[Kafka] [All about it]
Overview
- 设计目标:
- 以O(1) 常数级时间复杂度的访问性能,提供消息持久化能力。
- 高吞吐率。
- 支持 kafka server 间的消息分区,及分布式消费,同时保证每个partition内部的消息顺序传输。
- scale out:支持在线水平扩展。
- 为何使用消息系统:
- 解耦
- 冗余(持久化)
- 扩展性
- 顺序保证
- 缓冲
- 异步通信
- 常用message queue对比
- RabbitMQ: 重量级
- redis:基于 k-v 对的NoSQL数据库,但本身支持MQ功能,可以作为一个轻量级的队列服务使用。
发布订阅
- 拓扑:推拉结合。
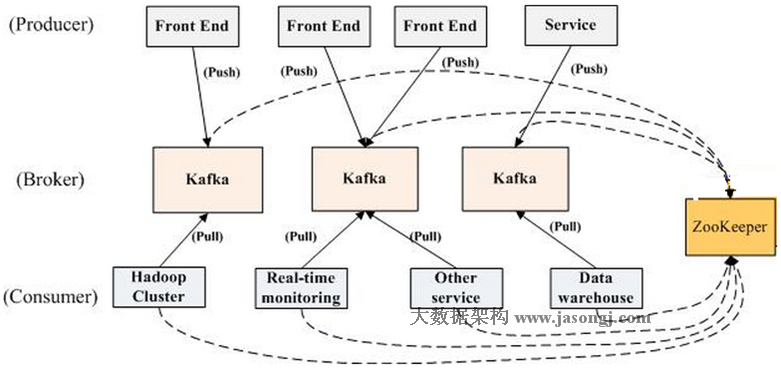
Zookeeper
常数级访问性能
- ref2
kafka文件存储机制
- 一个partition为一个文件夹
- segment
- segment的意义:把topic中一个大文件分成多个小文件段,就容易定期清除已消费完的文件。
- partition内部segment为一个个文件,segment命令方式为在文件后加上上一个segment的最后offset值。
- 物理结构上,一个segment file由两大部分组成,分别为index file和data file,这两个文件一一对应。
- index索引文件: 存储 "offset --> 物理偏移"。index文件采用的是稀疏存储的方式,每隔一定字节的数据建立一条索引,从而避免索引文件占用过多的空间,从而可以将索引保留在内存中。不过没有索引的数据间隔中还需要一次顺序扫描,不过范围很小。
- log数据文件

- 而每条消息长这样

- 如何在partition中通过offset查找message
- 查找segment file:根据offset二分查找,可快速定位到具体文件
- 通过segment file查找message
高吞吐率
- 每一条消息都是被append到partiton中,属于顺序写磁盘,因此效率非常高。
- 基于partition,producer会根据partition机制选择将其存储到哪一个partition,不同的消息可以并行写入不同partition。
Delivery Guarantee
- consumer端:consumer在从broker读取消息后,可以选择commit,该操作会在zk中保存该partition中读取消息的offset。可以设置为auto commit。
- 可以看到,这一过程中,数据处理与commit的顺序会决定消息从broker到consumer的delivery guarantee semantic。
- 读完消息先commit再处理:如果commit之后还未处理时consumer crash,就属于At most once。
- 处理完消息再commit: 如果处理完之后crash,就属于At least once。
- 可以看到,这一过程中,数据处理与commit的顺序会决定消息从broker到consumer的delivery guarantee semantic。
- kafka's guarantees are stronger in 3 ways:
- Idempotent producer
- Transactions
- Exactly-once stream processing
Idempotent producer
- 由于producer重发数据造成的duplicates:在kafka 0.11.0 后基于producer 幂等性解决。解决方案是:Producer ID + <topic, partition> 作为一个类似主键的东西解决。
- 实现方式:类似于TCP,发送到kafka的每批消息将包含一个序列号,该序列号用于重复数据的删除。与TCP不同的是,TCP只能在transient in-memory中提供保证。而序列号将被持久化存储到topic中,因此即使leader replica失败,接管的任何其他broker也能感知到消息是否重复。而且这种机制开销相当低,只需在每批消息中添加几个额外的字段。
- 优点:
- works transparently -- only one config change
- sequence numbers and producer ids are in the log
- resilient to broker failuers, producer retries, etc.
- 开销低,只需在每批消息中添加几个额外的字段。
Transactions
- Atomic writes across partitions
- 在一个事务内的消息要么全部可见,要么全都不可见。
- consumers必须被配置成,可跳过未提交的消息。
- transaction api
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch(ProducerFencedException e) {
producer.close();
} catch(KafkaException e) {
producer.abortTransaction();
} - producers需要使用新的producer API for transactions。
- consumers需要能够过滤掉 uncommited or aborted transactional messages。
Exactly-once stream processing
- Exactly-once stream processing across read-process-write tasks.
- 基于producer幂等性 和 事务原子性,通过Streams API实现 exactly-once 流处理成为可能。
+ Spark Streaming
- kafka + spark streaming 的应用场景非常常见。
- 整个系统对exactly once的保证,从来都不是靠系统中某一部分来实现就能搞定的,需要整个流式系统共同努力。
- spark streaming部分的exactly once的实现:使用WAL实现(注意不是checkpoint和replication,这两者是failover机制,不是专门解决exactly once的)。
- 输出操作对exactly once的实现:需要输出结果保证幂等性 or 提供事务支持。参见官方文档:
- In order to achieve exactly-once semantics for output of your results, your output operation that saves the data to an external data store must be either idempotent, or an atomic transaction that saves results and offsets(See Semantics of output operations in the main programming guide for further information).
- Exactly-once with Idempotent writes:
- 如果多次写产生的数据一样,那么这个输出操作就是幂等的。比如saveAsTextFile就是一个典型的幂等的更新。比如messages with unique keys can be written to database without duplication.
- 实现:
- set enable.auto.commit = false。缺省情况下,kafka DStream将会在收到数据后马上commit the consumer offsets。我们希望推迟这个操作直到the batch被完全处理掉。(这样可以实现at least once)
- 打开spark streaming的checkpointing来存储kafka offsets。但是如果应用程序代码改变了,checkpointed data是不可重用的,因此有second option如下:
- commit kafka offsets after outputs。kafka提供一个 commitAsync API,以及 HasOffsetRanges 类也可以被用来从initialRDD中提取offsets。
messages.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreachPartition { iter =>
// output to database
}
messages.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
- Exactly-once with transactional writes:
- transactional updates 需要一个unique identifier,我们可以使用batch time,partition id or kafka offsets来当做identifier,然后把结果 along with identifier一起在同一个事务中写入external storage。
- 这个原子操作可以提供exactly-once语义。如果offsets更新失败,或者通过 offset != $fromOffset 检测到duplicate offset,那么整个事务就会rollback,这也就包含智能了exactly-once语义。
- SS提供了三种storing offsets的方法,如下三种方法按顺序reliability是递增的,但同时code complexity也是递增的。
- checkpoints
- 缺点:
- output operation必须是幂等的,不然会有repeated outputs。
- 如果你的程序代码更改过,那么就无法从checkpoint处recover。 [这里的原因是:checkpointing刷到外部存储的是类Checkpoint对象序列化后的数据。那么在Spark Streaming Application重新编译后,再去反序列化checkpointing的数据就会失败。这个时候就必须新建SparkContext。]
- 缺点:
- kafka itself:kafka有一个offset commit API 用来存储offsets。缺省情况下,the new consumers会周期性地auto-commit offsets。但是很明显,你pull过来的数据不一定来得及被你消费,就会resulting in undefined semantics。
- 因此,我们可以使用 commitAsync API,来确保处理完数据之后再commit。
- 缺点:kafka is not transactional,因此你的输出仍然需要幂等。
- Your own data store
- 对于支持事务的data store,我们可以在同一个事务中保存offsets和results,从而保证两者in sync,即使是在failure的情况下。
- 如果你仔细地检查repeated or skipped offset ranges,那么就可以通过回滚事务来防止重复or丢失数据。这就保证了exactly-once
- checkpoints
- Spark streaming failover的实现,主要三种方式:
- checkpoint:在driver实现,用于在driver崩溃后,恢复driver的现场。
- replication:在receiver中用于解决单台executor挂掉后,未保存的数据丢失的问题。
- WAL:在driver和receiver中实现,用于解决:
- driver挂掉,所有executor都会挂掉,那么所有未保存的数据都会丢失,replication就不管用了
- driver挂掉后,哪些block在挂掉前注册到了driver中,以及挂掉前哪些block分配给了当前正在运行的batch job,这些信息就都丢失了。所以需要WAL对这些信息做持久化
- Conlusion:exactly-once在stream processing中是一个很强的语义,它会不可避免地给你的程序带来一些开销,影响吞吐量。而且不适用于windowed operations。
Kafka HA
- 多replica
- 数据一致性:
- 只有leader直接与producer & consumer交互,其他replica作为follower从leader复制数据。(这也减少了保证数据一致性的工作,否则需要保证replica之间有N*N条数据通路进行数据同步)。
- in-sync replica(ISR): leader所追踪的与其保持同步的replica列表。如果一个follower宕机(通过与zk之间的session来判定)or落后太多(可配置的条数),leader将其从ISR中移除。
- 复制机制:kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。
- 同步复制:要求所有能工作的follower都复制完,该消息才会commit,极大地影响了吞吐率。
- 异步复制:只要被leader写入log就认为已被commit,如果leader宕机就会丢失数据。
- 这也引出了问题:
- 如何propagate消息
- producer首先通过zk找到该partition的leader
- producer将消息发送给该partition的leader
- leader将消息写入本地log
- 每个follower都从leader pull数据
- follower收到消息(并写入log后),向leader发ack。(为了提高性能,每个follower在接收到数据后便ack,因此对已经commit的消息,只能保证已被存于多个replica的内存中。显然,这是为了性能做了一定牺牲的。)
- 一旦leader收到所有replica的ack,该消息就被认为已经commit了,leader将增加HW并向producer发送ack。(这里有一个问题是leader需要收到多少个follower的ack就向producer返回ack,如下)
- 在向producer发送ACK之前需要保证多少个replica已经收到该消息
- 怎样处理某个replica不工作的情况
- 怎样处理failed replica恢复回来的情况
- 如何propagate消息
- leader selection
这部分的难点就在于,因为follower可能落后许多或者crash了,所以必须确保选择"最新"的follower作为新的leader。基本的原则就是新的leader必须拥有原来的leader commit过的所有消息- 一个常用的leader selection方式是"Majority Vote"
- 如果有 2f + 1 个replica,那么在commit之前必须保证有f + 1 个replica复制完消息。为了保证正确的选出新的leader,fail的replica不能超过f个。
- 劣势:所容忍的fail的follower个数比较少。(e.g: 如果要容忍1个follower挂掉,必须要有5个以上的replica)。
- 其他常用的leader selection算法包括:zk的ZAB,Raft和Viewstamped Replication
- kafka采用的算法:在zk中动态维护了一个ISR,该ISR里的所有replica都跟上了leader,只有其内的成员才有被选为leader的可能。
- 一个常用的leader selection方式是"Majority Vote"
- 如何分配replica:
- 要求:
- load balance
- 容错能力:replica不能都在一个机器上
- 分配replica算法:
- 将broker(共n个)和待分配的partition排序
- 将第i个partition分配到第 (i mod n) 个broker上
- 将第i个partition的第j个replica分配到第 (i + j) mod n 个broker上
- 要求:
- 数据一致性:
- broker failover
- controller在zk的 /brokers/ids 节点上注册watch。 (一旦broker宕机,zk对于的znode会自动被删除:ephemeral node,zk会fire controller注册的watch,controller即可获取最新的幸存的Broker列表)
- controller决定set_p,该集合包含了宕机的所有broker上的所有partition。
- 对set_p中的每一个partition:
- 从 /brokers/topics/[topic]/partitions/[partition]/state 读取该Partition当前的ISR。
- 决定该partition的新leader。若当前ISR中至少有一个replica还幸存,则选择其中一个作为新的leader,新的ISR则包含当前ISR中所有幸存的replica。否则选择该partition中任意一个幸存的replica作为新leader以及ISR(显然,该场景下可能会有潜在的数据丢失)。
- 将新的leader,ISR和新的 leader_epoch 及 controller_epoch 写入 /brokers/topics/[topic]/partitions/[partition]/state。
- 直接通过RPC向set_p相关的Broker发送 LeaderAndISRRequest 命令。controller可以在一个RPC操作中发送多个命令从而提高效率。
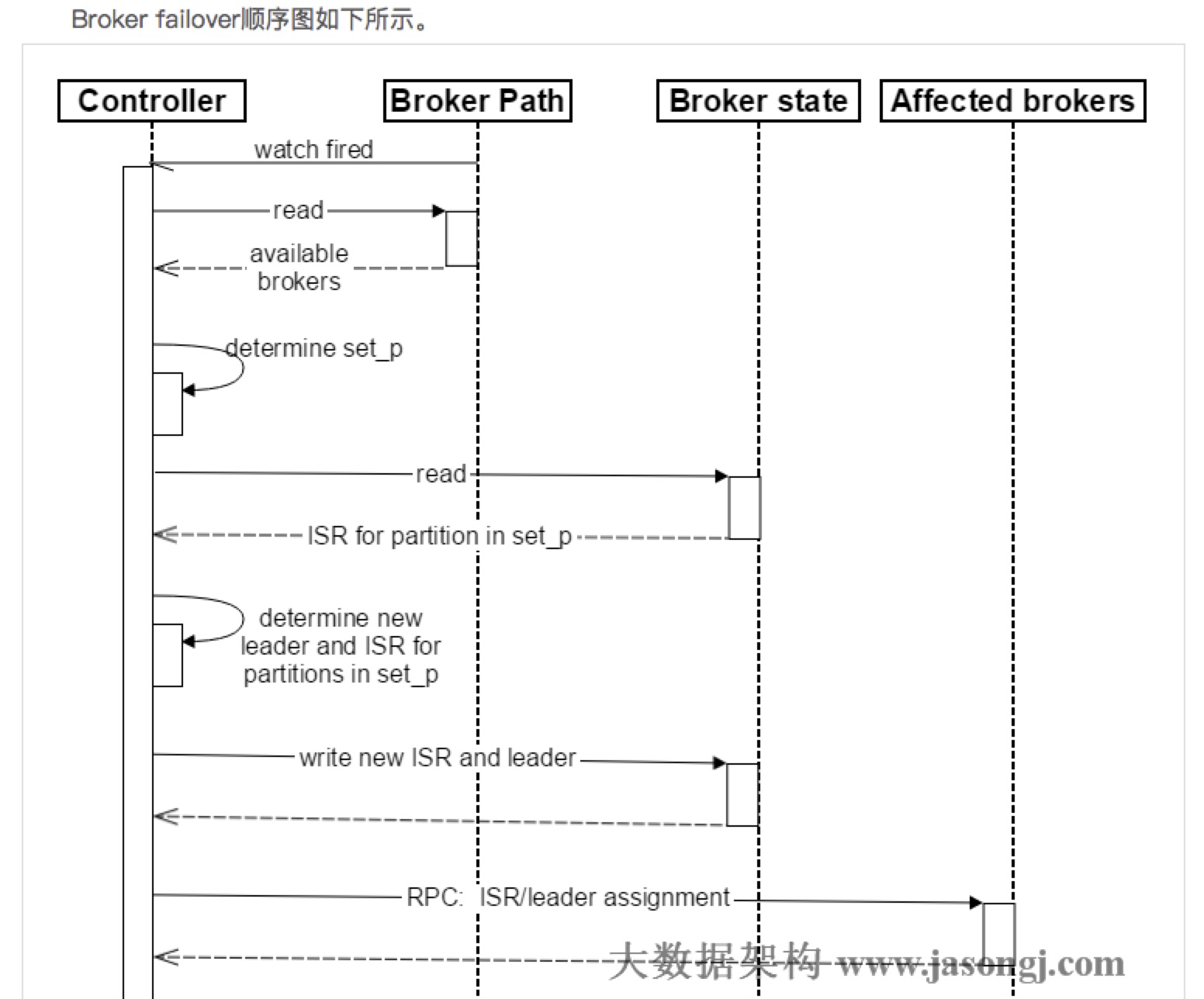
- 由于上述controller的引入,因此也需要 Controller Failover:
- 每个broker都会在controller path (/controller) 上注册一个watch。当前controller失败时,watch被fire,所有alive的broker都会去竞选成为新的controller,由zk保证只有一个竞选成功。
Consumer Design
High level consumer
- 适用于client只希望从kafka读取数据,不太关心消息offset的处理。
- High level consumer将从某个partition读取的最后一条消息的offset存于zk中(kafka从0.8.2版本开始同时支持将offset存于zk中,与将offset存于专用的kafka topic中)。
- 这个offset基于client提供的 consumer group 来保存。
- 注意,consumer group是整个kafka集群共享的,而非某个topic的。
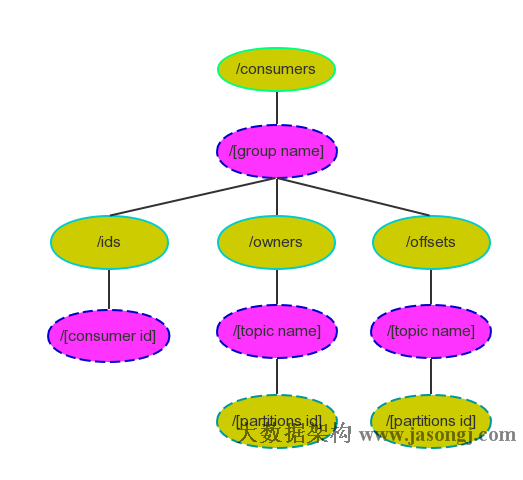
- 在consumer group内部,某个partition的数据只会被某一个特定的consumer实例所消费。每个consumer实例可以消费一个或多个特定partition的数据。
- 劣势:无法保证同一个consumer group里的consumer均匀消费数据。
- 优势:1. 每个consumer不用跟大量的broker通信,减少通信开销,同时降低了分配难度,实现也更简单。 2. 另外,每个partition内部数据是有序的,这种设计可以保持有序消费。
- consumer rebalance:
- 算法:
- 将目标topic下的所有partition排序,存于Pt
- 对某个consumer group下所有的consumer排序,存于Cg,第i个consumer记为Ci
- N = size(Pt) / size(Cg),向上取整
- 解除Ci对原来分配的partition的消费权
- 将第 i * N 到 i * (i + 1) * N - 1 个partition分配给Ci
- 实现:是由每一个consumer通过在zk上注册watch完成的。每个consumer被创建时会触发consumer group的rebalance。
- 算法:
Low Level Consumer
- 适合于用户希望更好的控制数据消费的场景,比如:
- 同一条消息读多次
- 只读取某个topic的部分partition
- 管理事务,从而确保每条消息被处理且仅被处理一次。
- low level consumer所需要的额外工作:
- 必须在应用程序中追踪offset,从而确定下一条应该消费哪条数据
- 应用程序需要通过程序获知每个partition的leader是谁
- 必须处理leader的变化
- 一般的使用流程:
- 查找一个alive broker,并且找出每个partition的leader
- 找出每个partition的follower
- 定义好请求,该请求应该能描述应用程序需要哪些数据
- fetch数据
- 识别leader变化,并对之做出必要的响应
高性能
宏观架构层面
- 利用partition实现并行处理。
- 组织架构:topic只是一个逻辑概念,每个topic都包含一个或多个partiiton,不同partition可位于不同节点。同时partition在物理上对应一个本地文件夹,每个partition包含一个or多个segment,每个segment包含一个数据文件和一个与之对应的索引文件。在逻辑上,可以把一个partition当做一个非常长的数组,可通过这个数组的索引(offset)去访问其数据。
- 关于并行:
- 一方面,由于不同的partition可位于不同的机器,因此可以充分利用集群优势,实现机器间的并行处理。
- 另一方面,由于partition在物理上对应一个文件夹,即使多个partition位于同一个节点,也可以通过配置让同一个节点的不同partition置于不同的disk driver上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
- partition是最小并发粒度
- ISR实现可用性与数据一致性的动态平衡:考虑CAP理论。
- 常见数据复制及一致性方案:
- Master-slave:
- RDBMS的读写分离即为典型的master-slave方案
- 同步复制可保证强一致性但会影响可用性
- 异步复制可提供高可用但会降低一致性
- WNR
- 主要用于去中心化的分布式系统中。
- N代表副本总数,W代表每次写操作要保证的最少写成功副本数,R代表每次读至少要读取的副本数。
- 当W + R > N 时,可保证每次读取的数据至少有一个副本拥有最新的数据
- 多个写操作的顺序难以保证,可能导致多副本间的写操作顺序不一致。
- Paxos及其变种
- Google的Chubby,zk的Zab,Raft等
- 基于ISR的数据复制方案 (kafka)
- 既非完全的同步复制,也不是完全的异步复制,而是基于ISR的动态复制方案
- ISR是由Leader动态维护的。如果follower不能紧跟上leader,它将被leader从ISR中移除,直到重新跟上后再次被加入ISR。
- ISR会在每次改变时持久化到zk中。
- 如何判断是否跟上?
- 对0.8.*版本,如果follower在 replica.lag.time.max.ms 时间内未向leader发送fetch请求,则会被移除。而即使某follower持续向leader发送fetch请求,follower与leader的数据差距在replcia.lag.max.messages以上,也会被移除。
- 从0.9.0.0开始,replcia.lag.max.messages被移除。同时leader会考虑follower是否在时间内与之保持一致。
- 使用ISR的原因:
- 与同步复制相比,可避免最慢的follower拖慢整体速度,提高了系统可用性
- ISR中所有的follower都包含了所有commit过的消息,而只有Commit过的消息才会被consumer消费,故从consume扔的角度而言,ISR中的所有replica都始终处于同步状态,从而与异步复制方案相比提高了数据一致性。
- ISR可动态调整,极限情况下,可以只包含leader,极大提高了可容忍的宕机的follower个数。
- Master-slave:
- 常见数据复制及一致性方案:
具体实现层面
- 高效使用磁盘:顺序写磁盘。
- 设计上,partition相当于一个非常长的数组,consumer通过offset顺序消费这些数据,并且不删除已经消费的数据。
- 删除过程,并非使用"读-写"模式去修改文件,而是将partition分为多个segment,每个segment对应一个物理文件,通过删除整个文件的方式去删除partition内的数据。
- 充分使用Page Cache
- 好处如下
- I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能
- I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
- 充分利用所有空闲内存(非JVM内存)。如果使用应用层Cache(即JVM堆内存),会增加GC负担
- 读操作可直接在Page Cache内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过Page Cache)交换数据
- 如果进程重启,JVM内的Cache会失效,但Page Cache仍然可用
- 好处如下
- 支持多disk drive
- broker的 log.dirs 配置项,允许配置多个文件夹。如果机器上有多个disk drive,可将不同的disk挂载到不同目录。
- 零拷贝
- kafka中存在大量的网络数据持久化到磁盘 和 磁盘文件通过网络发送的过程。这一过程的性能直接影响kafka的整体吞吐量。
- 减少网络开销
Reference
[Kafka] [All about it]的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- 消息队列 Kafka 的基本知识及 .NET Core 客户端
前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是因为要配合其他 java 项目中,所以就对 Kafka 了解了一下,也算是做个笔记吧. 本篇不谈论 Kafka 和其他的一些消息 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- .net windows Kafka 安装与使用入门(入门笔记)
完整解决方案请参考: Setting Up and Running Apache Kafka on Windows OS 在环境搭建过程中遇到两个问题,在这里先列出来,以方便查询: 1. \Jav ...
- kafka配置与使用实例
kafka作为消息队列,在与netty.多线程配合使用时,可以达到高效的消息队列
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
- Kafka副本管理—— 为何去掉replica.lag.max.messages参数
今天查看Kafka 0.10.0的官方文档,发现了这样一句话:Configuration parameter replica.lag.max.messages was removed. Partiti ...
- Kafka:主要参数详解(转)
原文地址:http://kafka.apache.org/documentation.html ############################# System ############### ...
- kafka
2016-11-13 20:48:43 简单说明什么是kafka? Apache kafka是消息中间件的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息 ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
随机推荐
- Redis 持久化RDB 和AOF
一.持久化之全量写入:RDB rdb配置 [redis@6381]$ more redis.conf save 900 1 save 300 10 save 60 10000 dbfilename & ...
- Oracle创建表、修改字段类型
1.创建表 1.创建表 create table SCM_PER( --SCM_PER表名 ID ) primary key,--主键ID USERID ),--用户ID --Permission v ...
- 关于Oracle单行函数的讲解
单行函数:对单个数值进行操作,并返回一个值. 分类:1.字符函数 1)concat(a,b) 拼接a,b两个字符串数据 2)initcap(x) 将每个单词x首字母大写 3)low ...
- 浅谈前端nuxt(ssr)
SSR: 服务端渲染(Server Side Render),即:网页是通过服务端渲染生成后输出给客户端. 一.那为什么要使用SSR呢? 我用一句话理解的就是降低SPA(Single Page App ...
- springcloud-zuul路由网关
路由网关(zuul) 在微服务架构中,需要多个基础的服务治理组件,包括服务注册与发现.服务消费.负载均衡.断路器.智能 路由.配置管理等,由这个基础组件相互协作,共同组建了一个简单的微服务系统.一个简 ...
- vue中$refs的使用
vue中$refs获取组件或元素: 获取的元素就相当于是一个原生获取的元素,可以进行操作 this.$refs.ele.style.color = 'red
- Jenkins自动构建gitlab项目(jenkins+maven+giltlab+tomcat)
环境准备: System:CentOS 7.3 (最小化安装) JDK: 8u161 (1.8_161) tomcat: 8.5.29 Jenkins: Jenkins 2.107.1 Gitlab: ...
- centos升级openssl方法及步骤
1.下载要升级到的openssl包https://cdn.openbsd.org/pub/OpenBSD/OpenSSH/portable/openssh-7.4p1.tar.gz 2.升级opens ...
- asp.netajax与jquery和bootstrap的无刷新完美实现
20190421asp.netajax与jquery和bootstrap的无刷新完美实现 设计代码和后台代码中重要部分加粗和深色以及字号加大. 设计前台代码: <%@ Page Title=&q ...
- lr12脚本参数化
1.注册.登录.获取商品列表lr脚本 Action() { lr_save_string("192.168.46.129:8080","IP"); ...