Azkaban各种类型的Job编写
一、概述
原生的 Azkaban 支持的plugin类型有以下这些:
- command:Linux shell命令行任务
- gobblin:通用数据采集工具
- hadoopJava:运行hadoopMR任务
- java:原生java任务
- hive:支持执行hiveSQL
- pig:pig脚本任务
- spark:spark任务
- hdfsToTeradata:把数据从hdfs导入Teradata
- teradataToHdfs:把数据从Teradata导入hdfs
其中最简单而且最常用的是command类型,我们在上一篇文章中已经描述了如何编写一个command的job任务。如果使用command类型,效果其实跟在本地执行Linux shell命令一样,这样的话,还不如把shell放到crontable 中运行。所以我们把重点放到Azkaban支持的比较常用的四种类型:java、hadoopJava、hive、spark
二、java类型
1、代码编写:MyJavaJob.java
package com.dataeye.java;
public class MyJavaJob {
public static void main(String[] args) {
System.out.println("#################################");
System.out.println("#### MyJavaJob class exec... ###");
System.out.println("#################################");
}
}
2、打包成jar文件:使用maven或者eclipse导出为jar文件
3、编写job文件:java.job
type=javaprocess
classpath=./lib/*,${azkaban.home}/lib/*
java.class=com.dataeye.java.MyJavaJob
4、组成一个完整的运行包
新建一个目录,在该目录下创建一个lib文件夹,把第二步打包的jar文件放到这里,把job文件放到和lib文件夹同一级的目录下,如下所示:

完整的运行包
5、打包成zip文件
把lib目录和job文件打包成zip文件,如下的java.zip:
6、提交运行,过程跟之前文章介绍的步骤一样,不再详述,执行结果如下:
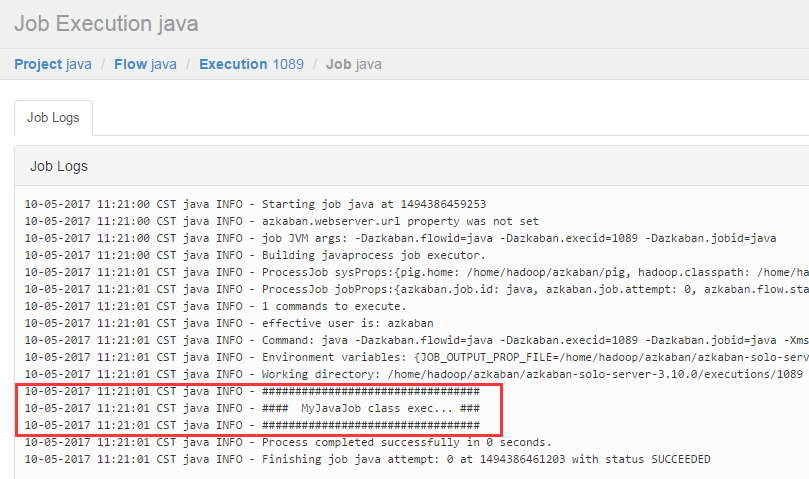
执行结果
从输出日志可以看出,代码已经正常执行。
以上是java类型的任务编写和执行的过程。接下来介绍其他任务编写的时候,只会介绍代码的编写和job的编写,其他过程与上面的一致。
三、hadoopJava类型
1、数据准备
以下内容是运行wordcount任务时需要的输入文件input.txt:
1 Ross male 33 3674
2 Julie male 42 2019
3 Gloria female 45 3567
4 Carol female 36 2813
5 Malcolm male 42 2856
6 Joan female 22 2235
7 Niki female 27 3682
8 Betty female 20 3001
9 Linda male 21 2511
10 Whitney male 35 3075
11 Lily male 27 3645
12 Fred female 39 2202
13 Gary male 28 3925
14 William female 38 2056
15 Charles male 48 2981
16 Michael male 25 2606
17 Karl female 32 2260
18 Barbara male 39 2743
19 Elizabeth female 26 2726
20 Helen female 47 2457
21 Katharine male 45 3638
22 Lee female 43 3050
23 Ann male 35 2874
24 Diana male 37 3929
25 Fiona female 45 2955
26 Bob female 21 3382
27 John male 48 3677
28 Thomas female 22 2784
29 Dean male 38 2266
30 Paul female 31 2679
把input.txt文件拷贝到hdfs的 /data/yann/input 目录下
2、代码准备:
package azkaban.jobtype.examples.java; import azkaban.jobtype.javautils.AbstractHadoopJob;
import azkaban.utils.Props;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.log4j.Logger; public class WordCount extends AbstractHadoopJob
{
private static final Logger logger = Logger.getLogger(WordCount.class);
private final String inputPath;
private final String outputPath;
private boolean forceOutputOverrite; public WordCount(String name, Props props)
{
super(name, props);
this.inputPath = props.getString("input.path");
this.outputPath = props.getString("output.path");
this.forceOutputOverrite = props.getBoolean("force.output.overwrite", false);
} public void run()
throws Exception
{
logger.info(String.format("Starting %s", new Object[] { getClass().getSimpleName() })); JobConf jobconf = getJobConf();
jobconf.setJarByClass(WordCount.class); jobconf.setOutputKeyClass(Text.class);
jobconf.setOutputValueClass(IntWritable.class); jobconf.setMapperClass(Map.class);
jobconf.setReducerClass(Reduce.class); jobconf.setInputFormat(TextInputFormat.class);
jobconf.setOutputFormat(TextOutputFormat.class); FileInputFormat.addInputPath(jobconf, new Path(this.inputPath));
FileOutputFormat.setOutputPath(jobconf, new Path(this.outputPath)); if (this.forceOutputOverrite)
{
FileSystem fs = FileOutputFormat.getOutputPath(jobconf).getFileSystem(jobconf);
fs.delete(FileOutputFormat.getOutputPath(jobconf), true);
} super.run();
} public static class Map extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable>
{
private static final IntWritable one = new IntWritable(1);
private Text word = new Text(); private long numRecords = 0L; public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
this.word.set(tokenizer.nextToken());
output.collect(this.word, one);
reporter.incrCounter(Counters.INPUT_WORDS, 1L);
} if (++this.numRecords % 100L == 0L)
reporter.setStatus("Finished processing " + this.numRecords + " records " + "from the input file");
} static enum Counters
{
INPUT_WORDS;
}
} public static class Reduce extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable>
{
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException
{
int sum = 0;
while (values.hasNext()) {
sum += ((IntWritable)values.next()).get();
}
output.collect(key, new IntWritable(sum));
}
}
}
3、编写job文件
wordcount.job文件内容如下:
type=hadoopJava
job.extend=false
job.class=azkaban.jobtype.examples.java.WordCount
classpath=./lib/*,${azkaban.home}/lib/*
force.output.overwrite=true
input.path=/data/yann/input
output.path=/data/yann/output
这样hadoopJava类型的任务已经完成,打包提交到Azkaban中执行即可
四、hive类型
1、编写 hive.sql文件
use azkaban; INSERT OVERWRITE TABLE
user_table1 PARTITION (day_p='2017-02-08')
SELECT appid,uid,country,province,city
FROM user_table0 where adType=1;
以上是标准的hive的sql脚本,首先切换到azkaban数据库,然后把user_table0 的数据插入到user_table1 表的指定day_p分区。需要先准备好 user_table0 和 user_table1 表结构和数据。
编写完成后,把文件放入 res 文件夹中。
2、编写hive.job文件
type=hive
user.to.proxy=azkaban
classpath=./lib/*,${azkaban.home}/lib/*
azk.hive.action=execute.query
hive.script=res/hive.sql
关键的参数是 hive.script,该参数指定使用的sql脚本在 res目录下的hive.sql文件
五、spark类型
spark任务有两种运行方式,一种是command类型,另一种是spark类型
首先准备好spark任务的代码
package com.dataeye.template.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{SQLContext}
object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage:WordCount <hdfs_file>")
System.exit(1)
}
System.out.println("get first param ==> " + args(0))
System.out.println("get second param ==> " + args(1))
/** spark 2.0的方式
* val spark = SparkSession.builder().appName("WordCount").getOrCreate()
*/
val sc = new SparkContext(new SparkConf().setAppName("WordCount"))
val spark = new SQLContext(sc)
val file = spark.sparkContext.textFile(args(0))
val wordCounts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
// 数据collect 到driver端打印
wordCounts.collect().foreach(println _)
}
}
然后准备数据,数据就使用前面hadoopJava中的数据即可。
最后打包成jar文件:spark-template-1.0-SNAPSHOT.jar
1、command类型
command类型的配置方式比较简单,spark.job文件如下:
type=command
command=${spark.home}/bin/spark-submit --master yarn-cluster --class com.dataeye.template.spark.WordCount lib/spark-template-1.0-SNAPSHOT.jar hdfs://de-hdfs/data/yann/info.txt paramtest
2、spark类型
type=spark master=yarn-cluster
execution-jar=lib/spark-template-1.0-SNAPSHOT.jar
class=com.dataeye.template.spark.WordCount
params=hdfs://de-hdfs/data/yann/info.txt paramtest
以上就是Azkaban支持的几种常用的任务类型。
Azkaban各种类型的Job编写的更多相关文章
- 阶段3 3.SpringMVC·_02.参数绑定及自定义类型转换_6 自定义类型转换器代码编写
mvc是基于组件的方式 类型转换的接口Converter,想实现类型转换,必须实现这个接口 Ctrl+N搜索 converter 这是一个接口类 它有很多的实现类.S是字符串.后面T是指要转换类型 新 ...
- springmvc:自定义类型转换器代码编写
字符串转换日期: 1.自定义一个类 /** * 字符串转换日期 */ public class StringToDateConverter implements Converter<String ...
- 编写TypeScript工具类型,你需要知道的知识
什么是工具类型 用 JavaScript 编写中大型程序是离不开 lodash 工具的,而用 TypeScript 编程同样离不开工具类型的帮助,工具类型就是类型版的 lodash .简单的来说,就是 ...
- 从零开始编写自己的C#框架(1)——前言
记得十五年前自学编程时,拿着C语言厚厚的书,想要上机都不知道要用什么编译器来执行书中的例子.十二年前在大学自学ASP时,由于身边没有一位同学和朋友学习这种语言,也只能整天混在图收馆里拼命的啃书.而再后 ...
- 数据库 定义 bit 类型 (true=1,false=0)
当Sql Server数据库定义 数据 为 bit 类型时, 编写代码时 要用 true or false 赋值. 例如: OffTheShelf 定义类型为 bit 后台赋值时 OffTheSh ...
- 转:C++编程隐蔽错误:error C2533: 构造函数不能有返回类型
C++编程隐蔽错误:error C2533: 构造函数不能有返回类型 今天在编写类的时候,出现的错误. 提示一个类的构造函数不能够有返回类型.在cpp文件里,该构造函数定义处并没有返回类型.在头文件里 ...
- 从零开始编写自己的C#框架 ---- 系列文章
目录: 从零开始编写自己的C#框架(1)——前言从零开始编写自己的C#框架(2)——开发前的准备工作从零开始编写自己的C#框架(3)——开发规范从零开始编写自己的C#框架(4)——文档编写说明从零开始 ...
- [C] zlstdint(让VC、TC等编译器自动兼容C99的整数类型)V1.0。支持Turbo C++ 3等DOS下的编译器
作者:zyl910 以前我曾为了让VC++等编译器支持C99的整数类型,便编写了c99int库来智能处理(http://www.cnblogs.com/zyl910/p/c99int_v102.htm ...
- 15.C#回顾及匿名类型(八章8.1-8.5)
今天的篇幅应该会很长,除了回顾前面学的一些,还有写一些关于匿名类型的相关知识,总体上对后续的学习很有帮助,学好了,后面更容易理解,不明白的,那就前面多翻几次,看多了总是会理解的.那么,进入正题吧. 自 ...
随机推荐
- Python笔记4——字典的一些基本操作
#字典 key-value #添加 my_family= {"father": "weihaiqing", "mother": " ...
- iptables-save命令
[root@localhost ~]# iptables-save -t filter > iptables.bak [root@localhost ~]# cat iptables.bak # ...
- Android日常问题整理
1.系统语言切换后Activity布局刷新问题 4.2增加了一个layoutDirection属性,当改变语言设置后,该属性也会成newConfig中的一个mask位.所以ActivityManage ...
- Vue-cli里面引用stylus遇到的问题总结
1.stylus的调用 在vue-cli中用到stylus样式处理器的时候一定要引用两个对应的报stylus stylus-loader 命令:cnpm install stylus stylus- ...
- Linux批量复制文件到文件夹
echo dirname* | xargs -n 1 cp -v filename 把当前目录下 filename文件拷贝到以dirname开头的不同文件夹里.
- 10_java基础——构造器里调用构造器
package com.huawei.test.java04; /** * This is Description * * @author * @date 2018/08/30 */ public c ...
- read读文件
FILE *fp=fopen("F:\\QQBrowser_Setup_DNF.exe", "rb"); fseek(fp, , SEEK_END); long ...
- 调试利器GDB(上)
什么是GDB: GDB应用: 静态分析工具与动态分析工具: GDB启动方式: GDB启动之后会有一个交互式的命令行,可以输入GDB特定的命令让GDB去工作. gdb test.out意思是这一次gdb ...
- 2018上C语言程序设计(高级)作业- 第4次作业成绩及总结
作业地址 https://edu.cnblogs.com/campus/hljkj/CS2017-01/homework/1842 评分准则 第4次作业各项成绩包括三项: 完成WC项目:60分:基本功 ...
- Java基于opencv—归一化
Opencv中提供了resize函数,可以把图像调整到相同大小 Java中resize函数的声明,内部调用的都是native方法 public static void resize(Mat src, ...