从零自学Hadoop(15):Hive表操作
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们介绍了Hive和对其进行了安装,下面我们就初步的使用hive进行讲解。
下面我们开始介绍hive的创建表,修改表,删除表等。
创建表
一:Hive Client
在Terminal输入hive命令需要安装Hive Client。
二:进入
切换用户,进入hive
su hdfs
hive
三:创建表
语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)];例子:
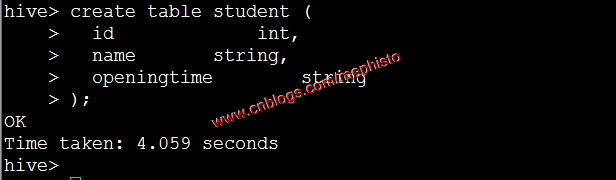
create table student (
id int,
name string,
openingtime string
);
四:创建带有分区的表
介绍:
一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。表中的一个 Partition 对应于表下的一个目录,Partition 就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
语法:
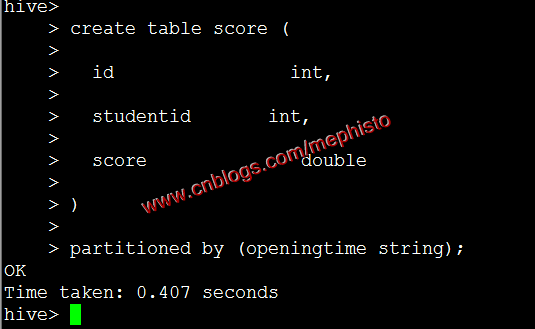
create table table_name ( id int, dtDontQuery string, name string ) partitioned by (date string)例子:
create table score ( id int, studentid int, score double ) partitioned by (openingtime string);

查看表
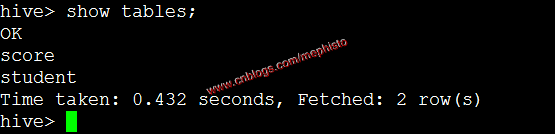
一:查看所有表
show tables;
二:查看某个表信息
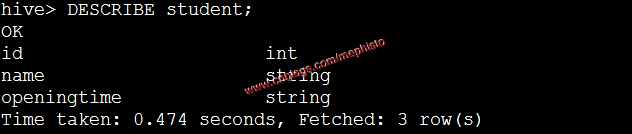
我们通过Desctribe来显示某个表的信息
语法:
DESCRIBE DATABASE [EXTENDED] db_name; DESCRIBE SCHEMA [EXTENDED] db_name; -- (Note: Hive 0.15. and later) --------------------------------------------------------------------------------- DESCRIBE [EXTENDED|FORMATTED] [db_name.]table_name[.col_name ( [.field_name] | [.'$elem$'] | [.'$key$'] | [.'$value$'] )* ]; -- (Note: Hive .x.x and .x.x only) -- (see "Hive 2.0+: New Syntax" below)例子:
DESCRIBE student;DESCRIBE score;
三:查看某列信息
DESCRIBE student.id;
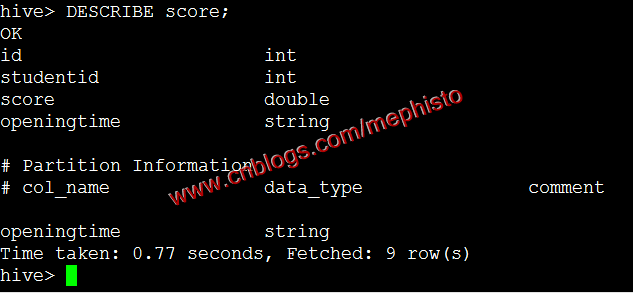

修改表
一:改表名
语法:
ALTER TABLE table_name RENAME TO new_table_name;例子:
alter table student rename to student1;
二:修改列
语法:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];例子:
alter table student1 change name name1 string;
三:增加/替换列
语法:
ALTER TABLE table_name [PARTITION partition_spec] ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) [CASCADE|RESTRICT]例子:
alter table student1 add columns (sex int);



删除表
一:删除表
语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];例子:
drop table score;
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。

系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
从零自学Hadoop(15):Hive表操作的更多相关文章
- 从零自学Hadoop系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 从零自学Hadoop(01):认识Hadoop ...
- 从零自学Hadoop(18):Hive的CLI和JDBC
阅读目录 序 Hive CLI(old CLI) Beeline CLI(new CLI) JDBC Demo下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出 ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
- 从零自学Hadoop(24):Impala相关操作上
阅读目录 序 数据库相关 表相关 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 ...
- 从零自学Hadoop(20):HBase数据模型相关操作上
阅读目录 序 介绍 命名空间 表 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 ...
- 从零自学Hadoop(21):HBase数据模型相关操作下
阅读目录 序 变量 数据模型操作 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 ...
- 从零自学Hadoop(14):Hive介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 本系列已 ...
- 从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录 序 将查询的结果写入文件系统 集群数据迁移一 集群数据迁移二 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephis ...
- 从零自学Hadoop(25):Impala相关操作下
阅读目录 序 导入数据 查询 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一 ...
随机推荐
- 相克军_Oracle体系_随堂笔记012-undo
undo表空间中undo段是自动生成的,oracle自动使用undo表空间的undo段. 作为高级DBA,需要了解Oracle是如何使用undo段的.这样出了性能问题才能够解决. 1.Undo表空 ...
- ssh整合问题总结--使用struts2+Ajax+jquery验证用户名是否已被注册
在用户模块中的用户注册需求上,通常要进行用户名是否已被注册的验证,今天正好写了这个需求,把详细代码和所遇到的问题贴过来.在使用struts2+ajax时候,通常我们会返回json类型的数据,但是像上面 ...
- Mongoose使用案例--让JSON数据直接入库MongoDB
目录 1.准备工作. 2.配置Mongoose. 3.创建目录及文件. 4.插入数据,POST提交JSON增加一条记录. 5.查询数据,取出你插入数据库的记录. 一.准备工作 使用Express4创建 ...
- ApiController使用Session验证出现Null解决方案
问题描述 在服务端保存登录信息,出现异常信息 分析发现HttpContext.Current.Session为null 解决方案 执行时出报异常,要在Global.asax里添加:开启Session功 ...
- 深入浅出JS的封装与继承
JS虽然是一个面向对象的语言,但是不是典型的面向对象语言.Java/C++的面向对象是object - class的关系,而JS是object - object的关系,中间通过原型prototype连 ...
- C#多线程编程
一.使用线程的理由 1.可以使用线程将代码同其他代码隔离,提高应用程序的可靠性. 2.可以使用线程来简化编码. 3.可以使用线程来实现并发执行. 二.基本知识 1.进程与线程:进程作为操作系统执行程序 ...
- Oracle11g 配置 ST_GEOMETRY
安装环境:ArcGIS Desktop10.2.1 .ArcSDE10.2.134940. Oracle11.2.0.1 操作系统:Windows Server 2012R2 DataCenter 安 ...
- python基础学习笔记2
词典 词典(dictionary)与列表相似,也可以存储多个元素.存储多个元素的对象称为容器(container); 常见的创建词典的方法: >>>dic = {'tom':11 ...
- 【转】acm小技巧
1.一般用c语言节约空间,要用c++库函数或STL时才用c++: cout.cin和printf.scanf最好不要混用. 大数据输入输出最后不用cin.cout,纺织超市. 2.有时候int型不够用 ...
- C标准头文件<signal.h>
信号即异常,或者理解为中断,一个进程接收到一个信号,如果没有处理机制,就会按照默认的处理方式进行处理,而默认的处理方式通常是终止当前进程或忽略该信号.当然,程序也可以编写相应的处理信号的函数,一旦接收 ...