Kd Tree算法详解
kd树(k-dimensional树的简称),是一种分割k维数据空间的数据结构,主要应用于多维空间关键数据的近邻查找(Nearest Neighbor)和近似最近邻查找(Approximate Nearest Neighbor)。
一、Kd-tree
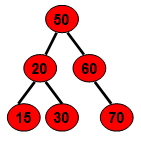
其实KDTree就是二叉查找树(Binary Search Tree,BST)的变种。二叉查找树的性质如下:
1)若它的左子树不为空,则左子树上所有结点的值均小于它的根结点的值;
2)若它的右子树不为空,则右子树上所有结点的值均大于它的根结点的值;
3)它的左、右子树也分别为二叉排序树;
例如:
如果我们要处理的对象集合是一个K维空间中的数据集,我们首先需要确定是:怎样将一个K维数据划分到左子树或右子树?
在构造1维BST树类似,只不过对于Kd树,在当前节点的比较并不是通过对K维数据进行整体的比较,而是选择某一个维度d,然后比较两个K维数据在该维度 d上的大小关系,即每次选择一个维度d来对K维数据进行划分,相当于用一个垂直于该维度d的超平面将K维数据空间一分为二,平面一边的所有K维数据 在d维度上的值小于平面另一边的所有K维数据对应维度上的值。也就是说,我们每选择一个维度进行如上的划分,就会将K维数据空间划分为两个部分,如果我 们继续分别对这两个子K维空间进行如上的划分,又会得到新的子空间,对新的子空间又继续划分,重复以上过程直到每个子空间都不能再划分为止。以上就是构造 Kd-Tree的过程,上述过程中涉及到两个重要的问题:
- 每次对子空间的划分时,怎样确定在哪个维度上进行划分;
- 在某个维度上进行划分时,怎样确保建立的树尽量地平衡,树越平衡代表着分割得越平均,搜索的时间也就是越少。
1、在哪个维度上进行划分?
一种选取轴点的策略是median of the most spread dimension pivoting strategy,统计样本在每个维度上的数据方差,挑选出对应方差最大值的那个维度。数据方差大说明沿该坐标轴方向上数据点分散的比较开。这个方向上,进行数据分割可以获得最好的平衡。
2、怎样确保建立的树尽量地平衡?
给定一个数组,怎样才能得到两个子数组,这两个数组包含的元素 个数差不多且其中一个子数组中的元素值都小于另一个子数组呢?方法很简单,找到数组中的中值(即中位数,median),然后将数组中所有元素与中值进行 比较,就可以得到上述两个子数组。同样,在维度d上进行划分时,划分点(pivot)就选择该维度d上所有数据的中值,这样得到的两个子集合数据个数就基本相同了。
二、Kd-Tree的构建
1)、在K维数据集合中选择具有最大方差的维度k,然后在该维度上选择中值m为pivot对该数据集合进行划分,得到两个子集合;同时创建一个树结点node,用于存储;
2)、对两个子集合重复(1)步骤的过程,直至所有子集合都不能再划分为止;
举个例子:
假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内(如下图中黑点所示)。kd树算法就是要确定图1中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)。下面就要通过一步步展示kd树是如何确定这些分割线的。
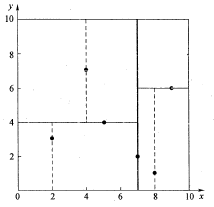
- 分别计算x,y方向上数据的方差,得知x方向上的方差最大;
- 根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以该node中的data = (7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于x轴的直线x = 7;
- 确定左子空间和右子空间。分割超平面x = 7将整个空间分为两部分,如下图所示。x < = 7的部分为左子空间,包含3个节点{(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点{(9,6),(8,1)}。
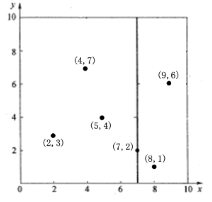
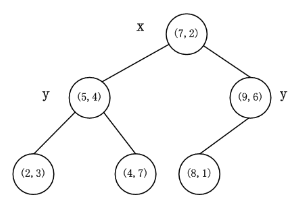
k-d树的构建是一个递归的过程。然后对左子空间和右子空间内的数据重复根节点的过程就可以得到下一级子节点(5,4)和(9,6)(也就是左右子空间的'根'节点),同时将空间和数据集进一步细分。如此反复直到空间中只包含一个数据点,如下图所示:
三、Kd-Tree的最近邻查找
- (1)将查询数据Q从根结点开始,按照Q与各个结点的比较结果向下访问Kd-Tree,直至达到叶子结点。
其中Q与结点的比较指的是将Q对应于结点中的k维度上的值与中值m进行比较,若Q(k) < m,则访问左子树,否则访问右子树。达到叶子结点时,计算Q与叶子结点上保存的数据之间的距离,记录下最小距离对应的数据点,记为当前最近邻点nearest和最小距离dis。 - (2)进行回溯操作,该操作是为了找到离Q更近的“最近邻点”。即判断未被访问过的分支里是否还有离Q更近的点,它们之间的距离小于dis。
如果Q与其父结点下的未被访问过的分支之间的距离小于dis,则认为该分支中存在离P更近的数据,进入该结点,进行(1)步骤一样的查找过程,如果找到更近的数据点,则更新为当前的最近邻点nearest,并更新dis。
如果Q与其父结点下的未被访问过的分支之间的距离大于dis,则说明该分支内不存在与Q更近的点。
回溯的判断过程是从下往上进行的,直到回溯到根结点时已经不存在与P更近的分支为止。
注:判断未被访问过的树分支中是否还有离Q更近的点,就是判断"Q与未被访问的树分支的距离|Q(k) - m|"是否小于"Q到当前的最近邻点nearest的距离dis"。从几何空间上来看,就是判断以Q为中心,以dis为半径超球面是否与未被访问的树分支代表的超矩形相交。
下面举两个例子来演示一下最近邻查找的过程。
假设我们的kd树就是上面通过样本集{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}创建的。
例1:查找点Q(2.1,3.1)
如下图所示,红色的点即为要查找的点。通过图4二叉搜索,顺着搜索路径很快就能找到当前的最邻近点(2,3)。
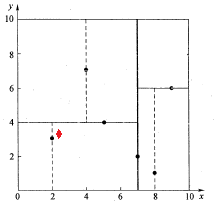
在上述搜索过程中,产生的搜索路径节点有<(7,2),(5,4),(2,3)>。为了找到真正的最近邻,还需要进行'回溯'操作,首先以(2,3)作为当前最近邻点nearest,计算其到查询点Q(2.1,3.1)的距离dis为0.1414,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点Q更近的数据点。以(2.1,3.1)为圆心,以0.1414为半径画圆,如图6所示。发现该圆并不和超平面y = 4交割,即这里:|Q(k) - m|=|3.1 - 4|=0.9 > 0.1414,因此不用进入(5,4)节点右子空间中去搜索。
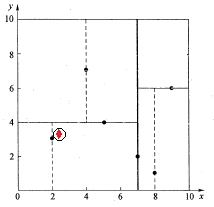
再回溯到(7,2),以(2.1,3.1)为圆心,以0.1414为半径的圆更不会与x = 7超平面交割,因此不用进入(7,2)右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2,3),最近距离为0.1414。
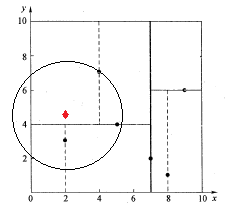
例2:查找点Q(2,4.5)
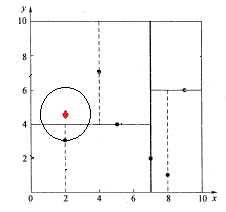
如下图所示,同样经过图4的二叉搜索,可得当前的最邻近点(4,7),产生的搜索路径节点有<(7,2),(5,4),(4,7)>。首先以(4,7)作为当前最近邻点nearest,计算其到查询点Q(2,4.5)的距离dis为3.202,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点Q更近的数据点。以(2,4.5)为圆心,以为3.202为半径画圆,如图7所示。发现该圆和超平面y = 4交割,即这里:|Q(k) - m|=|4.5 - 4|=0.5 < 3.202,因此进入(5,4)节点右子空间中去搜索。所以,将(2,3)加入到搜索路径中,现在搜索路径节点有<(7,2), (2, 3)>。同时,注意:点Q(2,4.5)与父节点(5,4)的距离也要考虑,由于这两点间的距离3.04 < 3.202,所以将(5,4)赋给nearest,并且dist=3.04。
接下来,回溯至(2,3)叶子节点,点Q(2,4.5)和(2,3)的距离为1.5,比距离(5,4)要近,所以最近邻点nearest更新为(2,3),最近距离dis更新为1.5。回溯至(7,2),如图8所示,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,即这里:|Q(k) - m|=|2 - 7|=5 > 1.5。至此,搜索路径回溯完。返回最近邻点(2,3),最近距离1.5。
四、总结
Kd树在维度较小时(比如20、30),算法的查找效率很高,然而当数据维度增大(例如:K≥100),查找效率会随着维度的增加而迅速下降。假设数据集的维数为D,一般来说要求数据的规模N满足N>>2的D次方,才能达到高效的搜索。
为了能够让Kd树满足对高维数据的索引,Jeffrey S. Beis和David G. Lowe提出了一种改进算法——Kd-tree with BBF(Best Bin First),该算法能够实现近似K近邻的快速搜索,在保证一定查找精度的前提下使得查找速度较快。
Kd Tree算法详解的更多相关文章
- Merkle Tree算法详解
转载自:http://blog.csdn.net/yuanrxdu/article/details/22474697Merkle Tree是Dynamo中用来同步数据一致性的算法,Merkle Tre ...
- [Network Architecture]DPN(Dual Path Network)算法详解(转)
https://blog.csdn.net/u014380165/article/details/75676216 论文:Dual Path Networks 论文链接:https://arxiv.o ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- Ext.Net学习笔记22:Ext.Net Tree 用法详解
Ext.Net学习笔记22:Ext.Net Tree 用法详解 上面的图片是一个简单的树,使用Ext.Net来创建这样的树结构非常简单,代码如下: <ext:TreePanel runat=&q ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
随机推荐
- (转)logback配置详解
找到一篇很详细的关于logback配置的介绍: 贴上原文链接:logback使用配置详解 1.介绍 Logback是由log4j创始人设计的另一个开源日志组件,它当前分为下面下个模块: logback ...
- localStorage和cookie的跨域解决方案
原文转自:点我 前言 localStorage和cookie大家都用过,我前面也有文章介绍过,跨域大家也都了解,我前面也有文章详细描述过.但是localStorage和cookie的跨域问题,好多小伙 ...
- ACM思维题训练 Section A
题目地址: 选题为入门的Codeforce div2/div1的C题和D题. 题解: A:CF思维联系–CodeForces -214C (拓扑排序+思维+贪心) B:CF–思维练习-- CodeFo ...
- 题目分享Q
题意:给出一个N个点的树,找出一个点来,以这个点为根的树时,所有点的深度之和最大 分析:这可以说是换根法的裸题吧 首先考虑对一个给定的根如何计算,这应该是最简单的那种树形dp吧甚至可能都不算dp(好像 ...
- 服务器3C直连网络好呢还是3C精品网络更好呢?
3C直连网络:通过用自有AS号与中国电信CTcc,中国联通CUcc,中国移动CMcc企业网进行直接接驳,提供对大陆方向有更高要求的网络接入服务. 简称:国内3c直连. 3C精品专线网:在3C直连基础上 ...
- [NBUT 1224 Happiness Hotel 佩尔方程最小正整数解]连分数法解Pell方程
题意:求方程x2-Dy2=1的最小正整数解 思路:用连分数法解佩尔方程,关键是找出√d的连分数表示的循环节.具体过程参见:http://m.blog.csdn.net/blog/wh2124335/8 ...
- 【hdu1030】“坐标表示法”
http://acm.hdu.edu.cn/showproblem.php?pid=1030 算法:以顶点为原点,建立坐标系,一个数可以唯一对应一个三元组(x, y, z),从任意一个点出发走一步,刚 ...
- linux-设置代理和取消代理
设置代理: export http_proxy="http://proxy-XXXXX" export https_proxy="https://proxy-XXXXX: ...
- css3 文字处理
text-overflow:ellipsis;超出的文字显示...前提是该盒子必须有overflow:hidden;属性 text-shadow 文字阴影 direction:控制文字方向,值有dow ...
- 谈谈Java常用类库中的设计模式 - Part Ⅰ
背景 最近一口气看完了Joshua Bloch大神的Effective Java(下文简称EJ).书中以tips的形式罗列了Java开发中的最佳实践,每个tip都将其意图和要点压缩在了标题里,这种做法 ...