(转)The Evolved Transformer - Enhancing Transformer with Neural Architecture Search
The Evolved Transformer - Enhancing Transformer with Neural Architecture Search
2019-03-26 19:14:33
A new paper by Google Brain presents the first NAS to improve Transformer, one of the leading architecture for many Natural Language Processing tasks. The paper uses an evolution-based algorithm, with a novel approach to speed up the search process, to mutate the Transformer architecture to discover a better one — The Evolved Transformer (ET). The new architecture performs better than the original Transformer, especially when comparing small mobile-friendly models, and requires less training time. The concepts presented in the paper, such as the use of NAS to evolve human-designed models, has the potential to help researchers improve their architectures in many other areas.
Background
Transformers, first suggested in 2017, introduced an attention mechanism that processes the entire text input simultaneously to learn contextual relations between words. A Transformer includes two parts — an encoder that reads the text input and generates a lateral representation of it (e.g. a vector for each word), and a decoder that produces the translated text from that representation. The design has proven to be very effective and many of today’s state-of-the-art models (e.g. BERT, GPT-2) are based on Transformers. An in-depth review of Transformers can be found here.
While the Transformer’s architecture was hand-crafted manually by talented researchers, an alternative is to use search algorithms. Their goal is to find the best architecture in the given search space — A space that defines the constraints of any model in it, such as number of layers, maximum number of parameters, etc. A known search algorithm is the evolution-based algorithm, Tournament Selection, in which the fittest architectures survive and mutate while the weakest die. The advantage of this algorithm is its simplicity while still being efficient. The paper relies on a version presented in Real et al. (see pseudo-code in Appendix A):
- The first pool of models is initialized by randomly sampling the search space or by using a known model as a seed.
- These models are trained for the given task and randomly sampled to create subpopulation.
- The best models are mutated by randomly changing a small part of their architecture, such as replacing a layer or changing the connection between two layers.
- The mutated models (child models) are added to the pool while the weakest model from the subpopulation is removed from the pool.
Defining the search space is an additional challenge when solving a search problem. If the space is too broad and undefined, the algorithm might not converge and find a better model in a reasonable amount of time. On the other hand, a space that is too narrow reduces the probability of finding an innovative model that outperforms the hand-crafted ones. The NASNet search architecture approaches this challenge by defining “stackable cells”. A cell can contain a set of operations on its input (e.g. convolution) from a predefined vocabulary and the model is built by stacking the same cell architecture several times. The goal of the search algorithm is only to find the best architecture of a cell.
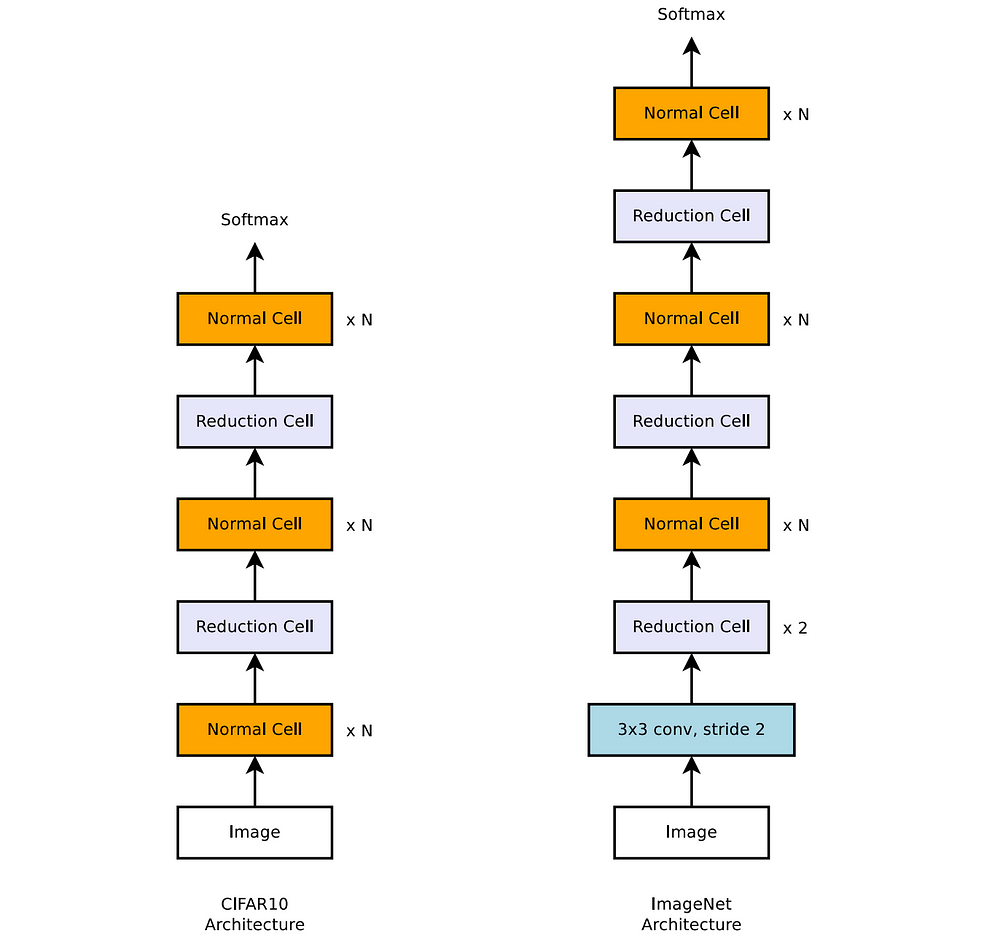
An example of the NASNet search architecture for image classification task that contains two types of stackable cells (Normal and Reduction Cell). Source: Zoph et al.
How Evolved Transformer (ET) works
As the Transformer architecture has proven itself numerous times, the goal of the authors was to use a search algorithm to evolve it into an even better model. As a result, the model frame and the search space were designed to fit the original Transformer architecture in the following way:
- The algorithm searches for two types of cells — one for the encoder with six copies (blocks) and another for the decoder with eight copies.
- Each block includes two branches of operations as shown in the following chart. For example, the inputs are any two outputs of the previous layers (blocks), a layer can be a standard convolution, attention head (see Transformer), etc, and activation can be ReLU and Leaky ReLU. Some elements can also be an identity operation or a dead-end.
- Each cell can be repeated up to six times.
In total, the search space adds up to ~7.3 * 10115 optional models. A detailed description of the space can be found in the appendix of the paper.
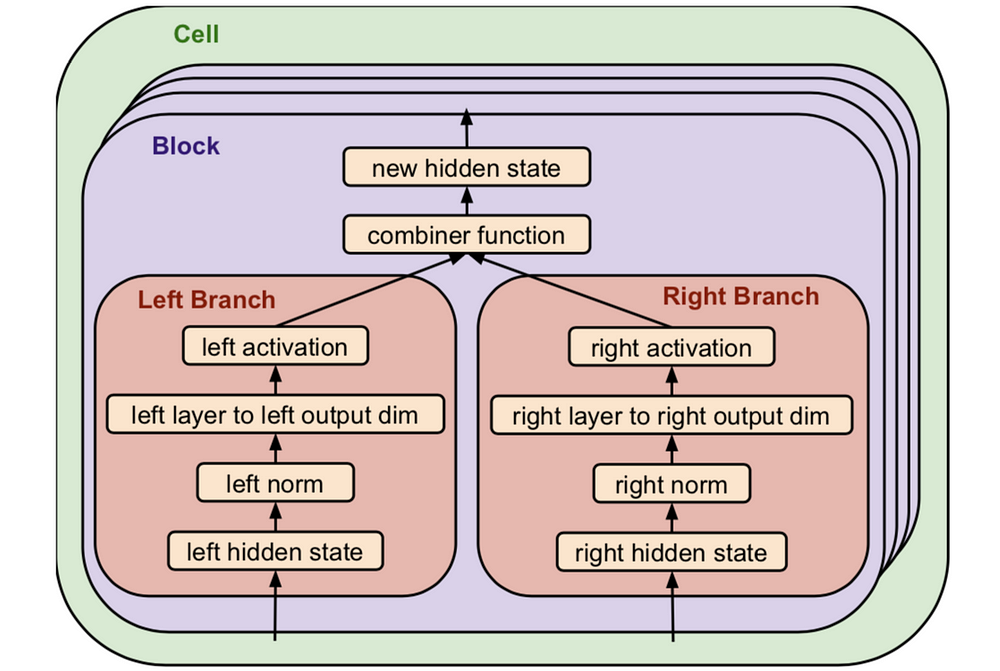
ET Stackable Cell format. Source: ET
Progressive Dynamic Hurdles (PDH)
Searching the entire space might take too long if the training and evaluation of each model are prolonged. It’s possible to overcome this problem in the field of image classification by performing the search on a proxy task, such as training a smaller dataset (e.g. CIFAR-10) before testing on a bigger dataset such as ImageNet. However, the authors couldn’t find an equivalent solution for translation models and therefore introduced an upgraded version of the tournament selection algorithm.
Instead of training each model in the pool on the entire dataset, a process that takes ~10 hours on a single TPU, the training is done gradually and only for the best models in the pool. The models in the pool are trained on a given amount of samples and more models are created according to the original tournament selection algorithm. Once there are enough models in the pool, a “fitness” threshold is calculated and only the models with better results (fitness) continue to the next step. These models will be trained on another batch of samples and the next models will be created and mutated based on them. As a result, PDH significantly reduces the training time spent on failing models and increases search efficiency. The downside is that “slow starters”, models that need more samples to achieve good results, might be missed.
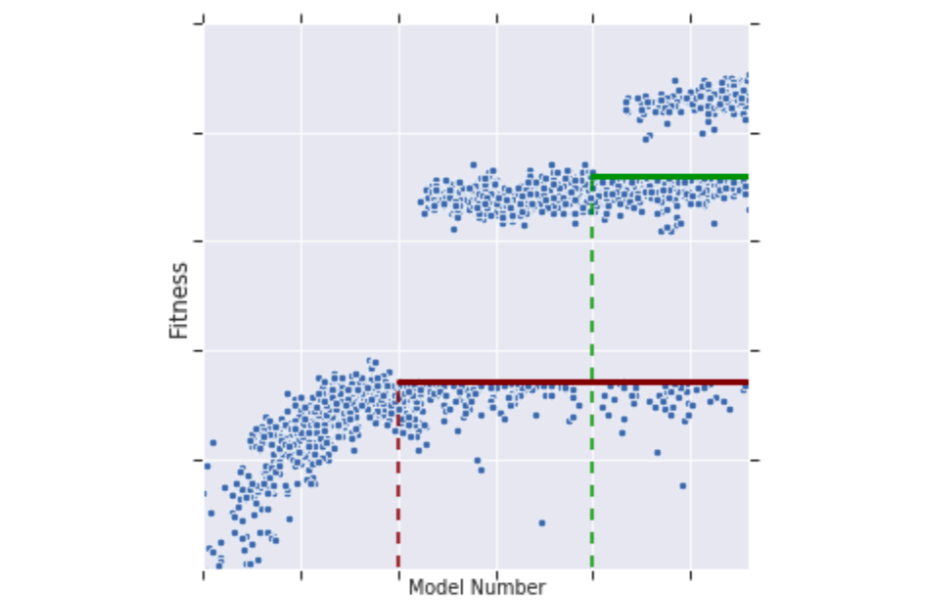
An example of the tournament selection training process. The models above the fitness threshold are trained on more sample and therefore reach better fitness. The fitness threshold increases in steps as new models are created. Source: ET
To “help” the search achieve high-quality results the authors initialized the search with the Transformer model instead of a complete random model. This step is necessary due to computing resources constraints. The table below compares the performance of the best model (using the perplexity metric, the lower the better) of different search techniques — Transformer vs. random initialization and PDH vs. regular tournament selection (with a given number of training steps per model).
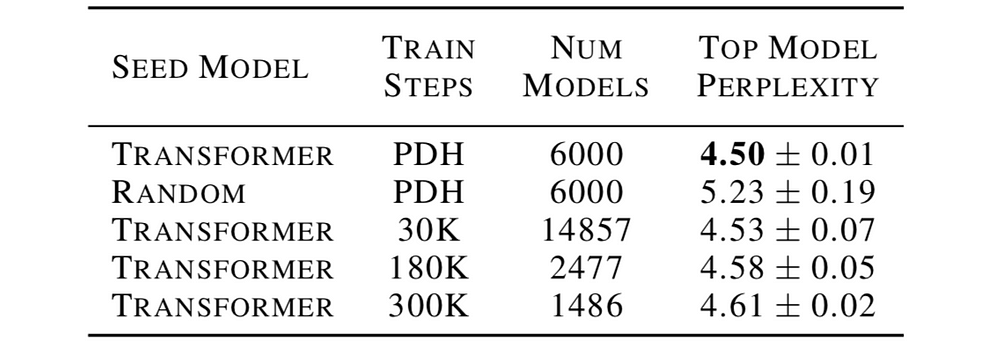
Comparison of different search techniques. Source: ET
The authors kept the total training time of each technique fixed and therefore the number of models differs: more training steps per model -> fewer total number of models can be searched and vice-versa. The PDH technique achieves the best results on average while being more stable (low variance). When reducing the number of training steps (30K), the regular technique performs almost as good on average as PDH. However, it suffers from a higher variance as it’s more prone to mistakes in the search process.
Results
The paper uses the described search space and PDH to find a translation model that performs well on known datasets such as WMT’18. The search algorithm ran on 15,000 models using 270 TPUs for a total of almost 1 billion steps, while without PDH the total required steps would have been 3.6 billion. The best model found was named The Evolved Transformer (ET) and achieved better results compared to the original Transformer (perplexity of 3.95 vs 4.05) and required less training time. Its encoder and decoder block architectures are shown in the following chart (compared to the original ones).
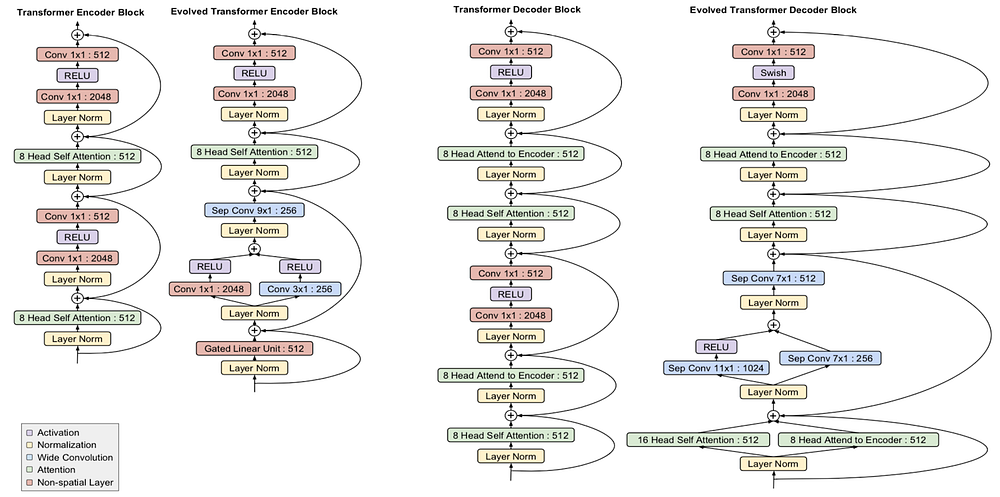
Transformer and ET encoder and decoder architectures. Source: ET
While some of the ET components are similar to the original one, others are less conventional such as depth-wise separable convolutions, which is more parameter efficient but less powerful compared to normal convolution. Another interesting example is the use of parallel branches (e.g. two convolution and RELU layers for the same input) in both the decoder and the encoder. The authors also discovered in an ablation study that the superior performance cannot be attributed to any single mutation of the ET compared to the Transformer.
Both ET and Transformer are heavy models with over 200 million parameters. Their size can be reduced by changing the input embedding (i.e. a word vector) size and the rest of the layers accordingly. Interestingly, the smaller the model the bigger the advantage of ET over Transformer. For example, for the smallest model with only 7 million parameters, ET outperforms Transformer by 1 perplexity point (7.62 vs 8.62).
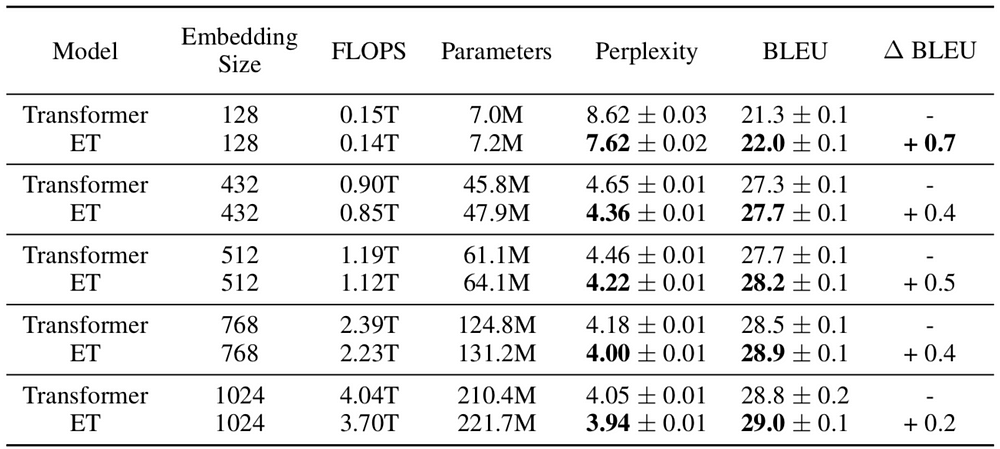
Comparison of Transformer and ET for different model sizes (according to embedding size). FLOPS represents the training duration of the model. Source: ET
Implementation details
As mentioned, the search algorithm required used over 200 Google’s TPUs in order to train thousands of models in a reasonable time. The training of the final ET model itself is faster than the original Transformer but still takes hours with a single TPU on the WMT’14 En-De dataset.
The code is open-source and is available for Tensorflow here.
Conclusion
Evolved Transformer shows the potential of combining hand-crafted with neural search algorithms to create architectures that are consistently better and faster to train. As computing resources are still limited (even for Google), researchers still need to carefully design the search space and improve the search algorithms to outperform human-designed models. However, this trend will undoubtedly just grow stronger over time.
To stay updated with the latest Deep Learning research, subscribe to my newsletter on LyrnAI
Appendix A - Tournament Selection Algorithm
The paper is based on the tournament selection algorithm from Real et al.except for the aging process of discarding the oldest models from the population:

(转)The Evolved Transformer - Enhancing Transformer with Neural Architecture Search的更多相关文章
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- (转)Illustrated: Efficient Neural Architecture Search ---Guide on macro and micro search strategies in ENAS
Illustrated: Efficient Neural Architecture Search --- Guide on macro and micro search strategies in ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
摘要 神经网络在多个领域都取得了不错的成绩,但是神经网络的合理设计却是比较困难的.在本篇论文中,作者使用 递归网络去省城神经网络的模型描述,并且使用 增强学习训练RNN,以使得生成得到的模型在验证集上 ...
- 小米造最强超分辨率算法 | Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search
本篇是基于 NAS 的图像超分辨率的文章,知名学术性自媒体 Paperweekly 在该文公布后迅速跟进,发表分析称「属于目前很火的 AutoML / Neural Architecture Sear ...
- Research Guide for Neural Architecture Search
Research Guide for Neural Architecture Search 2019-09-19 09:29:04 This blog is from: https://heartbe ...
- Neural Architecture Search — Limitations and Extensions
Neural Architecture Search — Limitations and Extensions 2019-09-16 07:46:09 This blog is from: https ...
随机推荐
- SQL行转列与列转行(转)
原文: http://blog.csdn.net/jx_870915876/article/details/52403472 add by zhj: 本文是以MySQL为例说明的,但其实它适用于所有关 ...
- linux上查询网卡型号
- csrf jsonp
网站b中包含向网站a发送的请求,那么网站b就会获得网站a的cookie,网站a登录了则网站b的cookie中会有网站a的sessionid,此时如果网站a对外提供需要sessionid的jsonp接口 ...
- Django系统
#Django系统 -环境 - python3.6 - django1.8 -参考资料 - [django中文教程](http://python.usyiyi.cn) - django架站的16堂课 ...
- #学号 20175201张驰 《Java程序设计》第2周学习总结
教材学习内容总结: 一.第二章: 1:标识符与关键字 2:基本数据类型:四种整数类型(byte.short.int.long).两种浮点数类型(float.double).一种字符类型(char).一 ...
- 10个用于处理日期和时间的 Python 库
Python本身提供了处理时间日期的功能,也就是datetime标准库.除此之外,还有很多优秀的第三方库可以用来转换日期格式,格式化,时区转化等等.今天就给大家分享10个这样的Python库. 上期入 ...
- C#、winform、wpf将类控件放进工具箱里
有时我们需要将vs自带的控件的某一些方法或属性进行一些修改,我们通常会新建一个类来继承它然后对它的方法或属性进行修改,那么我们如何将修改完成的控件类变成可视化控件放到工具箱中便于使用呢? 很简单,只要 ...
- mutex,thread
//#include <stdio.h> //#include <stdlib.h> //#include <unistd.h> #include <wind ...
- 关于动态添加iview admin路由以及刷新侧边栏
在main.js中的mounted中使用router.addRouters()方法后界面上的路由并未刷新. 在注释掉路由跳转的权限限制之后,发现直接在地址栏输入对应路由能够进去,只是侧边栏没有刷新. ...
- 关于webpack官网的学习
webpack,从名词上,"web pack",大概可以看出是一个网页打包工具,其实它具有打包.压缩.解析编译的功能. 使用(配置webpack.config.js) entry: ...