DPDK LPM库(学习笔记)
1 LPM库
DPDK LPM库组件为32位的key实现了最长前缀匹配(LPM)表查找方法,该方法通常用于在IP转发应用程序中找到最佳路由匹配。
2 LPM API概述
LPM组件实例的主要配置参数是要支持的最大规则数。 LPM前缀由一对参数(32位Key,深度)表示,深度范围为1到32。LPM规则由LPM前缀和与该前缀关联的一些用户数据表示。 该前缀用作LPM规则的唯一标识符。 在此实现中,用户数据的长度为1字节,称为下一跳,与其在路由表条目中存储下一跳ID的主要用途相关。
LPM组件主要方法有:
- 添加LPM规则:LPM规则作为输入参数。如果表中不存在具有相同前缀的规则,则新规则将添加到LPM表中。如果表中已经存在具有相同前缀的规则,则将更新该规则的下一跳。如果没有可用的存储空间,则会返回错误。
- 删除LPM规则:LPM规则的前缀作为输入参数。如果LPM表中存在具有指定前缀的规则,则将其删除。
- 查找LPM规则:提供32位Key作为输入。该算法用于选择给定Key的最佳匹配的LPM规则,并返回该规则的下一跳。如果LPM表中存在多个具有相同32位Key的规则,则该算法将深度最大的规则选为最佳匹配规则,这意味着输入Key和该规则Key之间具有最高有效位的匹配。
3 实现细节
当前实现使用DIR-24-8算法的一种变体,该算法以内存使用量为代价来提高LPM查找速度。 该算法允许执行查找操作,通常只需一次内存读访问。从统计上看,即便是不常出现的情况,当即最佳匹配规则的深度大于24时,查找操作也仅需要两次内存读访问。 因此,LPM查找操作的性能在很大程度上取决于特定内存位置是否存在于处理器高速cache中。
主要数据结构使用以下元素构建:
- 具有2 ^ 24个条目的表。
- 具有2 ^ 8个条目的多个表(RTE_LPM_TBL8_NUM_GROUPS)。
第一张表称为tbl24,使用要查找的IP地址的前24位进行索引,第二张表称为tbl8,使用IP地址的最后8位进行索引。这意味着,根据尝试将传入数据包的IP地址与tbl24中存储的规则进行匹配的结果,我们可能需要在第二级继续查找过程。
由于tbl24的每个条目都可能指向tbl8,因此理想情况下,我们将有2 ^ 24个tbl8,这与具有2 ^ 32个条目的单个表相同。 由于资源限制,这是不可行的。 相反,这种方法就是利用了超过24位的规则非常少的这一特定。通过将这个过程分为两个不同的表/级别并限制tbl8的数量,我们可以大大降低内存消耗,同时保持非常好的查找速度(大部分时间仅一个内存访问)。
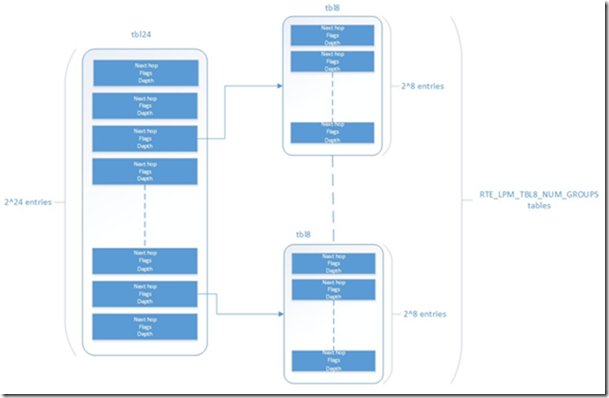
tbl24中的条目包含以下字段:
- 下一跳,或指向tbl8的索引
- 有效标志
- 外部条目标志
- 规则深度(长度)
第一个字段可以包含指示查找过程应该继续的tbl8的索引,或者如果已经找到最长的前缀匹配,则可以是下一跳本身。 这两个标志分别用于确定条目是否有效以及搜索过程是否已完成。 规则的深度或长度指的是存储在特定条目中的规则的位数。
tbl8中的条目包含以下字段:
- 下一跳
- 有效标志
- 有效组
- 规则深度
下一跳和深度包含与tbl24中相同的信息。 这两个标志分别显示条目和表是否有效。
另一个主要数据结构是一个包含有关规则(IP和下一跳)的主要信息的表。 这是一个更高级别的表,用于不同的事物:
- 在添加或删除之前,无需实际执行查找即可检查规则是否已经存在。
- 删除时,检查是否存在包含要删除的规则。 这很重要,因为主数据结构必须相应更新。
3.1 添加
添加规则时,存在不同的可能性。 如果规则的深度恰好是24位,则:
- 使用规则(IP地址)作为tbl24的索引。
- 如果条目无效(即它尚未包含规则),则更新下一跳的值,将有效标志设置为1(表示该条目正在使用),将外部条目标志设置为0(表示查找查找过程结束,因为这是匹配的最长前缀)。
如果规则的深度恰好是32位,则:
- 使用规则的前24位作为tbl24的索引。
- 如果该条目无效(即它尚未包含规则),则寻找一个空闲的tbl8,将tbl8的索引设置为此值,将有效标志设置为1(表示该条目正在使用),并将外部条目标志为1(意味着查找过程必须继续,因为规则尚未被完全探测)。
如果规则的深度为其他任何值,则必须执行前缀扩展。 这意味着将规则复制到所有条目(只要这些条目不被使用),这也会导致匹配。
举一个简单的例子,假设深度为20位。 这意味着将导致匹配的IP地址的前24位有2 ^(24-20)= 16个不同的组合。 因此,在这种情况下,我们将完全相同的条目复制到这些组合之一所索引的每个位置。
通过这样做,我们确保在查找过程中,如果存在与IP地址匹配的规则,则可以在一个或两次内存访问中找到该规则,具体取决于我们是否需要移至下一张表。 前缀扩展是该算法的关键之一,因为它可以通过添加冗余来极大地提高速度。
3.2 查找
查找过程更加简单快捷:
- 使用IP地址的前24位作为tbl24的索引。 如果该条目未使用,则表明我们没有与此IP匹配的规则。 如果有效且外部入口标志设置为0,则返回下一跳。
- 如果有效且外部入口标志设置为1,则我们使用tbl8索引查找要检查的tbl8,并将IP地址的最后8位用作此表的索引。 同样,如果该条目未使用,则我们没有与此IP地址匹配的规则。 如果有效,则返回下一跳。
3.3 规则数限制
规则数量受到诸多不同因素的限制。第一个是规则的最大数量,它是通过API传递的参数。一旦达到此数目,除非删除一个或多个规则,否则就无法在路由表中添加更多规则。
第二个原因是算法的固有局限性。如前所述,为避免高昂的内存消耗,编译时间限制了tbl8的数量(此值默认为256)。如果我们用尽了tbl8,我们将无法再添加任何规则。对于特定的路由表,需要多少个是很难预先确定的。
每当我们有一个深度大于24的新规则时,并且此规则的前24位与先前添加的规则的前24位不同,就会消耗tbl8。如果相同,那么新规则将与前一个规则共享相同的tbl8,因为这两个规则之间的唯一区别是在最后一个字节之内。
默认值为256情况下,我们最多可以有256个长度超过24位,且前三个字节都不同的规则。由于路由长度超过24位的不多,因此在大多数设置中这不是问题。即使是,也可以通过修改tbl8的数量来解决。
3.4 用例:IPv4转发
LPM算法用于实现实现IPv4转发的路由器使用的无类域间路由(CIDR)策略。
3.5 References
- DPDK官方编程指南:http://doc.dpdk.org/guides-20.02/prog_guide/lpm_lib.html
- RFC1519 Classless Inter-Domain Routing (CIDR): an Address Assignment and Aggregation Strategy http://www.ietf.org/rfc/rfc1519
- Pankaj Gupta, Algorithms for Routing Lookups and Packet Classification, PhD Thesis, Stanford University, 2000 (http://klamath.stanford.edu/~pankaj/thesis/ thesis_1sided.pdf )
DPDK LPM库(学习笔记)的更多相关文章
- numpy, matplotlib库学习笔记
Numpy库学习笔记: 1.array() 创建数组或者转化数组 例如,把列表转化为数组 >>>Np.array([1,2,3,4,5]) Array([1,2,3,4,5]) ...
- muduo网络库学习笔记(五) 链接器Connector与监听器Acceptor
目录 muduo网络库学习笔记(五) 链接器Connector与监听器Acceptor Connector 系统函数connect 处理非阻塞connect的步骤: Connetor时序图 Accep ...
- muduo网络库学习笔记(四) 通过eventfd实现的事件通知机制
目录 muduo网络库学习笔记(四) 通过eventfd实现的事件通知机制 eventfd的使用 eventfd系统函数 使用示例 EventLoop对eventfd的封装 工作时序 runInLoo ...
- muduo网络库学习笔记(三)TimerQueue定时器队列
目录 muduo网络库学习笔记(三)TimerQueue定时器队列 Linux中的时间函数 timerfd简单使用介绍 timerfd示例 muduo中对timerfd的封装 TimerQueue的结 ...
- C++STL标准库学习笔记(三)multiset
C++STL标准库学习笔记(三)multiset STL中的平衡二叉树数据结构 前言: 在这个笔记中,我把大多数代码都加了注释,我的一些想法和注解用蓝色字体标记了出来,重点和需要关注的地方用红色字体标 ...
- 【python】numpy库和matplotlib库学习笔记
Numpy库 numpy:科学计算包,支持N维数组运算.处理大型矩阵.成熟的广播函数库.矢量运算.线性代数.傅里叶变换.随机数生成,并可与C++/Fortran语言无缝结合.树莓派Python v3默 ...
- C++STL标准库学习笔记(一)sort
前言: 近来在学习STL标准库,做一份笔记并整理好,方便自己梳理知识.以后查找,也方便他人学习,两全其美,快哉快哉! 这里我会以中国大学慕课上北京大学郭炜老师的<程序设计与算法(一)C语言程序设 ...
- pandas库学习笔记(二)DataFrame入门学习
Pandas基本介绍——DataFrame入门学习 前篇文章中,小生初步介绍pandas库中的Series结构的创建与运算,今天小生继续“死磕自己”为大家介绍pandas库的另一种最为常见的数据结构D ...
- libev事件库学习笔记
一.libev库的安装 因为个人的学习环境是在ubuntu 12.04上进行的,所以本节仅介绍该OS下的安装步骤. 使用系统工具自动化安装: sudo apt-get install libev-de ...
随机推荐
- Data Flow Diagram with Examples - Customer Service System
Data Flow Diagram with Examples - Customer Service System Data Flow Diagram (DFD) provides a visual ...
- 如何使用Markdown 编写文档
Markdown 是一种轻量级标记语言,用来编写文本文档,一般后缀名为.md.该语言在 2004 由约翰·格鲁伯(John Gruber)创建. 由于Markdown 语法简单,易读易写,变得越来越通 ...
- Redis(二):单机数据库的实现
概要 本部分内容主要是研究单机数据库.分别介绍单机数据库的实现原理,数据库的持久化,Redis事件,服务器维护管理客户端以及单机服务器的运作机制. 数据库 数据库结构 Redis数据库由redis.h ...
- windows右键没有新建选项的解决办法
1 以管理员身份运行cmd 2 cmd /k reg add "HKEY_CLASSES_ROOT\Directory\Background\shellex\ContextMenuHandl ...
- SQL Server 字段和对应的说明操作(SQL Server 2005 +)
为什么80%的码农都做不了架构师?>>> 添加说明 EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value ...
- bootstrap-分页-默认分页
说明 默认分页 示例 <!DOCTYPE html> <html lang="zh-CN"> <head> <meta c ...
- 初见Ajax——javascript访问DOM的三种访问方式
最近好啰嗦 最近在一间小公司实习,写一些小东西.小公司嘛,人们都说在小公司要什么都写的.果真是. 前端,后台,无论是HTML,CSS,JavaScript还是XML,Java,都要自己全包了.还好前台 ...
- 51NOD 2072 装箱问题 背包问题 01 背包 DP 动态规划
有一个箱子容量为 V(正整数,0<=V<=20000),同时有 n 个物品(0<n<=30),每个物品有一个体积(正整数). 现在在 n 个物品中,任取若干个装入箱内,使得箱子 ...
- 读CSV文件并写arcgis shp文件
一.在这里我用到的csv文件是包含x,y坐标及高程.降雨量数据的文件.如下图所示. 二.SF简介 简单要素模型(Simple Feature,SF),是 OGC 国际组织定义的面向对象的矢量数据模型. ...
- 【Spark】部署流程的深度了解
文章目录 Spark核心组件 Driver Executor Spark通用运行流程图 Standalone模式运行机制 Client模式流程图 Cluster模式流程图 On-Yarn模式运行机制 ...