[Reinforcement Learning] 动态规划(Planning)
动态规划
动态规划(Dynamic Programming,简称DP)是一种通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
动态规划常常适用于具有如下性质的问题:
- 具有最优子结构(Optimal substructure)
- Principle of optimality applies
- Optimal solution can be decomposed into subproblems
- 重叠子问题(Overlapping subproblems)
- Subproblems recur many times
- Solutions can be cached and reused
动态规划方法所耗时间往往远少于朴素解法。
马尔可夫决策过程MDP满足上述两个性质:
- 贝尔曼方程提供了递归分解的结构;
- 价值函数可以保存和重复使用递归时的结果。
使用动态规划解决MDP/MRP
动态规划需要满足MDP过程是已知的(model-based)。
- For Predict:
- Input:MDP \(<S, A, P, R, \gamma>\) 和策略 $\pi $ 或者是 MRP \(<S, P, R, \gamma>\)
- Output:价值函数 \(v_{\pi}\)
- For Control:
- Input:MDP \(<S, A, P, R, \gamma>\)
- Output:最优价值函数 \(v_{*}\) 或者最优策略 \(\pi_{*}\)
策略评估
策略评估(Policy Evaluation)指的是计算给定策略的价值,解决的问题是 "How to evaluate a policy"。
策略评估的思路:迭代使用贝尔曼期望方程(关于 MDP 的贝尔曼期望方程形式见《马尔可夫决策过程》)。
策略评估过程如下图所示:
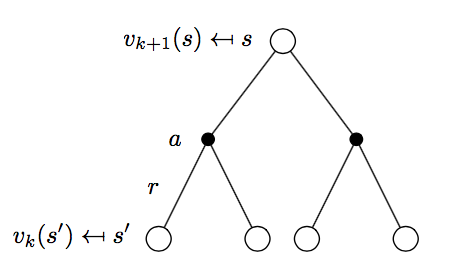
\[v_{k+1} = \sum_{a\in A}\pi(a|s) \Bigl( R_{s}^a + \gamma\sum_{s'\in S}P_{ss'}^a v_{k}(s') \Bigr)\]
使用向量形式表示:
\[\mathbf{v^{k+1}} = \mathbf{R^{\pi}} + \gamma \mathbf{P^{\pi}v^{k}}\]
策略迭代
策略迭代(Policy Iteration,简称PI)解决的问题是 "How to improve a policy"。
给定一个策略 \(\pi\):
- 评估策略 \(\pi\):
\[v_{\pi}(s) = E[R_{t+1} + \gamma R_{t+2} + ...| S_t = s]\] - 提升策略:通过采用贪婪方法来提升策略:
\[\pi ' = \text{greedy}(v_{\pi})\]
可以证明,策略迭代不断进行总是能收敛到最优策略,即 \(\pi ' = \pi^{*}\)。
策略迭代可以使用下图来形式化的描述:
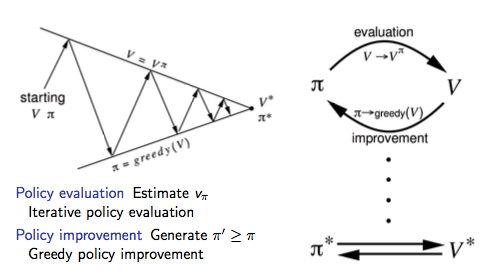
广义策略迭代
通过上述提到的策略评估我们不难发现,策略评估是一个不断迭代的过程:
\[v_{\pi}(s) = E[R_{t+1} + \gamma R_{t+2} + ...| S_t = s]\]
那么问题来了,Does policy evaluation need to converge to \(v_{\pi}\)?
我们是不是可以引入一个停止规则或者规定在迭代 \(k\) 次后停止策略评估?
再进一步想,我们为什么不在每次策略评估的迭代过程中进行策略提升(等同于策略评估迭代1次后停止)?
注:这和后续要介绍的值迭代等价。
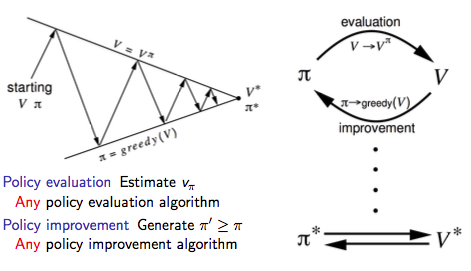
因此我们可以把上述策略迭代的过程一般化,即广义策略迭代(Generalised Policy Iteration,简称GPI)框架:
值迭代
介绍值迭代之前,我们先介绍下最优化原理。
最优化原理
最优化原理(Principle of Optimality)定义:
一个过程的最优决策具有这样的性质:即无论其初始状态和初始决策如何,其今后诸策略对以第一个决策所形成的状态作为初始状态的过程而言,必须构成最优策略。
最优化原理如果用数学化一点的语言来描述的话就是:
以状态 \(s\) 为起始点,策略 \(\pi(a|s)\) 可以得到最优值 \(v_{\pi}(s) = v_*(s)\) 当且仅当:
- 任意状态 \(s'\) 对于状态 \(s\) 均可达;
- 以状态 \(s'\) 为起始点,策略 \(\pi\) 可以得到最优值 \(v_{\pi}(s') = v_*(s')\)。
根据最优化原理可知,如果我们得到了子问题的解 $ v_*(s')$,那么以状态 \(s\) 为起始点的最优解 \(v_*(s)\) 可以通过一步回退(one-step lookahead)就能获取:
\[v_*(s) ← \max_{a\in A}\Bigl(R_s^a + \gamma \sum_{s'\in S}P_{ss'}^{a}v_*(s') \Bigr)\]
也就是说,我们可以从最后开始向前回退从而得到最优解,值迭代就是基于上述思想进行迭代更新的。
MDP值迭代
值迭代(Value Iteration,简称VI)解决的问题也是 "Find optimal policy $\pi $"。
但是不同于策略迭代使用贝尔曼期望方程的是,值迭代使用贝尔曼最优方程进行迭代提升。
值迭代与策略迭代不同的地方在于:
- Use Bellman optimal function, rather than Bellman expectation function
- Unlike policy iteration, there is no explicit policy
- Intermediate value functions may not correspond to any policy
如下图所示:
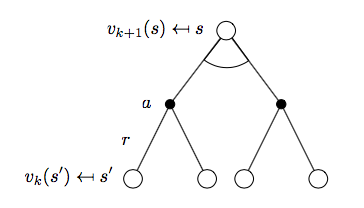
\[v_{k+1}(s) = \max_{a\in A}\Bigl(R_s^a + \gamma\sum_{s'\in S}P_{ss'}^a v_k(s') \Bigr)\]
对应的向量表示为:
\[\mathbf{v}_{k+1} = \max_{a\in A}\mathbf{R}^a + \gamma \mathbf{P^av}^k\]
下图为三种方法的总结:
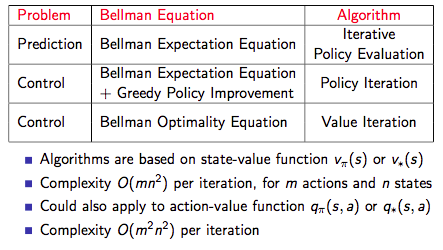
动态规划扩展
异步动态规划(Asynchronous Dynamic Programming)
- In-place dynamic programming
- Prioritised sweeping
- Real-time dynamic programming
Full-Width Backups vs. Sample Backups
Full-Width Backups
- DP uses full-width backups(DP is model-based)
- Every successor state and action is considered
- Using knowledge of the MDP transitions and reward function
- DP is effective for medium-sized problems (millions of states)
- For large problems, DP suffers Bellman’s curse of dimensionality(维度灾难)
维度灾难:Number of states \(n = |S|\) grows exponentially with number of state variables
- Even one backup can be too expensive
Sample Backups
后续将要讨论的时序差分方法
- Using sample rewards and sample transitions \(⟨S, A, R, S′⟩\)
- Instead of reward function R and transition dynamics P
- Advantages:
- Model-free: no advance knowledge of MDP required
- Breaks the curse of dimensionality through sampling
- Cost of backup is constant, independent of \(n = |S|\)
Reference
[1] 智库百科-最优化原理
[2] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto, 2018
[3] David Silver's Homepage
[Reinforcement Learning] 动态规划(Planning)的更多相关文章
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- 【论文阅读】PRM-RL Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
目录 摘要部分: I. Introduction II. Related Work III. Method **IMPORTANT PART A. RL agent training [第一步] B. ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- Learning Roadmap of Deep Reinforcement Learning
1. 知乎上关于DQN入门的系列文章 1.1 DQN 从入门到放弃 DQN 从入门到放弃1 DQN与增强学习 DQN 从入门到放弃2 增强学习与MDP DQN 从入门到放弃3 价值函数与Bellman ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 增强学习(Reinforcement Learning and Control)
增强学习(Reinforcement Learning and Control) [pdf版本]增强学习.pdf 在之前的讨论中,我们总是给定一个样本x,然后给或者不给label y.之后对样本进行 ...
- [Reinforcement Learning] Model-Free Control
上篇总结了 Model-Free Predict 问题及方法,本文内容介绍 Model-Free Control 方法,即 "Optimise the value function of a ...
- [Reinforcement Learning] Model-Free Prediction
上篇文章介绍了 Model-based 的通用方法--动态规划,本文内容介绍 Model-Free 情况下 Prediction 问题,即 "Estimate the value funct ...
随机推荐
- 免费了 -- EXCEL插件 智表ZCELL 普及版V1.0 发布了!!!
智表(zcell)是一款浏览器仿excel表格jquery插件.智表可以为你提供excel般的智能体验,支持双击编辑.设置公式.设置显示小数精度.下拉框.自定义单元格.复制粘贴.不连续选定.合并单元格 ...
- tensorflow 训练之tensorboard使用
1.add saclar and histogram tf.summary.scalar('mean', mean) tf.summary.histogram('histogram', var) 2. ...
- 看AppCan移动管理平台如何助力企业移动化
AppCan企业移动管理平台(EMM)是为企业移动化战略提供综合管理的平台产品.AppCan EM移动管理平台为企业提供对用户.应用.设备.内容.邮件的综合管理服务,并在此基础上为企业提供统一应用商店 ...
- 数据的存储方式:SQLiteOpenHelper的用法
Android为了让我们能够更加方便的的管理数据,专门提供了一个SQLiteOpenHelper类,它是一个抽象类,如果我们想要使用它,就需要创建一个自己帮助类去继承它,而且它有两个抽象的方法,分别是 ...
- docker企业实战视频教程
Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的.可移植的.自给自足的容器.开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署,包括VMs(虚拟机).bare metal. ...
- A Base Class pointer can point to a derived class object. Why is the vice-versa not true?
问题转载自:https://stackoverflow.com/questions/4937180/a-base-class-pointer-can-point-to-a-derived-class- ...
- 一、操作m'y's'ql
一.创建framework框架的控制台默认不支持mysql
- python的排序方式
""" 冒泡排序: 冒泡排序的思想: 每次比较两个相邻的元素, 如果他们的顺序错误就把他们交换位置 比如有五个数: 12, 35, 99, 18, 76, 从大到小排序, ...
- NOIP 2019游记
Update on 2019.4.20 禁赛预定
- laravel 【error】MethodNotAllowedHttpException No message
Symfony \ Component \ HttpKernel \ Exception \ MethodNotAllowedHttpException No message 报错原因[原理]CSRF ...