prometheus 集群
思路一
统一区域的监控目标,prometheus server两台监控相同的目标群体。

改变后

上面这个变化对于监控目标端,会多出一倍的查询请求,但在一台prometheus server宕机的情况下,可以不影响监控。
思路二
这是一个金字塔式的层次结构,而不是分布式层次结构。Prometheus 的抓取请求也会加载到prometheus work节点上,这是需要考虑的。
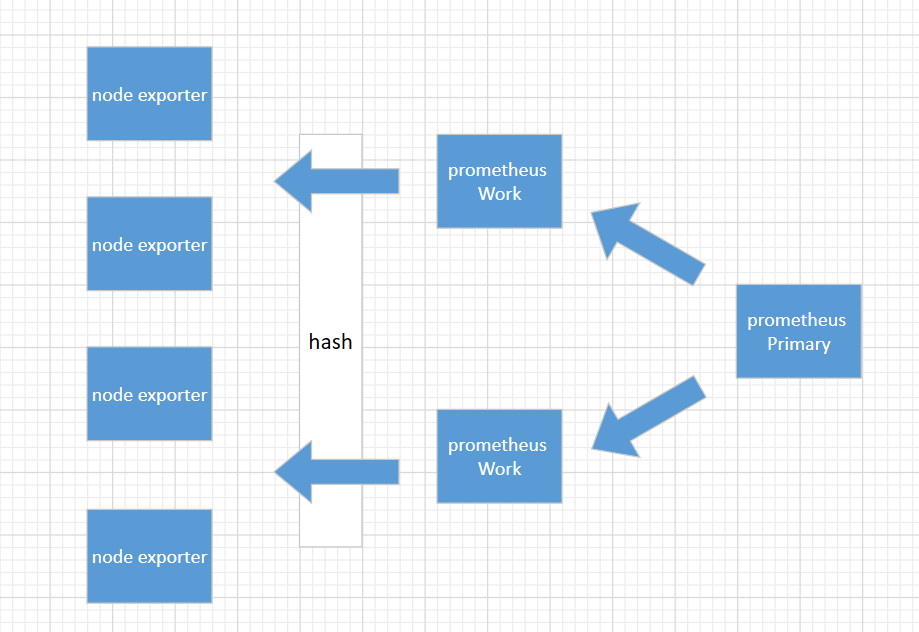
上面这种模式,准备3台prometheus server进行搭建,这种方式work节点一台宕机后,其它wokr节点不会去接手故障work节点的机器。
1、环境准备
192.168.31.151(primary)
192.168.31.144 (worker)
192.168.31.82(worker)
2、部署prometheus
cd /usr/loacl
tar -xvf prometheus-2.8.0.linux-amd64.tar.gz
ln -s /usr/local/prometheus-2.8.0.linux-amd64 /usr/local/prometheus
cd /usr/local/prometheus;mkdir bin conf data
mv ./promtool bin
mv ./prometheus bin
mv ./prometheus.yml conf
3、worker节点配置(192.168.31.144)
prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
external_labels:
worker: 0 # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*_rules.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets:
- 192.168.31.151:9090
- 192.168.31.144:9090
- 192.168.31.82:9090
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
- job_name: 'node_exporter'
file_sd_configs:
- files:
- targets/nodes/*.json
refresh_interval: 1m
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
- job_name: 'docker'
file_sd_configs:
- files:
- targets/docker/*.json
refresh_interval: 1m
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
- job_name: 'alertmanager'
static_configs:
- targets:
- 192.168.31.151:9093
- 192.168.31.144:9093
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
worker节点配置(192.168.31.82)
prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
external_labels:
worker: 1 # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*_rules.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets:
- 192.168.31.151:9090
- 192.168.31.144:9090
- 192.168.31.82:9090
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
- job_name: 'node_exporter'
file_sd_configs:
- files:
- targets/nodes/*.json
refresh_interval: 1m
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
- job_name: 'docker'
file_sd_configs:
- files:
- targets/docker/*.json
refresh_interval: 1m
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
- job_name: 'alertmanager'
static_configs:
- targets:
- 192.168.31.151:9093
- 192.168.31.144:9093
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
primary节点配置(192.168.31.151)
prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s). # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.31.151:9093
- 192.168.31.144:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*_alerts.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: 'node_workers'
file_sd_configs:
- files:
- 'targets/workers/*.json'
refresh_interval: 5m
honor_labels: true
metrics_path: /federate
params:
'match[]':
- '{__name__=~"^instance:.*"}'
cat ./targets/workers/workers.json
[{
"targets": [
"192.168.31.144:9090",
"192.168.31.82:9090"
]
}]
prometheus 集群的更多相关文章
- Prometheus集群介绍-1
Prometheus监控介绍 公司做教育的,要迁移上云,所以需要我这边从零开始调研加后期维护Prometheus:近期看过二本方面的prometheus书籍,一本是深入浅出一般是实战方向的:官方文档主 ...
- Thanos prometheus 集群以及多租户解决方案docker-compose 试用(一)
prometheus 是一个非常不多的metrics 监控解决方案,但是对于ha 以及多租户的处理并不是很好,当前有好多解决方案 cortex Thanos prometheus+ influxdb ...
- 部署prometheus监控kubernetes集群并存储到ceph
简介 Prometheus 最初是 SoundCloud 构建的开源系统监控和报警工具,是一个独立的开源项目,于2016年加入了 CNCF 基金会,作为继 Kubernetes 之后的第二个托管项目. ...
- 如何扩展单个Prometheus实现近万Kubernetes集群监控?
引言 TKE团队负责公有云,私有云场景下近万个集群,数百万核节点的运维管理工作.为了监控规模如此庞大的集群联邦,TKE团队在原生Prometheus的基础上进行了大量探索与改进,研发出一套可扩展,高可 ...
- 如何用Prometheus监控十万container的Kubernetes集群
概述 不久前,我们在文章<如何扩展单个Prometheus实现近万Kubernetes集群监控?>中详细介绍了TKE团队大规模Kubernetes联邦监控系统Kvass的演进过程,其中介绍 ...
- vivo 容器集群监控系统架构与实践
vivo 互联网服务器团队-YuanPeng 一.概述 从容器技术的推广以及 Kubernetes成为容器调度管理领域的事实标准开始,云原生的理念和技术架构体系逐渐在生产环境中得到了越来越广泛的应用实 ...
- 如何使用helm优雅安装prometheus-operator,并监控k8s集群微服务
前言:随着云原生概念盛行,对于容器.服务.节点以及集群的监控变得越来越重要.Prometheus 作为 Kubernetes 监控的事实标准,有着强大的功能和良好的生态.但是它不支持分布式,不支持数据 ...
- Kubernetes集群部署史上最详细(二)Prometheus监控Kubernetes集群
使用Prometheus监控Kubernetes集群 监控方面Grafana采用YUM安装通过服务形式运行,部署在Master上,而Prometheus则通过POD运行,Grafana通过使用Prom ...
- Prometheus监控elasticsearch集群(以elasticsearch-6.4.2版本为例)
部署elasticsearch集群,配置文件可"浓缩"为以下: cluster.name: es_cluster node.name: node1 path.data: /app/ ...
随机推荐
- Android 简单统计文本文件字符数、单词数、行数Demo
做的demo是统计文本文件的字符数.单词数.行数的,首先呢,我们必须要有一个文本文件.所以我们要么创建一个文本文件,并保存,然后再解析:要么就提前把文本文件先放到模拟器上,然后检索到文本名再进行解析. ...
- 回归算法比较(线性回归,Ridge回归,Lasso回归)
代码: # -*- coding: utf-8 -*- """ Created on Mon Jul 16 09:08:09 2018 @author: zhen &qu ...
- 安装Docker时错误提示 "could not change group /var/run/docker.sock to docker: group docker not found"的解决方案
安装Dock服务,主要命令是 yum install docker. 但是在启动的时候报错:warning msg="could not change group /var/run/doc ...
- 微软与开源干货对比篇_PHP和 ASP.NET在 Session实现和管理机制上差异
微软与开源干货对比篇_PHP和 ASP.NET在 Session实现和管理机制上差异 前言:由于开发人员要靠工具吃饭,可能和开发工具.语言.环境呆的时间比和老婆孩子亲人在一起的时间还多,所以每个人或多 ...
- TiDB 架构及设计实现
一. TiDB的核心特性 高度兼容 MySQL 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移. 水平弹性扩展 ...
- LeetCode算法题-Find Smallest Letter Greater Than Target(Java实现)
这是悦乐书的第306次更新,第326篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第175题(顺位题号是744).给定一个仅包含小写字母的有序字符数组,并给定目标字母目标 ...
- Ubuntu下搭建spark2.4环境(单机版)
说明:单机版的Spark的机器上只需要安装JDK即可,其他诸如Hadoop.Zookeeper(甚至是scala)之类的东西可以一概不安装.集群版搭建:Spark2.2集群部署和配置 一.安装JDK1 ...
- ValueError: too many values to unpack
Error msg: 执行: python manage,py makemigrations 报错:Value: too many values to unpack 问题: django第一次数据库迁 ...
- 菜鸟学python之程序初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2684 1.字符串操作: 解析身份证号:生日.性别.出生地等. def id ...
- [转帖]流程控制:for 循环
流程控制:for 循环 http://wiki.jikexueyuan.com/project/linux-command/chap34.html need more study need more ...