Cube的高级设置
分享来源地址:http://bigdata.51cto.com/art/201705/538648.htm
Cube的高级设置
随着维度数目的增加,Cuboid 的数量会爆炸式地增长。为了缓解 Cube 的构建压力,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等。”
众所周知,Apache Kylin 的主要工作就是为源数据构建 N 个维度的 Cube,实现聚合的预计算。理论上而言,构建 N 个维度的 Cube 会生成 2N 个 Cuboid, 如图 1 所示,构建一个 4 个维度(A,B,C, D)的 Cube,需要生成 16 个Cuboid。

随着维度数目的增加 Cuboid 的数量会爆炸式地增长,不仅占用大量的存储空间还会延长 Cube 的构建时间。为了缓解 Cube 的构建压力,减少生成的 Cuboid 数目,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等,本系列将深入讲解这些高级设置的含义及其适用的场景。
聚合组(Aggregation Group)
用户根据自己关注的维度组合,可以划分出自己关注的组合大类,这些大类在 Apache Kylin 里面被称为聚合组。例如图 1 中展示的 Cube,如果用户仅仅关注维度 AB 组合和维度 CD 组合,那么该 Cube 则可以被分化成两个聚合组,分别是聚合组 AB 和聚合组 CD。如图 2 所示,生成的 Cuboid 数目从 16 个缩减成了 8 个。
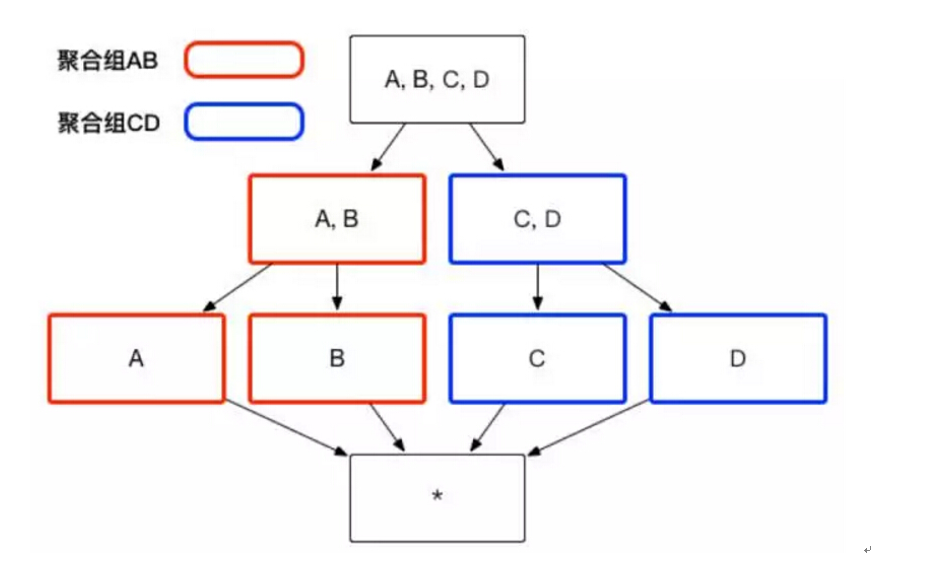
(图2)
用户关心的聚合组之间可能包含相同的维度,例如聚合组 ABC 和聚合组 BCD 都包含维度 B 和维度 C。这些聚合组之间会衍生出相同的 Cuboid,例如聚合组 ABC 会产生 Cuboid BC,聚合组 BCD 也会产生 Cuboid BC。这些 Cuboid不会被重复生成,一份 Cuboid 为这些聚合组所共有,如图 3 所示。
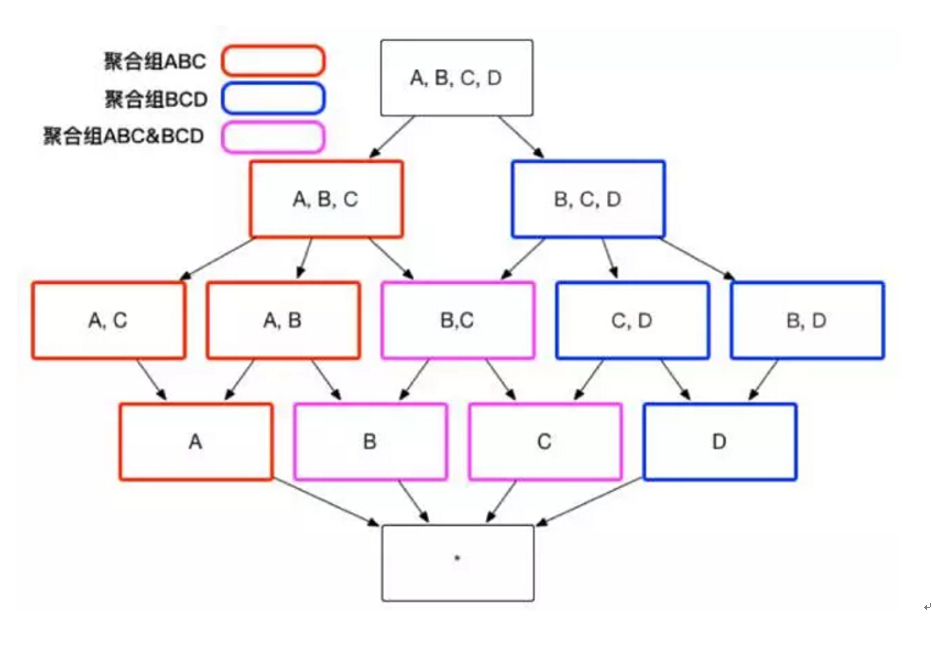
(图3)
有了聚合组用户就可以粗粒度地对 Cuboid 进行筛选,获取自己想要的维度组合。
聚合组应用实例
假设创建一个交易数据的 Cube,它包含了以下一些维度:顾客 ID buyer_id 交易日期 cal_dt、付款的方式 pay_type 和买家所在的城市 city。有时候,分析师需要通过分组聚合 city、cal_dt 和 pay_type 来获知不同消费方式在不同城市的应用情况;有时候,分析师需要通过聚合 city 、cal_dt 和 buyer_id,来查看顾客在不同城市的消费行为。在上述的实例中,推荐建立两个聚合组,包含的维度和方式如图 4 :
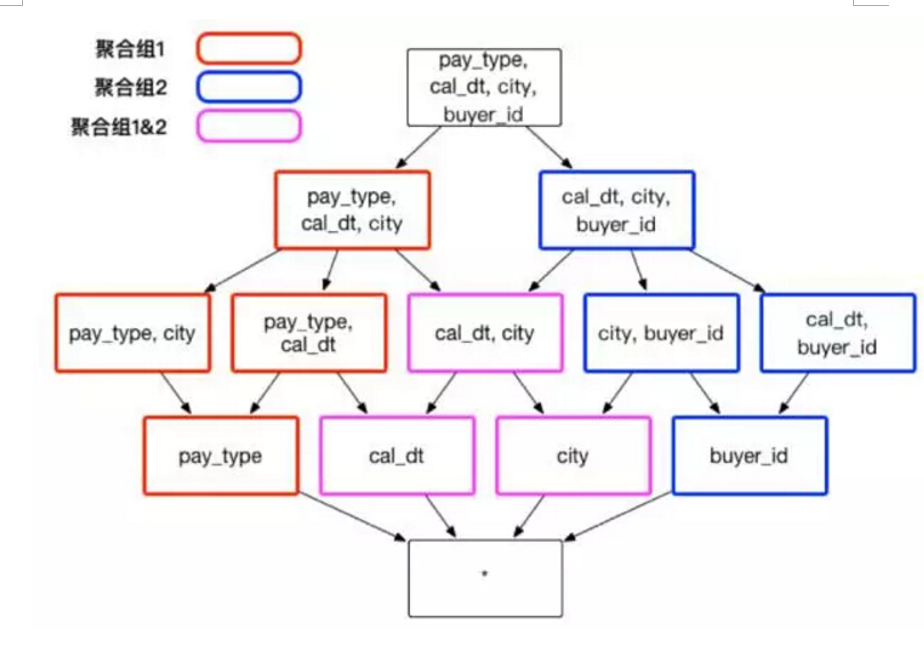
(图4)
聚合组 1: [cal_dt, city, pay_type]
聚合组 2: [cal_dt, city, buyer_id]
在不考虑其他干扰因素的情况下,这样的聚合组将节省不必要的 3 个 Cuboid: [pay_type, buyer_id]、[city, pay_type, buyer_id] 和 [cal_dt, pay_type, buyer_id] 等,节省了存储资源和构建的执行时间。
Case 1:
SELECT cal_dt, city, pay_type, count(*) FROM table GROUP BY cal_dt, city, pay_type 则将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case2:
SELECT cal_dt, city, buy_id, count(*) FROM table GROUP BY cal_dt, city, buyer_id 则将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case3 如果有一条不常用的查询:
SELECT pay_type, buyer_id, count(*) FROM table GROUP BY pay_type, buyer_id 则没有现成的完全匹配的 Cuboid。
此时,Apache Kylin 会通过在线计算的方式,从现有的 Cuboid 中计算出最终结果。
联合维度(Joint Dimension)
用户有时并不关心维度之间各种细节的组合方式,例如用户的查询语句中仅仅会出现 group by A, B, C,而不会出现 group by A, B 或者 group by C 等等这些细化的维度组合。这一类问题就是联合维度所解决的问题。例如将维度 A、B 和 C 定义为联合维度,Apache Kylin 就仅仅会构建 Cuboid ABC,而 Cuboid AB、BC、A 等等Cuboid 都不会被生成。最终的 Cube 结果如图5所示,Cuboid 数目从 16 减少到 4。
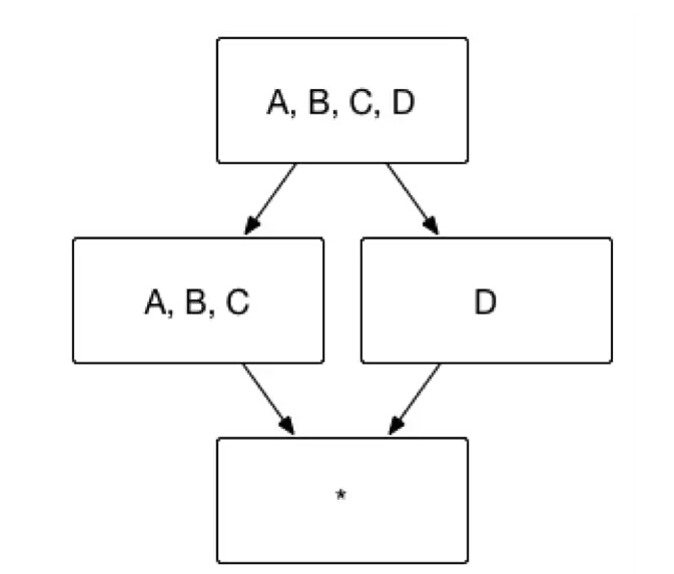
(图5)
联合维度应用实例
假设创建一个交易数据的Cube,它具有很多普通的维度,像是交易日期 cal_dt,交易的城市 city,顾客性别 sex_id 和支付类型 pay_type 等。分析师常用的分析方法为通过按照交易时间、交易地点和顾客性别来聚合,获取不同城市男女顾客间不同的消费偏好,例如同时聚合交易日期 cal_dt、交易的城市 city 和顾客性别 sex_id来分组。在上述的实例中,推荐在已有的聚合组中建立一组联合维度,包含的维度和组合方式如图6:
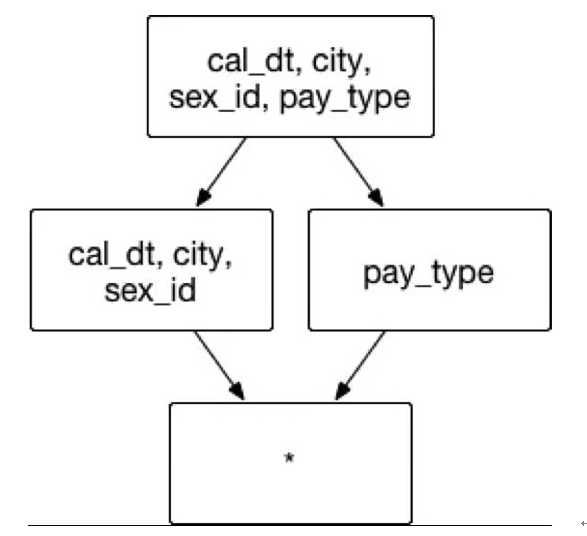
(图6)
聚合组:[cal_dt, city, sex_id,pay_type]
联合维度: [cal_dt, city, sex_id]
Case 1:
SELECT cal_dt, city, sex_id, count(*) FROM table GROUP BY cal_dt, city, sex_id 则它将从Cuboid [cal_dt, city, sex_id]中获取数据
Case2如果有一条不常用的查询:
SELECT cal_dt, city, count(*) FROM table GROUP BY cal_dt, city 则没有现成的完全匹配的 Cuboid,Apache Kylin 会通过在线计算的方式,从现有的 Cuboid 中计算出最终结果。
层级维度(Hierarchy Dimension)
用户选择的维度中常常会出现具有层级关系的维度。例如对于国家(country)、省份(province)和城市(city)这三个维度,从上而下来说国家/省份/城市之间分别是一对多的关系。也就是说,用户对于这三个维度的查询可以归类为以下三类:
- group by country
- group by country, province(等同于group by province)
- group by country, province, city(等同于 group by country, city 或者group by city)
以图7所示的 Cube 为例,假设维度 A 代表国家,维度 B 代表省份,维度 C 代表城市,那么ABC 三个维度可以被设置为层级维度,生成的Cube 如图7所示。
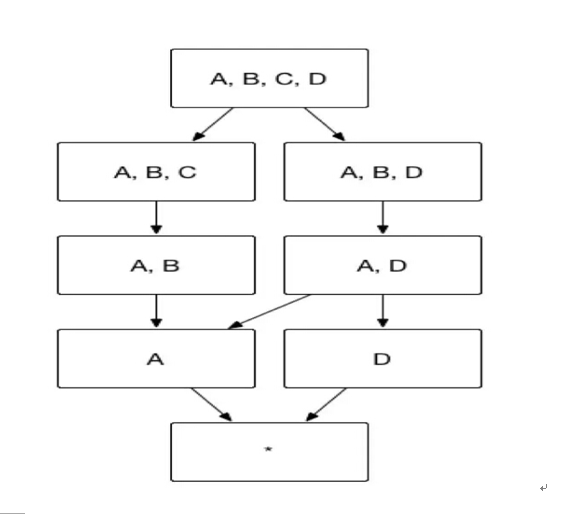
(图7)
例如,Cuboid [A,C,D]=Cuboid[A, B, C, D],Cuboid[B, D]=Cuboid[A, B, D],因而 Cuboid[A, C, D] 和 Cuboid[B, D] 就不必重复存储。
图8展示了 Kylin 按照前文的方法将冗余的Cuboid 剪枝从而形成图 2 的 Cube 结构,Cuboid 数目从 16 减小到 8。
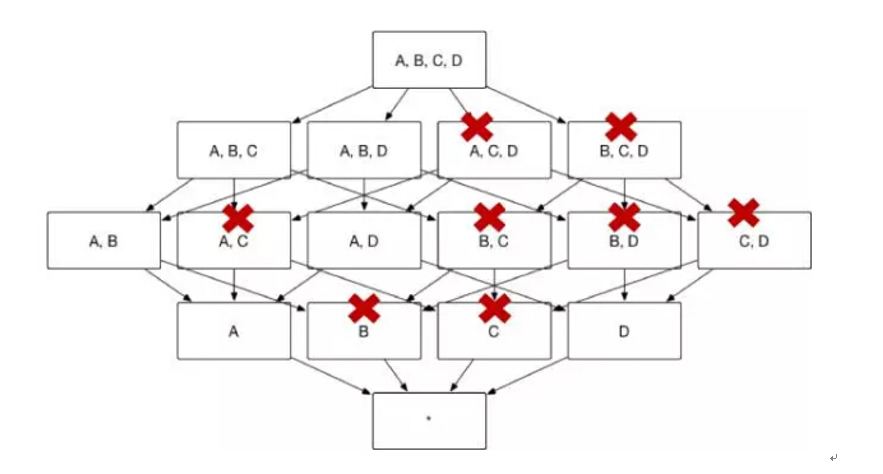
(图8)
层级维度应用实例
假设一个交易数据的 Cube,它具有很多普通的维度,像是交易的城市 city,交易的省 province,交易的国家 country, 和支付类型 pay_type等。分析师可以通过按照交易城市、交易省份、交易国家和支付类型来聚合,获取不同层级的地理位置消费者的支付偏好。在上述的实例中,建议在已有的聚合组中建立一组层级维度(国家country/省province/城市city),包含的维度和组合方式如图9:
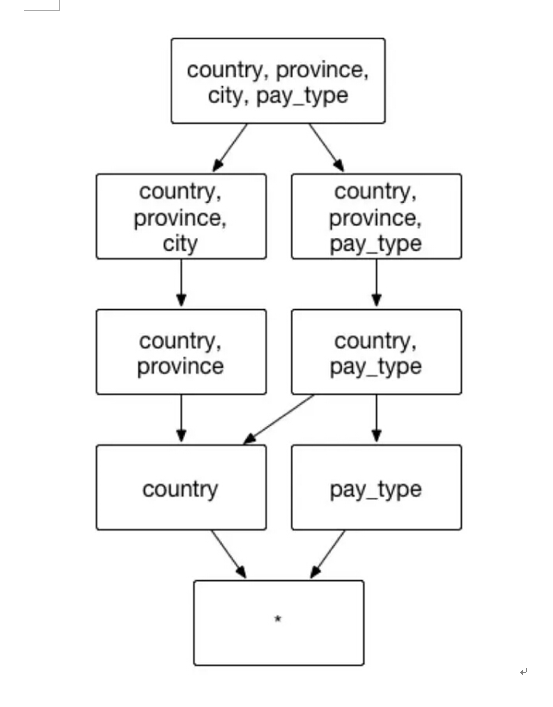
(图9)
聚合组:[country, province, city,pay_type]
层级维度: [country, province, city]
Case 1 当分析师想从城市维度获取消费偏好时:
SELECT city, pay_type, count(*) FROM table GROUP BY city, pay_type 则它将从 Cuboid [country, province, city, pay_type] 中获取数据。
Case 2 当分析师想从省级维度获取消费偏好时:
SELECT province, pay_type, count(*) FROM table GROUP BY province, pay_type 则它将从Cuboid [country, province, pay_type] 中获取数据。
Case 3 当分析师想从国家维度获取消费偏好时:
SELECT country, pay_type, count(*) FROM table GROUP BY country, pay_type 则它将从Cuboid [country, pay_type] 中获取数据。
Case 4 如果分析师想获取不同粒度地理维度的聚合结果时:
无一例外都可以由图 3 中的 cuboid 提供数据 。
例如,SELECT country, city, count(*) FROM table GROUP BY country, city 则它将从 Cuboid [country, province, city] 中获取数据。
必要维度 (Mandatory Dimension)
用户有时会对某一个或几个维度特别感兴趣,所有的查询请求中都存在group by这个维度,那么这个维度就被称为必要维度,只有包含此维度的Cuboid会被生成(如图10)。
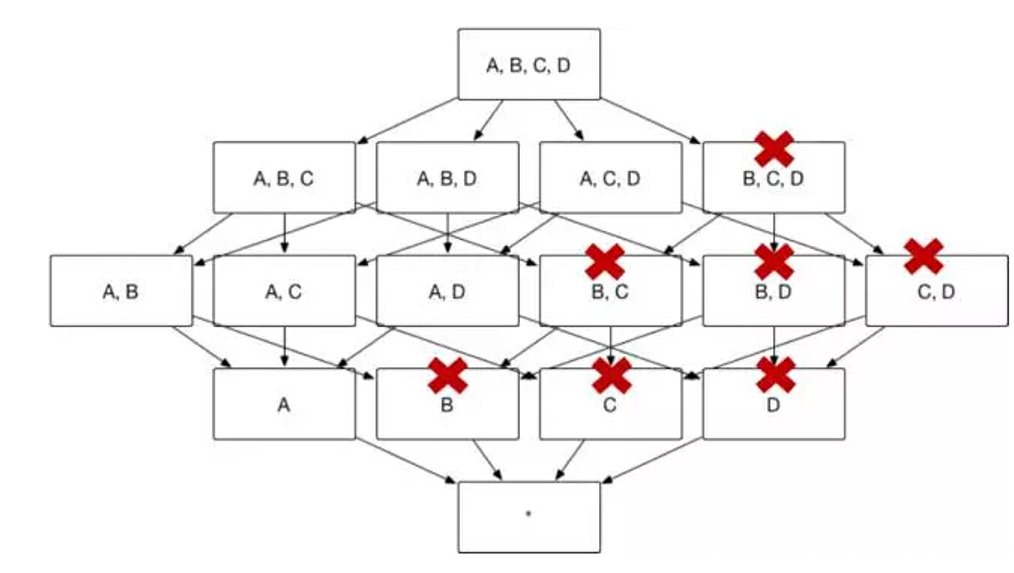
(图10)
以图 1中的Cube为例,假设维度A是必要维度,那么生成的Cube则如图11所示,维度数目从16变为9。
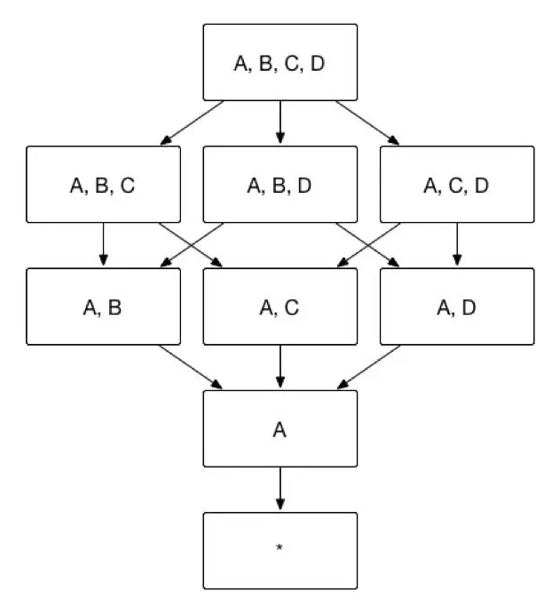
(图11)
必要维度应用实例
假设一个交易数据的Cube,它具有很多普通的维度,像是交易时间order_dt,交易的地点location,交易的商品product和支付类型pay_type等。其中,交易时间就是一个被高频作为分组条件(group by)的维度。 如果将交易时间order_dt设置为必要维度,包含的维度和组合方式如图12:
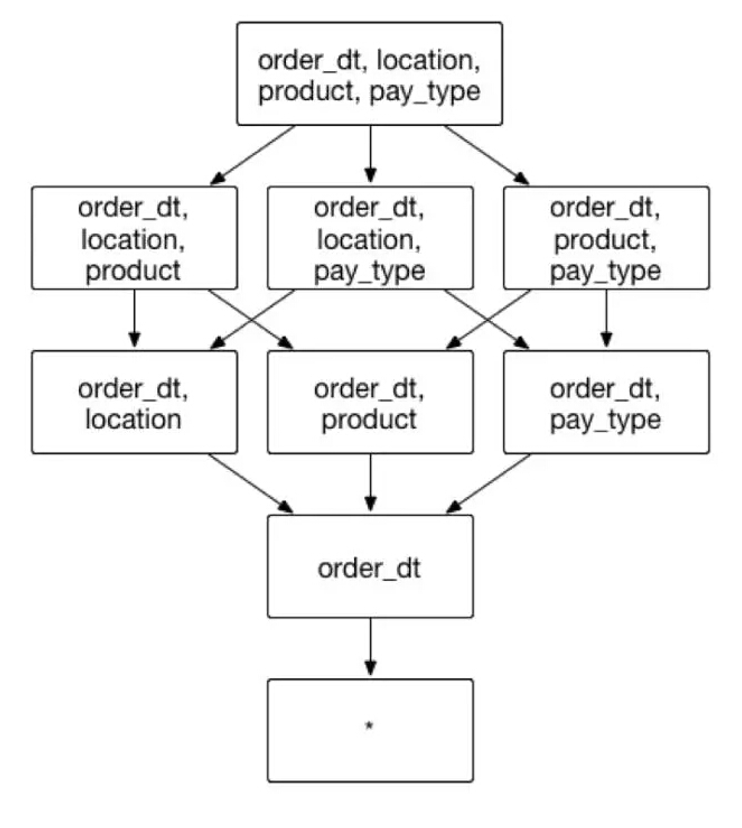
(图12)
系列总结
根据本系列的原理介绍,在Kylin的高级设置中,用户可以根据查询需求对Cube构建预计算的结果进行优化(剪枝),从而减少占用的存储空间。 而优化得当的Cube可以在占用尽量少的存储空间的同时提供极强的查询性能。
Cube的高级设置的更多相关文章
- Navicat(连接) -1高级设置
高级设置 设置位置当创建一个新的连接,Navicat 将在设置位置创建一个子文件夹.大多数文件都保存在该子文件夹: Navicat 对象 服务器类型 扩展名 查询 全部 .sql 导出查询结果设置文件 ...
- Netsharp快速入门(之17) Netsharp基础功能(参照高级设置)
5.2 参照高级设置 1. 以往来字段为例,打开平台工具-界面管理-列表管理,找到往来单位的资源节点,记下列表项目中的名称 2.记下往来单位部件工作区的id 3. 打开平台工具-界面管理-参照 ...
- 一个完整的Installshield安装程序实例—艾泽拉斯之海洋女神出品(四) --高级设置二
原文:一个完整的Installshield安装程序实例-艾泽拉斯之海洋女神出品(四) --高级设置二 上一篇:一个完整的安装程序实例—艾泽拉斯之海洋女神出品(三) --高级设置一4. 根据用户选择的组 ...
- 高级设置电脑系统windows7防火墙出错代码0×6D9原因与解决技巧
高级设置windows防火墙能够更好的保护电脑系统安全,在电脑系统windows7设置过程中难免会遇到某些问题,有用户在安装MRGT后想要打开SNMP的161端口,但在打开高级安全windows防火墙 ...
- cdnbest获取,删除,增加,修改域名列表,高级设置api示例
<?php $uid = 28; $vhost = 'asdfw'; $token = getToken($uid, $vhost); print_r($token); //获取token fu ...
- vsftp 虚拟用户高级设置(转载)
发布:xiaokk 来源:net [大 中 小] vsftp 虚拟用户高级设置 本文转自:http://www.jbxue.com/article/1724.html 1.安装所需软件包 ...
- 手把手教你搭饥荒专用服务器(三)—MOD及其他高级设置
友情链接: 手把手教你搭饥荒专用服务器(一)-服务器准备工作 手把手教你搭饥荒专用服务器(二)-环境配置及基本使用 手把手教你搭饥荒专用服务器(三)-MOD及其他高级设置 手把手教你搭饥荒专用服务器( ...
- PocketBeagle 初高级设置
前言 原创文章,转载引用务必注明链接,水平有限,如有疏漏,欢迎指正.本文使用markdown标记语言写成,为获得最好的阅读体验,请访问我的博客原文. 1. PocketBeagle Summary ...
- Protel99se轻松入门:特殊技巧和高级设置(一)
这里简单介绍一下自动布线和手动布线方面的设置问题 1.如何进入PCB的这个布线规则选项: 2.电气安全距离的设置 3.导线宽度的设置 4.学会了设置图层就可以做单面板以及多层板,而不只是双面板 5.布 ...
随机推荐
- Java引入的一些新特性
Java引入的一些新特性 Java 8 (又称为 jdk 1.8) 是 Java 语言开发的一个主要版本. Oracle 公司于 2014 年 3 月 18 日发布 Java 8 ,它支持函数式编程, ...
- SCOI2019 退役记
退役了.D2没有翻盘,愉快出队,文化课见. 19年4月14日:某校第一届的最后一名OIer退出竞赛. 留坑. 万一退役失败了呢
- Eclipse debug Source not found
点击打开链接最近开始慢慢转向idea开发了,但是因为旧项目是在eclipse里面.就没有在idea导入,所以旧项目就用eclipse,新项目就用idea.然而最近几天eclipse似乎不干了,每次de ...
- 【Docker】(1)---Docker入门篇
Docker入门篇 简单一句话: Docker 是一个便携的应用容器. 一.Docker的作用 网上铺天盖地的是这么说的: (1) Docker 容器的启动可以在秒级实现,这相比传统的虚拟机方式要快得 ...
- Linux命令之sftp - 安全文件传输命令行工具
用途说明 sftp命令可以通过ssh来上传和下载文件,是常用的文件传输工具,它的使用方式与ftp类似,但它使用ssh作为底层传输协议,所以安全性比ftp要好得多. 常用方式 格式:sftp <h ...
- Python和C++的混合编程(使用Boost编写Python的扩展包)
想要享受更轻松愉悦的编程,脚本语言是首选.想要更敏捷高效,c++则高山仰止.所以我一直试图在各种通用或者专用的脚本语言中将c++的优势融入其中.原来贡献过一篇<c++和js的混合编程>也是 ...
- Python:数据可视化pyecharts的使用
什么是pyecharts? pyecharts 是一个用于生成 Echarts 图表的类库. echarts 是百度开源的一个数据可视化 JS 库,主要用于数据可视化.pyecharts 是一个用于生 ...
- Chapter 5 Blood Type——20
"Just let me sit for a minute, please?" I begged. “就让我坐一会可以吗?” 我乞求道. He helped me sit on t ...
- Connection open error . Connection Timeout Expired. The timeout period elapsed during the post-login phase.
是这样的,最近我在开发Api(重构),用的数据库是Sqlserver,使用的Orm是 SqlSugar(别问我为什么选这个,boss选的同时我也想支持国人写的东西,且文档也很全). 被催的是,写好了程 ...
- Mysql实战面试题
一.索引 B+ Tree 原理 1. 数据结构 B Tree 指的是 Balance Tree,也就是平衡树.平衡树是一颗查找树,并且所有叶子节点位于同一层. B+ Tree 是基于 B Tree 和 ...