linux内核IDR机制详解【转】
这几天在看Linux内核的IPC命名空间时候看到关于IDR的一些管理性质的东西,刚开始看有些迷茫,深入看下去豁然开朗的感觉,把一些心得输出共勉。
我们来看一下什么是IDR?IDR的作用是什么呢?
先来看下IDR的作用:IDR主要实现ID与数据结构的绑定。刚开始看的时候感觉到有点懵,什么叫“ID与数据结构的绑定”?举一个例子大家就会明白了:在IPC通信的时候先要动态获取一个key值或者使用现有的key值进行通信,那么系统怎么知道这个key值是否使用了呢?这个就需要IDR来进行判断了。以上就是IDR的一些浅显的概念,IDR本质上就是通过对于ID一些有效的管理进而管理和这些ID有关的数据结构----不限于IPC通信的key值。
IDR怎么对于数据ID管理呢?传统上我们对于未使用的ID进行管理的时候可以使用位图进行管理,也可以使用数组进行管理,也可以使用链表进行ID管理,三个个各有优缺点:
- 使用位图进行管理的时候优点是使用空间少,但是对于位图对应的数据结构支持不太友好。
- 使用数组进行管理的时候寻址快速,但是只能管理比较少量的ID数目。
- 使用链表进行管理的时候虽然可以支持大量的数据ID,但是通过链表的指针寻址比较慢。
所以引入了以上三者的优点进行IDR管理。
IDR管理的核心
IDR把每一个ID分级数据进行管理,每一级维护着ID的5位数据,这样就可以把IDR分为7级进行管理(5*7=35,维护的数据大于32位),如下所示:
31 30 | 29 28 27 26 25 | 24 23 22 21 20 | 19 18 17 16 15 | 14 13 12 11 10 | 9 8 7 6 5 | 4 3 2 1 0
例如数据ID为0B 10 11111 10011 00111 11001 100001 00001,寻址如下:
1. 第一级寻址 ary1[0b10]得到第二级地址ary2[]
2. ary3 = ary2[0b11111]
3. ary4 = ary3[ob10011]
4. ary5 = ary4[0b00111]
5. ary6 = ary5[0b11001]
6. ary7 = ary6[0b100001]
7. ary8 = ary7[0b00001]
ary8即为要寻址到的ID对应的IDR指针。
如下图:
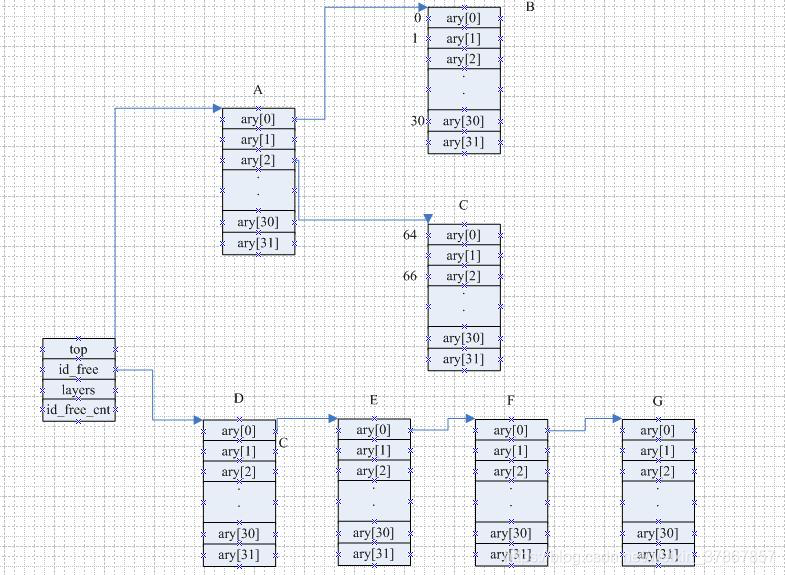
上图中每一个分级中的IDR数组中的值不为空代表相应位有效的ID位,但是使用数组下标标示有效的ID位还是有点慢----需要通过数组下标以及数组内容判断有效的ID位,所以对于每一个IDR引入了有效的ID位图来表示,每一个位图为32位刚好给出了相应的有效的ID位。方便查找。
上图中只是使用了IDR的32个数组表示,并没有给出IDR的位图以及层数标志,下面给出相应的数据结构:
IDR 数据结构:
struct idr_layer {
//位图,ary数组结构哪个有效
unsigned long bitmap; /* A zero bit means "space here" */
//IDR数组
struct idr_layer __rcu *ary[1<<IDR_BITS];
标示
int count; /* When zero, we can release it */
//层数,代表所在的ID位
int layer; /* distance from leaf */
struct rcu_head rcu_head;
};
struct idr {
//IDR层数头,实际上就是32叉树
struct idr_layer __rcu *top;
//尚未使用的IDR
struct idr_layer *id_free;
//层数
int layers; /* only valid without concurrent changes */
//id_free未用的个数;
int id_free_cnt;
spinlock_t lock;
};
下面讨论一下IDR的初始化以及增删改查ID问题:
- IDR的初始化
- IDR的增加
- IDR的查找
IDR的初始化:
IDR的初始化相对来说比较简单,使用IDR_INIT可以初始化一个IDR,原型如下:
#define IDR_INIT(name) \
{ \
.top = NULL, \
.id_free = NULL, \
.layers = 0, \
.id_free_cnt = 0, \
.lock = __SPIN_LOCK_UNLOCKED(name.lock), \
}
可以看到IDR只是把各个数据值为零,原子锁初始化下。
IDR的增加:
IDR增加比较复杂,在C中编程大部分情况可以分为如下两点讨论:
1.idr.top为NULL的情况;
2.idr.top不为NULL的情况;
以上考虑问题也是可以的,但是没有考虑到如下问题:
每一个idr_layer结构体有一个layer标示,我们每每增加一层,就要遍历整个idr的32叉树。无形中增加了系统负担。
idr设计者在考虑问题时候恰恰相反,没增加一个idr_layer层,就把要增加的idr_layer->ary[0]指向旧的idr_layer树的根,把要增加idr_layer->layer赋予旧的根部的idr_layer->layer + 1值,这样就不会考虑到idr->top为NULL的情况了。ps:只需要判断在增加第一个idr_layer时候判断一下,并且把idr_layer->layer值赋为0.
IDR的查找:
在查找IDR时侯会先查找IDR根节点,然后根据ID位所在的层的值遍历IDR树,如果查找到某一段树为NULL,则会返回NULL。
以下是IDR查找的过程:
void *idr_find(struct idr *idp, int id)
{
int n;
struct idr_layer *p;
//获取根IDR
p = rcu_dereference_raw(idp->top);
if (!p)
return NULL;
/**
根据IDR的层数获取要遍历的个数;
**/
n = (p->layer+1) * IDR_BITS;
/* 去除我们不需要查找的位数. */
id &= MAX_ID_MASK;
/***如果ID值大于n, 1<<n为根据层数换算过来的ID的最大值**/
if (id >= (1 << n))
return NULL;
BUG_ON(n == 0);
/***
遍历顺序:28---->0,每次减少5位,可以遍历完全IDR的32叉树
***/
while (n > 0 && p) {
n -= IDR_BITS;
BUG_ON(n != p->layer*IDR_BITS);
p = rcu_dereference_raw(p->ary[(id >> n) & IDR_MASK]);
}
return((void *)p);
}
linux内核IDR机制详解【转】的更多相关文章
- linux 内核 RCU机制详解
RCU(Read-Copy Update)是数据同步的一种方式,在当前的Linux内核中发挥着重要的作用.RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数 ...
- linux内核 RCU机制详解【转】
本文转载自:https://blog.csdn.net/xabc3000/article/details/15335131 简介 RCU(Read-Copy Update)是数据同步的一种方式,在当前 ...
- Linux内核ROP姿势详解(二)
/* 很棒的文章,在freebuf上发现了这篇文章上部分的翻译,但作者貌似弃坑了,顺手把下半部分也翻译了,原文见文尾链接 --by JDchen */ 介绍 在文章第一部分,我们演示了如何找到有用的R ...
- Linux内核异常处理体系结构详解(一)【转】
转自:http://www.techbulo.com/1841.html 2015年11月30日 ⁄ 基础知识 ⁄ 共 6653字 ⁄ 字号 小 中 大 ⁄ Linux内核异常处理体系结构详解(一)已 ...
- [转]Linux内核源码详解--iostat
Linux内核源码详解——命令篇之iostat 转自:http://www.cnblogs.com/york-hust/p/4846497.html 本文主要分析了Linux的iostat命令的源码, ...
- Linux find运行机制详解
本文目录: 1.1 find基本用法示例 1.2 find理论部分 1.2.1 expression-operators 1.2.2 expression-options 1.2.3 expressi ...
- linux内核 idr机制
idr机制解决了什么问题?为什么需要idr机制(或者说,idr机制这种解决方案,相对已有的其他方案,有什么优势所在) ? idr在linux内核中指的就是整数ID管理机制,从本质上来说,这就是一种将整 ...
- 嵌入式Linux内核I2C子系统详解
1.1 I2C总线知识 1.1.1 I2C总线物理拓扑结构 I2C总线在物理连接上非常简单,分别由SDA(串行数据线)和SCL(串行时钟线)及上拉电阻组成.通信原理是通过对SCL和SDA线高 ...
- linux内核调优详解
cat > /etc/sysctl.conf << EOF net.ipv4.ip_forward = net.ipv4.conf.all.rp_filter = net.ipv4. ...
随机推荐
- Android开发:Android虚拟机启动错误Can't find 'Linux version ' string in kernel image file
Android启动出错,虚拟机报错信息如下: Starting emulator for AVD 'test' emulator: ERROR: Can't find 'Linux version ' ...
- ThinkInJava之内部类
一:内部类概述 将一个类的定义放在另一个类的内部,这就是内部类.内部类是Java一种非常有用的特征,因为他允许你把一些逻辑相关的数据组织在一起,并控制它的可见性. 二:内部类的创建 我们都知道类的创建 ...
- vue + hbuilder 开发备忘录
踩过的坑: axios 安卓低版本兼容性处理 阻止表单中,button默认事件,出现刷新问题. 设置滚动条的位置 vue 数据和对象数据变化 dom结构不变 android低版本 白屏问题 你是不是用 ...
- FTP解决连接慢问题
今天发现程序报登录FTP超时,于是便手动登录发现真的慢,于是网上搜便获取大招亲测有效,于是怕忘的我马上记录下来,zzzzzzz!! 如下解决 vim /etc/vsftpd/vsftpd.conf 在 ...
- 利用Python爬去囧网福利(多线程、urllib、request)
import os; import urllib.request; import re; import threading;# 多线程 from urllib.error import URLErro ...
- C#版(击败100.00%的提交) - Leetcode 372. 超级次方 - 题解
版权声明: 本文为博主Bravo Yeung(知乎UserName同名)的原创文章,欲转载请先私信获博主允许,转载时请附上网址 http://blog.csdn.net/lzuacm. Leetcod ...
- Solr04 - 在Jetty和Tomcat上部署Solr单机服务
目录 1 准备安装环境 2 通过内部Jetty服务器启动 3 通过配置Tomcat服务器启动 3.1 删除不需要的应用 3.2 修改服务端口 3.3 部署solr.war 3.4 扩展: 虚拟目录发布 ...
- 记录阿里云服务器mysql被黑
前言 比上次服务器被黑还要恐怖的数据库被黑,再次强调,数据库不备份不做安全,你就可以准备跑路了. 这次记录一下整个被黑的过程,以及整个检查和处理的过程. 发现 上个月某一天,网站出现了无法登录的情况, ...
- AppBoxFuture(三): 分而治之
系统数据量达到一定程度后必将采用分库分表的方式来提高系统性能,但传统的分库分表方式也必将带来更高的开发复杂程度.新一代的NewSql及NoSql数据库由于天生的分布式存储基因,既保证了能够横向扩展 ...
- OpenCV在C#中应用—OpenCVSharp
1.什么是OpenCVSharp 之前一直是基于OpenCV开发视觉算法,但C++语言对于GUI的开发相对于C#来说确实很不方便,之前就了解到C#下使用OpenCV可以使用EmguCV,这段时间 ...