使用sbt构建spark 程序
今日在学习scala和spark相关的知识。之前在eclipse下编写了wordcount程序。但是关于导出jar包这块还是很困惑。于是学习sbt构建scala。
关于sbt的介绍网上有很多的资料,这里就不解释了。参考:http://wiki.jikexueyuan.com/project/sbt-getting-started/install-sbt.html
关于linux下(centos)安装sbt: 依次执行
curl https://bintray.com/sbt/rpm/rpm > bintray-sbt-rpm.repo
sudo mv bintray-sbt-rpm.repo /etc/yum.repos.d/
sudo yum install sbt
使用sbt需要按照sbt的要求生成相关的目录:
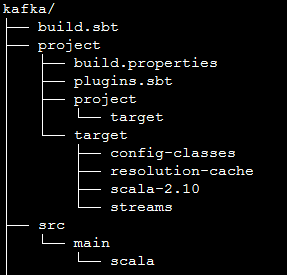
其中,kafka是项目根目录,build.sbt的内容如下:
name := "test" version := "1.0" scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.10" % "1.6.2" % "provided" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.2" % "provided" libraryDependencies += "org.apache.spark" %% "spark-sql" % "1.6.2" % "provided" libraryDependencies += "org.apache.spark" % "spark-streaming-kafka_2.10" % "1.6.2" //注意版本
scalaVersion是指定编译程序的scala版本,因为这里用的是spark1.6.2,所以对应的scala版本为2.10.5
libraryDependencies 是指程序的库依赖,最后的provided 的意思是,spark内已经提供了这几个库,打包时,无需考虑这几个。
src是项目源代码所在位置:

KafkaWordCount.scala内容如下:
import java.util.HashMap
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.SparkConf object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < ) {
System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>")
System.exit()
} val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds())
ssc.checkpoint("checkpoint") val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(), Seconds(), )
wordCounts.print() ssc.start()
ssc.awaitTermination()
}
}
在项目的根目录,即kafka目录下面,运行: sbt compile 对项目进行编译。sbt package 导出jar包。
在spark目录运行:
./bin/spark-submit --master spark://192.168.1.241:7077 --class KafkaWordCount /root/kafka/target/scala-2.10/test_2.10-1.0.jar 127.0.0.1:2181 2 2 2
这样运行出错,提示没有kafkaUtil这个类,网上查了下,是使用package打包时,并没有将依赖的jar包打成一个,因此需要使用assembly插件
并且运行的时候,会有类似错误:
Exception in thread "main" org.apache.spark.SparkException:
Checkpoint RDD CheckpointRDD[] at foreachRDD at WebPagePopularityValueCalculator.scala:68(0)
has different number of partitions than original RDD MapPartitionsRDD[] at updateStateByKey at WebPagePopularityValueCalculator.scala:62(2)
这是因为在集群模式运行时,需要将checkpoint文件夹设置为hdfs类似的路径。解决方法为:使用hdfs的路径: hdfs:ip:9000/data
关于assembly的介绍: http://blog.csdn.net/beautygao/article/details/32306637
参考:http://stackoverflow.com/questions/27198216/sbt-assembly-deduplicate-error-exclude-error
http://blog.csdn.net/ldds_520/article/details/51443606
http://www.cnblogs.com/scnu-ly/p/5106726.html
使用sbt构建spark 程序的更多相关文章
- sbt编译spark程序提示value toDF is not a member of Seq()
sbt编译spark程序提示value toDF is not a member of Seq() 前提 使用Scala编写的Spark程序,在sbt编译打包的时候提示value toDF is no ...
- 构建Spark作业
首先,要清楚,一个Java或Scala或python实现的Spark作业. 1.用sbt构建Spark作业 2.用Maven构建Spark作业 3.用non-maven-aware工具构建Spark作 ...
- sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类
sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类 详述 使用sbt对写的Spark程序打包,过程中没有问题 spark-submit提交jar包运行提示找不到对应的类 解 ...
- SBT安装及命令行打包spark程序
1.从https://www.scala-sbt.org/download.html官网上寻找所需要的安装包 可以直接本地下载完扔进去也可以wget路径,在这里我用的是sbt1.2.8版本的,下载到/ ...
- SBT 构建scala eclipse开发
scala eclipse sbt 应用程序开发 搭建Eclipse开发Scala应用程序的一般步骤 一.环境准备: 1.Scala : http://www.scala-lang.org/ 2.Sc ...
- 使用IDEA运行Spark程序
使用IDEA运行Spark程序 1.安装IDEA 从IDEA官网下载Community版本,解压到/usr/local/idea目录下. tar –xzf ideaIC-13.1.4b.tar.gz ...
- Spark:利用Eclipse构建Spark集成开发环境
前一篇文章“Apache Spark学习:将Spark部署到Hadoop 2.2.0上”介绍了如何使用Maven编译生成可直接运行在Hadoop 2.2.0上的Spark jar包,而本文则在此基础上 ...
- 构建Spark的Eclipse开发环境
前言 无论Windows 或Linux 操作系统,构建Spark 开发环境的思路一致,基于Eclipse 或Idea,通过Java.Scala 或Python 语言进行开发.安装之前需要提前准备好JD ...
- 使用SBT构建Scala应用(转自git)
# 使用SBT构建Scala应用 ## SBT简介 SBT是Simple Build Tool的简称,如果读者使用过Maven,那么可以简单将SBT看做是Scala世界的Maven,虽然二者各有优劣, ...
随机推荐
- sublime text 3 license 2016.05
补充:2016.05 最近经过测试,3个注册码在新版3103的sublime上已经不可用了. 现补充两枚新版的license key: -– BEGIN LICENSE -– Michael Barn ...
- Tornado实战项目(伪JD商城)
预备知识 在之前tornado商城项目中,在开始之前需要引入一些项目设计知识,如接口,抽象方法抽象类,组合,程序设计原则等,个人理解项目的合理设计可增加其灵活性, 降低数据之间的耦合性,提高稳定性,下 ...
- 使用Lamda生成函数
#include <functional> int main() { std::function<]; ; i < ;i++ ) fn[i] = [=]() {return i ...
- AUTOIT解决域控普通用户以管理员身份安装软件方法
windows域管理,本是很好的管理方式,方便的软件分发,权限控制等功能.不过由于我处软件分发总有那么一些电脑没有成功安装,或是新装的电脑安装软件时漏了安装一些软件,而这些软件需要管理员权限安装的,用 ...
- ssh整合需要那些jar
struts2 commons-logging-1.0.4.jar -------主要用于日志处理 freemarker-2.3.8.jar ------- 模板相关操作需要包 ognl-2.6.1 ...
- 北京易信软科信息技术有限公司 问卷调查管理系统V2.0
北京易信软科信息技术有限公司 问卷调查管理系统V2.0 支持题目模板配置.题型模板配置.选项模板配置,报表查询功能配置 按月建表功能 运用java开发.velocity技术实现页面加载功能,高性能,高 ...
- WCF框架处理流程初探
拜读了大牛蒋金楠的<WCF技术剖析之一:通过一个ASP.NET程序模拟WCF基础架构>,写点心得. (原文:http://www.cnblogs.com/artech/archive/20 ...
- 【练习】oracel获取当前session的id方法
1. :: SYS; SID ---------- 2. :: SYS@ORA11GR2>SELECT USERENV('SID') FROM DUAL; USERENV('SID') ---- ...
- 关于ckeditor 第二次加载 出现问题
在使用ckeditor 出现的问题也比较多的 ,一个问题是图片上传的问题 ,一个就是第二次加载的时候 ckeditor编辑框出现不了的问题 第一个问题 是修改ckeditor js属性 网上都有 第 ...
- 第一天 :学习node.js
① node.js环境配置 我学过的语言最简单的一门 直接百度就可以配置 ② 每个入门 的程序都是从helloworld开始 代码如下 : var http=require('http'); http ...