07--STL序列容器(Array)
一:Array了解
array<T,N> 模板定义了一种相当于标准数组的容器类型。
它是一个有 N 个 T 类型元素的固定序列。除了需要指定元素的类型和个数之外,它和常规数组没有太大的差别。
模板实例的元素被内部存储在标准数组中。
和标准数组相比,array 容器的额外幵销很小,---->比标准数组还是大一些
但提供了两个优点:
1.std::array除了有传统数组支持随机访问、效率高、存储大小固定等特点外,还支持迭代器访问、获取容量、获得原始指针等高级功能。
而且它还不会退化成指针T *给开发人员造成困惑。
2.如果使用 at(),当用一个非法的索引访问数组元素时,能够被检测到,因为容器知道它有多少个元素,
这也就意味着数组容器可以作为参数传给函数,而不再需要单独去指定数组元素的个数。
注意:
其中的元素是一个有序的集合 允许随机访问 其迭代器属于随机迭代器 其size()的结果总等于N 不支持分配器 //像vector,deque动态分配空间是需要分配器来实现的 是唯一一个无任何东西被指定为初值时,会被预初始化的容器,这意味着对于基础类型初值可能不明确 class array<> 是一个聚合体(不带用户提供的构造函数,没有private和protected的nonstatic数据成员,没有base类,有没有virtual 函数),
这意味着保存所有元素的那个成员是public,然而C++并没有指定其名称,因此对该public成员的任何直接访问都会导致不可预期的行为,也绝对不可移植。
二:array构造
array<Elem,N> c //默认构造函数; 创建一个默认初始化的数组 array<Elem,N> c(c2) //复制构造函数; 创建另一个与c2同型的vector副本(所有元素都被复制) array<Elem,N> c = c2 //复制构造函数; 创建另一个与c2同型的vector副本(所有元素都被复制) array<Elem,N> c(rv) //移动构造函数; 拿走右值rv的元素创建一个新的数组 array<Elem,N> c = rv //移动构造函数; 拿走右值rv的元素创建一个新的数组 array<Elem,N> c = initlist //使用初始化列表创建一个初始化的数组
三:array元素存取
c[idx] //返回索引idx所标示的元素,不进行范围检查 c.at(idx) //返回索引idx所标示的元素,如果越界,抛出range-error c.front() //返回第一个元素,不检查第一个元素是否存在 c.back() //返回最后一个元素,不检查最后一个元素是否存在
四:array赋值操作
c = c2 //将c2所有元素赋值给c c = rv //将右值对象rv的所有元素移动赋值给c c.fill(val) //将val赋值给数组c里的每个元素 c1.swap(c2) //交换c1和c2的数 swap(c1,c2) //交换c1和c2的数
如果使用=操作符或者swap(),两个array必须具备相同类型,即元素类型和大小必须相同。
五:迭代相关函数
c.begin() //返回一个随机存取迭代器,指向第一个元素 c.end() //返回一个随机存取迭代器,指向最后一个元素 c.cbegin() //返回一个随机存取常迭代器,指向第一个元素 c.cend() //返回一个随机存取常迭代器,指向最后一个元素 c.rbegin() //返回一个逆向迭代器,指向逆向迭代的第一个元素 c.rend() //返回一个逆向迭代器,指向逆向迭代的最后一个元素 c.crbegin() //返回一个逆向常迭代器,指向逆向迭代的第一个元素 c.crend() //返回一个逆向常迭代器,指向逆向迭代的最后一个元素
array<int, > arr = {,,,,,}; //默认补全0
for (array<int, >::iterator iter = arr.begin(); iter != arr.end(); iter++)
{
cout << *iter << " ";
}
六:性能测试
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <stdio.h>
#include <cstring> #if _MSC_VER
#define snprintf _snprintf
#endif using namespace std; long get_a_target_long()
{
/******变量声明********/
long target = ;
/**********************/ cout << "targer (0~" << RAND_MAX << "):";
cin >> target;
return target;
} string get_a_target_string()
{
/******变量声明********/
long target = ;
char buf[];
/**********************/ cout << "targer (0~" << RAND_MAX << "):";
cin >> target; snprintf(buf, , "%d", target);
return string(buf);
} //与后面的比较函数中回调参数对应
int compareLongs(const void* l1, const void* l2)
{
return (*(long*)l1 - *(long*)l2);
} int compareStrings(const void* s1, const void* s2)
{
if (*(string*)s1 > *(string*)s2)
return ;
if (*(string*)s1 < *(string*)s2)
return -;
return ;
}
公共函数
/************************************************************************/
/*测试数组 */
/************************************************************************/
#include <array>
#include <iostream>
#include <algorithm>
#include <ctime>
#include <cstdlib> #define ASIZE 200000 //由于数组声明需要使用常量值,故在这里写死
//500000个long---4000000Byte---4M //数组Array测试
namespace jj01
{
void test_array()
{
cout << "\ntest_array()*******" << endl; /******变量声明:数组初始********/
array<long, ASIZE> arr; /******变量声明:记录时间********/
clock_t timeStart = clock(); //开始时间
for (long i = ; i < ASIZE; i++)
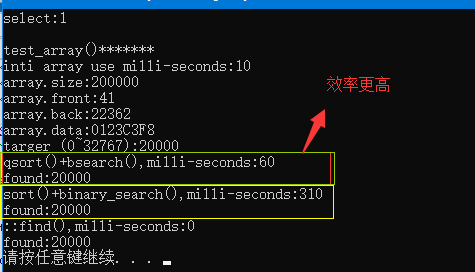
arr[i] = rand(); //0-32767,所以有重复 cout << "inti array use milli-seconds:" << (clock() - timeStart) << endl; //获取初始化数组耗时
cout << "array.size:" << arr.size() << endl; //获取数组大小
cout << "array.front:" << arr.front() << endl; //获取数组首元素
cout << "array.back:" << arr.back() << endl; //获取数组尾元素
cout << "array.data:" << arr.data() << endl; //获取数组首地址 /******变量声明:获取我们要查询的数********/
long target = get_a_target_long(); timeStart = clock(); //qsort和bsearch是C编译器自带的快速排序和二分查找算法
qsort(arr.data(), ASIZE, sizeof(long), compareLongs); /******变量声明:pItem是我们获取的返回的元素地址********/
long* pItem =
(long*)bsearch(&target, arr.data(), ASIZE, sizeof(long), compareLongs);
cout << "qsort()+bsearch(),milli-seconds:" << clock() - timeStart << endl;
if (pItem != NULL)
cout << "found:" << *pItem << endl;
else
cout << "not found!" << endl; random_shuffle(arr.begin(), arr.end()); //乱序 //STL排序查找算法
timeStart = clock(); sort(arr.begin(), arr.end());
/******变量声明:flag布尔型判断是否找到数据********/
bool flag =
binary_search(arr.begin(), arr.end(), target); cout << "sort()+binary_search(),milli-seconds:" << clock() - timeStart << endl;
if (flag != false)
cout << "found:" << *pItem << endl;
else
cout << "not found!" << endl; //使用find方法进行查找
timeStart = clock(); auto pI = find(arr.begin(), arr.end(), target); cout << "::find(),milli-seconds:" << clock() - timeStart << endl;
if (flag != false)
cout << "found:" << *pI << endl;
else
cout << "not found!" << endl;
}
}
07--STL序列容器(Array)的更多相关文章
- STL 序列容器
转自时习之 STL中大家最耳熟能详的可能就是容器,容器大致可以分为两类,序列型容器(SequenceContainer)和关联型容器(AssociativeContainer)这里介绍STL中的各种序 ...
- STL List容器
转载http://www.cnblogs.com/fangyukuan/archive/2010/09/21/1832364.html 各个容器有很多的相似性.先学好一个,其它的就好办了.先从基础开始 ...
- STL序列式容器学习总结
STL序列式容器学习总结 参考资料:<STL源码剖析> 参考网址: Vector: http://www.cnblogs.com/zhonghuasong/p/5975979.html L ...
- STL——序列式容器
一.容器概述与分类 1. STL容器即是将运用最广的一些数据结构实现出来.常用的数据结构有array, list, tree, stack, queue, hash table, set, map…… ...
- 《STL源码剖析》——第四章、序列容器
1.容器的概观与分类 所谓序列式容器,其中的元素都可序(ordered)[比如可以使用sort进行排序],但未必有序(sorted).C++语言本身提供了一个序列式容器array,STL另外再提供v ...
- STL常用序列容器
这里简要的记述一下STL常用容器的实现原理,要点等内容. vector vector是比较常用的stl容器,用法与数组是非类似,其内部实现是连续空间分配,与数组的不同之处在于可弹性增加空间,而arra ...
- STL基础--容器
容器种类 序列容器(数组,链表) Vector, deque, list, forward list, array 关联容器(二叉树),总是有序的 set, multiset根据值排序,元素值不能修改 ...
- [C++ STL] 各容器简单介绍
什么是STL? 1.STL(Standard Template Library),即标准模板库,是一个高效的C++程序库. 2.包含了诸多常用的基本数据结构和基本算法.为广大C++程序员们提供了一个可 ...
- 【Example】C++ STL 常用容器概述
前排提醒: 由于 Microsoft Docs 全是机翻.所以本文表格是我人脑补翻+审校. 如果有纰漏.模糊及时评论反馈. 序列式容器 序列容器是指在逻辑上以线性排列方式存储给定类型元素的容器. 这些 ...
- C++ STL vector容器学习
STL(Standard Template Library)标准模板库是C++最重要的组成部分,它提供了一组表示容器.迭代器.函数对象和算法的模板.其中容器是存储类型相同的数据的结构(如vector, ...
随机推荐
- springCloud feign使用/优化总结
基于springCloud Dalston.SR3版本 1.当接口参数是多个的时候 需要指定@RequestParam 中的value来明确一下. /** * 用户互扫 * @param uid 被扫 ...
- pyspider爬网页出现中文乱码的解决办法
为什么会出现乱码呢?按照binux的说法 这就是 lxml 的蛋疼之处,给它 unicode 它有的时候它不认,给它 bytes 它又处理不好 方法1: response.content = (res ...
- 十款 Chrome 扩展工具,提高前端编码效率
1. 掘金 Chrome 插件 对于开发者来说,比开发过程更重要的,应该要算平时对于开发资源以及技术文章一点一滴的积累了吧.那么,开发者能够在哪里获取需要的技术内容呢?过去,你可能需要在 GitHub ...
- JS倒计时两种种实现方式
最近做浏览器界面倒计时,用js就实现,两种方式: 一:设置时长,进行倒计时.比如考试时间等等 代码如下: <html> <head> <meta charset=&quo ...
- eclipse中使用Lombok(转)
原文链接:https://www.cnblogs.com/justuntil/p/7120534.html windows环境 1.下载lombok.jar包https://projectlombok ...
- 4.26 IO流
- kvm虚拟化
1.kvm虚拟化介绍 什么是虚拟化 虚拟化就是通过模拟计算机硬件(cpu,内存,硬盘,网卡)来实现在一台物理服务器上运行同时多个不同的操作系统,并且使每个操作系统之间都是互相隔离的 为什么要学习虚拟化 ...
- 通过 docker 搭建自用的 gitlab 服务
前言 git 是当下如日中天的版本管理系统.现在如果不是工作在 git 版本管理系统之下,几乎都不好意思和人打招呼了.有很多现成的互联网的 git 服务提供给大家使用,例如号称程序员社交网络的 Git ...
- MyCP.java蓝墨云班课
题目要求: 编写MyCP.java 实现类似Linux下cp XXX1 XXX2的功能,要求MyCP支持两个参数: java MyCP -tx XXX1.txt XXX2.bin 用来把文本文件(内容 ...
- 【深色模式】macOS Mojave+Visual Studio for Mac+FineUICore多图赏析!
全面开启深色模式,今早成功升级到 macOS Mojave,下面就来欣赏一下吧. 点击图片,查看大图 1. 下载 macOS Mojave 2. 安装成功,开启深色模式 3. 来一张桌面截图 4. 开 ...