大数据学习之hdfs集群安装部署04
1-> 集群的准备工作
1)关闭防火墙(进行远程连接)
systemctl stop firewalld
systemctl -disable firewalld
2)永久修改设置主机名
vi /etc/hostname
注意:需要重启生效->reboot
3)配置映射文件
vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.40.11 bigdata11
192.168.40.12 bigdata12
192.168.40.13 bigdata13
2-> 安装jdk
1)上传tar包
用winscp那个软件吧
2)解压tar包
tar -zxvf jdk
3)配置环境变量
vi /etc/profile
export JAVA_HOME=/root/training/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
注意:加载环境变量 source /etc/profile
4)发送到其它机器(偷个懒,不用一个一个的配,哈哈哈)
scp -r /root/.bash_profile root@bigdata12:/root/.bash_profile
scp -r /root/.bash_profile root@bigdata13:/root/.bash_profile
注意:加载环境变量 source /etc/profile
5)配置ssh免密登录
-》ssh-keygen 生成密钥对
-》 ssh-copy-id 自己
ssh-copy-id 其它
ssh-copy-id 其它
每台机器都这样操作。
1:生产公钥对:ssh-keygen -t rsa(直接回车到底)
2:把公钥发送给serverB: ssh-copy-id -i .ssh/id_rsa.pub root@bigdata11
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata12
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata13
3-> 安装HDFS集群(注意,只是安装的hdfs,并非完全的hadoop,我们用到什么就装什么。有助于学习理解)
1) 修改hadoop-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
2) 修改core-site.xml
<!--配置hdfs-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata11:9000</value>
</property>
</configuration>
3) 修改hdfs-site.xml
<configuration>
<!--配置元数据存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/training/hadoop-2.8.4/dfs/name</value>
</property>
//配置数据存储位置
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/training/hadoop-2.8.4/dfs/data</value>
</property>
</configuration>
4)格式化namenode
hadoop namemode -format
5)分发hadoop到其它机器
scp -r /root/training/hadoop-2.8.4/ bigdata12:/root/training/
scp -r /root/training/hadoop-2.8.4/ bigdata13:/root/training/
6)配置hadoop环境变量
export HADOOP_HOME=/root/training/hadoop-2.8.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6)分发hadoop环境变量
scp -r /root/.bash_profile root@bigdata12:/root/.bash_profile
scp -r /root/.bash_profile root@bigdata13:/root/.bash_profile
注意:加载环境变量 source /root/.bash_profile(每个虚拟机都要配置)
7)启动namenode
hadoop-daemon.sh start namenode
8)启动datanode
hadoop-daemon.sh start datanode
9)访问namenode提供的web端口:50070
4-> 自动批量的启动脚本
1)修改配置文件vi /etc/hadoop/slaves(记得每台虚拟机都要配置哦)
bigdata12
bigdata13
2)执行启动命令
start-dfs.sh
start-dfs.sh
如果在安装过程中出现了问题。可以私聊我的qq。在线帮忙解决。或者将问题发在我qq邮箱1850748316@qq.com,我会第一时间回复你!!
附加一个免密登录的原理图吧!!
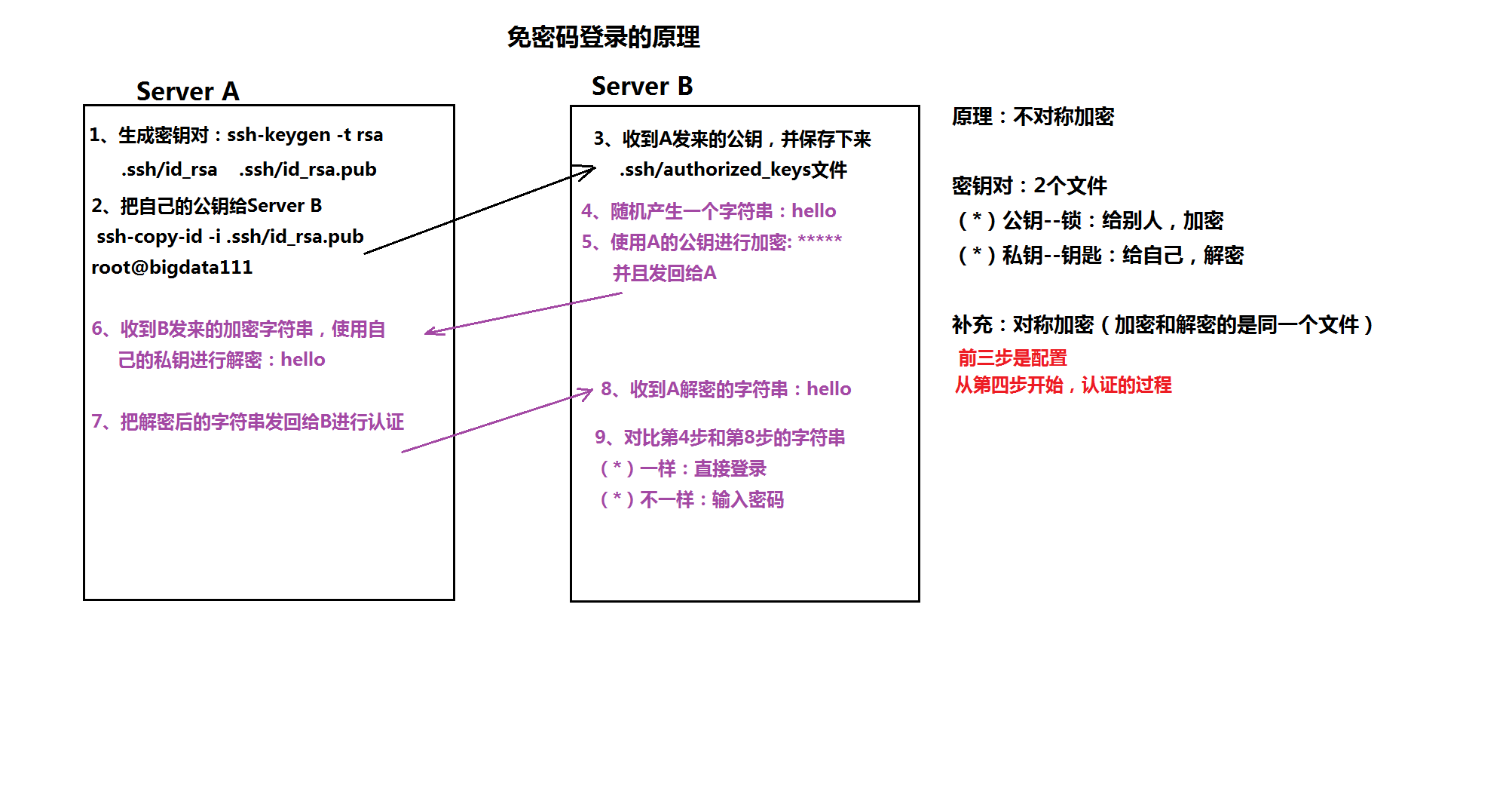
===========================================================》》
小bug1:secondNameNode(备份)在bigdata11那个机器上,这样第二名称节点也没有起什么作用!
完全成了摆设
解决方案:先在bigdata11上修改hdfs-site.xlm
添加如下代码
<property>
<!--注意不是https。-->
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata12:50090</value>
</property>
这里只是在bigdata11上修改了。由于是集群模式。所有机子都要修改!!!
直接分发到其他机器就行了
scp hdfs-site.xml bigdata12:$PWD
scp hdfs-site.xml bigdata13:$PWD
重启集群就会发现只有bigdata12上才有secondnamenode
大数据学习之hdfs集群安装部署04的更多相关文章
- 大数据平台搭建-spark集群安装
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- 大数据学习——hadoop2.x集群搭建
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- HDFS集群安装部署
准备环境: 三台centos7虚拟机(Node-1,Node-2,Node-3) 配置虚拟机网络,保证三台机器可以互相ping通,并且和宿主机可以互相ping通.如果仅仅是作为虚拟机学习,可以关闭防火 ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- 【分布式】Zookeeper伪集群安装部署
zookeeper:伪集群安装部署 只有一台linux主机,但却想要模拟搭建一套zookeeper集群的环境.可以使用伪集群模式来搭建.伪集群模式本质上就是在一个linux操作系统里面启动多个zook ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
随机推荐
- (二叉树 递归) leetcode 145. Binary Tree Postorder Traversal
Given a binary tree, return the postorder traversal of its nodes' values. Example: Input: [1,null,2, ...
- html中设置锚点定位
1.使用id定位: (这样的定位可以针对任何标签来定位. ) <a name="1F" href="#1F">锚点1</a> <d ...
- JavaEEspring整理
Spring框架—控制反转(IOC) 1 Spring框架概述 1.1 什么是Spring 1.2 S ...
- 一次对JDK进行"减肥"的记录
起因 最近做的一个小项目,因为要涉及到批量部署,每次在部署之前都需要在各个主机上先安装jdk环境(为了使用jdk自带的工具如jps等,所以没有单纯安装jre),但是因为jdk文件太大(以jdk-8u1 ...
- 一个关于kindle固件修改的问题
手头有一个序列号为B05A开头的日版kpw2,默认没有中文界面.之前看过@5201992318q 大神的帖子,原因是系统langpicker.conf文件中有一段判断序列号并删除语言的代码,于是我萌发 ...
- IIS中报错弹出调试,系统日志-错误应用程序名称: w3wp.exe,版本: 8.5.9600.16384,时间戳: 0x5215df96(360主机卫士)
偶遇一次特殊情况,在使用Web系统导入数据模版(excel)时,服务端IIS会报错并弹出调试框,然后整个网站都处于卡死的debug状态,如果点否不进行调试,则IIS会中断调试,Web系统继续执行,运行 ...
- .Net Core的Excel导入
1.前台代码,layui模板 2.后台代码,后台实现 (1)导入 (2)数据验证 (3)将导入数据存储在数据库中 (4)定义保存导入数据接口 (5)接口的实现调用业务层 (6)业务层接口 (7)业务层 ...
- L1-Day6
1.我喜欢哈尔滨的夏天 [我的翻译]I like the summer in harebing. [标准答案]I like the summer in Harbin. [对比分析]哈尔滨 Harbin ...
- 安卓触控一体机的逆袭之路_追逐品质_支持APP软件安卓
显示性能参数 接口:RGB信号 分辨率:1024*600 比例16:9 显示尺寸(A.A.):222.72*(W)*125.28(H)mm 外围尺寸:235.0(W)*143.0(H)*4.5(T)m ...
- FFT学习笔记
快速傅里叶变换FFT(Fast Fourior Transform) 先说一下它能干嘛qwq 傅里叶变换有两种,连续傅里叶变换和离散傅里叶变换,OI中主要用来快速计算多项式卷积. 等一下,卷积是啥 ...