测试好用的一版为8.2.0,但是官网已经下不到了,所以我会把下载链接放在文末,需要的同学自取,不要再下8.3.0/8.4.0!!!
拖更了一个多月,忙于公司的新项目,期间接触到了一个新东西,那就是solr,什么是solr,我理解为全文检索,他能实现数据库的全文检索并实现高亮显示,相信你的脑海中已经浮现出了在淘宝类似的购物平台搜索商品时的样子,没错,solr跟他很类似,当我们需要全文检索的时候就可以用到solr,下面开始搭建solr环境。
下载安装Apache Solr
我们到solr官网下载solr安装包
.png)
下载为zip格式,直接解压到本地即可。solr内置了jetty服务器,所以我们可以直接运行,当然我们也可以把solr部署到tomcat等服务器中运行,这里我们使用内置的服务器。
启动solr服务
我们进入到solr安装目录的bin文件夹下,shift+右键打开命令行窗口,win10是powershell窗口,所以我们打开后要执行cmd命令切换到cmd窗口(以下所执行的solr命令均是在此目录下执行,不再赘述),接着执行solr start来启动solr,这是solr启动成功的画面。
.png)
我们打开浏览器输入localhost:8983(solr默认启动端口为8983)就能看到solr界面了。
.png)
添加core
core就相当于solr的一个项目实例,输入命令solr create -c mycore
成功创建后,可以在 solr-8.2.0/server/solr/ 目录下看到自动生成的默认配置文件
.png)
创建完成后,重新进入后台控制页面,可以查看到新建的 core
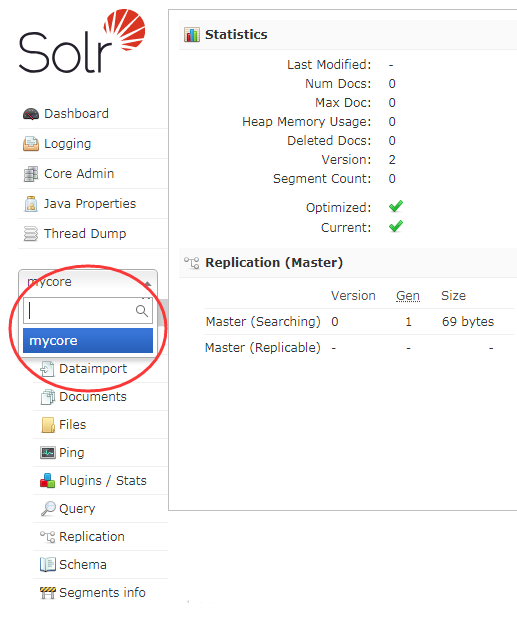
配置中文分词器 IK-Analyzer-Solr8
分词器就是能把我们输入的一个短语分成几个单词的形式,例如我爱中国,会被分为 我,爱,中国,三个。
为什么需要分词器?全文检索的意义就是当我们输入一个词语的时候能把相关涵盖的全都搜出来,比如我们搜索笔记本电脑,会把笔记本电脑拆成,笔记本,电脑,也就是说笔记本和电脑都会被查出来,这才是我们所需要的。
下载solr8版本的ik分词器,下载地址:https://search.maven.org/search?q=com.github.magese
.png)
将下载好的jar包放入solr-8.2.0\server\solr-webapp\webapp\WEB-INF\lib目录中
然后到solr-8.2.0\server\solr\mycore\conf目录中打开managed-schema文件
.png)
打开managed-schema文件在文件末尾添加以下代码
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
.png)
然后我们输入solr restart -port 8983来重启solr,回到后台管理页面
选择mycore -> Analysis -> 选择分词器 text_ik 输入 "我爱中国"
点击"Analyse Values"按钮可以看到结果已经分词成功了。
.png)
Solr后台管理
solr的安装与部署已经结束了,接下来带大家熟悉solr管理界面的各种功能。
Dashboard
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
Logging
Solr运行日志信息
Core Admin
Solr Core的管理界面。Solr Core 是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个索引目录。
java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
Core selector
选择一个SolrCore进行详细操作,如下:
.png)
Analysis
分词器,在上面已经讲过了,通过此界面可以测试索引分析器和搜索分析器的执行情况。
Dataimport
可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中。
Document
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
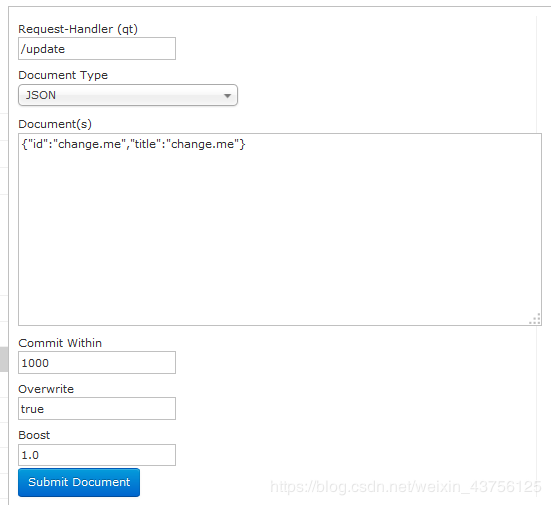
/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
Query
solr的条件查询操作
.png)
Request-Handler
/select为一个URI。solr服务在接受到这个请求的时候,就会根据”/select”这段URI来选择对应的RequestHandler。
common
| 参数 | 描述 | 用法 |
|---|---|---|
| q | 这是Apache Solr的主要查询参数,文档根据它们与此参数中的术语的相似性来评分。 | * : * |
| fq | 这个参数表示Apache Solr的过滤器查询,将结果集限制为与此过滤器匹配的文档。 | |
| sort | 这个参数指定由逗号分隔的字段列表,根据该列表对查询的结果进行排序。 | id desc,price asc |
| start | start参数表示页面的起始偏移量,此参数的默认值为0。若为1,表示从第二条记录中检索记录 | 1 |
| rows | 这个参数表示每页要检索的文档的数量。此参数的默认值为10。例如,可以通过将值2传递到参数行(row),将查询结果中的记录总数限制为2。 | 2 |
| fl | 这个参数为结果集中的每个文档指定返回的字段列表。如果想在结果文档中显示指定字段,则需要传递必填写的字段列表,用逗号分隔,作为属性fl的值。 | id,content |
| df | ||
| Raw Query Parameters | ||
| wt | 这个参数表示要查看响应结果的写入程序的类型。选择一个来获取所需文档类型的响应。 | json、xml |
| indent | 返回的结果是否缩进,默认关闭,用 indent=true | on 开启,一般调试json,php,ruby输出才有必要用这个参数。 | indent=true | on |
| debugQuery | 设置返回结果是否显示Debug信息。 | |
| dismax | ||
| edismax | ||
| hl | 开启高亮显示 | |
| hl.fl | 要高亮显示的域 | |
| hl.simple.pre | 高亮显示的前缀 | |
| hl.simple.post | 高亮显示的后缀 | |
| spatial | ||
| spellcheck |
至此,solr的安装与部署就讲完了,相信你们对solr也有了一定的了解,这是solr学习的第一篇,我打算一共写三篇文章来讲解solr,分别是【solr的安装与部署】【solr同步mongodb数据】【ssm项目整合solr】,把我在项目中使用solr的心得都分享出来。
Solr8.2.0下载链接:链接: https://pan.baidu.com/s/19HQOeXmYAesYH0UfNDwFgA 提取码: a3qs

solr学习(一)安装与部署的更多相关文章
- Solr学习、安装与Quick Start
之前用Lucene进行了一些简单的例子,现在安装Solr学习一下. 在mac下,貌似可以直接brew install solr来进行安装.尝试一下. 貌似安装成功了: ==> Summary
- cowboy学习笔记(安装与部署)
安装cowboy,参照官方文档:http://ninenines.eu/docs/en/cowboy/1.0/guide/getting_started/ 添加依赖库:在makefile中添加,会自动 ...
- Lucene/Solr搜索引擎开发笔记 - 第2章 Solr安装与部署(Tomcat篇)
一.安装环境 图1-1 Tomcat和Solr的版本 我本机目前使用的Java版本为JDK 1.8,因为Solr 4.9要求Java版本为1.7+,请注意. 二.Solr部署到Tomcat流程 图1- ...
- solr 学习之简介及安装
一.solr简介 Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展,并对索 ...
- Hadoop学习------Hadoop安装方式之(二):伪分布部署
要想发挥Hadoop分布式.并行处理的优势,还须以分布式模式来部署运行Hadoop.单机模式是指Hadoop在单个节点上以单个进程的方式运行,伪分布模式是指在单个节点上运行NameNode.DataN ...
- Redis学习01_redis安装部署(centos)
原文: http://www.cnblogs.com/herblog/p/9305668.html Redis学习(一):CentOS下redis安装和部署 1.基础知识 redis是用C语言开发的 ...
- Solr学习总结(二)Solr的安装与配置
接着前一篇,这里总结下Solr的安装与配置 1.准备 1.安装Java8 和 Tomcat9 ,java和tomcat 的安装这里不再重复.需要注意的是这两个的版本兼容问题.貌似java8 不支持,t ...
- [原创]HBase学习笔记(1)-安装和部署
HBase安装和部署 使用的HBase版本是1.2.4 1.安装步骤(默认hdfs已安装好) # 下载并解压安装包 cd tools/ tar -zxf hbase-1.2.4-bin.tar.gz ...
- java学习——平台的安装与部署
Java 平台安装与部署 jre,jdk安装与部署 1)jre,jdk安装过程(略) 2)部署过程 新建(JAVA_HOME) 变量名:JAVA_HOME 变量值:E:\Program Files ( ...
随机推荐
- Laravel 上传excel,读取并写入数据库 (实现自动建表、存记录值
<?php namespace App\Http\Controllers; use Illuminate\Foundation\Bus\DispatchesJobs; use Illuminat ...
- rowStyle设置Bootstrap Table行样式
日常开发中我们通常会用到隔行变色来美化表格,也会根据每行的数据显示特定的背景颜色,如果库存低于100的行显示红色背景 CSS样式 <style> .bg-blue { background ...
- HDU2087 剪花布条 题解 KMP算法
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2087 题目大意:给定字符串 \(s\) 和 \(t\) ,找出 \(s\) 中出现不重叠的 \(t\) ...
- H3C 以太网集线器
- tomcat access日志
每次看access log都会记不住pattern里的各个标识代表的什么意思,记录下,备忘! tomcat的access log是由实现了org.apache.catalina.AccessLog接口 ...
- js(一) 三大事件 实现注册验证
ps:小声比比,为什么一周多没更,因为js真的好难啊. 上一周做了一整周的jsp+sevlet+mysql做了一个MVC模式的最基本的新闻系统源码会有空搞出来的 好累 好多的. 三大事件 (鼠标事件. ...
- Talk is cheap. Show me the code.
Talk is cheap. Show me the code. -- Linux创始人 Linus Torvalds 2000-08-25 Stay hungry Stay foolish -- 乔 ...
- [转]Redis和Memcache区别,优缺点对比
1. Redis和Memcache都是将数据存放在内存中,都是内存数据库.不过memcache还可用于缓存其他东西,例如图片.视频等等. 2.Redis不仅仅支持简单的k/v类型的数据,同时还提供li ...
- linux scull 中的缺陷
让我们快速看一段 scull 内存管理代码. 在写逻辑的深处, scull 必须决定它请求的内 存是否已经分配. 处理这个任务的代码是: if (!dptr->data[s_pos]) { dp ...
- linux 基于 jiffy 的超时
到目前为止所展示的次优化的延时循环通过查看 jiffy 计数器而不告诉任何人来工作. 但是最好的实现一个延时的方法, 如你可能猜想的, 常常是请求内核为你做. 有 2 种方 法来建立一个基于 jiff ...