高可用Redis(十三):Redis缓存的使用和设计
1.缓存的受益和成本
1.1 受益
1.可以加速读写:Redis是基于内存的数据源,通过缓存加速数据读取速度
2.降低后端负载:后端服务器通过前端缓存降低负载,业务端使用Redis降低后端数据源的负载等
1.2 成本
1.数据不一致:后端数据源中的数据缓存到Redis,如果后端数据库中的数据被更新时,根据更新策略不同,Redis缓存层中的数据和数据源的数据有时间窗口不一致
2.代码维护成本:多了一层缓存逻辑,以前只需要读取后端数据库,现在还需要维护缓存的读写以及Redis与数据库的连接等
3.运维成本:例如Redis Cluster
1.3 使用场景
1.降低后端负载:对高消耗的SQL,例如做排行榜的计算涉及到很多张数据表上数据的很复杂的实时计算,这种计算实际上没有任何意义,
如果使用Redis缓存,只需要第一次把计算结果写入到Redis缓存中,后续的计算直接在Redis中就可以了,join结果集/分组统计结果进行缓存
2.加速请求响应:由于Redis中的数据是保存在内存中的,利用Redis可以显著的提高IO响应时间
3.大量写请求合并为批量写:如计数器先使用Redis进行累加,最后把结果批量写入到后端数据库中,而不用每次都更新到后端数据库,有效降低后端数据库的负载
2.缓存的更新策略
缓存中的数据有生命周期,需要定期更新和删除,保证内存空间的合理使用以及缓存数据的一致,缓存数据需要根据合理的数据更新策略更新缓存中的数据
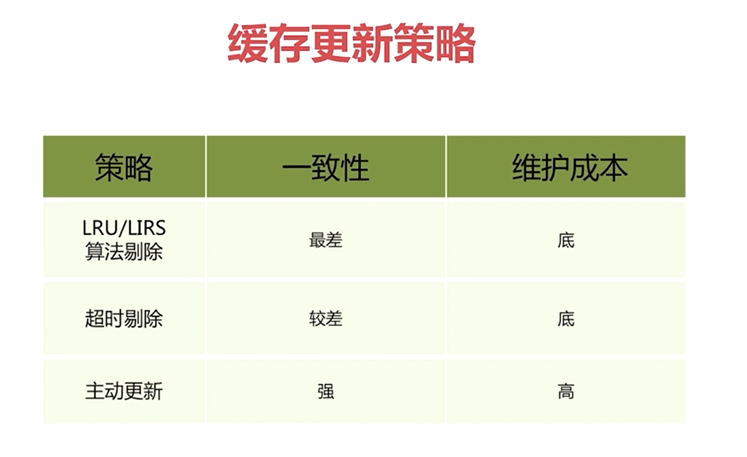
- LRU/LFU/FIFO算法剔除:Redis使用
maxmemory-policy,即Redis中的数据占用的内存超过设定的最大内存时的操作策略 - 超时剔除:对缓存的数据设置过期时间,超过过期时间自动删除缓存数据,然后再次进行缓存,保证与数据库中的数据一致
- 主动更新:开发者控制key的更新周期,当key在后端数据库中发生更新时,向Redis主动发送消息,Redis接收到消息对key进行更新或删除
Redis的配置文件中定义了下面的缓存更新策略
volatile-lru -> remove the key with an expire set using an LRU algorithm # 根据LRU算法删除过期的key
allkeys-lru -> remove any key according to the LRU algorithm # 根据LRU算法删除一些key
volatile-random -> remove a random key with an expire set # 随机删除一些设置了过期时间的key
allkeys-random -> remove a random key, any key # 从所有的key中随机删除一些key
volatile-ttl -> remove the key with the nearest expire time (minor TTL) # 删除一些快过期的key
noeviction -> don't expire at all, just return an error on write operations # 不删除任何key,在向Redis写入key时返回一个错误,这将会占用更多的内存
需要注意的是:with any of the above policies, Redis will return an error on write operations, when there are no suitable keys for eviction。即在上面的六种策略中,如果没有key可以被删除时,向Redis中写入数据会返回一个error异常
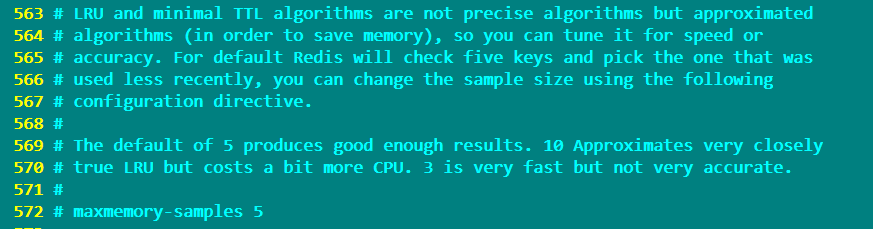
LRU和最小TTL算法并不是精确的算法,而是近似的算法(为了节省内存)。因此可以根据速度或准确性对其进行优化设置,使用maxmemory-samples选项来设置这个值
默认情况下,maxmemory-samples的值设置为5,即Redis将检查5个键并选择使用最少的一个key,如果设置为10,非常接近真实的LRU算法,但是另外消耗一些的CPU。如果设置为3则会加快Redis,但执行结果不够准确。
缓存更新策略对比
2.1 对于缓存的建议
- 对数据一致性要求不高,即真实数据和缓存数据差别较大对业务影响不大情况下,可以采用最大内存和淘汰策略,内存使用量超过
maxmemory-policy时,自动删除数据,而不会影响业务 - 对数据一致性要求较高,即真实数据和缓存数据差别较大会影响业务情况下,可以采用超时剔除和主动更新结合策略,由最大内存和淘汰策略兜底。如果主动更新的功能出现问题失效,没有把一些不必要的数据删除时,Redis占用的内存会越来越多,此时可以给一些有生命周期的key设置比较长的过期时间,然后设置
maxmemory和maxmemory-policy,来保证Redis占用的内存超过设置的最大内存时删除一些过期的key,来保证Redis的高可用
3.缓存粒度控制

上图中,使用Redis来做缓存,底层使用MySQL来做数据存储源,这种架构下大部分请求由Redis处理,少部分请求到达MySQL。
从MySQL中获取一个用户的所有信息,然后缓存到Redis的数据结构中。
此时需要面对一个问题:缓存这个用户的所有数据信息,还是缓存用户需要的用户信息字段。
可以从三个角度来考虑:
3.1 通用性
从通用性角度考虑,缓存全量属性更好。
当用户数据表字段发生改变时,不需要修改程序就可以直接同步修改之后的用户信息到Redis缓存中供用户使用,但是用占用更多的内存空间
3.2 占用空间
从占用空间的角度考虑,缓存部分属性更好.
同样当用户数据表字段发生改变时而用户需要这个字段信息时,就需要修改程序源代码来把修改之后的用户信息同步缓存到Redis中,这种情况下占用的内存空间比全量属性占用的内存空间要少
3.3 代码维护
从代码维护角度考虑,表面上全量属性更好。
不管数据源中的数据表结构如何改变,都会把所有的数据同步到Redis缓存中,而不需要修改程序源代码,但是在大多数情况下,不会使用到全量数据,只需要缓存需要的数据就可以了,从内存空间消耗及性能方面考虑,使用部分属性更好
3.4 总结
选择缓存属性时,需要综合考虑缓存全量属性还是部分属性
4.缓存穿透优化
4.1 什么叫缓存穿透
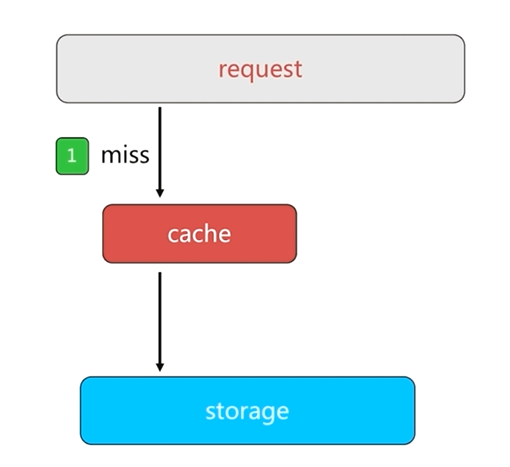
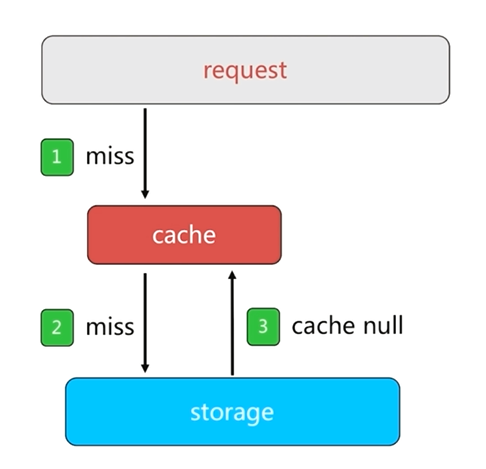
正常情况下,客户端从缓存中获取数据,如果缓存中没有用户请求需要的数据,就会读取数据源中的数据返回给客户端,同时把数据回写到缓存中。这样当下次客户端再请求这个数据时,就可以直接从缓存中获取数据而不需要经过数据库了。
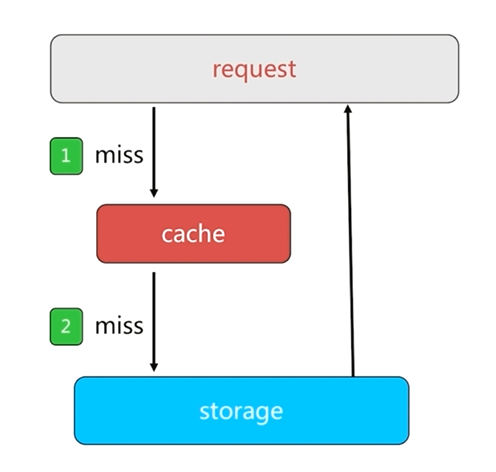
如果客户端获取一个数据源中没有的key时,先从缓存中获取,获取结果为null,然后到数据源中获取,同样获取结果为null,这样所有的请求都会到达数据源,这就是缓存穿透的基本过程
缓存的存在就是为了保护数据源,缓存穿透之后会对数据源造成巨大的负载和压力,这就失去了缓存的意义。
4.2 缓存穿透的原因
业务程序自身的问题:如无法对缓存进行回写等逻辑bug
恶意攻击,爬虫等
4.3 缓存穿透的发现
根据业务的响应时间来进行判断,当业务的响应时间远远过正常情况下的响应时间时,很有可能就是缓存穿透造成的
可以通过监控一些指标:总调用数,缓存层命中数,存储层命中数等发现缓存穿透
4.4 缓存穿透解决办法
4.4.1 缓存空对象
缓存空对象是一种简单粗暴的解决方法
当数据源中没有用户请求需要的数据时,会请求数据源,之前的做法是数据源返回一个null,而缓存中并不做回写,缓存空对象的做法就是把null回写到缓存中,暂时解决缓存穿透带来的压力
缓存空对象会造成两个问题
1.如果是恶意攻击和爬虫等,如果每次请求的数据都不一致,缓存空对象时会在缓存中设置很多的key,即使这些key的值都为空值,也会占用很多的内存空间,此时可以为这个key设置过期时间来降低这样的风险
2.缓存空对象并设置过期时间,在这个时间内即使数据源恢复正常,请求得到的结果仍然是null,造成缓存层和存储层数据短期不一致。这种情况下,可以通过订阅发布消息来解决,当数据源恢复正常时,会发布消息,然后把正常数据缓存到Redis中
4.4.2 布隆过滤器拦截
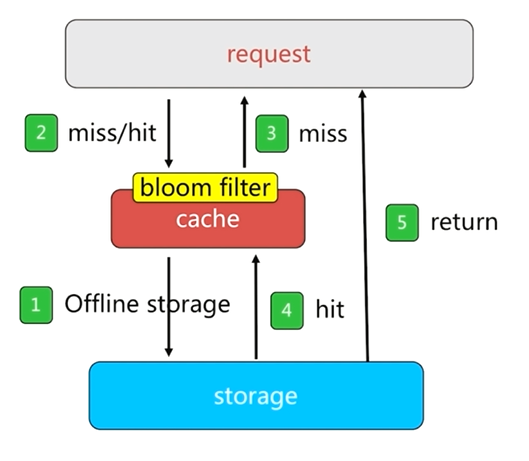
使用布隆过滤器可以通过占用很小的内存来对数据进行过滤
布隆过滤器拦截是把所有的key或者离散数据保存到布隆过滤器中,然后使用布隆过滤器在缓存层之前再做一层拦截。
如果请求没有被布隆过滤器拦截,则会到达缓存层获取需要的数据并返回,以达到实际效果
布隆过滤器对于固定的数据可以起到很好的效果,但是对于频繁更新的数据,布隆过滤器的构建会面临很多问题
4.4.3 缓存穿透解决办法对比
1.缓存空对象代码层面比较简单,但是需要一些额外的内存空间来保存空对象,而且会有短时间内的数据不一致性
2.布隆过滤器需要特殊的使用场景,布隆过滤器需要维护一些单独的代码,而且布隆过滤器也会占用额外的很少的内存空间来实现数据的过滤
5.无底洞问题优化
5.1 无底洞问题描述
2010年,Facebook已经有了3000个Memcache节点,Facebook发现问题:"加"Memcache节点,客户端批量操作的效率不仅没有提升,反而下降,这就是一个无底洞问题
5.2 无底洞问题关键点
当只有一个节点时,执行一次mget只产生一次网络IO;而当节点增加到3个时,使用顺序IO方式执行一次mget就会产生三次网络IO
同理,当节点越来越多,执行一次mget所需要的网络时间也越来越多,会对客户端的执行效率带来很大的下降
实际上网络IO由于扩容已经由原来的O(1)变成O(node)了,节点越多,并行执行一次mget命令所需要的时间就越长,如果串行执行mget命令所需要的时间就更多了。
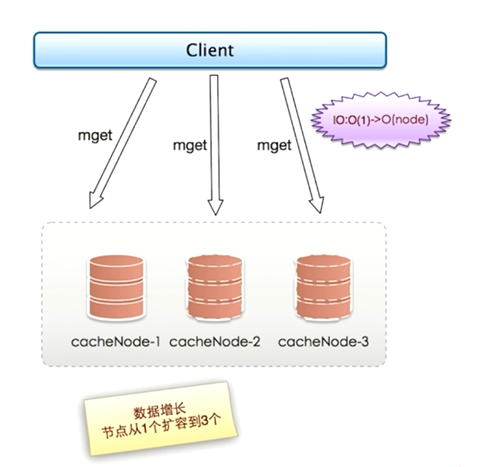
无底洞问题关键点即:
- 更多的机器 != 更多的性能
- 批量接口需求(mget和mset等):在执行mget和mset等命令时会面对的问题
- 数据增长与水平扩展需求等:随着业务量越来越大,对于缓存和数据源存储的需求也是越来越大,就需要对缓存和数据源进行扩容,即增加缓存节点和数据源节点,但是节点数量增多并不能带来性能的提升,这是一个矛盾的问题
5.3 优化IO的方法
- 优化命令本身:例如执行慢查询keys,hgetall bigkey等命令时,尽量选择在缓存节点压力不大时执行
- 减少网络通信次数,例如执行mget命令由原来的O(n)次网络时间缩减为O(node)次网络时间,
- 降低接入成本:例如客户端长连接/连接池,NIO等
5.4 四种批量优化方法:
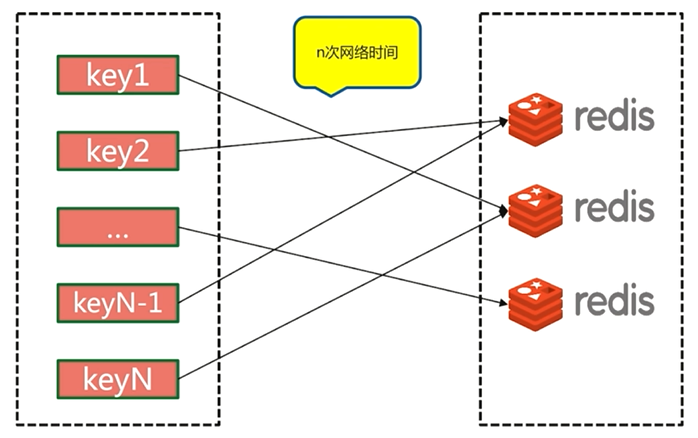
5.4.1 串行mget
串行mget需要n次网络时间
5.4.2 串行IO
由于客户端对key进行重新组装,所以把网络通信时间降低到节点次O(node)
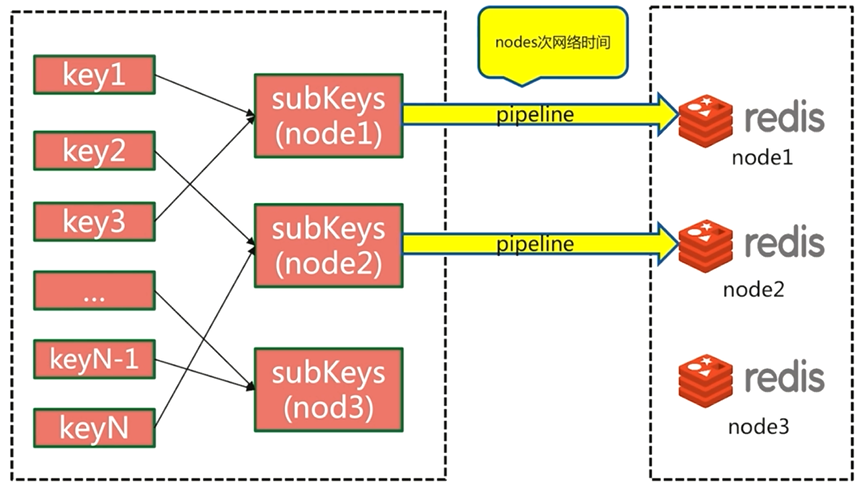
5.4.3 并行IO
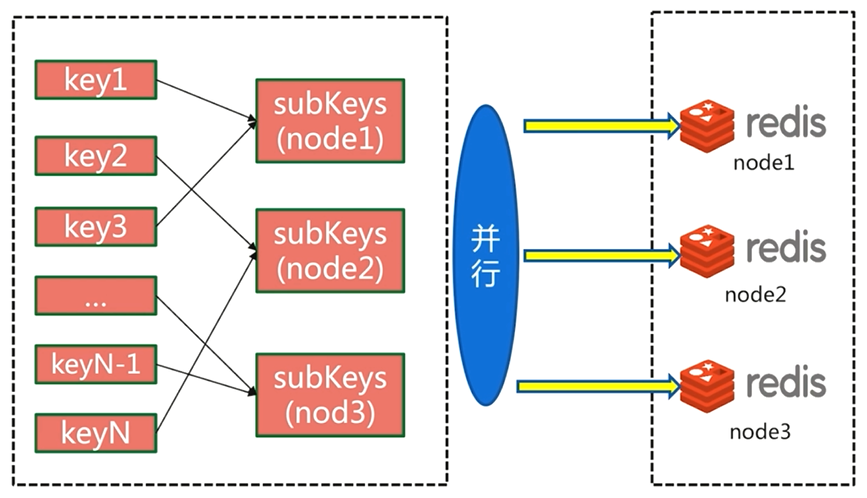
并行IO也会在客户端对key进行重新组装,然后执行并行操作,所需要的网络时间为O(1)
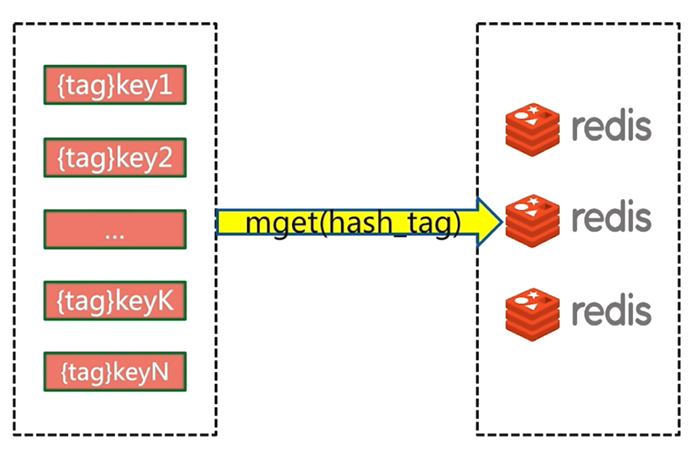
5.4.4 hash_tag
hash_tag会把所有的key都分配到一个节点,但是使用这种方法会遇到各种问题
5.5 四种优化方案的优缺点分析

6.执行key重建优化
6.1 缓存重建过程描述
在正常情况下,客户端发送请求,会先到缓存,从缓存中获取需要的数据,如果缓存中并没有需要数据,才会继续向数据源请求,从数据源中获取数据返回给客户端并回写到缓存中,这就是缓存的重建过程
6.2 缓存重建问题描述
如果重建的是一个热点key,用户访问量非常大。很多用户发送请求获取数据,执行线程从缓存中获取数据,但是此时缓存中并有这些数据,就会从数据源中获取数据,然后重建缓存。
当缓存重建完成,后续的访问才会直接读取缓存数制并返回
在这个过程中,会有很多线程同时查询并重建缓存key,一方面会对数据源造成很大压力,另一方面也会加大响应的时间
6.3 解决缓存重建的目标
减少缓存重建次数:不要多次重建缓存
数据尽可能一致:缓存中的数据要尽可能与数据源中的数据保持一致
减少潜在风险:可能造成死锁或者线程池大量被夯住等情况
6.4 缓存重建解决方法
6.4.1 互斥锁(mutex key)
互斥锁是一种比较直观和简单的解决思路
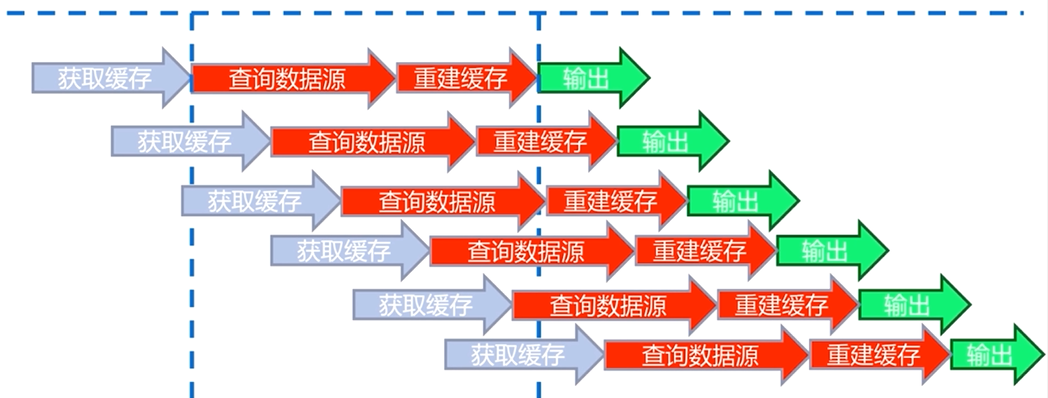
第一个用户从缓存中获取数据,此时缓存中并没有用户需要的数据,会从数据源中重建缓存,
用户在从数据源查询获取数据和重建缓存的过程中加上一把锁,当重建缓存完成以后再把锁解开,并返回
当第二个用户也想从缓存中获取数据时,如果第一个用户重建缓存的过程还没有结束,即锁还没有被解开时,就会等待,同样后续访问的用户也经过这样一个过程
当缓存重建完成,锁被解开,所有的用户请求都从缓存中获取数据并输出
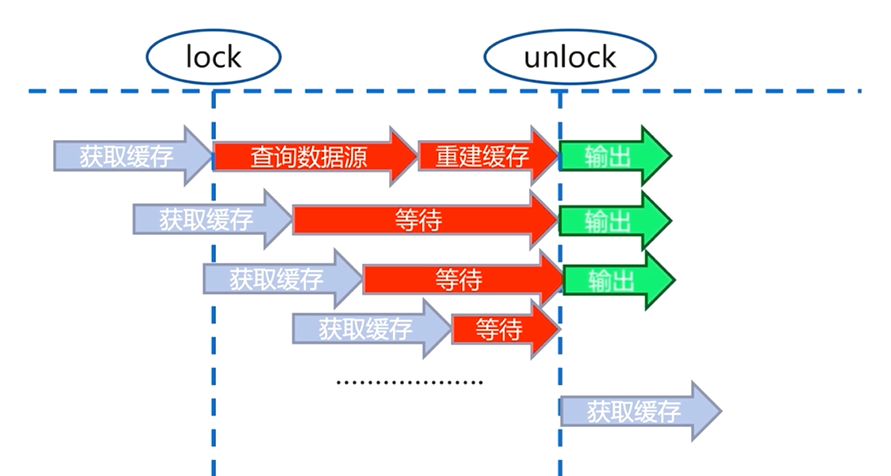
互斥锁解决了缓存大量重建的过程,但是在缓存重建的过程中会有一个等待时间,大量线程被夯住,有可能造成死锁的情况
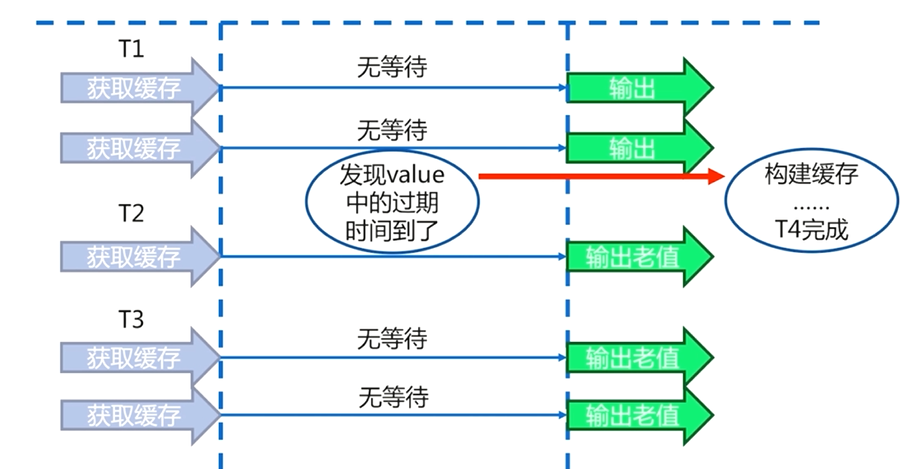
6.4.2 数据永不过期
在缓存层面,每一个key都不设置过期时间(没有设置expire)
在功能层面中,为每个value添加逻辑过期时间,一旦发现超过逻辑过期时间后,会使用单独的线程去构建缓存
需要注意的是
数据永不过期是一个异步的过程,即使缓存重建失败,也不会造成线程夯住的问题
数据永不过期基本杜绝了热点key的重建问题。
数据永不过期好处是:相比于使用互斥锁的方案,不会使用户产生一个等待的时间,而且可以保证只有一个线程来完成数据源的查询和缓存的重建
数据永不过期的缺点:在缓存重建完成之前,用户从缓存中得到的原来的数据有可能与从数据源中的新数据不一致的情况
数据永不过期中设置逻辑过期时间,会为每一个key设置过期时间,会增加维护成本,占用更多的内存空间。
6.4 缓存重建解决方法对比

高可用Redis(十三):Redis缓存的使用和设计的更多相关文章
- 《【面试突击】— Redis篇》--Redis Cluster及缓存使用和架构设计的常见问题
能坚持别人不能坚持的,才能拥有别人未曾拥有的.关注编程大道公众号,让我们一同坚持心中所想,一起成长!! <[面试突击]— Redis篇>--Redis Cluster及缓存使用和架构设计的 ...
- Redis入门到高可用(十三)—— 发布订阅
一.模型 二.主要API 1.publish(发布命令) 2.subcribe(订阅) 3.取消订阅(unsubcribe) 4.其他API 三.消息队列功能 redis实现消息队列功能 应用场景:抢 ...
- Redis(十三):Redis分布式锁的正确实现方式
前言 分布式锁一般有三种实现方式:1. 数据库乐观锁:2. 基于Redis的分布式锁:3. 基于ZooKeeper的分布式锁.本篇博客将介绍第二种方式,基于Redis实现分布式锁.虽然网上已经有各种介 ...
- SaltStack高可用multi-master-第十三篇
multi-master官方介绍 As of Salt 0.16.0, the ability to connect minions to multiple masters has been made ...
- 玩转 Redis缓存 集群高可用
转自:https://segmentfault.com/a/1190000008432854 Redis作为主流nosql,在高并发使用场景中都会涉及到集群和高可用的问题,有几种持久化?场景下的缓存策 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- asp.net core 实战之 redis 负载均衡和"高可用"实现
1.概述 分布式系统缓存已经变得不可或缺,本文主要阐述如何实现redis主从复制集群的负载均衡,以及 redis的"高可用"实现, 呵呵双引号的"高可用"并不是 ...
- net core 实战之 redis 负载均衡和"高可用"实现
net core 实战之 redis 负载均衡和"高可用"实现 1.概述 分布式系统缓存已经变得不可或缺,本文主要阐述如何实现redis主从复制集群的负载均衡,以及 redis的& ...
- Redis + keepalived 高可用群集搭建
本次实验环境介绍: 操作系统: Centos 7.3 IP : 192.168.10.10 Centos 7.3 IP : 192.168.10.20 VIP 地址 : 192.168.1 ...
- 如何搭建高可用redis架构?
如何搭建高可用redis架构? 温国兵 架构师小秘圈 昨天 作者:温国兵,曾任职于酷狗音乐,现为三七互娱 DBA.目前主要关注领域:数据库自动化运维.高可用架构设计.数据库安全.海量数据解决方案.以及 ...
随机推荐
- vue.js 列表追加项写法
<ul id="app"> <template v-for="site in sites"> <li>{{ site.nam ...
- 「Algospot」龙曲线DRAGON
一道考验思维的好题,顺便总结求第k大问题的常规思路: 传送门:$>here<$ 题意 给出初始串FX,每分形一次所有X替换为X+YF,所有Y替换为FX-Y.问$n$代字符串第$p$位起长度 ...
- jQuery截取字符串的几种方式
在我们写前端JS代码的时候,我们会遇到只需要其中部分字符串的时候,下面我就提供集中截取字符串的方法: 1.取后缀 var fileDir = $("#file").val(); v ...
- Maven 学习总结 (五) 之 持续集成、构建web应用
持续集成的作用.过程和优势 简单说,持续集成就是快速且高频率地自动构建项目的所有源码,并为项目成员提供丰富的反馈信息. 快速:集成的速度要尽可能地快,开发人员不希望自己的代码提交半天之后才得到反馈. ...
- 使用Docker安装Nginx
启动命令 docker run -d -p : --name nginx -v $PWD/nginx.conf:/etc/nginx/nginx.conf -v $PWD/conf.d/:/etc/n ...
- Linux关闭You have new mail in /var/spool/mail/root提示
终端远程登陆Linux后经常提示You have new mail in /var/spool/mail/root 这个提示是LINUX会定时查看LINUX各种状态做汇总,每经过一段时间会把汇总的信息 ...
- js中对cookie的操作及json数据与cookie结合的用法
cookie的使用 添加cookie 添加cookie:document.cookie = “key=value”; // 一次写入一个键值对 document.cookie = 'test1=hel ...
- python面试题一个字符串是否由重复的子字符串组成
一,给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成.给定的字符串只含有小写英文字母,并且长度不超过10000. 输入: "abab" 输出: True 解释: 可由 ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
- 解决axios在ie浏览器下提示promise未定义的问题
参考链接: https://blog.csdn.net/bhq1711617151/article/details/80266436 在做项目的时候发现在ie11上出现不兼容的问题,对于和后台交互这块 ...