hadoop2-HBase的安装和测试
在安装和测试HBase之前,我们有必要先了解一下HBase是什么
我们可以通过下面的资料对其有一定的了解:
我想把我知道的分享给大家,方便大家交流。
以下是本文的大纲:
1.Hadoop集群环境搭建
2.Hbase的介绍
3.单机模式解压和安装HBase
3.1.创建t_student表
3.2.查看表t_student
3.3.查看表结构
3.4.插入数据
3.5.查询table
4.完全分布式模式解压和安装HBase
4.1.创建t_student表
4.2.插入数据
4.3.数据从内存写入到磁盘
4.4.再次插入数据
4.5.再次把数据写入到磁盘
4.6.手动合并文件
4.7.查看文件内容
若有不正之处,还请多多谅解,并希望批评指正。
请尊重作者劳动成果,转发请标明blog地址
https://www.cnblogs.com/hongten/p/hongten_hadoop_hbase.html
正所谓磨刀不费砍材功,下面的工具大家可以先下载备用。
环境及工具:
Windows 7 (64位)下面的虚拟机(64位):VMware-workstation-full-14.0.0-6661328.exe
Linux操作系统:CentOS-6.5-x86_64-bin-DVD1.iso
Xshell:Xshell-6.0.0101p.exe
WinSCP:从windows上面上传文件到Linux
zookeeper:zookeeper-3.4.6.tar.gz
hadoop:hadoop-2.5.1_x64.tar.gz
链接:https://pan.baidu.com/s/1hvdbGUh488Gl1EF2v44BIw
提取码:ncdd
Hbase: hbase-0.98.9-hadoop2-bin.tar.gz
1.Hadoop集群环境搭建
在做Hbase安装和测试之前,我们有必要把 Hadoop2集群环境搭建 好。
2.Hbase的介绍
Hadoop Database, 是一个高可靠性,高性能,面向列,可伸缩,实时读写的分布式数据库。
利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务
主要用来存储非结构化和半结构化的松散数据(列存NoSQL数据库) Column Family 列族 HBase表中的每个列都归属某个列族,列族必须作为表模式(schema)定义的一部分预先给出,如: create 'test', 'course';
列名以列族作为前缀,每个'列族'都可以有多个列成员(column);如course:math, course:english,新的列族成语(列)可以随时按需,动态加入
权限控制,存储以及调优都在列族层面进行的;
HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。 HBase体系架构
Client: 包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper:
1. 保证任何时候,集群中只有一个master
2. 存储所有Region的寻址入口
3. 实时监控Region Server的上线和下线信息,并实时通知master
4. 存储Hbase的schema和table元数据 Master:
1. 为Region Server分配region
2. 负责Region Server的负载均衡
3. 发现失效的Region Server并重新分配其上的region
4. 管理用户对table的增删改操作 Region Server:
1. 维护region,处理对这些region的IO请求
2. 负责切分在运行过程中变的过大的region Rgion:
1. HBase自动把表水平分成多个区域(region),每个region会报错一个表里面某段连续的数据;每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阈值的时候,region就会等分两个新的region(裂变)
2. 当table中的行不断增多,就会有越来越多的region,这样一张完整的表被保存在多个Region Server上。 Memstore于storefile:
1. 一个region由多个store组成,一个sote对应一个CF(列族)
2. sotre包含位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,region server会启动flashcache进程写入storefile,每次写入形成单独的一个storefile。(这样在一个region里面就会产生很多个storefile)
3. 当storefile文件的数量增长到一定阈值后,系统会进行合并(Minor, Major Compaction),在合并过程中贵进行版本合并和删除工作(Major),形成更大的storefile。
4. 当一个region所有storefile的大小和超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的region server服务器,实现负载均衡。
5. 客户端检索数据,现在memstore找,找不到再找storefile。
3.单机模式解压和安装HBase
--单机模式解压和安装HBase
tar -zxvf hbase-0.98.9-hadoop2-bin.tar.gz --创建软链
ln -sf /root/hbase-0.98.9-hadoop2 /home/hbase --配置java环境变量
cd /home/hbase/conf/ vi hbase-env.sh --jdk必须在1.6以上
export JAVA_HOME=/usr/java/jdk1.7.0_67 :wq --修改hbase-site.xml文件,数据保存到本地
vi hbase-site.xml <configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///opt/hbase</value>
</property>
</configuration> :wq --关闭防火墙
service iptables stop --启动HBase
cd /home/hbase/bin/
./start-hbase.sh --检查是否已经启动
jps
--查看是否有HMaster进程 --查看监听的端口
netstat -naptl | grep java --启动浏览器访问
http://node4:60010
3.1.创建t_student表
--进入hbase
cd /home/hbase/bin/
./hbase shell --创建t_student表
create 't_student' , 'cf1' hbase(main):003:0> create 't_student' , 'cf1'
0 row(s) in 0.4000 seconds
3.2.查看表t_student
--查看表
list hbase(main):004:0> list
TABLE
t_student
1 row(s) in 0.0510 seconds
3.3.查看表结构
--查看表结构
desc 't_student' hbase(main):005:0> desc 't_student'
Table t_student is ENABLED
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '', VERSIONS => '', COMPRESSION => 'NONE', MIN_VERSIONS => '', TTL => 'FOREVER', KEEP_DEL
ETED_CELLS => 'FALSE', BLOCKSIZE => '', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
1 row(s) in 0.1310 seconds
3.4.插入数据
--插入数据
put 't_student' , '', 'cf1:name', 'hongten' hbase(main):006:0> put 't_student' , '', 'cf1:name', 'hongten'
0 row(s) in 0.1750 seconds
3.5.查询table
--查询table
hbase(main):007:0> scan 't_student'
ROW COLUMN+CELL
007 column=cf1:name, timestamp=1541162668222, value=hongten
1 row(s) in 0.0670 seconds
4.完全分布式模式解压和安装HBase
--完全分布式模式解压和安装HBase
--拷贝hbase-0.98.9-hadoop2-bin.tar.gz从节点node1到node2, node3, node4节点上
scp /root/hbase-0.98.9-hadoop2-bin.tar.gz root@node2:~/
scp /root/hbase-0.98.9-hadoop2-bin.tar.gz root@node3:~/
scp /root/hbase-0.98.9-hadoop2-bin.tar.gz root@node4:~/ --解压缩文件
tar zxvf hbase-0.98.9-hadoop2-bin.tar.gz --创建软链
ln -sf /root/hbase-0.98.9-hadoop2 /home/hbase cd /home/hbase/conf/ vi hbase-site.xml --mycluster为集群名称
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
<description>The directory shared by RegionServers.</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>The mode the cluster will be in. Possible values are false: standalone and pseudo-distributed setups with managed Zookeeper true: fully-distributed with unmanaged Zookeeper Quorum (see hbase-env.sh)</description>
</property> <property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
<description>Comma separated list of servers in the ZooKeeper Quorum.
For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com".
By default this is set to localhost for local and pseudo-distributed modes
of operation. For a fully-distributed setup, this should be set to a full
list of ZooKeeper quorum servers. If HBASE_MANAGES_ZK is set in hbase-env.sh
this is the list of servers which we will start/stop ZooKeeper on.
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/zookeeper</value>
<description>Property from ZooKeeper's config zoo.cfg.
The directory where the snapshot is stored.
</description>
</property> :wq --修改regionservers文件,该文件列出所有region server主机的hostname
vi regionservers node1
node2
node3
node4 :wq --修改hbase-env.sh文件 vi hbase-env.sh
--修改java环境变量
export JAVA_HOME=/usr/java/jdk1.7.0_67 --默认为true,使用hbase自带的zookeeper
--修改为false,使用我们自定义的zookeeper
export HBASE_MANAGES_ZK=false :wq --使得Hadoop和HBase关联起来
--把hadoop的配置文件hdfs-site.xml拷贝到/home/hbase/conf/目录 cd /home/hbase/conf/
cp -a /home/hadoop-2.5/etc/hadoop/hdfs-site.xml . --把同样的配置从node1拷贝到node2,node3,node4上面去scp /home/hbase/conf/* root@node2:/home/hbase/conf/scp /home/hbase/conf/* root@node3:/home/hbase/conf/scp /home/hbase/conf/* root@node4:/home/hbase/conf/ --关闭所有节点上的防火墙(node1, node2, node3, node4)
service iptables stop --在启动HBase之前,我们需要确保zookeeper和hadoop都已经启动
--我们这里在node1,node2,node3,node4上面都有配置hbase,
--启动的时候,随便选择一个节点启动hbase,由于我们之前有配置免密码登录
--所以我们在node1上面启动hbase
cd /home/hbase/bin/ ./start-hbase.sh 输出结果:
[root@node1 bin]# ./start-hbase.sh
starting master, logging to /home/hbase/bin/../logs/hbase-root-master-node1.out
node3: starting regionserver, logging to /home/hbase/bin/../logs/hbase-root-regionserver-node3.out
node1: starting regionserver, logging to /home/hbase/bin/../logs/hbase-root-regionserver-node1.out
node4: starting regionserver, logging to /home/hbase/bin/../logs/hbase-root-regionserver-node4.out
node2: starting regionserver, logging to /home/hbase/bin/../logs/hbase-root-regionserver-node2.out --可以在node4上面启动master
cd /home/hbase/bin/ ./hbase-daemon.sh start master 输出结果:
[root@node4 bin]# ./hbase-daemon.sh start master
starting master, logging to /home/hbase/bin/../logs/hbase-root-master-node4.out
[root@node4 bin]# jps
28630 HRegionServer
28014 NodeManager
29096 Jps
29004 HMaster
27923 JournalNode
27835 DataNode --浏览器输入
http://node1:60010
我们在浏览器里面输入http://node1:60010
可以进入Hbase的管理界面,我们可以看到我们在4个节点(node1,node2, node3,node4)上都部署了Region Server。

4.1.创建t_student表
--创建t_student表
create 't_student' , 'cf1'
4.2.插入数据
此时的数据还在memstore里面(即HBase的管理的内存里面)
--插入数据
put 't_student' , '', 'cf1:name', 'hongten'
4.3.数据从内存写入到磁盘
把memstore的数据写入到storefile里面
--把数据从内存写入到磁盘
flush 't_student'
4.4.再次插入数据
put 't_student' , '', 'cf1:name', 'Tom'
put 't_student' , '', 'cf1:name', 'Dive'
4.5.再次把数据写入到磁盘
--把数据从内存写入到磁盘
flush 't_student'
此时我们可以看到,在HDFS上面有两个文件
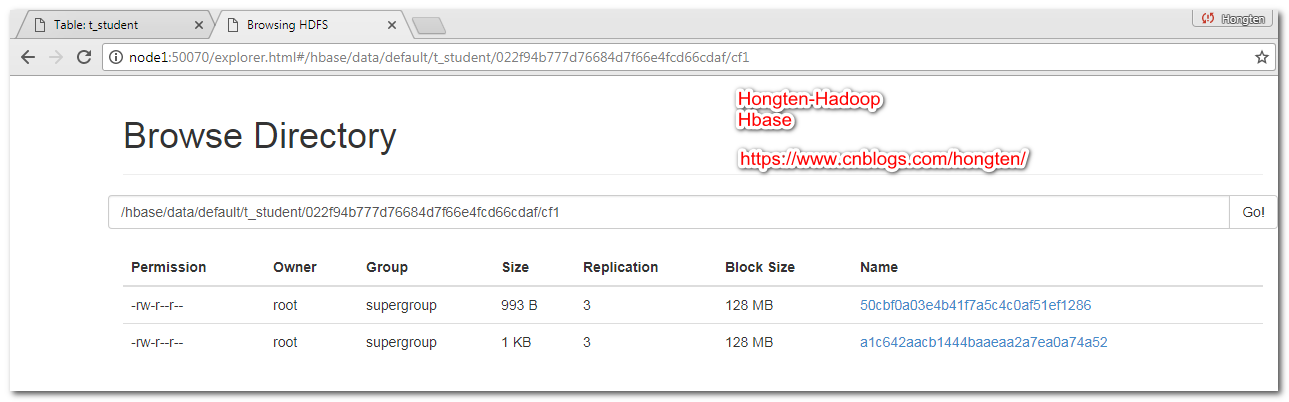
4.6.手动合并文件
--手动合并文件
major_compact 't_student'
合并之后,两个文件变成了一个文件

4.7.查看文件内容
上面文件的全路径
--查看文件内容
[root@node1 bin]# ./hbase hfile -p -f /hbase/data/default/t_student/022f94b777d76684d7f66e4fcd66cdaf/cf1/8efb9596ac774e839f0775efc55a8ab7
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hbase-0.98.9-hadoop2/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
2018-11-02 08:55:29,281 INFO [main] Configuration.deprecation: fs.default.name is deprecated. Instead, use fs.defaultFS
2018-11-02 08:55:29,429 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
2018-11-02 08:55:29,732 INFO [main] util.ChecksumType: Checksum using org.apache.hadoop.util.PureJavaCrc32
2018-11-02 08:55:29,734 INFO [main] util.ChecksumType: Checksum can use org.apache.hadoop.util.PureJavaCrc32C
K: 001/cf1:name/1541173663169/Put/vlen=3/mvcc=0 V: Tom
K: 002/cf1:name/1541173670882/Put/vlen=4/mvcc=0 V: Dive
K: 007/cf1:name/1541173242683/Put/vlen=7/mvcc=0 V: hongten
Scanned kv count -> 3
========================================================
More reading,and english is important.
I'm Hongten
大哥哥大姐姐,觉得有用打赏点哦!你的支持是我最大的动力。谢谢。
Hongten博客排名在100名以内。粉丝过千。
Hongten出品,必是精品。
E | hongtenzone@foxmail.com B | http://www.cnblogs.com/hongten
========================================================
hadoop2-HBase的安装和测试的更多相关文章
- Hbase的安装与测试
实验环境 虚拟机伪分布式 Ubuntu 17.10 JDK 1.8 Hadoop 2.7.6 Hbase 1.3.3 ①安装和配置HBase. 首先从官网http://archive.apache.o ...
- Hbase的安装测试工作
Hbase的安装测试工作: 安装:http://www.cnblogs.com/neverwinter/archive/2013/03/28/2985798.html 测试:http://www.cn ...
- Hadoop2.2.0多节点分布式安装及测试
众所周知,hadoop在10月底release了最新版2.2.很多国内的技术同仁都马上在网络上推出了自己对新版hadoop的配置心得.这其中主要分为两类: 1.单节点配置 这个太简单了,简单到只要懂点 ...
- Hbase的安装(hadoop-2.6.0,hbase1.0)
Hbase的安装相对很简单啊...只要你装了Hadoop 装Hbase就是分分钟的事 如果要装hadoop集群的话 hadoop分类的集群安装好了,如果已经装好单机版~ 那就再配置如下就好~ 一.vi ...
- Apache Hadoop2.x 边安装边入门
完整PDF版本:<Apache Hadoop2.x边安装边入门> 目录 第一部分:Linux环境安装 第一步.配置Vmware NAT网络 一. Vmware网络模式介绍 二. NAT模式 ...
- hbase单机版安装
hbase单机版安装 1. hbase单机版安装 HBase的安装也有三种模式:单机模式.伪分布模式和完全分布式模式. hbase依赖于Hadoop和Zookeeper. 这里安装的是单机版 ...
- Linux Hadoop2.7.3 安装(单机模式) 二
Linux Hadoop2.7.3 安装(单机模式) 一 Linux Hadoop2.7.3 安装(单机模式) 二 YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的Jo ...
- Hadoop2.6.0安装 — 集群
文 / vincentzh 原文连接:http://www.cnblogs.com/vincentzh/p/6034187.html 这里写点 Hadoop2.6.0集群的安装和简单配置,一方面是为自 ...
- Hadoop第3周练习--Hadoop2.X编译安装和实验
作业题目 位系统下进行本地编译的安装方式 选2 (1) 能否给web监控界面加上安全机制,怎样实现?抓图过程 (2)模拟namenode崩溃,例如将name目录的内容全部删除,然后通过secondar ...
随机推荐
- 多人聊天室(Java)
第1部分 TCP和UDP TCP:是一种可靠地传输协议,是把消息按一个个小包传递并确认消息接收成功和正确才发送下一个包,速度相对于UDP慢,但是信息准确安全:常用于一般不要求速度和需要准确发送消息的场 ...
- [译]Ocelot - Configuration
原文 这里有一个配置的样例.配置主要有两个部分.一个是ReRoutes数组,另一个是GlobalConfiguration.ReRoute告诉Ocelot怎么处理上游的请求.Global config ...
- 【cpp】chap 8
1.输出“输入的内容” // basic file operations #include <iostream> #include <fstream> #include < ...
- 关于PHP创建接口及调用接口的简短例子(本地)
********************************************************************************************** /*这是P ...
- TCP/IP教程
一.TCP/IP 简介 TCP/IP 是用于因特网的通信协议. 通信协议是对计算机必须遵守的规则的描述,只有遵守这些规则,计算机之间才能进行通信. 什么是 TCP/IP? TCP/IP 是供已连接因特 ...
- 在JS中如何判断所输入的是一个数、整数、正数、非数值?
1.判断是否为一个数字: Number(num)不为 NaN,说明为数字 2. 判断一个数为正数: var num=prompt("请输入:"); if(Number(num)&g ...
- java(8)二重循环
一.二重循环 1.循环中,嵌套另外一个循环,将内层的循环,看成外层循环的一个循环操作 2.常见的二重循环 形式1: 外层while或do…while 内层为for循环 形式2: 外层.内层都 ...
- I. Max answer(RMQ预处理前缀和)
题目链接: https://nanti.jisuanke.com/t/38228 题目大意:给你n个数,让你找出一个区间中f的最大值,具体的f计算方法,这段区间的和乘以这段区间的最小值. 具体思路:我 ...
- Linux进程组调度机制分析【转】
转自:http://oenhan.com/task-group-sched 又碰到一个神奇的进程调度问题,在系统重启过程中,发现系统挂住了,过了30s后才重新复位,真正系统复位的原因是硬件看门狗重启的 ...
- $Django python中使用redis, django中使用(封装了),redis开启事务(管道)
一 Python操作Redis之普通连接 #先安装 pip3 install redis import redis r = redis.Redis(host='127.0.0.1', port=637 ...