自然语言23_Text Classification with NLTK
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)

QQ:231469242
欢迎喜欢nltk朋友交流
https://www.pythonprogramming.net/text-classification-nltk-tutorial/?completed=/wordnet-nltk-tutorial/
Text Classification with NLTK
Now that we're comfortable with NLTK, let's try to tackle text
classification. The goal with text classification can be pretty broad.
Maybe we're trying to classify text as about politics or the military.
Maybe we're trying to classify it by the gender of the author who wrote
it. A fairly popular text classification task is to identify a body of
text as either spam or not spam, for things like email filters. In our
case, we're going to try to create a sentiment analysis algorithm.
To do this, we're going to start by trying to use the movie
reviews database that is part of the NLTK corpus. From there we'll try
to use words as "features" which are a part of either a positive or
negative movie review. The NLTK corpus movie_reviews data set has the
reviews, and they are labeled already as positive or negative. This
means we can train and test with this data. First, let's wrangle our
data.
import nltk
import random
from nltk.corpus import movie_reviews documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)] random.shuffle(documents) print(documents[1]) all_words = []
for w in movie_reviews.words():
all_words.append(w.lower()) all_words = nltk.FreqDist(all_words)
print(all_words.most_common(15))
print(all_words["stupid"])
It may take a moment to run this script, as the movie reviews dataset is somewhat large. Let's cover what is happening here.
After importing the data set we want, you see:
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
Basically, in plain English, the above code is translated to: In each category (we have pos or neg), take all of the file IDs (each review has its own ID), then store the word_tokenized version (a list of words) for the file ID, followed by the positive or negative label in one big list.
Next, we use random to shuffle our documents. This is because we're going to be training and testing. If we left them in order, chances are we'd train on all of the negatives, some positives, and then test only against positives. We don't want that, so we shuffle the data.
Then, just so you can see the data you are working with, we print out documents[1], which is a big list, where the first element is a list the words, and the 2nd element is the "pos" or "neg" label.
Next, we want to collect all words that we find, so we can have a massive list of typical words. From here, we can perform a frequency distribution, to then find out the most common words. As you will see, the most popular "words" are actually things like punctuation, "the," "a" and so on, but quickly we get to legitimate words. We intend to store a few thousand of the most popular words, so this shouldn't be a problem.
print(all_words.most_common(15))
The above gives you the 15 most common words. You can also find out how many occurences a word has by doing:
print(all_words["stupid"])
Next up, we'll begin storing our words as features of either positive or negative movie reviews.
导入corpus语料库的movie_reviews 影评
all_words 是所有电影影评的所有文字,一共有150多万字
#all_words 是所有电影影评的所有文字,一共有150多万字
all_words=movie_reviews.words()
'''
all_words
Out[37]: ['plot', ':', 'two', 'teen', 'couples', 'go', 'to', ...] len(all_words)
Out[38]: 1583820
'''
影评的分类category只有两种,neg负面,pos正面
import nltk
import random
from nltk.corpus import movie_reviews for category in movie_reviews.categories():
print(category) '''
neg
pos
'''
列出关于neg负面的文件ID
movie_reviews.fileids("neg")
'''
'neg/cv502_10970.txt',
'neg/cv503_11196.txt',
'neg/cv504_29120.txt',
'neg/cv505_12926.txt',
'neg/cv506_17521.txt',
'neg/cv507_9509.txt',
'neg/cv508_17742.txt',
'neg/cv509_17354.txt',
'neg/cv510_24758.txt',
'neg/cv511_10360.txt',
'neg/cv512_17618.txt'
.......
'''
列出关于pos正面的文件ID
movie_reviews.fileids("pos")
'pos/cv989_15824.txt',
'pos/cv990_11591.txt',
'pos/cv991_18645.txt',
'pos/cv992_11962.txt',
'pos/cv993_29737.txt',
'pos/cv994_12270.txt',
'pos/cv995_21821.txt',
'pos/cv996_11592.txt',
'pos/cv997_5046.txt',
'pos/cv998_14111.txt',
'pos/cv999_13106.txt'
输出neg/cv987_7394.txt 的文字,一共有872个
list_words=movie_reviews.words("neg/cv987_7394.txt")
'''
['please', 'don', "'", 't', 'mind', 'this', 'windbag', ...]
'''
len(list_words)
'''
Out[30]: 872
'''
tuple1=(list(movie_reviews.words("neg/cv987_7394.txt")), 'neg')
'''
Out[32]: (['please', 'don', "'", 't', 'mind', 'this', 'windbag', ...], 'neg')
'''
#用列表解析最终比较方便
#展示形式多条(['please', 'don', "'", 't', 'mind', 'this', 'windbag', ...], 'neg')
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
一共有2000个文件
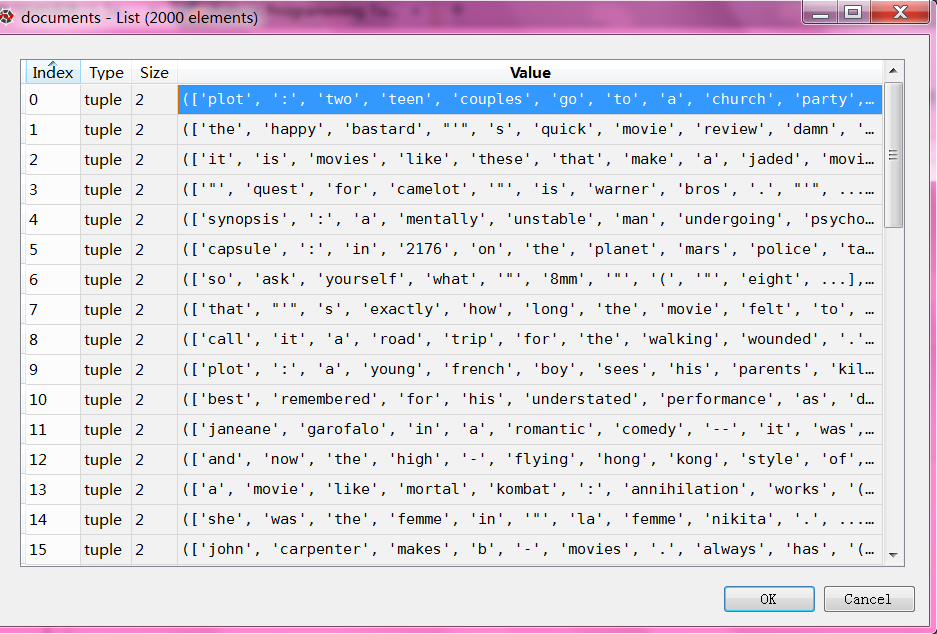
每个文件由一窜单词和评论neg/pos组成
完整测试代码
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 4 09:27:48 2016 @author: daxiong
"""
import nltk
import random
from nltk.corpus import movie_reviews documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)] random.shuffle(documents) #print(documents[1]) all_words = []
for w in movie_reviews.words():
all_words.append(w.lower()) all_words = nltk.FreqDist(all_words)
#print(all_words.most_common(15))
print(all_words["stupid"])

自然语言23_Text Classification with NLTK的更多相关文章
- 自然语言处理(1)之NLTK与PYTHON
自然语言处理(1)之NLTK与PYTHON 题记: 由于现在的项目是搜索引擎,所以不由的对自然语言处理产生了好奇,再加上一直以来都想学Python,只是没有机会与时间.碰巧这几天在亚马逊上找书时发现了 ...
- 自然语言20_The corpora with NLTK
QQ:231469242 欢迎喜欢nltk朋友交流 https://www.pythonprogramming.net/nltk-corpus-corpora-tutorial/?completed= ...
- 自然语言19.1_Lemmatizing with NLTK(单词变体还原)
QQ:231469242 欢迎喜欢nltk朋友交流 https://www.pythonprogramming.net/lemmatizing-nltk-tutorial/?completed=/na ...
- 自然语言14_Stemming words with NLTK
https://www.pythonprogramming.net/stemming-nltk-tutorial/?completed=/stop-words-nltk-tutorial/ # -*- ...
- 自然语言13_Stop words with NLTK
https://www.pythonprogramming.net/stop-words-nltk-tutorial/?completed=/tokenizing-words-sentences-nl ...
- 自然语言处理2.1——NLTK文本语料库
1.获取文本语料库 NLTK库中包含了大量的语料库,下面一一介绍几个: (1)古腾堡语料库:NLTK包含古腾堡项目电子文本档案的一小部分文本.该项目目前大约有36000本免费的电子图书. >&g ...
- python自然语言处理函数库nltk从入门到精通
1. 关于Python安装的补充 若在ubuntu系统中同时安装了Python2和python3,则输入python或python2命令打开python2.x版本的控制台:输入python3命令打开p ...
- Python自然语言处理实践: 在NLTK中使用斯坦福中文分词器
http://www.52nlp.cn/python%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E5%AE%9E%E8%B7%B5-% ...
- 推荐《用Python进行自然语言处理》中文翻译-NLTK配套书
NLTK配套书<用Python进行自然语言处理>(Natural Language Processing with Python)已经出版好几年了,但是国内一直没有翻译的中文版,虽然读英文 ...
随机推荐
- PHP与MySQL
这周学习了PHP与MySQL的搭接下面来给大家分享一下: 1.账号注册,论坛发帖... 思路:通过form表单提交到PHP页面,PHP页面往MySQL中插入数据: 2.账号登陆 思路:form提交数据 ...
- 三大范式与BCNF
引用:http://www.cnblogs.com/ybwang/archive/2010/06/04/1751279.html 参考: 1.范式间的区别 http://www.cnblogs.com ...
- 【POJ 3243】Clever Y 拓展BSGS
调了一周,我真制杖,,, 各种初始化没有设为1,,,我当时到底在想什么??? 拓展BSGS,这是zky学长讲课的课件截屏: 是不是简单易懂.PS:聪哥说“拓展BSGS是偏题,省选不会考,信我没错”,那 ...
- ArcGIS 帮助(10.2、10.2.1 和 10.2.2)收集
帮助首页 [Oracle基础] 快速浏览:Oracle 地理数据库 什么是 Oracle Spatial? 设置到 Oracle 的连接 存储在 Oracle 地理数据库中的系统表 结合企业级地理数据 ...
- 100114J
经过思考后,很明显,我们可以看出应该是求出两条最长的链,链是指挂在连通块上的
- Freemarker 各种格式化
1.格式化日期 ${updated?string("yyyy-MM-dd HH:mm:ss")} 如果指定的变量不一定存在,可以这样: ${(dateMap.beginTime?s ...
- Linux的vim三种模式及命令
一般模式:在Linux终端中输入"vim 文件名"就进入了一般模式,但不能输入文字.编辑模式:在一般模式下按i就会进入编辑模式,此时就可以写程式,按Esc可回到一般模式. 命令模式 ...
- 【BZOJ-3450】Tyvj1952Easy 概率与期望DP
3450: Tyvj1952 Easy Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 468 Solved: 353[Submit][Status] ...
- 数组、ArraryList和List三者的区别
在C#中数组,ArrayList,List都能够存储一组对象,那么这三者到底有什么样的区别呢. 数组 数组在C#中最早出现的.在内存中是连续存储的,所以它的索引速度非常快,而且赋值与修改元素也很简单. ...
- 数据结构算法C语言实现(七)--- 3.1栈的线性实现及应用举例
一.简述 栈,LIFO.是操作受限的线性表,和线性表一样有两种存储表示方法.下面以顺序存储为例,实现. 二.ADT 暂无. 三.头文件 //3_1.h /** author:zhaoyu email: ...