Kafka(二)设计原理
1、持久性
kafka使用文件存储消息,这就直接决定kafka在性能上严重依赖文件系统的本身特性。且无论任何OS下,对文件系统本身的优化几乎没有可能。因为kafka是对日志进行append操作,因此磁盘检索的开支是较小的;同时为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阈值再flush到磁盘,这样减少了磁盘IO调用的次数。
2、性能
需要考虑的影响性能点很多,除磁盘IO之外,我们还需要考虑网络IO,这直接关系到kafka的吞吐量问题,kafka并没有提供太多高超的技巧,对于producer端,可以将消息buffer起来,当消息的条数达到一定阀值的时候,批量发送给broker,对于consumer端也一样,批量fetch多条消息,不过消息量的大小可以通过配置文件来指定。对于kafka broker端,似乎有个sendfile系统调用可以潜在的提升网络IO性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次copy和交换,其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略。压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑,可以将任何在网络上传输的消息都经过压缩。kafka支持gzip/snappy等各种压缩方式。
3、生产者
负载均衡:producer将会和Topic下所有partition leader保持socket连接;消息由producer直接通过socket发送到broker,中间不会经过任何“路由层”,事实上,消息被路由到哪个partition上,由producer决定。比如可以采用“random”“key-hash”“轮询”等,如果一个topic中有多个partitions,那么producer端实现“消息均衡分发”是必要的。
其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper client,已经注册了watch用来监听partition leader的变更时间。
异步发送:将多的消息暂且在客户端buffer起来,并将它们批量的发送到broker,小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率。不过这也有一定的隐患,比如说当producer失效时,那些尚未发送的消息将会丢失
4、消费者
consumer端向broker发送“fetch”请求,并告知其获取消息的offset;此后consumer将会获得一定条数的消息;consumer端也可以重置offset来重新消费消息。
在JMS实现中,TOPIC模型基于push方式,即broker将消息推送给consumer端,不过在kafka中,采用了pull方式,即consumer在和broker建立连接之后,主动去pull或者说fetch消息。这种模式有些优点,首先consumer端可以根据自己的消费能力适时的去fetch消息并处理,且可以控制消息消费的进度(offset);此外,消费者可以良好的控制消息的数量,batch fetch。
其他JMS实现,消息消费的位置是由prodiver保留,以便避免重复发送消息或者将没有消费成功的消息重发等,同时还要控制消息的状态,这就要求JMS broker需要太多额外的工作。在kafka中,partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制。当消息被consumer接受之后,consumer可以在本地保存最后消息的offset,并间歇性的向zookeeper注册offset。
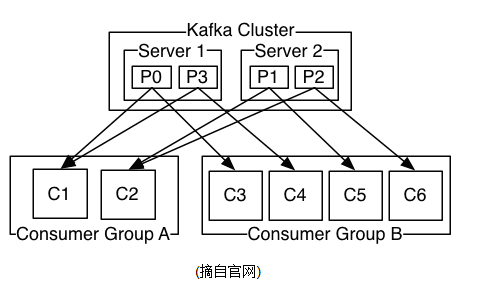
5、消息传送机制
对于JMS实现,消息传输担保非常直接:有且只有一次(exextly once)。在kafka中稍有不同。
- at most once:最多一次。这个和JMS中“非持久化”消息类似,发送一次,无论成败,将不会重发
- at least one: 如果offset未能成功同步到zookeeper,那么消息有可能再次被fetch
- exactly once:消息只会发送一次
6、复制备份
kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);备份的个数可以通过broker配置文件来设定.leader处理所有的read-write请求,follower需要和leader保持同步.Follower和consumer一样,消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它.即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.(不同于其他分布式存储,比如hbase需要"多数派"存活才行)
当leader失效时,需在followers中选取出新的leader,可能此时follower落后于leader,因此需要选择一个"up-to-date"的follower.选择follower时需要兼顾一个问题,就是新leaderserver上所已经承载的partition leader的个数,如果一个server上有过多的partition leader,意味着此server将承受着更多的IO压力.在选举新leader,需要考虑到"负载均衡".
7、日志
如果一个topic的名称为“my_topic”,它有2个partition,那么日志将会保存在my_topic_0和my_topic_1中,日志文件中保存了一系列"log entries",每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";每个日志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置。每个partition在物理存储层面,有多个log file组成(称为segment)。segmentfile的命名为“最小offset”.kafka。例如“00000000000.kafka”,其中“最小offset”表示此segment中起始消息的offset。
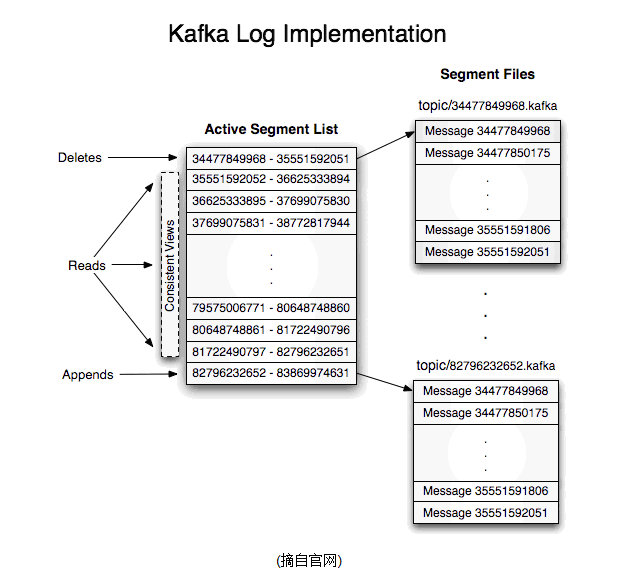
其中每个partition中所持有的segments列表信息会存储在zookeeper中。
当segment文件尺寸达到一定阈值时(可以通过配置文件设定,默认1G),将会创建一个新的文件;当buffer中消息的条数达到阀值时将会触发日志信息flush到日志文件中,同时如果“距离最近一次flush的时间差”达到阀值时,也会触发flush到日志文件。如果broker失效,极有可能会丢失那些尚未flush到文件消息。因为server意外实现,仍然会导致log文件格式的破坏(文件尾部),那么就要求当server启动是需要检测最后一个segment的文件结构是否合法并进行必要的修复。
获取消息时,需要指定offset和最大chunk尺寸,offset用来表示消息的起始位置,chunk size用来表示最大获取消息的总长度(间接的表示消息的条数)。根据offset,可以找到此消息所在segment文件,然后根据segment的最小offset取差值,得到它在file中的相对位置,直接读取输出即可。
日志文件的删除策略非常简单:启动一个后台线程定期扫描log file列表。把保存时间超过阈值的文件直接删除。为了避免删除文件时仍然有read操作,采取copy-on-write方式。
8、分配
kafka使用zookeeper来存储一些meta信息,并使用了zookeeper watch机制来发现meta信息的变更并作出相应的动作(比如consumer失效,触发负载均衡等)
- Broker node registry;当一个kafkabroker启动后,首先会向zookeeper注册自己的节点信息(临时znode),同时当broker和zookeeper断开连接时,此znode也会被删除。格式:/broker/ids/[0...N] --> host:port;其中[0..N]表示broker id,每个broker的配置文件中都需要指定一个数字类型的id(全局不可重复),znode的值为此broker的host:port信息
- Broker Topic Registry: 当一个broker启动时,会向zookeeper注册自己持有的topic和partitions信息,仍然是一个临时znode. 格式: /broker/topics/[topic]/[0...N] 其中[0..N]表示partition索引号.
- Consumer and Consumer group: 每个consumer客户端被创建时,会向zookeeper注册自己的信息;此作用主要是为了"负载均衡".一个group中的多个consumer可以交错的消费一个topic的所有partitions,简而言之,保证此topic的所有partitions都能被此group所消费,且消费时为了性能考虑,让partition相对均衡的分散到每个consumer上.
- Consumer id Registry: 每个consumer都有一个唯一的ID(host:uuid,可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息. 格式:/consumers/[group_id]/ids/[consumer_id]。仍然是一个临时的znode,此节点的值为{"topic_name":#streams...},即表示此consumer目前所消费的topic + partitions列表.
- Consumer offset Tracking: 用来跟踪每个consumer目前所消费的partition中最大的offset. 格式:/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]-->offset_value. 此znode为持久节点,可以看出offset跟group_id有关,以表明当group中一个消费者失效,其他consumer可以继续消费.
- Partition Owner registry: 用来标记partition被哪个consumer消费.临时znode. 格式:/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]-->consumer_node_id当consumer启动时,所触发的操作: (a)首先进行consumer id registry (b)然后在“consumer id registry”节点下注册一个watch用来监听当前group 中其他consumer 的leave 和 join;只要此znode path下节点列表变更。都会触发此group 下 consumer的负载均衡。(比如一个consumer失效,那么其它consumer接管partitions)(c)在Broker id registry节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance。
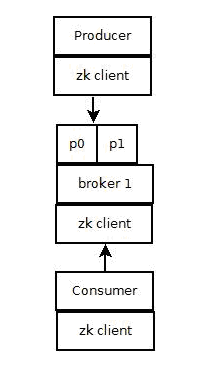
(1)Producer端使用zookeeper用来“发现”broker列表,以及和Topic下每个partition leader建立socket连接并发送消息。
(2)Broker端使用zookeeper用来注册broker信息,已经检测partitionleader存活性
(3)Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息
Kafka(二)设计原理的更多相关文章
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的原因是什么? 3.kafka集群consumer和producer状 ...
- Kafka设计原理
一.入门 1.简介 Apache Kafka是一个分布式消息发布订阅系统.它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log) ...
- 中间件 | kafka简介、使用场景、设计原理、主要配置及集群搭建
开源Java学习 公众号 一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性 ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- 深入理解kafka设计原理
最近开研究kafka,下面分享一下kafka的设计原理.kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力. 1.持久性 k ...
- 二 kafka设计原理
kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力. 1.持久性 kafka使用文件存储消息,这就直接决定kafka ...
- Kafka概述与设计原理
kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性: 1. 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. 2 .高吞吐量:即使是 ...
- 深入理解Kafka核心设计及原理(三):消费者
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16114877.html 深入理解Kafka核心设计及原理(一):初识Kafka 深入理解Kafka核心设计及原 ...
- 深入理解Kafka核心设计及原理(四):主题管理
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16124354.html 目录: 4.1创建主题 4.2 优先副本的选举 4.3 分区重分配 4.4 如何选择合 ...
- 深入理解Kafka核心设计及原理(五):消息存储
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16127749.html 目录: 5.1文件目录布局 5.2消息压缩 5.3日志索引 5.4日志文件及索引文件分 ...
随机推荐
- WSL(Windows Subsystem for Linux)--Pico Process Overview
[转载] Windows Subsystem for Linux -- Pico Process Overview Overview This post discusses pico processe ...
- win7下怎么安装IIS
工具/原料 win7旗舰版系统 笔记本一台 WIN7下怎么安装iis教程: 点击开始→控制面板,然后再点击程序和功能,勿点击卸载程序,否则到不了目标系统界面. 然后在程序和功能下面,点击打开和关闭wi ...
- git简单提交操作
一.本地仓库操作 1.打开git命令行,先'到需要提交的目录 2.输入git init,初始化本地仓库 3.输入git add <file> 命令添加提交文件 4.输入git status ...
- 数论 C - Aladdin and the Flying Carpet
It's said that Aladdin had to solve seven mysteries before getting the Magical Lamp which summons a ...
- C# 中利用 CRC32 值判断文件是否重复
需要在 NuGet 中引用 Crc32.NET 包 直接贴代码了: using Force.Crc32; using System; using System.Collections.Generic; ...
- CentOS7 安装配置 MySQL 5.7
1. 下载 yum 源文件 mysql80-community-release-el7-2.noarch.rpm https://dev.mysql.com/downloads/repo/yum/ 2 ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- OpenCV4.1.0实践(3) - 图片缩放
简单的案例: (1)通过比例进行缩放 import cv2 as cv import numpy as np # 图片缩放 img = cv.imread('images/animal.jpg', f ...
- XXXX is not in the sudoers file. This incident will be reported解决方法
假设你用的是Red Hat系列(包括Fedora和CentOS)的Linux系统.当你执行sudo命令时可能会提示“某某用户 is not in the sudoers file. This inc ...
- pypinyin, jieba分词与Gensim
一 . pypinyin from pypinyin import lazy_pinyin, TONE, TONE2, TONE3 word = '孙悟空' print(lazy_pinyin(wor ...