sparkJavaApi逐个详解
说明:掌握spark的一个关键,就是要深刻理解掌握RDD各个函数的使用场景,这样我们在写业务逻辑的时候就知道在什么时候用什么样的函数去实现,得心应手,本文将逐步收集整理各种函数原理及示例代码,持续更新,方便大家学习掌握。
函数列表:
1、join的使用
2、cogroup的使用
3、GroupByKey的使用
4、map的使用
5、flatmap的使用
6、mapPartitions的使用
7、mapPartitionsWithIndex的使用
8、sortBy的使用
9、takeOrdered的使用
10、takeSample的使用
11、distinct的使用
12、cartesian的使用
13、fold的使用
14、countByKey的使用
15、reduce的使用
16、aggregate的使用
17、aggregateByKey的使用
18、foreach的使用
19、foreachPartition的使用
20、lookup的使用
21、saveAsTextFile的使用
22、saveAsObjectFile的使用
23、treeAggregate的使用
24、treeReduce的使用
1、join的使用
官方文档描述:
Return an RDD containing all pairs of elements with matching keys in `this` and `other`.
Each* pair of elements will be returned as a (k, (v1, v2)) tuple,
where (k, v1) is in `this` and* (k, v2) is in `other`.
Performs a hash join across the cluster.
函数原型:
def join[W](other: JavaPairRDD[K, W]): JavaPairRDD[K, (V, W)]
def join[W](other: JavaPairRDD[K, W], numPartitions: Int): JavaPairRDD[K, (V, W)]
def join[W](other: JavaPairRDD[K, W], partitioner: Partitioner): JavaPairRDD[K, (V, W)]将一组数据转化为RDD后,分别创造出两个PairRDD,然后再对两个PairRDD进行归约(即合并相同Key对应的Value),过程如下图所示:
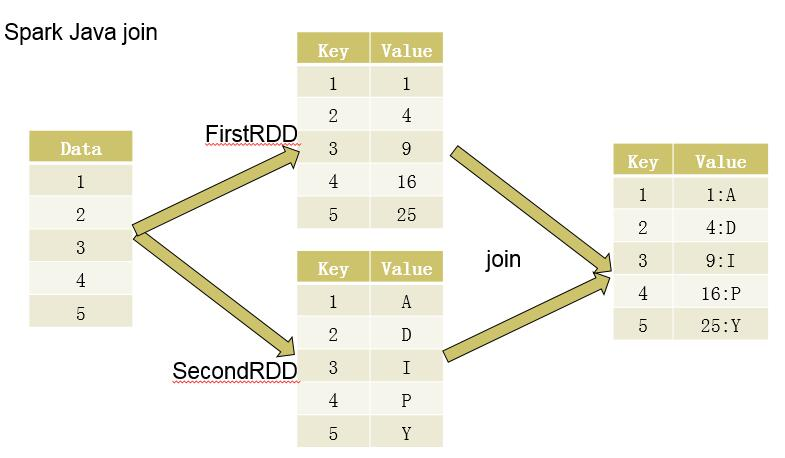
代码实现如下:
public class SparkRDDDemo {
public static void main(String[] args){
SparkConf conf = new SparkConf().setAppName("SparkRDD").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> data = Arrays.asList(1,2,3,4,5);
JavaRDD<Integer> rdd = sc.parallelize(data);
//FirstRDD
JavaPairRDD<Integer, Integer> firstRDD = rdd.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer num) throws Exception {
return new Tuple2<>(num, num * num);
}
});
//SecondRDD
JavaPairRDD<Integer, String> secondRDD = rdd.mapToPair(new PairFunction<Integer, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Integer num) throws Exception {
return new Tuple2<>(num, String.valueOf((char)(64 + num * num)));
}
});
JavaPairRDD<Integer, Tuple2<Integer, String>> joinRDD = firstRDD.join(secondRDD);
JavaRDD<String> res = joinRDD.map(new Function<Tuple2<Integer, Tuple2<Integer, String>>, String>() {
@Override
public String call(Tuple2<Integer, Tuple2<Integer, String>> integerTuple2Tuple2) throws Exception {
int key = integerTuple2Tuple2._1();
int value1 = integerTuple2Tuple2._2()._1();
String value2 = integerTuple2Tuple2._2()._2();
return "<" + key + ",<" + value1 + "," + value2 + ">>";
}
});
List<String> resList = res.collect();
for(String str : resList)
System.out.println(str);
sc.stop();
}
}
补充1
join就是把两个集合根据key,进行内容聚合;
A join B的结果:(1,("Spark",100)),(3,("hadoop",65)),(2,("Tachyon",95))
源码分析:
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}
**
从源码中可以看出,join() 将两个 RDD[(K, V)] 按照 SQL 中的 join 方式聚合在一起。与 intersection() 类似,首先进行 cogroup(), 得到 <K, (Iterable[V1], Iterable[V2])> 类型的 MappedValuesRDD,然后对 Iterable[V1] 和 Iterable[V2] 做笛卡尔集,并将集合 flat() 化。
**
实例:
List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7);
final Random random = new Random();
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data);
JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2<Integer, Integer>(integer,random.nextInt(10));
}
}); JavaPairRDD<Integer,Tuple2<Integer,Integer>> joinRDD = javaPairRDD.join(javaPairRDD);
System.out.println(joinRDD.collect()); JavaPairRDD<Integer,Tuple2<Integer,Integer>> joinRDD2 = javaPairRDD.join(javaPairRDD,2);
System.out.println(joinRDD2.collect()); JavaPairRDD<Integer,Tuple2<Integer,Integer>> joinRDD3 = javaPairRDD.join(javaPairRDD, new Partitioner() {
@Override
public int numPartitions() {
return 2;
}
@Override
public int getPartition(Object key) {
return (key.toString()).hashCode()%numPartitions();
}
});
System.out.println(joinRDD3.collect());
2.cogroup的使用
然后对B组集合中key相同的value进行聚合,之后对A组与B组进行"join"操作;
示例代码:
public class CoGroup {
public static void main(String[] args) {
SparkConf conf=new SparkConf().setAppName("spark WordCount!").setMaster("local");
JavaSparkContext sContext=new JavaSparkContext(conf);
List<Tuple2<Integer,String>> namesList=Arrays.asList(
new Tuple2<Integer, String>(1,"Spark"),
new Tuple2<Integer, String>(3,"Tachyon"),
new Tuple2<Integer, String>(4,"Sqoop"),
new Tuple2<Integer, String>(2,"Hadoop"),
new Tuple2<Integer, String>(2,"Hadoop2")
);
List<Tuple2<Integer,Integer>> scoresList=Arrays.asList(
new Tuple2<Integer, Integer>(1,100),
new Tuple2<Integer, Integer>(3,70),
new Tuple2<Integer, Integer>(3,77),
new Tuple2<Integer, Integer>(2,90),
new Tuple2<Integer, Integer>(2,80)
);
JavaPairRDD<Integer, String> names=sContext.parallelizePairs(namesList);
JavaPairRDD<Integer, Integer> scores=sContext.parallelizePairs(scoresList);
/**
* <Integer> JavaPairRDD<Integer, Tuple2<Iterable<String>, Iterable<Integer>>>
* org.apache.spark.api.java.JavaPairRDD.cogroup(JavaPairRDD<Integer, Integer> other)
*/
JavaPairRDD<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> nameScores=names.cogroup(scores);
nameScores.foreach(new VoidFunction<Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>>>() {
private static final long serialVersionUID = 1L;
int i=1;
@Override
public void call(
Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> t)
throws Exception {
String string="ID:"+t._1+" , "+"Name:"+t._2._1+" , "+"Score:"+t._2._2;
string+=" count:"+i;
System.out.println(string);
i++;
}
});
sContext.close();
}
}
示例结果:
- ID:4 , Name:[Sqoop] , Score:[] count:1
- ID:1 , Name:[Spark] , Score:[100] count:2
- ID:3 , Name:[Tachyon] , Score:[70, 77] count:3
- ID:2 , Name:[Hadoop, Hadoop2] , Score:[90, 80] count:4
官方文档描述:
For each key k in `this` or `other`, return a resulting RDD that contains a tuple
with the list of values for that key in `this` as well as `other`.List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7, 1, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2<Integer, Integer>(integer,1);
}
}); //与 groupByKey() 不同,cogroup() 要 aggregate 两个或两个以上的 RDD。
JavaPairRDD<Integer,Tuple2<Iterable<Integer>,Iterable<Integer>>> cogroupRDD = javaPairRDD.cogroup(javaPairRDD);
System.out.println(cogroupRDD.collect()); JavaPairRDD<Integer,Tuple2<Iterable<Integer>,Iterable<Integer>>> cogroupRDD3 = javaPairRDD.cogroup(javaPairRDD, new Partitioner() {
@Override
public int numPartitions() {
return 2;
}
@Override
public int getPartition(Object key) {
return (key.toString()).hashCode()%numPartitions();
}
});
System.out.println(cogroupRDD3);
3、GroupByKey的使用
感觉reduceByKey只能完成一些满足交换率,结合律的运算,如果想把某些数据聚合到一些做一些操作,得换groupbykey
比如下面:我想把相同key对应的value收集到一起,完成一些运算(例如拼接字符串,或者去重)
public class SparkSample {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String args[]) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("Spark_GroupByKey_Sample");
sparkConf.setMaster("local");
JavaSparkContext context = new JavaSparkContext(sparkConf);
List<Integer> data = Arrays.asList(1,1,2,2,1);
JavaRDD<Integer> distData= context.parallelize(data);
JavaPairRDD<Integer, Integer> firstRDD = distData.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2(integer, integer*integer);
}
});
JavaPairRDD<Integer, Iterable<Integer>> secondRDD = firstRDD.groupByKey();
List<Tuple2<Integer, String>> reslist = secondRDD.map(new Function<Tuple2<Integer, Iterable<Integer>>, Tuple2<Integer, String>>() {
@Override
public Tuple2<Integer, String> call(Tuple2<Integer, Iterable<Integer>> integerIterableTuple2) throws Exception {
int key = integerIterableTuple2._1();
StringBuffer sb = new StringBuffer();
Iterable<Integer> iter = integerIterableTuple2._2();
for (Integer integer : iter) {
sb.append(integer).append(" ");
}
return new Tuple2(key, sb.toString().trim());
}
}).collect();
for(Tuple2<Integer, String> str : reslist) {
System.out.println(str._1() + "\t" + str._2() );
}
context.stop();
}
}
补充1 引自:http://blog.csdn.net/zongzhiyuan/article/details/49965021
在spark中,我们知道一切的操作都是基于RDD的。在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式。这种格式很像Python的字典类型,便于针对key进行一些处理。
针对pair RDD这样的特殊形式,spark中定义了许多方便的操作,今天主要介绍一下reduceByKey和groupByKey,因为在接下来讲解《在spark中如何实现SQL中的group_concat功能?》时会用到这两个operations。
首先,看一看spark官网[1]是怎么解释的:
reduceByKey(func, numPartitions=None)
Merge the values for each key using an associative reduce function. This will also perform the merginglocally on each mapper before sending results to a reducer, similarly to a “combiner” in MapReduce. Output will be hash-partitioned with numPartitions partitions, or the default parallelism level if numPartitions is not specified.
也就是,reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
groupByKey(numPartitions=None)
Group the values for each key in the RDD into a single sequence. Hash-partitions the resulting RDD with numPartitions partitions. Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will provide much better performance.
也就是,groupByKey也是对每个key进行操作,但只生成一个sequence。需要特别注意“Note”中的话,它告诉我们:如果需要对sequence进行aggregation操作(注意,groupByKey本身不能自定义操作函数),那么,选择reduceByKey/aggregateByKey更好。这是因为groupByKey不能自定义函数,我们需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
为了更好的理解上面这段话,下面我们使用两种不同的方式去计算单词的个数[2]:
- val words = Array("one", "two", "two", "three", "three", "three")
- val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
- val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
- val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
上面得到的wordCountsWithReduce和wordCountsWithGroup是完全一样的,但是,它们的内部运算过程是不同的。
(1)当采用reduceByKeyt时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。借助下图可以理解在reduceByKey里究竟发生了什么。 注意在数据对被搬移前同一机器上同样的key是怎样被组合的(reduceByKey中的lamdba函数)。然后lamdba函数在每个区上被再次调用来将所有值reduce成一个最终结果。整个过程如下:

(2)当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时。整个过程如下:
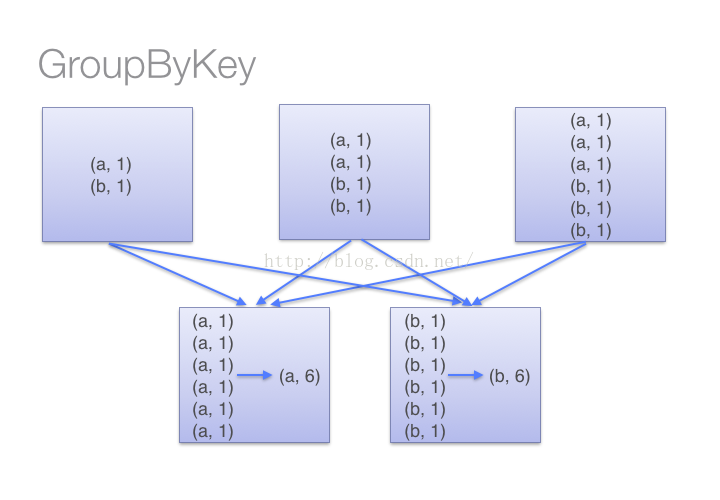
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
最后,对reduceByKey中的func做一些介绍:
如果是用Python写的spark,那么有一个库非常实用:operator[3],其中可以用的函数包括:大小比较函数,逻辑操作函数,数学运算函数,序列操作函数等等。这些函数可以直接通过“from operator import *”进行调用,直接把函数名作为参数传递给reduceByKey即可。如下:
- <span style="font-size:14px;">from operator import add
- rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
- sorted(rdd.reduceByKey(add).collect())
- [('a', 2), ('b', 1)]</span>
#################################################################################################################################
官方文档描述:
Group the values for each key in the RDD into a single sequence. Allows controlling the partitioning of the 从源码中可以看出groupByKey()是基于combineByKey()实现的, 只是将 Key 相同的 records 聚合在一起,一个简单的 shuffle 过程就可以完成。ShuffledRDD 中的 compute() 只负责将属于每个 partition 的数据 fetch 过来,之后使用 mapPartitions() 操作进行 aggregate,生成 MapPartitionsRDD,到这里 groupByKey() 已经结束。最后为了统一返回值接口,将 value 中的 ArrayBuffer[] 数据结构抽象化成 Iterable[]。groupByKey() 没有在 map 端进行 combine(mapSideCombine = false),这样设计是因为map 端 combine 只会省掉 partition 里面重复 key 占用的空间;但是,当重复 key 特别多时,可以考虑开启 combine。
实例:
List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data);
//转为k,v格式
JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2<Integer, Integer>(integer,1);
}
}); JavaPairRDD<Integer,Iterable<Integer>> groupByKeyRDD = javaPairRDD.groupByKey(2);
System.out.println(groupByKeyRDD.collect()); //自定义partition
JavaPairRDD<Integer,Iterable<Integer>> groupByKeyRDD3 = javaPairRDD.groupByKey(new Partitioner() {
//partition各数
@Override
public int numPartitions() { return 10; }
//partition方式
@Override
public int getPartition(Object o) {
return (o.toString()).hashCode()%numPartitions();
}
});
System.out.println(groupByKeyRDD3.collect());
4、map的使用
数据集中的每个元素经过用户自定义的函数转换形成一个新的RDD,新的RDD叫MappedRDD
5、flatmap的使用
6、mapPartitions的使用
mapPartitions与map类似,但是如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效的过。比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。
两者的主要区别是调用的粒度不一样:map的输入变换函数是应用于RDD中每个元素,而mapPartitions的输入函数是应用于每个分区。
假设一个rdd有10个元素,分成3个分区。如果使用map方法,map中的输入函数会被调用10次;而使用mapPartitions方法的话,其输入函数会只会被调用3次,每个分区调用1次。
函数原型:
def mapPartitions[U](f:FlatMapFunction[java.util.Iterator[T], U]): JavaRDD[U]
def mapPartitions[U](f:FlatMapFunction[java.util.Iterator[T], U],
preservesPartitioning: Boolean): JavaRDD[U]List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7);
//RDD有两个分区
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,2);
//计算每个分区的合计
JavaRDD<Integer> mapPartitionsRDD = javaRDD.mapPartitions(new FlatMapFunction<Iterator<Integer>, Integer>() {
@Override
public Iterable<Integer> call(Iterator<Integer> integerIterator) throws Exception {
int isum = 0;
while(integerIterator.hasNext())
isum += integerIterator.next();
LinkedList<Integer> linkedList = new LinkedList<Integer>();
linkedList.add(isum);
return linkedList; }
}); System.out.println("mapPartitionsRDD~~~~~~~~~~~~~~~~~~~~~~" + mapPartitionsRDD.collect());
######################################################################################################################################
rdd的mapPartitions是map的一个变种,它们都可进行分区的并行处理。
两者的主要区别是调用的粒度不一样:map的输入变换函数是应用于RDD中每个元素,而mapPartitions的输入函数是应用于每个分区。
假设一个rdd有10个元素,分成3个分区。如果使用map方法,map中的输入函数会被调用10次;而使用mapPartitions方法的话,其输入函数会只会被调用3次,每个分区调用1次。
//生成10个元素3个分区的rdd a,元素值为1~10的整数(1 2 3 4 5 6 7 8 9 10),sc为SparkContext对象
val a = sc.parallelize(1 to 10, 3)
//定义两个输入变换函数,它们的作用均是将rdd a中的元素值翻倍
//map的输入函数,其参数e为rdd元素值
def myfuncPerElement(e:Int):Int = {
println("e="+e)
e*2
}
//mapPartitions的输入函数。iter是分区中元素的迭代子,返回类型也要是迭代子
def myfuncPerPartition ( iter : Iterator [Int] ) : Iterator [Int] = {
println("run in partition")
var res = for (e <- iter ) yield e*2
res
}
val b = a.map(myfuncPerElement).collect
val c = a.mapPartitions(myfuncPerPartition).collect
在spark shell中运行上述代码,可看到打印了3次run in partition,打印了10次e=。
从输入函数(myfuncPerElement、myfuncPerPartition)层面来看,map是推模式,数据被推到myfuncPerElement中;mapPartitons是拉模式,myfuncPerPartition通过迭代子从分区中拉数据。
这两个方法的另一个区别是在大数据集情况下的资源初始化开销和批处理处理,如果在myfuncPerPartition和myfuncPerElement中都要初始化一个耗时的资源,然后使用,比如数据库连接。在上面的例子中,myfuncPerPartition只需初始化3个资源(3个分区每个1次),而myfuncPerElement要初始化10次(10个元素每个1次),显然在大数据集情况下(数据集中元素个数远大于分区数),mapPartitons的开销要小很多,也便于进行批处理操作。
mapPartitionsWithIndex和mapPartitons类似,只是其参数多了个分区索引号。
7、mapPartitionsWithIndex的使用
mapPartitionsWithIndex与mapPartitions基本相同,只是在处理函数的参数是一个二元元组,元组的第一个元素是当前处理的分区的index,元组的第二个元素是当前处理的分区元素组成的Iterator
函数原型:
def mapPartitionsWithIndex[R]( f:JFunction2[jl.Integer, java.util.Iterator[T],
java.util.Iterator[R]],
preservesPartitioning: Boolean = false): JavaRDD[R]
源码分析:
def mapPartitions[U: ClassTag](f:Iterator[T] => Iterator[U],
preservesPartitioning:Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(this, (context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}从源码中可以看到其实mapPartitions已经获得了当前处理的分区的index,只是没有传入分区处理函数,而mapPartitionsWithIndex将其传入分区处理函数。
实例:
List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7);
//RDD有两个分区
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,2);
//分区index、元素值、元素编号输出
JavaRDD<String> mapPartitionsWithIndexRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<Integer>, Iterator<String>>() {
@Override
public Iterator<String> call(Integer v1, Iterator<Integer> v2) throws Exception {
LinkedList<String> linkedList = new LinkedList<String>();
int i = 0;
while (v2.hasNext())
linkedList.add(Integer.toString(v1) + "|" + v2.next().toString() + Integer.toString(i++));
return linkedList.iterator();
}
},false); System.out.println("mapPartitionsWithIndexRDD~~~~~~~~~~~~~~~~~~~~~~" + mapPartitionsWithIndexRDD.collect());
8、sortBy的使用
官方文档描述:
Return this RDD sorted by the given key function.**
sortBy根据给定的f函数将RDD中的元素进行排序。
**
实例:
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data, 3);
final Random random = new Random(100);
//对RDD进行转换,每个元素有两部分组成
JavaRDD<String> javaRDD1 = javaRDD.map(new Function<Integer, String>() {
@Override
public String call(Integer v1) throws Exception {
return v1.toString() + "_" + random.nextInt(100);
}
});
System.out.println(javaRDD1.collect());
//按RDD中每个元素的第二部分进行排序
JavaRDD<String> resultRDD = javaRDD1.sortBy(new Function<String, Object>() {
@Override
public Object call(String v1) throws Exception {
return v1.split("_")[1];
}
},false,3);
System.out.println("result--------------" + resultRDD.collect());
9、takeOrdered的使用
官方文档描述:
Returns the first k (smallest) elements from this RDD using the**
natural ordering for T while maintain the order.
takeOrdered函数用于从RDD中,按照默认(升序)或指定排序规则,返回前num个元素。
**
源码分析:
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
if (num == 0) {
Array.empty
} else {
val mapRDDs = mapPartitions { items =>
// Priority keeps the largest elements, so let's reverse the ordering.
val queue = new BoundedPriorityQueue[T](num)(ord.reverse)
queue ++= util.collection.Utils.takeOrdered(items, num)(ord)
Iterator.single(queue)
}
if (mapRDDs.partitions.length == 0) {
Array.empty
} else {
mapRDDs.reduce { (queue1, queue2) =>
queue1 ++= queue2
queue1
}.toArray.sorted(ord)
}
}
}
从源码分析可以看出,利用mapPartitions在每个分区里面进行分区排序,每个分区局部排序只返回num个元素,这里注意返回的mapRDDs的元素是BoundedPriorityQueue优先队列,再针对mapRDDs进行reduce函数操作,转化为数组进行全局排序。
public static class TakeOrderedComparator implements Serializable,Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
return -o1.compareTo(o2);
}
}
List<Integer> data = Arrays.asList(5, 1, 0, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data, 3);
System.out.println("takeOrdered-----1-------------" + javaRDD.takeOrdered(2));
List<Integer> list = javaRDD.takeOrdered(2, new TakeOrderedComparator());
System.out.println("takeOrdered----2--------------" + list);
10、takeSample的使用
官方文档描述:
Return a fixed-size sampled subset of this RDD in an array**
takeSample函数返回一个数组,在数据集中随机采样 num 个元素组成。
**
源码分析:
def takeSample(
withReplacement: Boolean,
num: Int,
seed: Long = Utils.random.nextLong): Array[T] =
{
val numStDev = 10.0
if (num < 0) {
throw new IllegalArgumentException("Negative number of elements requested")
} else if (num == 0) {
return new Array[T](0)
}
val initialCount = this.count()
if (initialCount == 0) {
return new Array[T](0)
}
val maxSampleSize = Int.MaxValue - (numStDev * math.sqrt(Int.MaxValue)).toInt
if (num > maxSampleSize) {
throw new IllegalArgumentException("Cannot support a sample size > Int.MaxValue - " + s"$numStDev * math.sqrt(Int.MaxValue)")
}
val rand = new Random(seed)
if (!withReplacement && num >= initialCount) {
return Utils.randomizeInPlace(this.collect(), rand)
}
val fraction = SamplingUtils.computeFractionForSampleSize(num, initialCount, withReplacement)
var samples = this.sample(withReplacement, fraction, rand.nextInt()).collect()
// If the first sample didn't turn out large enough, keep trying to take samples;
// this shouldn't happen often because we use a big multiplier for the initial size
var numIters = 0
while (samples.length < num) {
logWarning(s"Needed to re-sample due to insufficient sample size. Repeat #$numIters")
samples = this.sample(withReplacement, fraction, rand.nextInt()).collect()
numIters += 1
}
Utils.randomizeInPlace(samples, rand).take(num)
}
实例:
List<Integer> data = Arrays.asList(5, 1, 0, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data, 3);
System.out.println("takeSample-----1-------------" + javaRDD.takeSample(true,2));
System.out.println("takeSample-----2-------------" + javaRDD.takeSample(true,2,100));
//返回20个元素
System.out.println("takeSample-----3-------------" + javaRDD.takeSample(true,20,100));
//返回7个元素
System.out.println("takeSample-----4-------------" + javaRDD.takeSample(false,20,100));
11、distinct的使用
官方文档描述:
Return a new RDD containing the distinct elements in this RDD.
函数原型:
def distinct(): JavaRDD[T]
def distinct(numPartitions: Int): JavaRDD[T]
**
第一个函数是基于第二函数实现的,只是numPartitions默认为partitions.length,partitions为parent RDD的分区。
distinct() 功能是 deduplicate RDD 中的所有的重复数据。由于重复数据可能分散在不同的 partition 里面,因此需要 shuffle 来进行 aggregate 后再去重。然而,shuffle 要求数据类型是 <K, V> 。如果原始数据只有 Key(比如例子中 record 只有一个整数),那么需要补充成 <K, null> 。这个补充过程由 map() 操作完成,生成 MappedRDD。然后调用上面的 reduceByKey() 来进行 shuffle,在 map 端进行 combine,然后 reduce 进一步去重,生成 MapPartitionsRDD。最后,将 <K, null> 还原成 K,仍然由 map() 完成,生成 MappedRDD。
**
实例:
List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7, 1, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); JavaRDD<Integer> distinctRDD1 = javaRDD.distinct();
System.out.println(distinctRDD1.collect());
JavaRDD<Integer> distinctRDD2 = javaRDD.distinct(2);
System.out.println(distinctRDD2.collect());
12、cartesian的使用
官方文档描述:
Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of
实例:
List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data); JavaPairRDD<Integer,Integer> cartesianRDD = javaRDD.cartesian(javaRDD);
System.out.println(cartesianRDD.collect());
13、fold的使用
官方文档描述:
Aggregate the elements of each partition, and then the results for all the partitions,
using a given associative and commutative function and a neutral "zero value".
The function op(t1, t2) is allowed to modify t1 and return it as its result value
to avoid object allocation; however, it should not modify t2.fold是aggregate的简化,将aggregate中的seqOp和combOp使用同一个函数op。
从源码中可以看出,先是将zeroValue赋值给jobResult,然后针对每个分区利用op函数与zeroValue进行计算,再利用op函数将taskResult和jobResult合并计算,
同时更新jobResult,最后,将jobResult的结果返回。
实例:
List<String> data = Arrays.asList("5", "1", "1", "3", "6", "2", "2");
JavaRDD<String> javaRDD = javaSparkContext.parallelize(data,5);
JavaRDD<String> partitionRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() {
@Override
public Iterator<String> call(Integer v1, Iterator<String> v2) throws Exception {
LinkedList<String> linkedList = new LinkedList<String>();
while(v2.hasNext()){
linkedList.add(v1 + "=" + v2.next());
}
return linkedList.iterator();
}
},false);
System.out.println(partitionRDD.collect());
String foldRDD = javaRDD.fold("0", new Function2<String, String, String>() {
@Override
public String call(String v1, String v2) throws Exception {
return v1 + " - " + v2;
}
});
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + foldRDD);
14、countByKey的使用
官方文档描述:
源码分析:
def countByKey(): Map[K, Long] = self.withScope {
self.mapValues(_ => 1L).reduceByKey(_ + _).collect().toMap
}注意,从上述分析可以看出,countByKey操作将数据全部加载到driver端的内存,如果数据量比较大,可能出现OOM。因此,如果key数量比较多,建议进行
rdd.mapValues(_ => 1L).reduceByKey(_ + _),返回RDD[T, Long]。**
实例:
List<String> data = Arrays.asList("5", "1", "1", "3", "6", "2", "2");
JavaRDD<String> javaRDD = javaSparkContext.parallelize(data,5);
JavaRDD<String> partitionRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() {
@Override
public Iterator<String> call(Integer v1, Iterator<String> v2) throws Exception {
LinkedList<String> linkedList = new LinkedList<String>();
while(v2.hasNext()){
linkedList.add(v1 + "=" + v2.next());
}
return linkedList.iterator();
}
},false);
System.out.println(partitionRDD.collect());
JavaPairRDD<String,String> javaPairRDD = javaRDD.mapToPair(new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2<String, String>(s,s);
}
});
System.out.println(javaPairRDD.countByKey());
15、reduce的使用
官方文档描述:
Reduces the elements of this RDD using the specified commutative and associative binary operator.
函数原型:
def reduce(f: JFunction2[T, T, T]): T根据映射函数f,对RDD中的元素进行二元计算(满足交换律和结合律),返回计算结果。
从源码中可以看出,reduce函数相当于对RDD中的元素进行reduceLeft函数操作,reduceLeft函数是从列表的左边往右边应用reduce函数;之后,在driver端对结果进行合并处理,因此,如果分区数量过多或者自定义函数过于复杂,对driver端的负载比较重。
实例:
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3);
Integer reduceRDD = javaRDD.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + reduceRDD);
16、aggregate的使用
官方文档描述:
Aggregate the elements of each partition, and then the results for all the partitions, using given combine functions and a neutral "zero value".
This function can return a different result type, U, than the type of this RDD, T. Thus, we need one operation for merging a T into an U and one operation for merging two U's,
as in scala.TraversableOnce. Both of these functions are allowed to modify and return their first argument instead of creating a new U to avoid memory allocation.
aggregate函数将每个分区里面的元素进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。
这个函数最终返回U的类型不需要和RDD的T中元素类型一致。 这样,我们需要一个函数将T中元素合并到U中,另一个函数将两个U进行合并。
其中,参数1是初值元素;参数2是seq函数是与初值进行比较;参数3是comb函数是进行合并 。
注意:如果没有指定分区,aggregate是计算每个分区的,空值则用初始值替换。
实例:
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3);
Integer aggregateValue = javaRDD.aggregate(3, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("seq~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + v1 + "," + v2);
return Math.max(v1, v2);
}
}, new Function2<Integer, Integer, Integer>() {
int i = 0;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("comb~~~~~~~~~i~~~~~~~~~~~~~~~~~~~"+i++);
System.out.println("comb~~~~~~~~~v1~~~~~~~~~~~~~~~~~~~" + v1);
System.out.println("comb~~~~~~~~~v2~~~~~~~~~~~~~~~~~~~" + v2);
return v1 + v2;
}
});
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"+aggregateValue);
17、aggregateByKey的使用
官方文档描述:
Aggregate the values of each key, using given combine functions and a neutral "zero value".This function can return a different result type, U
, than the type of the values in this RDD,V.Thus, we need one operation for merging a V into a U and one operation for merging two U's,as in scala.TraversableOnce.
The former operation is used for merging values within a partition, and the latter is used for merging values between partitions. To avoid memory allocation,
both of these functions are allowed to modify and return their first argument instead of creating a new U.aggregateByKey函数对PairRDD中相同Key的值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。
和aggregate函数类似,aggregateByKey返回值的类型不需要和RDD中value的类型一致。
因为aggregateByKey是对相同Key中的值进行聚合操作,所以aggregateByKey函数最终返回的类型还是Pair RDD,
对应的结果是Key和聚合好的值;而aggregate函数直接是返回非RDD的结果,这点需要注意。在实现过程中,定义了三个aggregateByKey函数原型,
但最终调用的aggregateByKey函数都一致。其中,参数zeroValue代表做比较的初始值;参数partitioner代表分区函数;参数seq代表与初始值比较的函数;参数comb是进行合并的方法。
实例:
//将这个测试程序拿文字做一下描述就是:在data数据集中,按key将value进行分组合并,
//合并时在seq函数与指定的初始值进行比较,保留大的值;然后在comb中来处理合并的方式。
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
int numPartitions = 4;
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data);
final Random random = new Random(100);
JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2<Integer, Integer>(integer,random.nextInt(10));
}
});
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"+javaPairRDD.collect()); JavaPairRDD<Integer, Integer> aggregateByKeyRDD = javaPairRDD.aggregateByKey(3,numPartitions, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("seq~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + v1 + "," + v2);
return Math.max(v1, v2);
}
}, new Function2<Integer, Integer, Integer>() {
int i = 0;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("comb~~~~~~~~~i~~~~~~~~~~~~~~~~~~~" + i++);
System.out.println("comb~~~~~~~~~v1~~~~~~~~~~~~~~~~~~~" + v1);
System.out.println("comb~~~~~~~~~v2~~~~~~~~~~~~~~~~~~~" + v2);
return v1 + v2;
}
});
System.out.println("aggregateByKeyRDD.partitions().size()~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"+aggregateByKeyRDD.partitions().size());
System.out.println("aggregateByKeyRDD~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~"+aggregateByKeyRDD.collect());
18、foreach的使用
官方文档描述:
Applies a function f to all elements of this RDD.
foreach用于遍历RDD,将函数f应用于每一个元素。
实例:
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3);
javaRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
System.out.println(integer);
}
});
19、foreachPartition的使用
官方文档描述:
Applies a function f to each partition of this RDD.
foreachPartition和foreach类似,只不过是对每一个分区使用f。
实例:
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3); //获得分区ID
JavaRDD<String> partitionRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<Integer>, Iterator<String>>() {
@Override
public Iterator<String> call(Integer v1, Iterator<Integer> v2) throws Exception {
LinkedList<String> linkedList = new LinkedList<String>();
while(v2.hasNext()){
linkedList.add(v1 + "=" + v2.next());
}
return linkedList.iterator();
}
},false);
System.out.println(partitionRDD.collect());
javaRDD.foreachPartition(new VoidFunction<Iterator<Integer>>() {
@Override
public void call(Iterator<Integer> integerIterator) throws Exception {
System.out.println("___________begin_______________");
while(integerIterator.hasNext())
System.out.print(integerIterator.next() + " ");
System.out.println("\n___________end_________________");
}
});
20、lookup的使用
官方文档描述:
Return the list of values in the RDD for key `key`. This operation is done efficiently if the RDD has a known partitioner by only searching the partition that the key maps to.lookup用于(K,V)类型的RDD,指定K值,返回RDD中该K对应的所有V值。 从源码中可以看出,如果partitioner不为空,计算key得到对应的partition,在从该partition中获得key对应的所有value;
如果partitioner为空,则通过filter过滤掉其他不等于key的值,然后将其value输出。
实例:
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data, 3);
JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
int i = 0;
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
i++;
return new Tuple2<Integer, Integer>(integer,i + integer);
}
});
System.out.println(javaPairRDD.collect());
System.out.println("lookup------------" + javaPairRDD.lookup(4));
21、saveAsTextFile的使用
官方文档描述:
Save this RDD as a text file, using string representations of elements.saveAsTextFile用于将RDD以文本文件的格式存储到文件系统中。 从源码中可以看到,saveAsTextFile函数是依赖于saveAsHadoopFile函数,由于saveAsHadoopFile函数接受PairRDD,
所以在saveAsTextFile函数中利用rddToPairRDDFunctions函数转化为(NullWritable,Text)类型的RDD,然后通过saveAsHadoopFile函数实现相应的写操作。
实例:
实例: List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,5);
javaRDD.saveAsTextFile("/user/tmp");
22、saveAsObjectFile的使用
官方文档描述:
Save this RDD as a SequenceFile of serialized objects.
saveAsObjectFile用于将RDD中的元素序列化成对象,存储到文件中。
从源码中可以看出,saveAsObjectFile函数是依赖于saveAsSequenceFile函数实现的,将RDD转化为类型为实例:
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,5);
javaRDD.saveAsObjectFile("/user/tmp");
23、treeAggregate的使用
官方文档描述:
Aggregates the elements of this RDD in a multi-level tree pattern.可理解为更复杂的多阶aggregate。 从源码中可以看出,treeAggregate函数先是对每个分区利用scala的aggregate函数进行局部聚合的操作;同时,依据depth参数计算scale,
如果当分区数量过多时,则按i%curNumPartitions进行key值计算,再按key进行重新分区合并计算;最后,在进行reduce聚合操作。这样可以通过调解深度来减少reduce的开销。
实例:
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,3);
//转化操作
JavaRDD<String> javaRDD1 = javaRDD.map(new Function<Integer, String>() {
@Override
public String call(Integer v1) throws Exception {
return Integer.toString(v1);
}
}); String result1 = javaRDD1.treeAggregate("0", new Function2<String, String, String>() {
@Override
public String call(String v1, String v2) throws Exception {
System.out.println(v1 + "=seq=" + v2);
return v1 + "=seq=" + v2;
}
}, new Function2<String, String, String>() {
@Override
public String call(String v1, String v2) throws Exception {
System.out.println(v1 + "<=comb=>" + v2);
return v1 + "<=comb=>" + v2;
}
});
System.out.println(result1);
24、treeReduce的使用
官方文档描述:
Reduces the elements of this RDD in a multi-level tree pattern.与treeAggregate类似,只不过是seqOp和combOp相同的treeAggregate。 从源码中可以看出,treeReduce函数先是针对每个分区利用scala的reduceLeft函数进行计算;最后,在将局部合并的RDD进行treeAggregate计算,这里的seqOp和combOp一样,初值为空。在实际应用中,可以用treeReduce来代替reduce,
主要是用于单个reduce操作开销比较大,而treeReduce可以通过调整深度来控制每次reduce的规模。
实例:
List<Integer> data = Arrays.asList(5, 1, 1, 4, 4, 2, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data,5);
JavaRDD<String> javaRDD1 = javaRDD.map(new Function<Integer, String>() {
@Override
public String call(Integer v1) throws Exception {
return Integer.toString(v1);
}
});
String result = javaRDD1.treeReduce(new Function2<String, String, String>() {
@Override
public String call(String v1, String v2) throws Exception {
System.out.println(v1 + "=" + v2);
return v1 + "=" + v2;
}
});
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + treeReduceRDD);
25、combineByKey的使用
官方文档描述:
Generic function to combine the elements for each key using a custom set of aggregation functions. Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined type" C Note that V and C can be different -- for example, one might group an RDD of type (Int, Int) into an RDD of type (Int, Seq[Int]).
Users provide three functions:
- `createCombiner`, which turns a V into a C (e.g., creates a one-element list)
- `mergeValue`, to merge a V into a C (e.g., adds it to the end of a list)
- `mergeCombiners`, to combine two C's into a single one.
In addition, users can control the partitioning of the output RDD, and whether to perform map-side aggregation (if a mapper can produce multiple items with the same key).
该函数是用于将RDD[k,v]转化为RDD[k,c],其中类型v和类型c可以相同也可以不同。
其中的参数如下:
- createCombiner:该函数用于将输入参数RDD[k,v]的类型V转化为输出参数RDD[k,c]中类型C;
- mergeValue:合并函数,用于将输入中的类型C的值和类型V的值进行合并,得到类型C,输入参数是(C,V),输出是C;
- mergeCombiners:合并函数,用于将两个类型C的值合并成一个类型C,输入参数是(C,C),输出是C;
- numPartitions:默认HashPartitioner中partition的个数;
- partitioner:分区函数,默认是HashPartitionner;
- mapSideCombine:该函数用于判断是否需要在map进行combine操作,类似于MapReduce中的combine,默认是 true。
从源码中可以看出,combineByKey()的实现是一边进行aggregate,一边进行compute() 的基础操作。假设一组具有相同 K 的 <K, V> records 正在一个个流向 combineByKey(),createCombiner 将第一个 record 的 value 初始化为 c (比如,c = value),然后从第二个 record 开始,来一个 record 就使用 mergeValue(c, record.value) 来更新 c,比如想要对这些 records 的所有 values 做 sum,那么使用c = c + record.value。等到 records 全部被 mergeValue(),得到结果 c。假设还有一组 records(key 与前面那组的 key 均相同)一个个到来,combineByKey() 使用前面的方法不断计算得到 c’。现在如果要求这两组 records 总的 combineByKey() 后的结果,那么可以使用 final c = mergeCombiners(c, c') 来计算;然后依据partitioner进行不同分区合并。
实例:
List<Integer> data = Arrays.asList(1, 2, 4, 3, 5, 6, 7, 1, 2);
JavaRDD<Integer> javaRDD = javaSparkContext.parallelize(data);
//转化为pairRDD
JavaPairRDD<Integer,Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2<Integer, Integer>(integer,1);
}
}); JavaPairRDD<Integer,String> combineByKeyRDD = javaPairRDD.combineByKey(new Function<Integer, String>() {
@Override
public String call(Integer v1) throws Exception {
return v1 + " :createCombiner: ";
}
}, new Function2<String, Integer, String>() {
@Override
public String call(String v1, Integer v2) throws Exception {
return v1 + " :mergeValue: " + v2;
}
}, new Function2<String, String, String>() {
@Override
public String call(String v1, String v2) throws Exception {
return v1 + " :mergeCombiners: " + v2;
}
});
System.out.println("result~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~" + combineByKeyRDD.collect());
sparkJavaApi逐个详解的更多相关文章
- Android 网络框架之Retrofit2使用详解及从源码中解析原理
就目前来说Retrofit2使用的已相当的广泛,那么我们先来了解下两个问题: 1 . 什么是Retrofit? Retrofit是针对于Android/Java的.基于okHttp的.一种轻量级且安全 ...
- JavaScript事件详解-jQuery的事件实现(三)
正文 本文所涉及到的jQuery版本是3.1.1,可以在压缩包中找到event模块.该篇算是阅读笔记,jQuery代码太长.... Dean Edward的addEvent.js 相对于zepto的e ...
- mina框架详解
转:http://blog.csdn.net/w13770269691/article/details/8614584 mina框架详解 分类: web2013-02-26 17:13 12651人 ...
- 详解Javascript的继承实现(二)
上文<详解Javascript的继承实现>介绍了一个通用的继承库,基于该库,可以快速构建带继承关系和静态成员的javascript类,好使用也好理解,额外的好处是,如果所有类都用这种库来构 ...
- 数据结构图文解析之:二叉堆详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- trie字典树详解及应用
原文链接 http://www.cnblogs.com/freewater/archive/2012/09/11/2680480.html Trie树详解及其应用 一.知识简介 ...
- MyBatis Generator 详解
MyBatis Generator中文文档 MyBatis Generator中文文档地址:http://mbg.cndocs.tk/ 该中文文档由于尽可能和原文内容一致,所以有些地方如果不熟悉,看中 ...
- MyBatis Generator 详解 【转来纯为备忘】
版权声明:版权归博主所有,转载请带上本文链接!联系方式:abel533@gmail.com 目录(?)[+] MyBatis Generator中文文档 运行MyBatis Generator X ...
- IOS Animation-CABasicAnimation、CAKeyframeAnimation详解&区别&联系
1.先看看网上流传的他们的继承图: 从上面可以看出CABasicAnimation与CAKeyframeAnimation都继承于CAPropertyAnimation.而CAPropertyAnim ...
随机推荐
- 最佳实践:阿里云VPC、ECS支持IPv6啦!
12月6日,阿里云宣布为企业提供全栈IPv6解决方案. 阿里云专有网络VPC.云服务器ECS,作为阿里云的核心产品,也于2018年11月底上线双栈VPC.双栈ECS,目前正在对外公测中. 那么如何在阿 ...
- luoguP3799 妖梦拼木棒 [组合数学]
题目背景 上道题中,妖梦斩了一地的木棒,现在她想要将木棒拼起来. 题目描述 有n根木棒,现在从中选4根,想要组成一个正三角形,问有几种选法? 输入输出格式 输入格式: 第一行一个整数n 第二行n个整数 ...
- Android中的Serialable和Parcelable的区别
本文主要介绍Parcelable和Serializable的作用.效率.区别及选择,关于Serializable的介绍见<Java中的序列化Serialable高级详解> 1.作用 Ser ...
- SXOI2018酱油记
Day 0: 嗯前一天刚听说要去参加省选(可能以前也说了不过没听见),作为弱省高一的蒟蒻准备去打打酱油.下午去五中试机啥也没敲晃荡一圈又回去了.今年来也就是打打酱油心情自然是很平静,真不知道明年现在我 ...
- NX二次开发-UFUN创建镜像体UF_MODL_create_mirror_body
NX11+VS2013 #include <uf.h> #include <uf_modl.h> UF_initialize(); //创建块 UF_FEATURE_SIGN ...
- Java-Class-@I:org.apache.ibatis.annotations.Mapper
ylbtech-Java-Class-@I:org.apache.ibatis.annotations.Mapper 1.返回顶部 2.返回顶部 1. package com.ylbtech.ed ...
- 什么是PoE、PSE、PD设备?
一个完整的PoE系统包括供电端设备(PSE, Power Sourcing Equipment)和受电端设备(PD, Power Device)两部分.PSE设备是为以太网客户端设备供电的设备,同时也 ...
- MySQL 11章_索引、触发器
一. 索引: . 为什么要使用索引: 一本书需要目录能快速定位到寻找的内容,同理,数据表中的数据很多时候也可以为他们创建相应的“目录”,称为索引,当创建索引后查询数据也会更加高效 . Mysql中的索 ...
- 2019-5-21-dotnet-使用-GC.GetAllocatedBytesForCurrentThread-获取当前线程分配过的内存大小...
title author date CreateTime categories dotnet 使用 GC.GetAllocatedBytesForCurrentThread 获取当前线程分配过的内存大 ...
- shell 命令 修改文件权限 chmod
1. 所有者+.-权限 更改那个拥有者的权限 u 表示文件的所有者 g 表示文件所在的组 o 表示其他用户 a 所有,以上三者 增加 / 减少权限 + 表示增加权限 - 表示取消权限 更改具体 ...