20行Python代码爬取王者荣耀全英雄皮肤
引言
王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了。我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成。
准备工作
爬取皮肤本身并不难,难点在于分析,我们首先得得到皮肤图片的url地址,话不多说,我们马上来到王者荣耀的官网: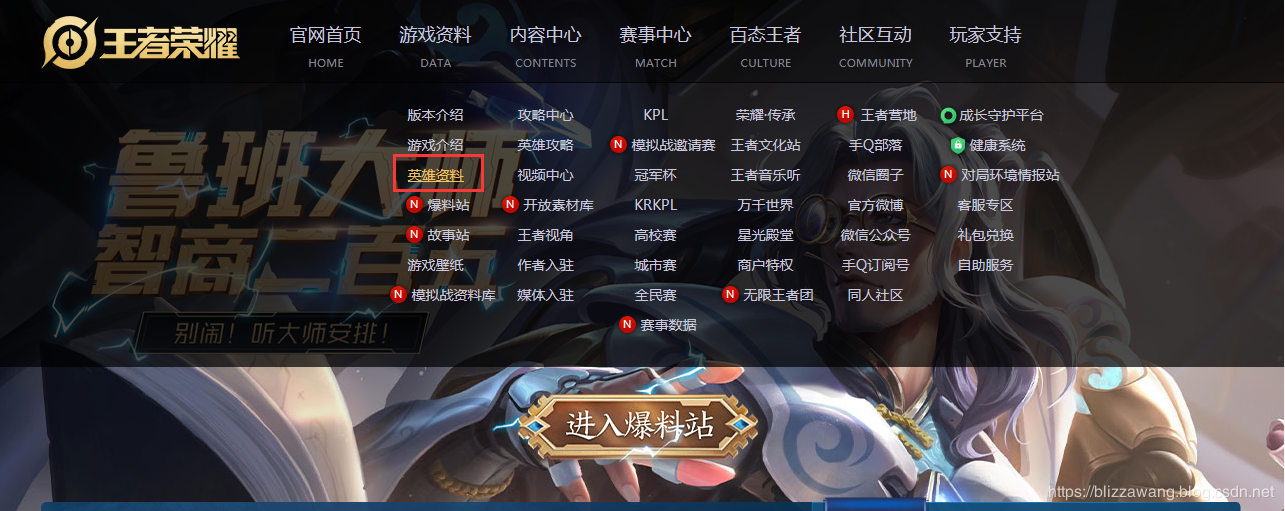
我们点击英雄资料,然后随意地选择一位英雄,接着F12打开调试台,找到英雄原皮肤的图片地址:
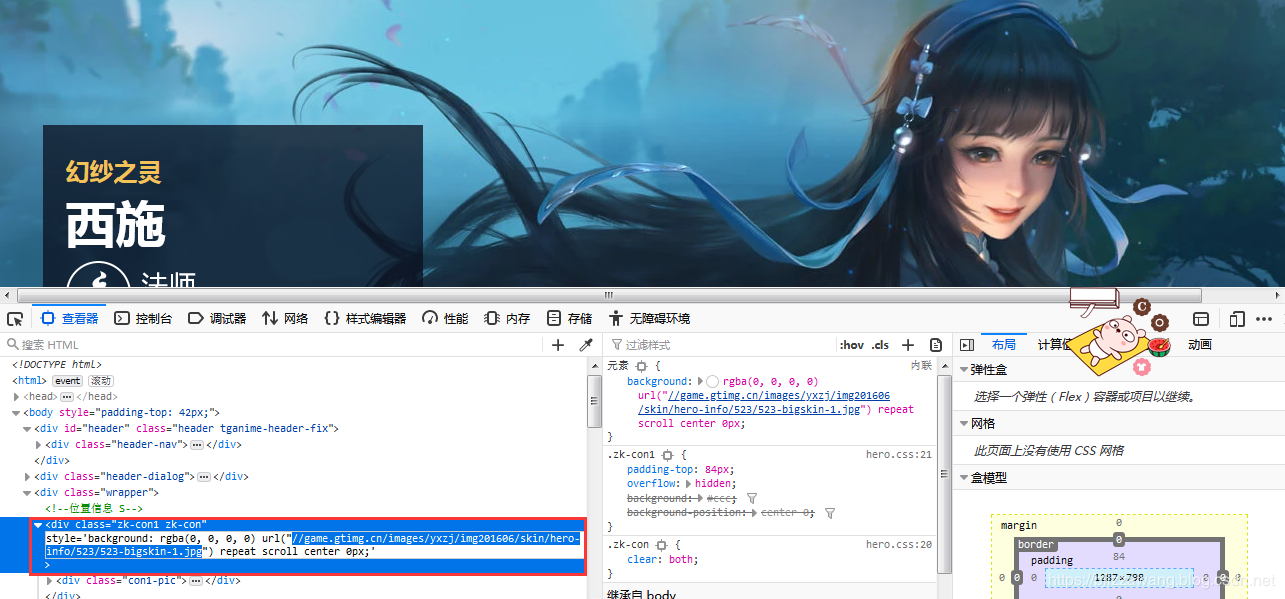
接着,我们切换一下英雄的皮肤,会发现图片地址没有明显的变化,只是最后的数字序号改变了,我们将两个皮肤图片的地址放在一起比较一下:
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/523/523-bigskin-1.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/523/523-bigskin-2.jp
我们可以猜测,对于同一个英雄的皮肤图片地址,仅仅是最后的数字序号不同,为了证实我们的猜想,我们可以继续找出一个英雄的全皮肤图片,找一个皮肤多一点的,例如我这里找的是孙尚香,将它的所有皮肤图片地址放在一起比较:
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-1.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-2.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-3.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-4.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-5.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-6.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/111/111-bigskin-7.jpg
由此我们得出结论,同一个英雄的皮肤图片路径从1开始依次递增,我们再来看看不同英雄之间是如何区分的。会发现,不管皮肤图片如何改变,浏览器上方的地址始终是不变的,所以我们将两个不同英雄的url地址放到一起比较一下:
https://pvp.qq.com/web201605/herodetail/523.shtml
https://pvp.qq.com/web201605/herodetail/111.shtml
乍一看,似乎没有什么规律,但我们要从这里发现一点,就是最后的数字其实控制的是哪个英雄,我们暂且认为它是英雄的编号,可不幸的是,英雄编号之间好像没有什么规律,不用着急,我们再到官网上找找线索。
在英雄资料界面,我们打开F12调试台,通过抓取网络请求,我发现了几个文件:
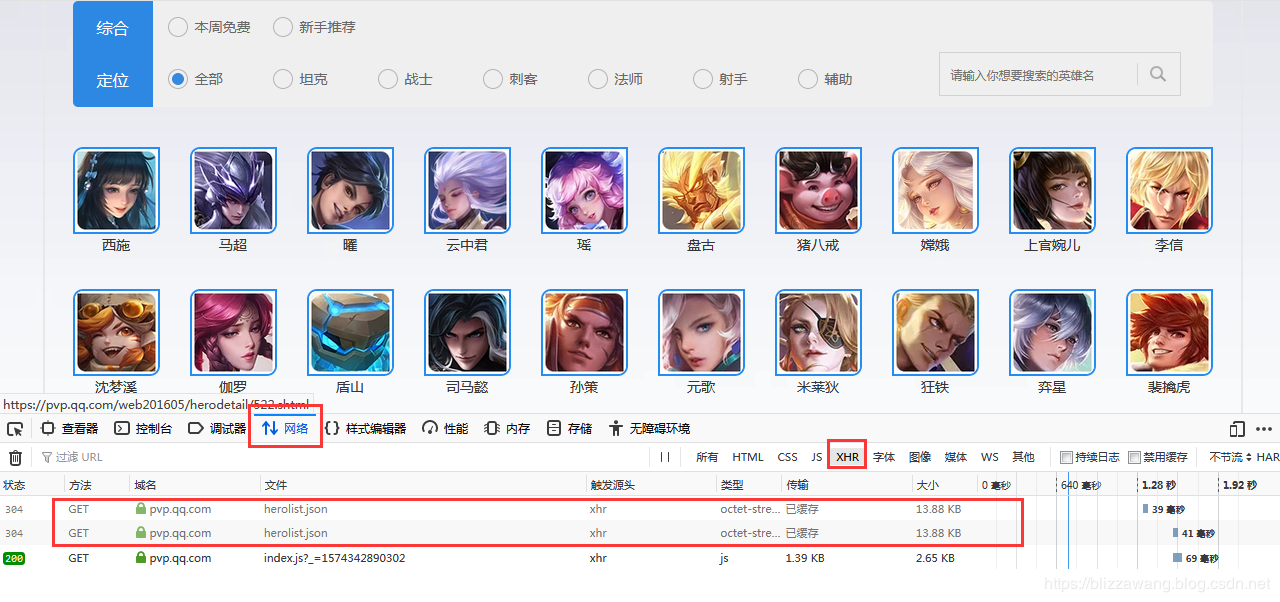
点击网络,然后点击XHR,就可以看到这几个文件,看到文件的名字大家应该就清楚了,这些文件存储的就是英雄列表信息,我们点击查看一下:
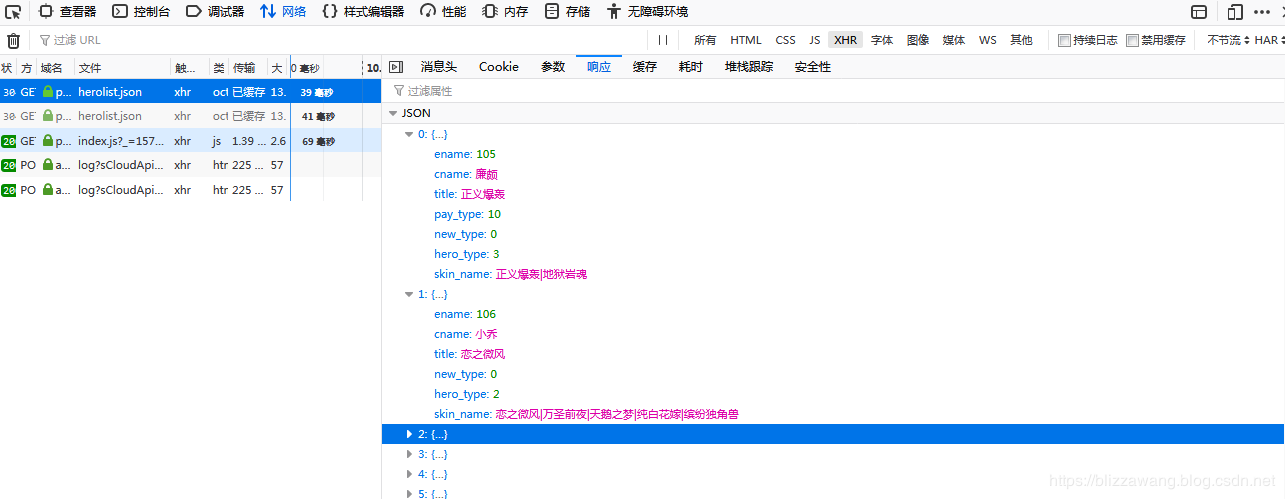
没错,这里存储的就是英雄信息,包括英雄的名字,英雄编号等等其它信息,我们可以试试这些信息的准确性,例如小乔的ename,也就是英雄编号为106,所以按照之前的想法,英雄小乔的详情地址应为:https://pvp.qq.com/web201605/herodetail/106.shtml
经过尝试后发现确实如此。
到这里,准备工作就完成了,其实进行到这里,整个工程就完成了一半了,接下来就是代码的实现了。
代码实现
首先我们创建一个Python文件,然后导入os和requests模块。
按照前面的步骤,我们首先需要获取到英雄列表信息,也就是herolist.json文件,文件地址为:https://pvp.qq.com/web201605/js/herolist.json,这在调试台中可以找到。
那么我们首先就要通过这个地址获取到英雄列表信息的json数据,然后解析json数据,将有用的信息提取出来:
url = 'https://pvp.qq.com/web201605/js/herolist.json'
herolist = requests.get(url) # 获取英雄列表json文件 herolist_json = herolist.json() # 转化为json格式
hero_name = list(map(lambda x: x['cname'], herolist.json())) # 提取英雄的名字
hero_number = list(map(lambda x: x['ename'], herolist.json())) # 提取英雄的编号
这样我们就获取到了英雄名字和编号,可以输出测试一下:
拿到了英雄编号之后,事情就变得很简单了,只需拼接一下url地址即可:
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + hero_number + '/' + hero_number + '-bigskin-1.jpg,这样可以获取到所有英雄的皮肤图片了,但是这里会有一个问题,英雄的皮肤是有多有少的,有的英雄只有两个皮肤,有的却有六七个,所以图片编号的最大值我们并不清楚,这里我采用了一个比较笨的办法,就是让一个变量从1到10依次递增去拼接图片地址,如果遇到没有的图片我们就不处理,因为没有一个英雄的皮肤超过了10个,所以我们就能获取到所有的图片了。下面看代码实现:
# 下载图片
def downloadPic():
i = 0
for j in hero_number:
# 创建文件夹
os.mkdir("C:\\Users\\Administrator\\Desktop\\wzry\\" + hero_name[i])
# 进入创建好的文件夹
os.chdir("C:\\Users\\Administrator\\Desktop\\wzry\\" + hero_name[i])
i += 1
for k in range(10):
# 拼接url
onehero_link = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(j) + '/' + str(
j) + '-bigskin-' + str(k) + '.jpg'
im = requests.get(onehero_link) # 请求url
if im.status_code == 200:
open(str(k) + '.jpg', 'wb').write(im.content) # 写入文件
实现非常地简单,代码注释也已经写得很清楚了,有了这个函数之后,我们只需调用一下,就可以下载图片了,整个程序的完整代码如下:
import os
import requests url = 'https://pvp.qq.com/web201605/js/herolist.json'
herolist = requests.get(url) # 获取英雄列表json文件 herolist_json = herolist.json() # 转化为json格式
hero_name = list(map(lambda x: x['cname'], herolist.json())) # 提取英雄的名字
hero_number = list(map(lambda x: x['ename'], herolist.json())) # 提取英雄的编号 # 下载图片
def downloadPic():
i = 0
for j in hero_number:
# 创建文件夹
os.mkdir("C:\\Users\\Administrator\\Desktop\\wzry\\" + hero_name[i])
# 进入创建好的文件夹
os.chdir("C:\\Users\\Administrator\\Desktop\\wzry\\" + hero_name[i])
i += 1
for k in range(10):
# 拼接url
onehero_link = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(j) + '/' + str(
j) + '-bigskin-' + str(k) + '.jpg'
im = requests.get(onehero_link) # 请求url
if im.status_code == 200:
open(str(k) + '.jpg', 'wb').write(im.content) # 写入文件 downloadPic()
除去注释,接近20行的代码我们就完成了王者荣耀全英雄皮肤的爬取,是不是非常简单呢?我们可以测试一下这个程序,首先要在桌面上创建一个文件夹,名为wzry,因为这里的代码我已经写死了,如果要修改的话大家也可以进行修改,文件夹创建完成后点击运行即可,等待片刻,图片就全部下载完成了。
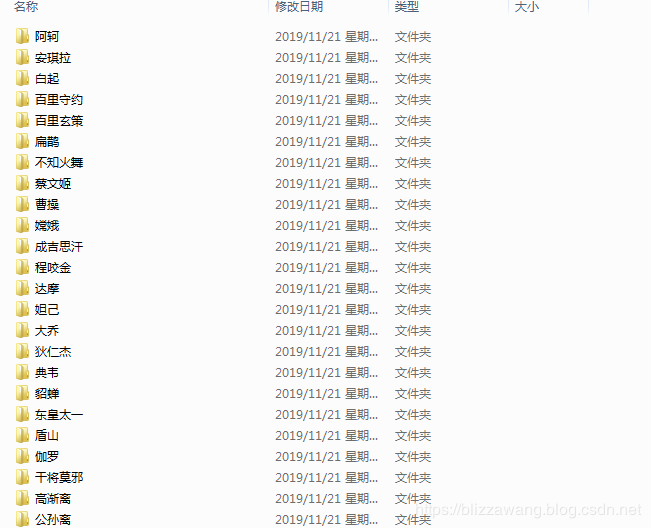

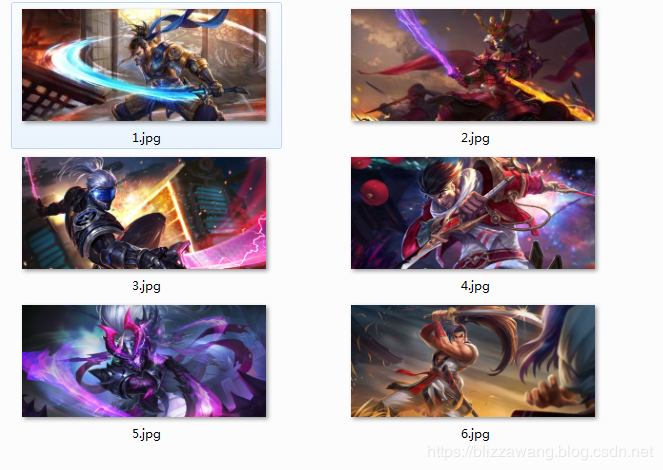
对于程序中json字符串的解析,我们还可以使用jsonpath模块来进行,使用该模块能够更加快捷地获取到我们想要的信息,解析方式如下:
hero_name = jsonpath.jsonpath(html_json, "$..cname")
hero_number = jsonpath.jsonpath(html_json, "$..ename")
该方法接收一个json字符串和解析规则,$…cname则表示从根目录下找寻任意位置的以cname为键的值,并放入字典中。
结尾
爬虫是非常有趣的,因为它非常直观,视觉冲击感强,写出来也很有成就感,爬虫虽然强大,但千万不能随意爬取隐私信息。
最后,如果对文中程序有更好的建议,及其他疑惑,关注微信公众号python社区营
20行Python代码爬取王者荣耀全英雄皮肤的更多相关文章
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- python爬取王者荣耀全英雄皮肤
import os import requests url = 'https://pvp.qq.com/web201605/js/herolist.json' herolist = requests. ...
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- python学习--第二天 爬取王者荣耀英雄皮肤
今天目的是爬取所有英雄皮肤 在爬取所有之前,先完成一张皮肤的爬取 打开anacond调出编译器Jupyter Notebook 打开王者荣耀官网 下拉找到位于网页右边的英雄/皮肤 点击[+更多] 进入 ...
- 利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片. 首先,我们找到王者的官网http://pvp.qq.com/web201605 ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- 用Python爬取"王者农药"英雄皮肤
0.引言 作为一款现象级游戏,王者荣耀,想必大家都玩过或听过,游戏里中各式各样的英雄,每款皮肤都非常精美,用做电脑壁纸再合适不过了.本篇就来教大家如何使用Python来爬取这些精美的英雄皮肤. 1.环 ...
随机推荐
- 19-1 djanjo中admin的简单用法
1. 创建管理员账号 python3 manage.py createsuperuser 2. 在admin注册我们的表 在app目录下面的admin.py里面按以下语法注册 admin.site.r ...
- 【iOS知识学习】_int、NSInteger、NSUInteger、NSNumber的差别和联系
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/weasleyqi/article/details/33396809 1.首先先了解下NSNumber ...
- Java版各种排序算法 (冒泡,快速,选择,插入)
package com.test4; import java.util.*; //Calendar 显示时间 /** * @author qingfeng * 功能:排序算法 */ public cl ...
- 08查找满足条件的n个数
第一节.寻找和为定值的两个数 题目:输入一个数组和一个数字,在数组中查找两个数,使得它们的和正好是输入的那个数字.要求时间复杂度是O(n).如果有多对数字的和等于输入的数字,输出任意一对即可. 例如输 ...
- A.The beautiful values of the palace 南京网络赛
A对于知道了解主席树性质的人来说,的确算是一个模板题目 题目在于给一个螺旋矩阵,以及一些权值,问在二维区间内权值和是多少? 对于螺旋矩阵权值来说,计算每个点的值,只需要O1计算即可.我们可以通过计算内 ...
- 在ThinkPHP中,if标签和比较标签对于变量的比较。
在TP模板语言中.if和eq都可以用于变量的比较. <比较标签 name="变量" value="值">内容</比较标签> 比如: &l ...
- 根据User Agent参数的各个字段Mozilla/5.0/4.0-AppleWebKit/Chrome/Safari/Firefox/Opera/MSIE来确定/判断客户端使用什么浏览器
下面给你一一解答以及给你介绍: //Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like ...
- get_magic_quotes_gpc() PHP转义的真正含义
如何正确的理解PHP转 义是一个初学者比较困扰的问题.我们今天为大家简要的讲述了PHP转义的具体含义,希望有所帮助.PHP转义一直困扰着我, 今天认真的看了一下PHP手册, 终于解决了. 在PHP中默 ...
- hdu 1217 Arbitrage(佛洛依德)
Arbitrage Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total S ...
- 2019-10-30-C#-dotnet-core-局域网组播方法
title author date CreateTime categories C# dotnet core 局域网组播方法 lindexi 2019-10-30 9:0:48 +0800 2019- ...