[Python数据挖掘]第3章、数据探索
1、缺失值处理:删除、插补、不处理
2、离群点分析:简单统计量分析、3σ原则(数据服从正态分布)、箱型图(最好用)
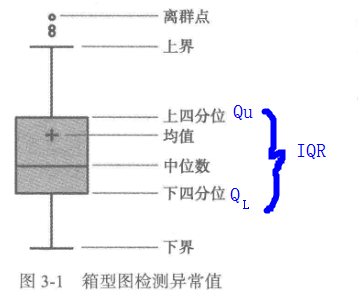
离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR
import pandas as pd catering_sale = '../data/catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列 import matplotlib.pyplot as plt #导入图像库
#plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
#plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 plt.figure() #建立图像
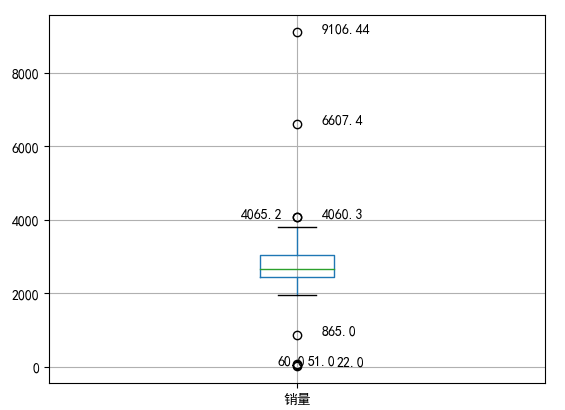
p = data.boxplot(return_type='dict') #画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'fliers'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象 #用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i])) plt.show() #展示箱线图
3、贡献度分析(帕累托分析,20/80定律)
import pandas as pd
import matplotlib.pyplot as plt #导入图像库 dish_profit = 'data/catering_dish_profit.xls' #餐饮菜品盈利数据
data = pd.read_excel(dish_profit, index_col = u'菜品名')
data = data[u'盈利'].copy()
data.sort_values(ascending = False) plt.figure()
data.plot(kind='bar')
plt.ylabel(u'盈利(元)')
p = 1.0*data.cumsum()/data.sum()
p.plot(color = 'r', secondary_y = True, style = '-o',linewidth = 2)
plt.annotate(format(p[6], '.4%'), xy = (6, p[6]), xytext=(6*0.9, p[6]*0.9), arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2")) #添加注释,即85%处的标记。这里包括了指定箭头样式。
plt.ylabel(u'盈利(比例)')
plt.show()

4、相关性分析(以餐饮数据为例)
导入数据

求相关系数的三种方式


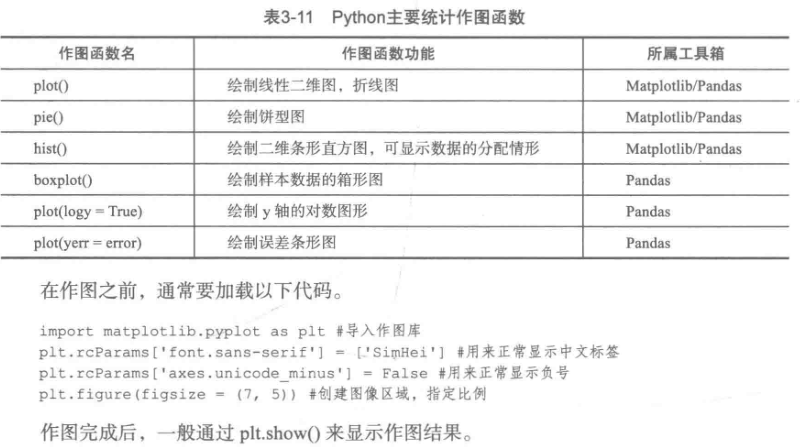
5、统计作图函数



[Python数据挖掘]第3章、数据探索的更多相关文章
- [Python数据挖掘]第4章、数据预处理
数据预处理主要包括数据清洗.数据集成.数据变换和数据规约,处理过程如图所示. 一.数据清洗 1.缺失值处理:删除.插补.不处理 ## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模) impo ...
- [Python数据挖掘]第7章、航空公司客户价值分析
一.背景和挖掘目标 二.分析方法与过程 客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary) 1.EDA(探索性数据分析) #对数据 ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- [Python数据挖掘]第8章、中医证型关联规则挖掘
一.背景和挖掘目标 二.分析方法与过程 1.数据获取 2.数据预处理 1.筛选有效问卷(根据表8-6的标准) 共发放1253份问卷,其中有效问卷数为930 2.属性规约 3.数据变换 ''' 聚类 ...
- [Python数据挖掘]第5章、挖掘建模(下)
四.关联规则 Apriori算法代码(被调函数部分没怎么看懂) from __future__ import print_function import pandas as pd #自定义连接函数,用 ...
- [Python数据挖掘]第5章、挖掘建模(上)
一.分类和回归 回归分析研究的范围大致如下: 1.逻辑回归 #逻辑回归 自动建模 import pandas as pd from sklearn.linear_model import Logist ...
- Python 数据分析—第七章 数据归整:清理、转换、合并、重塑
一.数据库风格的Dataframe合并 import pandas as pd import numpy as np df1 = pd.DataFrame({'1key':['b','b','a',' ...
- 数据挖掘(二)用python实现数据探索:汇总统计和可视化
今天我们来讲一讲有关数据探索的问题.其实这个概念还蛮容易理解的,就是我们刚拿到数据之后对数据进行的一个探索的过程,旨在了解数据的属性与分布,发现数据一些明显的规律,这样的话一方面有助于我们进行数据预处 ...
随机推荐
- 消除 ASP.NET Core 告警 "No XML encryptor configured. Key may be persisted to storage in unencrypted form"
在 ASP.NET Core 中如果在 DataProtection 中使用了 PersistKeysToFileSystem 或 PersistKeysToFileSystem services.A ...
- 中国省份毗邻关系JSON数据[相邻省份][所辖市级信息][行政区划]
最近做一个需求, 需要一份每个省份相邻[毗邻]的省份信息,这里整理了一版. json 数据,结构大致这样子的. [ { "id": 7, "name": &qu ...
- linux1
虚拟内存:内核通过磁盘上的存储空间来实现虚拟内存,这块区域称为交换空间.内核不断交换空间和实际的物理内存之间反复交换虚拟内存中的内容 linux运行中的程序叫做进程. 内核创建了第一个进程,叫做Ini ...
- 关于php得到参数数据
通过GET得到参数数据 $_SERVER['QUERY_STRING'] 获取?后面的值 $_SERVER['SCRIPT_NAME'] 获取当前脚本的路径 具体参数通过_GET['参数']获得 fi ...
- su: authentication failure 解决方法
在Linux上切换root时,密码正确..但提示:su: authentication failure ->sudo passwd ->Password:你当前的密码 ->Enter ...
- python练习题-day26
#bim(property) class People: def __init__(self,name,weight,height): self.name=name self.weight=weigh ...
- docker+kibana+filebeat的安装
安装filebeat服务(在需要收集日志的主机安装filebeat) 下载和安装key文件 rpm --import https://packages.elastic.co/GPG-KEY-elast ...
- python基础-->流程控制-->分支结构-->单项分支-->双向分支
# ###流程控制 ''' 流程:代码执行过程 流程控制:对代码执行过程的管控 顺序结构:代码默认从上到下依次执行 分支结构:对代码执行过程的管控 循环机构: while for ..in.... 分 ...
- 一个农民工混迹于 IT 行业多年后的泣血总结
一看题目,你心里一定闪出一个想法,这又是一篇软文吧,是不是,不想辩别了,自己判断吧哈哈.这是根据本人真实经历所写的一篇总结.假如你满足你的现状,这就是一篇软文,请立刻关闭此文章,继续你现在的生活. ...
- MATLAB矩阵运算
1. 矩阵的加减乘除和(共轭)转置 (1) 矩阵的加法和减法 如果矩阵A和B有相同的维度(行数和列数都相等),则可以定义它们的和A+B以及它们的差A-B,得到一个与A和B同维度的矩阵C,其中Cij=A ...