CentOS7虚拟机配置、Hadoop搭建、wordCount DEMO运行
安装虚拟机
最开始先安装虚拟机,我是12.5.7版本,如果要跟着我做的话,版本最好和我一致,不然后面可能会出一些莫名其妙的错误,下载链接如下(注册码也在里面了):
链接:https://pan.baidu.com/s/1qoqeKcgMsjFKPFQFBFP6lg
提取码:2aog
安装虚拟机直接下一步、下一步就好了,没什么可说的,安装好后,虚拟机询问是否更新,点不更新,更新了就改版本了。
配置虚拟机操作系统
接下来开始配置虚拟机系统。
首先下载CentOS7的镜像,下载链接如下:
链接:https://pan.baidu.com/s/17Guf4e0LKH2KfOgBlgBnNA
提取码:skvu
然后打开虚拟机:文件——新建虚拟机,打开新建虚拟机向导(然后配置如下):


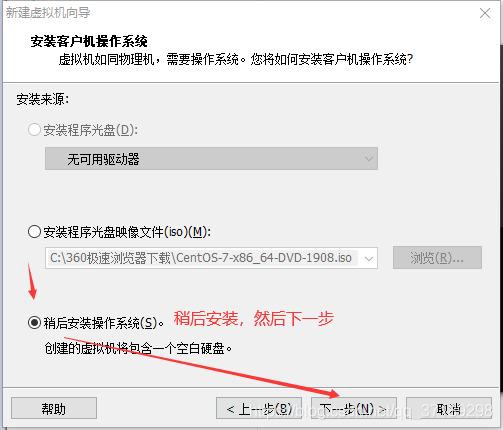

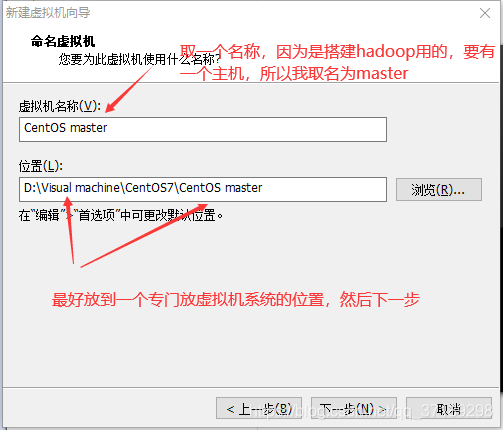


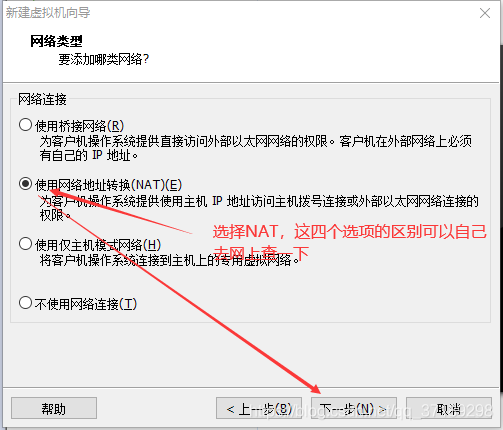
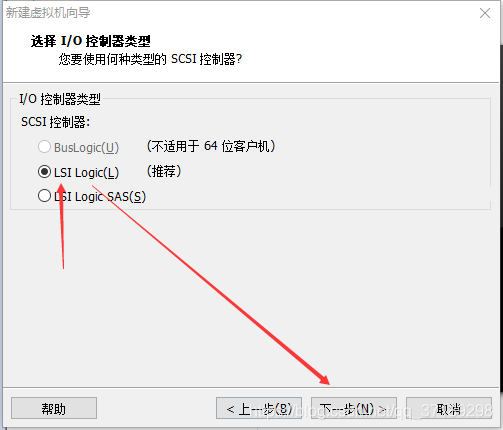
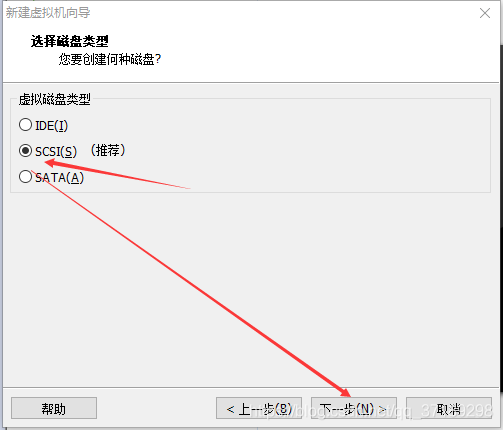
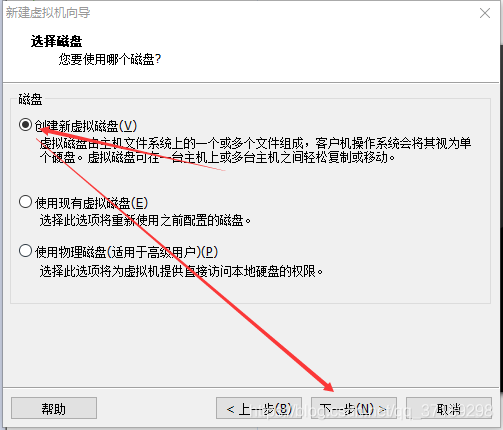
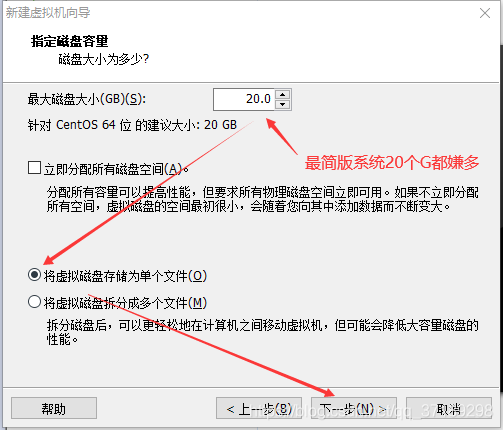
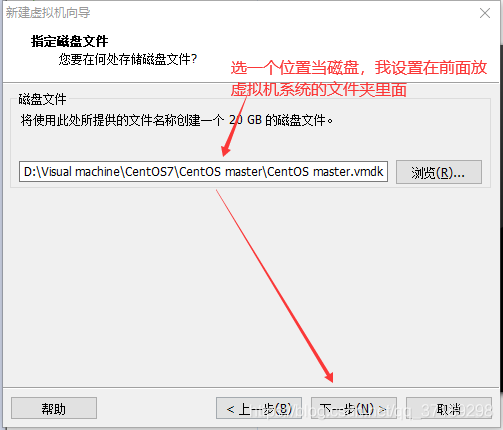
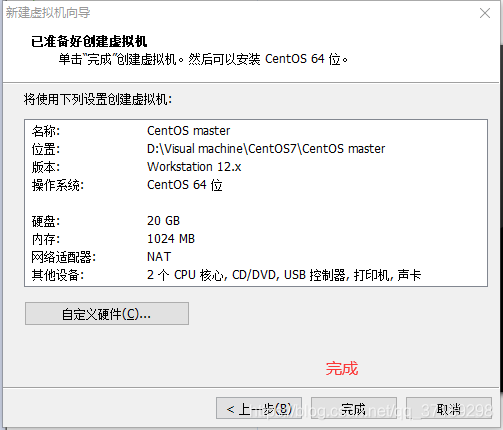
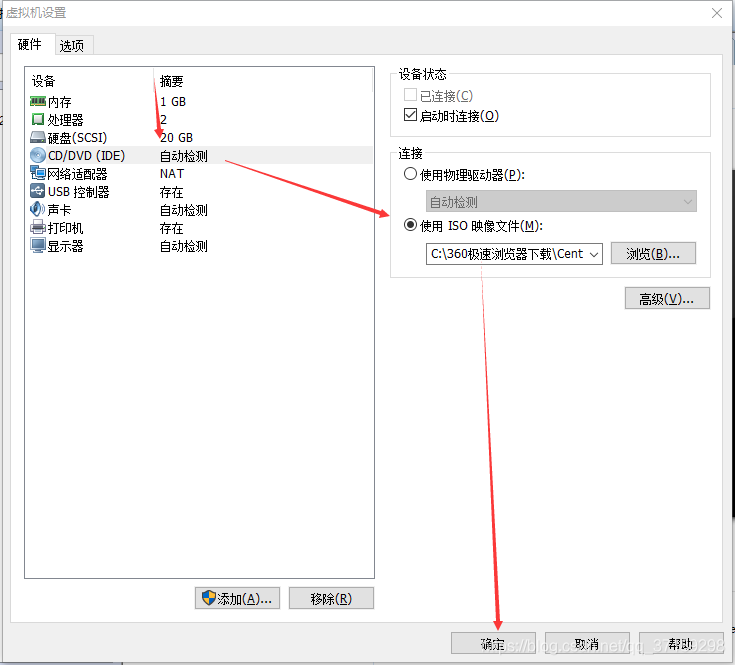
虚拟机向导完毕后,在左边出现一个虚拟机选项:右键设置——CD/DVD(IDE)——使用ISO映像文件——浏览,选择前面下载好的CentOS7镜像——确定:
点击开启此虚拟机:
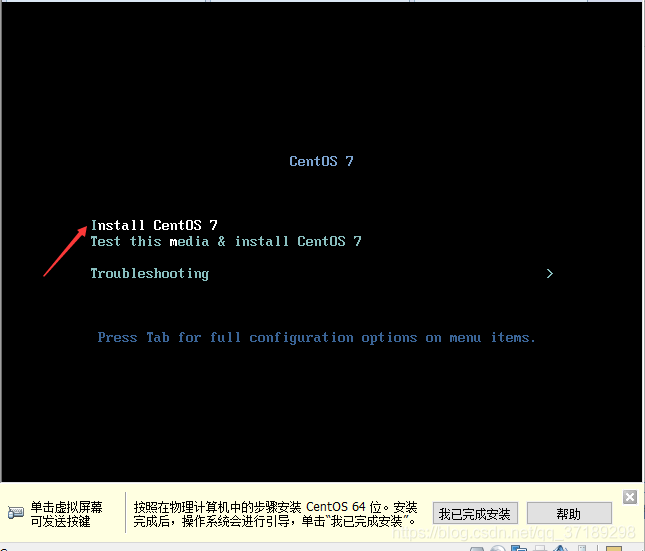
进入操作系统安装界面,选择Install CentOS 7,回车:
待会还有一个回车要按,也可以等待一会它自动确认,然后会启动安装程序:

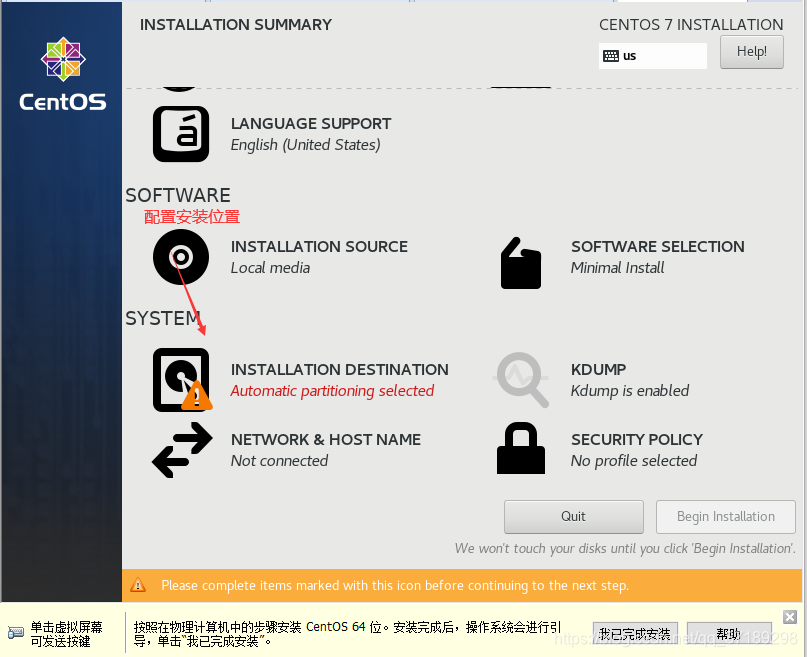
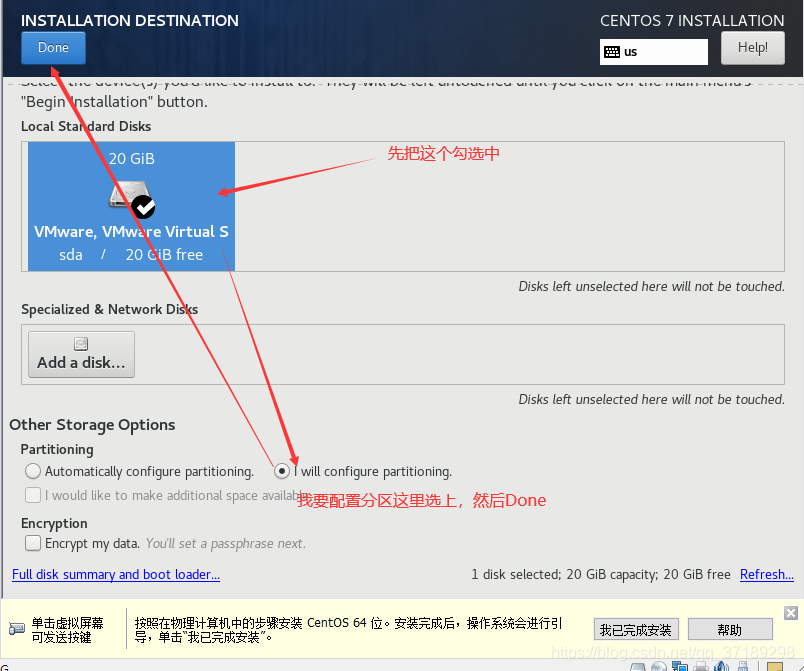
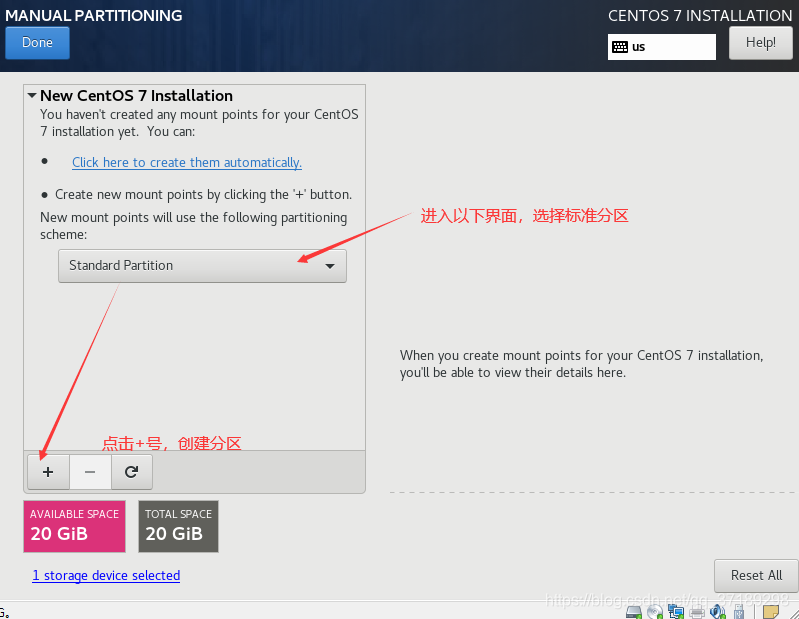

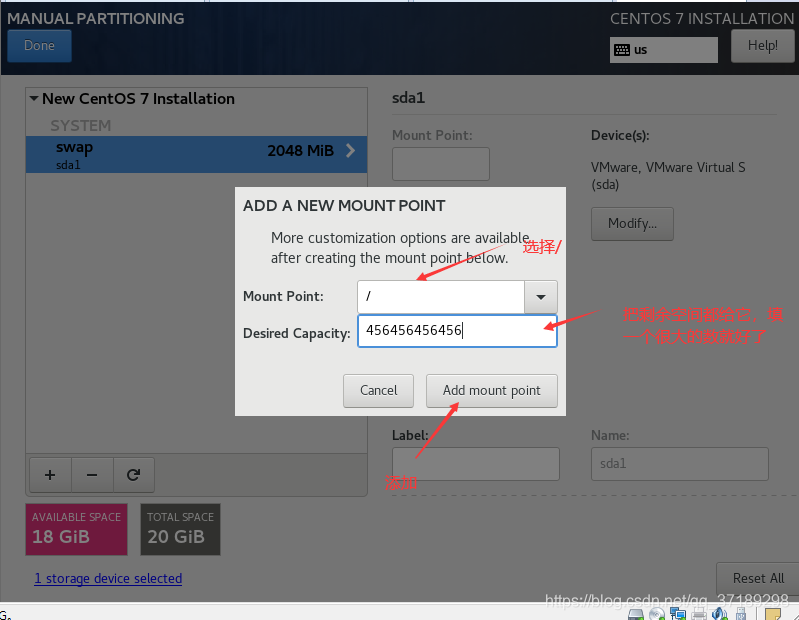
然后再点+号,添加另一个分区:
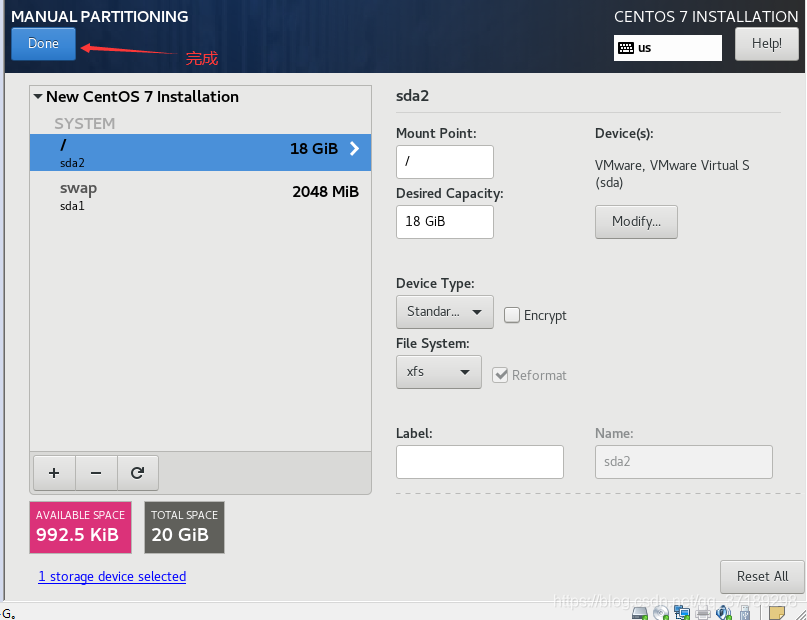
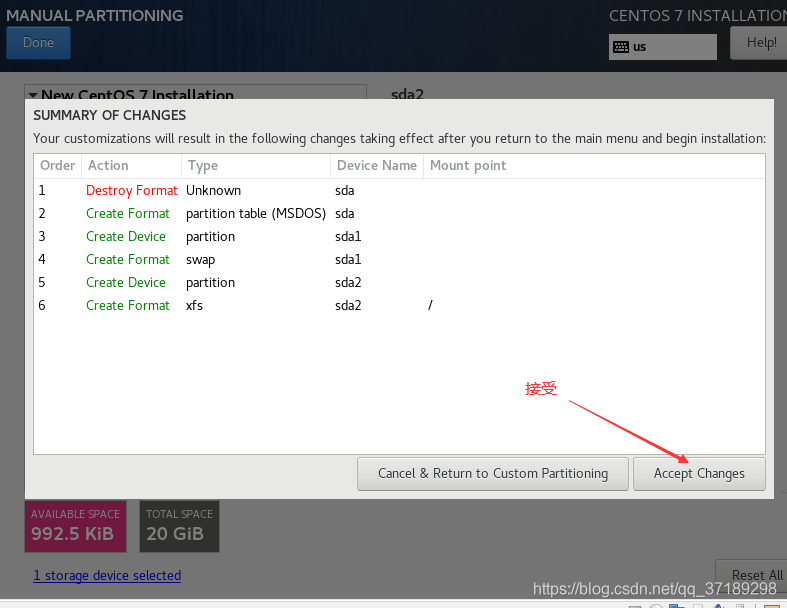
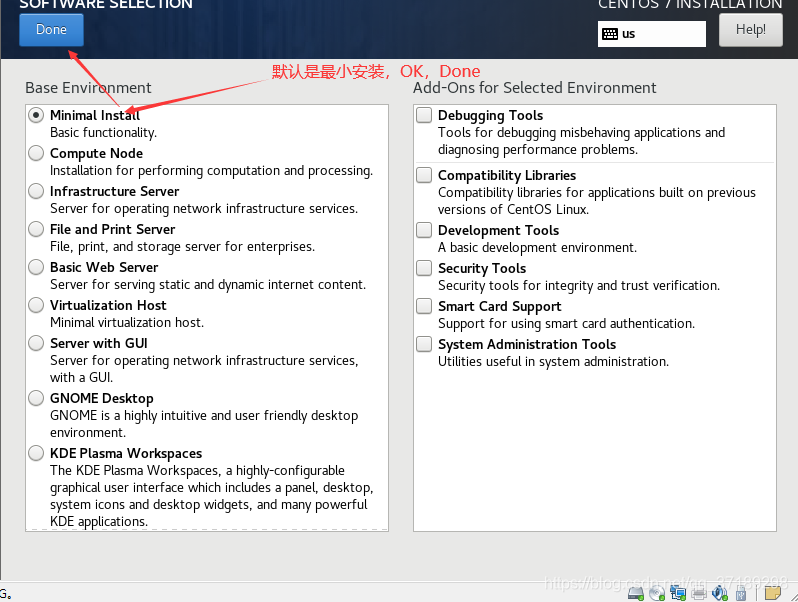



虚拟机系统安装完毕!重启后打开系统:
输入root用户名,回车,密码(就是你刚刚创建的密码),回车:
用root用户进入操作系统界面(root用户是权限最高的用户,所以执行一些指令都不需要sudo):

配置虚拟机静态NAT网络
接下来配置虚拟机的网络。
首先右键你的CentOS虚拟机——设置——网络适配器,右边网络连接选项卡中选择:NAT模式或自定义中的VMnet8,将操作系统网络设置为网络地址转换(NAT)模式,这两种选择的效果是一样的,都是通过VMnet8与物理主机互连,然后点击确定(我这里选择NAT模式选项)。

设置好后,在虚拟机界面:编辑——虚拟网络编辑器,点击右下角的更改设置,修改NAT模式的子网等配置。操作如下两张图图:

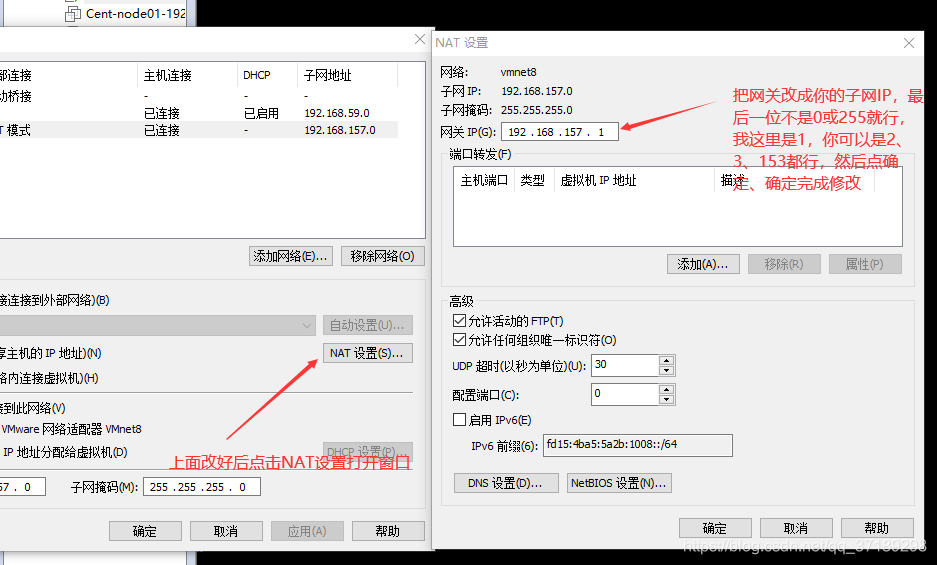
然后在主机windows界面:网络——属性——更改适配器设置,看到里面有个VMware Network Adapter VMnet8,是虚拟器自动生成的,右键它——属性——网络选项卡——点中Internet协议版本4(TCP/IPv4)——属性,修改如下图:
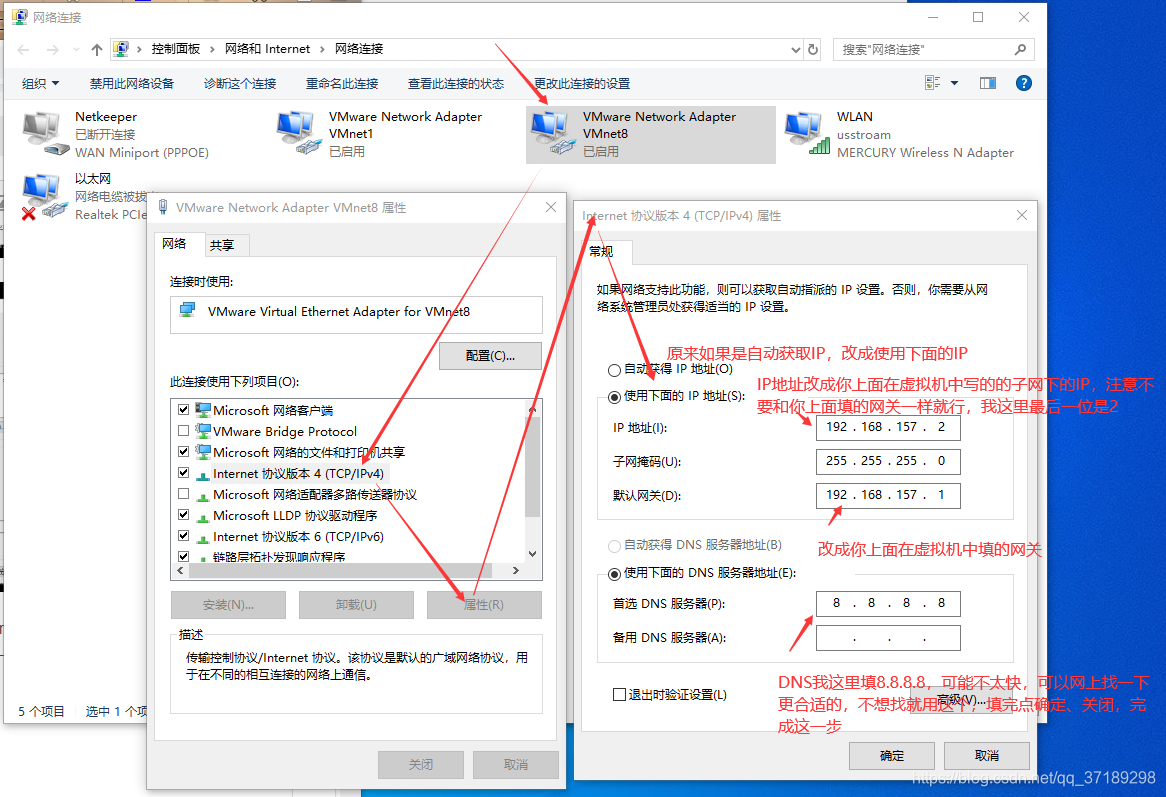
外部配置好了,现在开始配置虚拟机内CentOS的静态网络。
打开虚拟机进入CentOS的命令界面,登录Root用户,输入ip addr查看网卡名称:
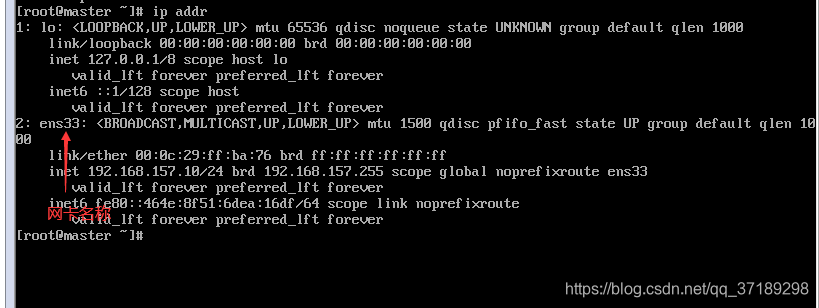
接着输入vi /etc/sysconfig/network-scripts/ifcfg-ens33(ens33是网卡名称,如果你的不是ens33,就改成你的网卡名称)(vi是使用一个编辑器的命令,vi 后面加一些文本类文件可以打开它进行编辑),进入网络配置文件修改配置,按键盘Insert键进入编辑模式 ,修改如下图:

修改好后按ESC,从编辑模式进入命令模式,输入:wq(w代表write,q代表quit,如输入:q不保存直接退出)再按回车回到命令界面,不要忘记冒号“:”,如果冒号没打,按w会进入recording模式记录你的键盘操作,按q退出这个模式,再重新打:wq就行。
然后在命令界面输入service network restart,重新启动网络服务:

再接着输入网址,如ping www.baidu.com,就能联网了:
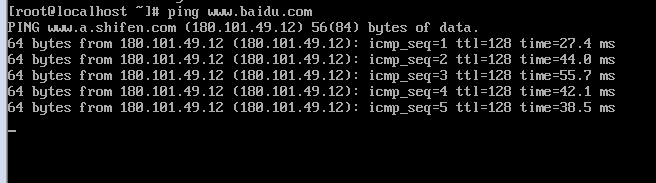
按键盘Ctrl+C退出联网,回到命令行:
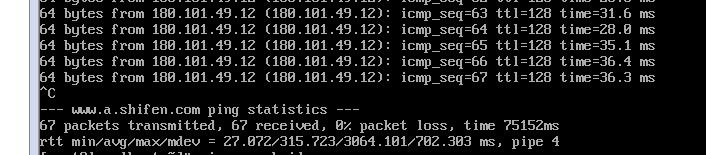
还可以再试一试ping你刚刚填的VMnet8的IP地址,如我这里ping 192.168.157.2
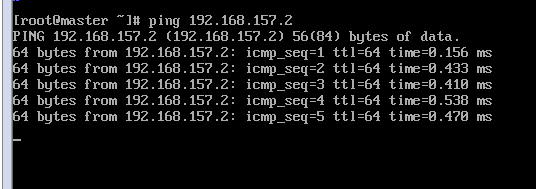
在Windows主机打开CMD也可以ping 虚拟机的IP试试,我这里ping 192.168.157.10
可以看到三个ping都成功了,说明1、虚拟机能连接外网。2、虚拟机能和物理主机互连。3、物理主机能和虚拟机互连。这样,一个CentOS的静态NAT网络就算配置完成了。
ifconfig命令和ip addr命令差不多,也可以查看ip等信息,然而操作系统没有这个命令,因为新安装的Minimal系统中并没有装这个命令,可以用yum install net-tools.x86_64命令从网上下载安装。
讲一个坑,害我找了半天的原因。虚拟机系统有时候会出错,关闭不了,甚至直接用任务管理器关闭都不行,再次打开虚拟机那个系统还是被占用不能打开。如果系统里没有保存什么重要的文件,或者有备份的话,就直接把那个系统移除了并在物理主机把它的文件删了一劳永逸。而原来我在网上找了一个方法,说在外部windows的运行中输入msconfig,打开启动项,直接把VMware的服务全都停止了,然后系统会变好,其实并没有用。这些服务中包含了VMware NAT service,一旦停了,虚拟机就不能通过NAT联外部网络了(不能ping www.baidu.com连接外部网络,但是还能ping局域网IP如192.168.157.2),导致我后来浪费好几个小时在这上面。
CentOS主机名修改
接下来进行CentOS的主机名修改。
这里面有三个“主机名”容易弄混淆:hosts文件保存的主机名、hostname文件保存的主机名、network文件保存的主机名。
hosts保存的是IP地址和域名的对应,比如局域网里有个主机域名叫node1,它的ip是192.168.3.3,那你保存这个对应进去以后,ping node1就等于ping 192.168.3.3。
network里面保存的就主机域名,现在暂时看不出啥用,因为hosts里面的域名不都是自己写的吗,和别的主机取域名叫啥好像没啥关系,但是为了便于辨认,就要修改。
hostname保存的是你这个操作系统的名称,自己看的名称而已,与网络没什么关系,为了辨认最好修改成和network里面的域名一样。
分别这样修改(vim是vi的升级版,没有这个命令就yum -y install vim安装一下):
network:


hosts:


hostname:

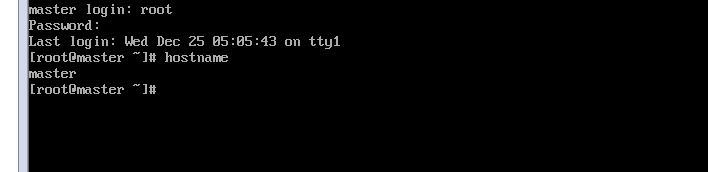
改好名以后关闭防火墙,用systemctl stop firewalld 关闭,systemctl disable firewalld 取消防火墙开机启动(复制会出错,最好自己打,一模一样都会出错,我都奇怪了)。reboot重启机器,进入root用户,再输入hostname,可以看到主机名是master:
CentOS安装JDK
系统配置完毕,现在给系统安装JDK(Java SE Development Kit)。因为是最简的系统,所以不能用图形界面,我们可以使用物理windows主机下载好jdk传给虚拟机来安装。传入文件的软件要用到XShell和XFtp。
Xshell和XFtp下载链接:
链接:https://pan.baidu.com/s/1dsLbd5pDZcSXqy1K5M_0qQ
提取码:y80z
XFtp是直接用的,无需安装,但是在用之前要先双击一下里面的绿化(重要,别忘了),把XFtp破解一下,并且它会把注册表信息写进去,这样在XShell里面要用XFtp的时候才会自动打开XFtp。
XShell需要安装,直接下一步下一步就好了。
安装好后打开Xshell:文件——新建,填入虚拟机系统的IP点击确定就可以实现和虚拟机系统的连接(当然虚拟机系统要打开进入root用户)。
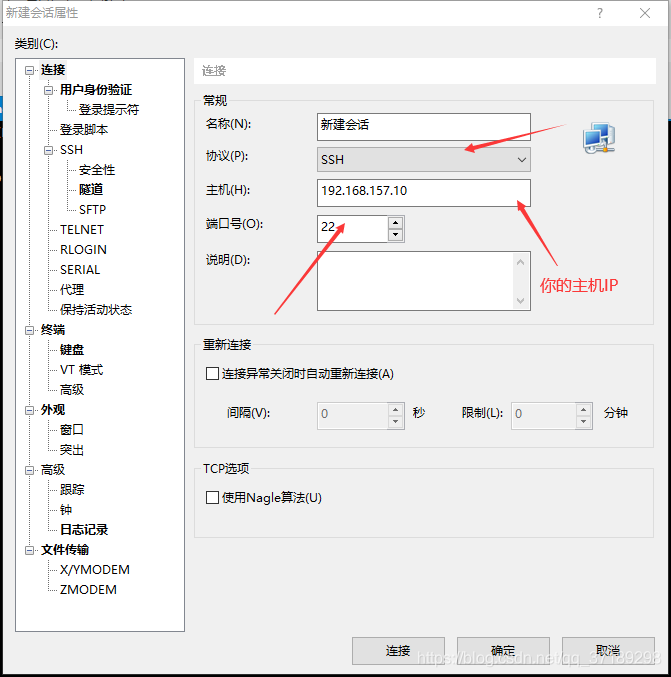
双击新建会话:

root用户,然后输入操作系统的密码,确定,连接完毕!界面和虚拟机里面的命令行一模一样,但是可以复制和粘贴代码哦~

连接好了以后,就可以点击上方的绿色按钮,Xshell会打开电脑中安装好的XFtp,让XFtp和虚拟机的操作系统连接,并且可以传输文件。(Xshell和XFtp是同一家公司出的,所以可以相互调用,但是我很奇怪都是连接操作系统,为什么不把功能集中到一个软件)
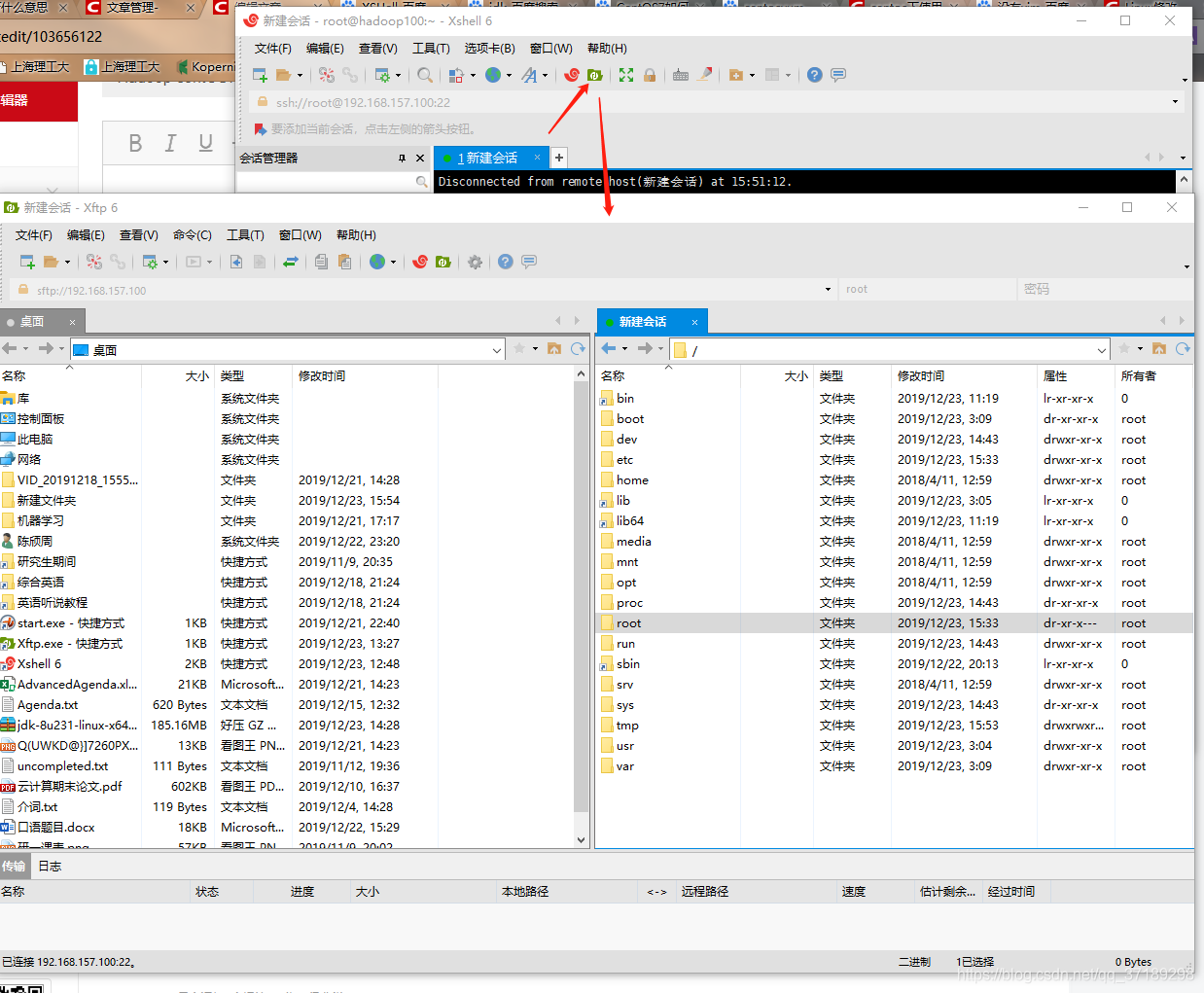
然后使用mkdir命令在/usr/local/里面创建一个java文件夹,其实也可以直接用XFtp进行创建,特别方便,就和图形界面一样:
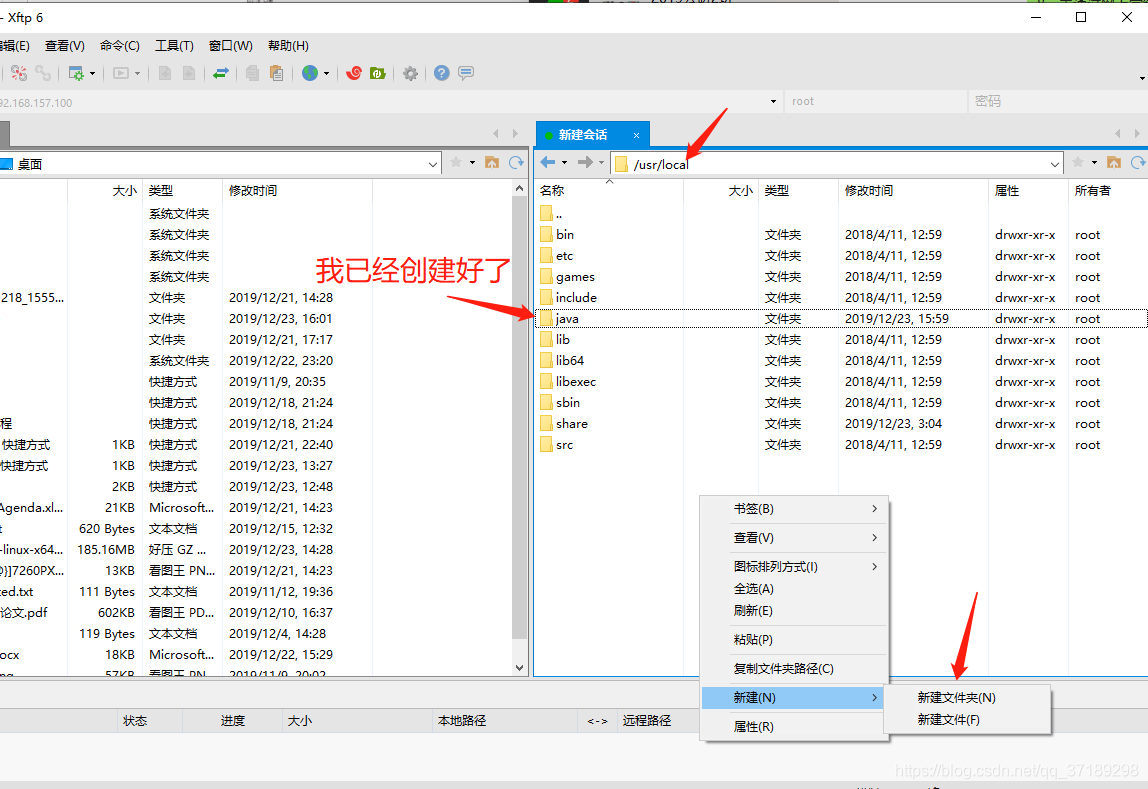
然后把下载好的JDK压缩包拖进Java文件夹。我的使用的JDK包:
链接:https://pan.baidu.com/s/1jxsH25gdGTw1AK_yD24C8w
提取码:wifb
然后在命令行中(虚拟机命令行或Xshell里都行)cd /usr/local/java进入java文件夹,tar -xvf jdk-8u231-linux-x64.tar.gz解压JDK,-xvf后面的名称对应的是你下载的JDK压缩包名称,如果使用的是我的JDK包,那就一样,别复制错了(后面版本问题我都不再提醒了,包括hadoop、mysql、mysql-connector-java等等,其中mysql和mysql-connector-java版本是有对应的,这是大坑,如果你的两个版本不对应的话,后面出错原因会很难找到,所以这些版本什么都和我一致最好,链接都提供了呢,这么良心的博主哪里找)。
解压好后, rm -rf jdk-8u221-linux-x64.tar.gz删除原来的压缩包(强迫症,你不删除也行),当然在XFtp中也能右键删除。
然后配置环境,vim /etc/profile编辑文件,在最后一行加上:

加上以后ESC,然后:wq回车,退出编辑,在命令行里输入source /etc/profile,编译刚刚改过的文件,就完成JDK的配置了。
然后可以用 java -version 和javac -version 命令测试JDK是否成功安装:

配置安装hadoop
JDK装好了,现在正式开始装hadoop。
先下载hadoop镜像,链接:
链接:https://pan.baidu.com/s/17h4kxK9RoqjNE0mIHpsReQ
提取码:nujr
在local下面创建hadoop文件夹,把镜像拖进里面,tar -zxvf hadoop,tab键,自动出现剩余的压缩包名称,解压tar包,然后删除压缩包。
vim /etc/profile修改环境变量:
HADOOP_HOME=/usr/local/hadoop/hadoop-2.8.5
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin

:wq保存并退出编辑,source /etc/profile,编译刚刚的配置,然后在命令行输入hado,按Tab键,如果自动补全为hadoop,说明配置好了。
然后在hadoop下创建四个文件夹,分别是tmp、hdfs、name和data,name在hdfs下,命令如下:
mkdir /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/hdfs/name
mkdir /usr/local/hadoop/hdfs/data
接下来进入hadoop文件 /etc/hadoop 目录,命令:
cd /usr/local/hadoop/hadoop-2.8.5/etc/hadoop
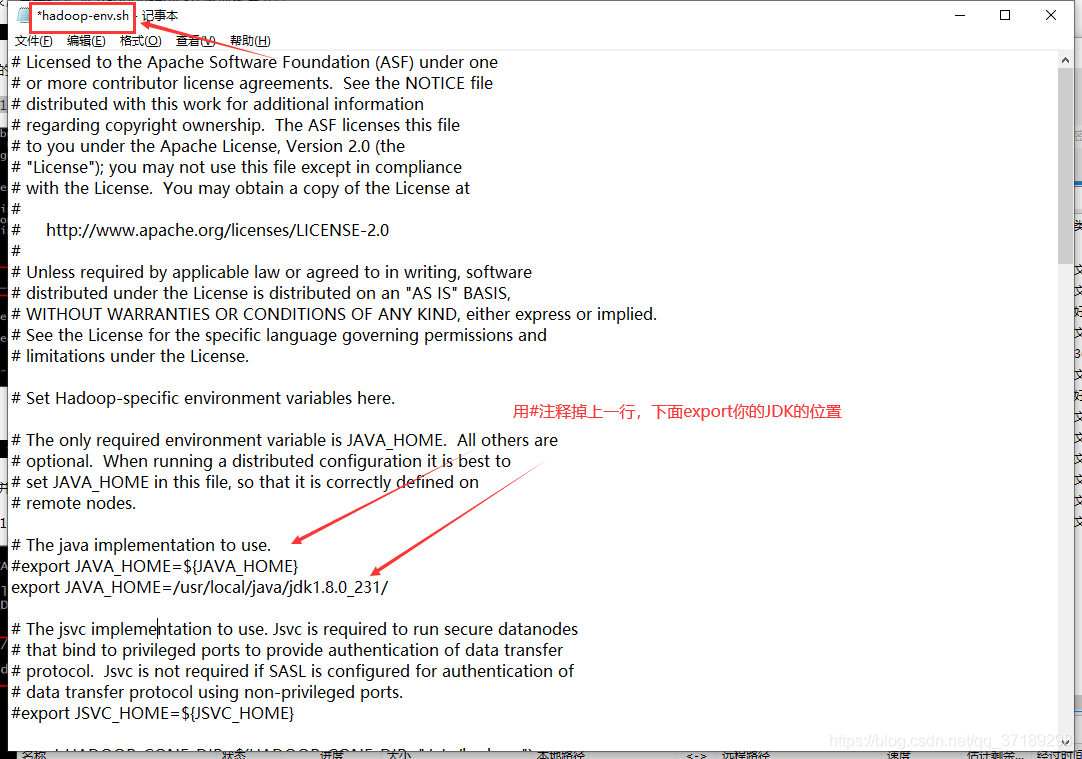
里面存放的是hadoop的配置文件,要修改一些配置,分别是hadoop-env.sh、yarn-env.sh、core-site.xml 、hdfs-site.xml,如下(我直接通过XFtp修改了,你也可以用命令行修改):
export JAVA_HOME=/usr/local/java/jdk1.8.0_231/

<!-- 插入core-site.xml的代码 -->
<property>
<name> fs.default.name </name>
<value>hdfs://master:9000</value>
<description>指定HDFS的默认名称</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>节点上本地的hadoop临时文件夹</description>
</property>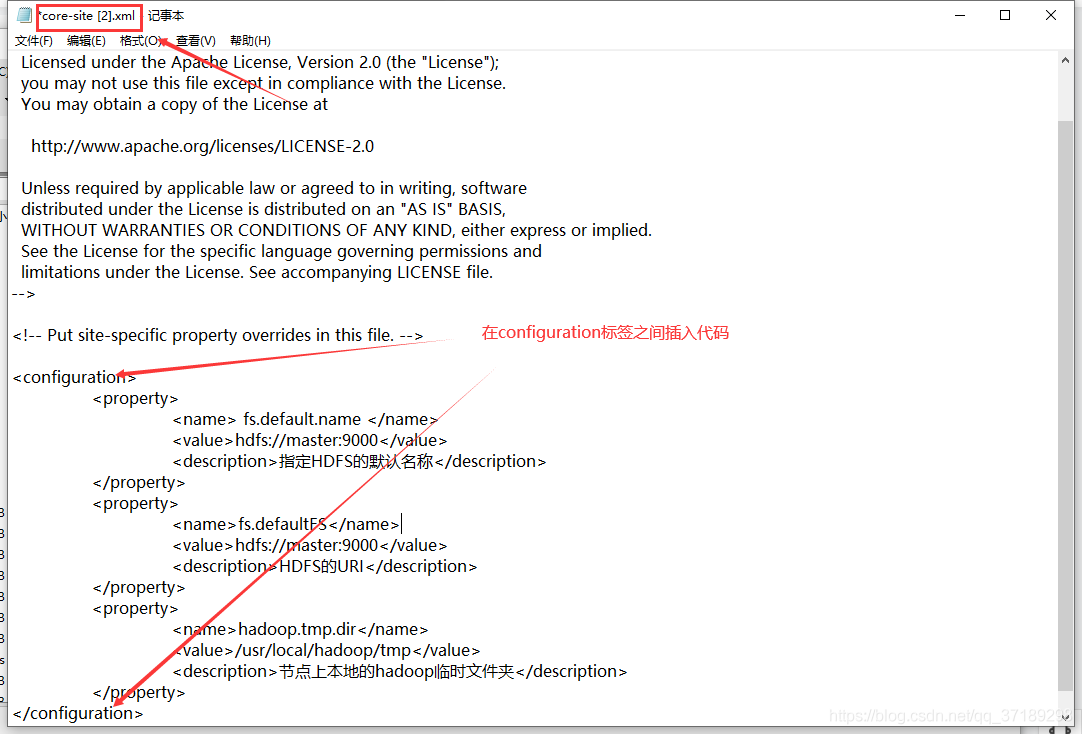
<!-- 插入hdfs-site.xml的代码 -->
<property>
<name> fs.default.name </name>
<value>hdfs://master:9000</value>
<description>指定HDFS的默认名称</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>节点上本地的hadoop临时文件夹</description>
</property>
改好文件后,还是在/usr/local/hadoop/hadoop-2.8.5/etc/hadoop目录,输入cp mapred-site.xml.template mapred-site.xml,将mapred-site.xml.template文件复制到当前目录,并重命名为mapred-site.xml。
然后继续修改mapred-site.xml文件:
<!-- 插入mapred-site.xml的代码 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>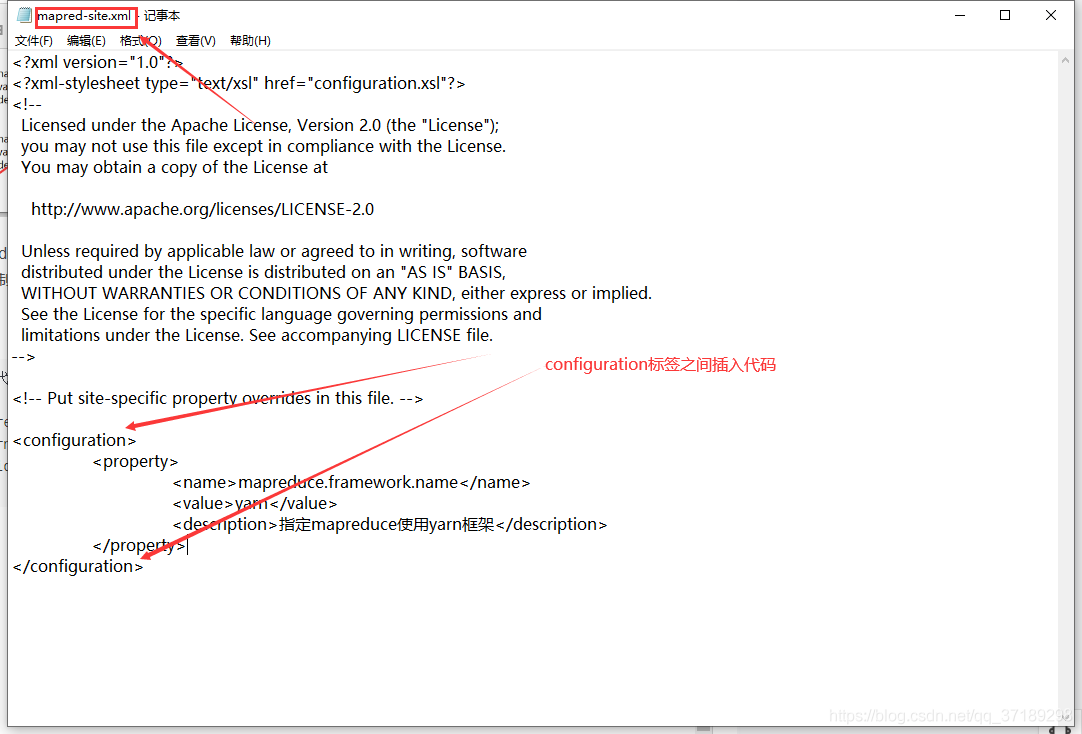
接着修改yarn-site.xml 文件:
<!-- 插入yarn-site.xml的代码 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>
NodeManager上运行的附属服务。
需配置成mapreduce_shuffle,才可运行MapReduce程序
</description>
</property>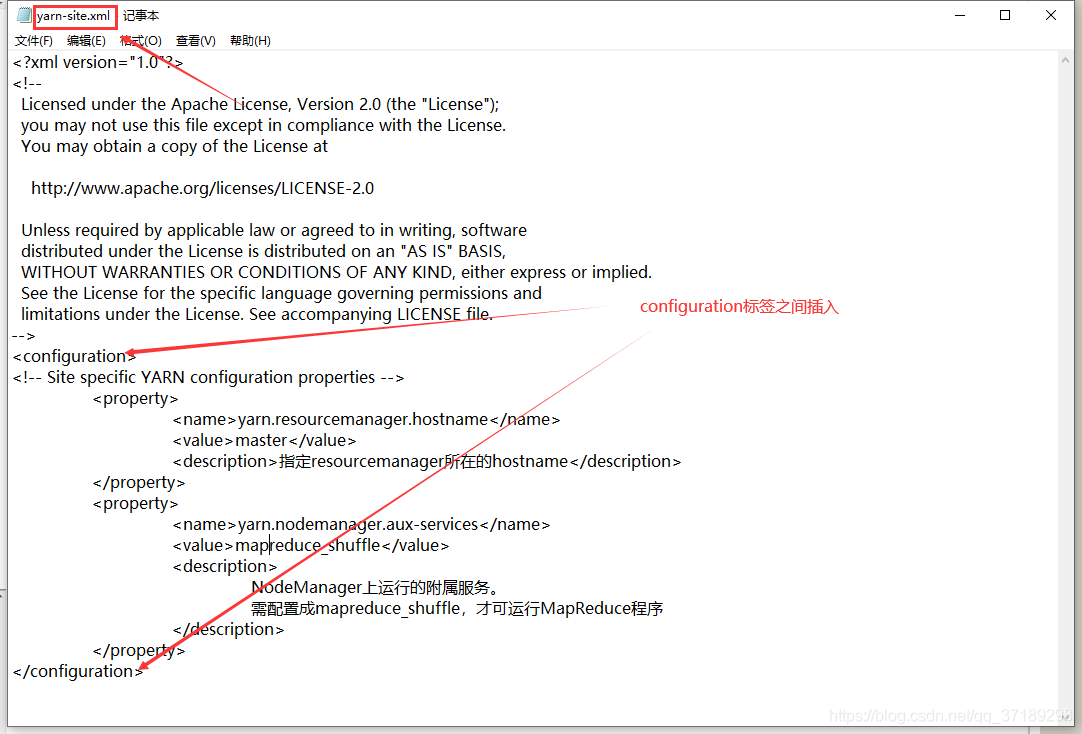
最后修改slaves文件:

现在一台主机弄好了,现在添加其他的节点虚拟机系统。
在虚拟机中,右键虚拟主机,管理——克隆,打开克隆虚拟机向导:

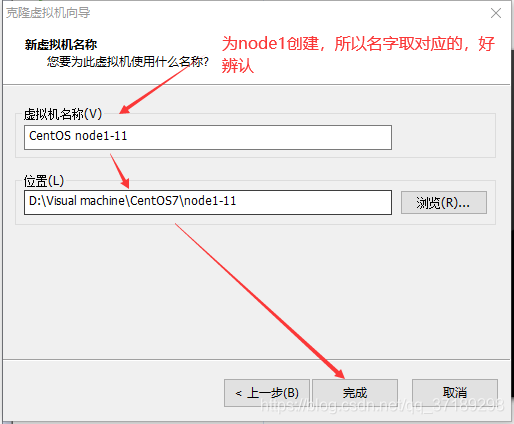
克隆好node1后,右键node1虚拟机,设置——网络适配器
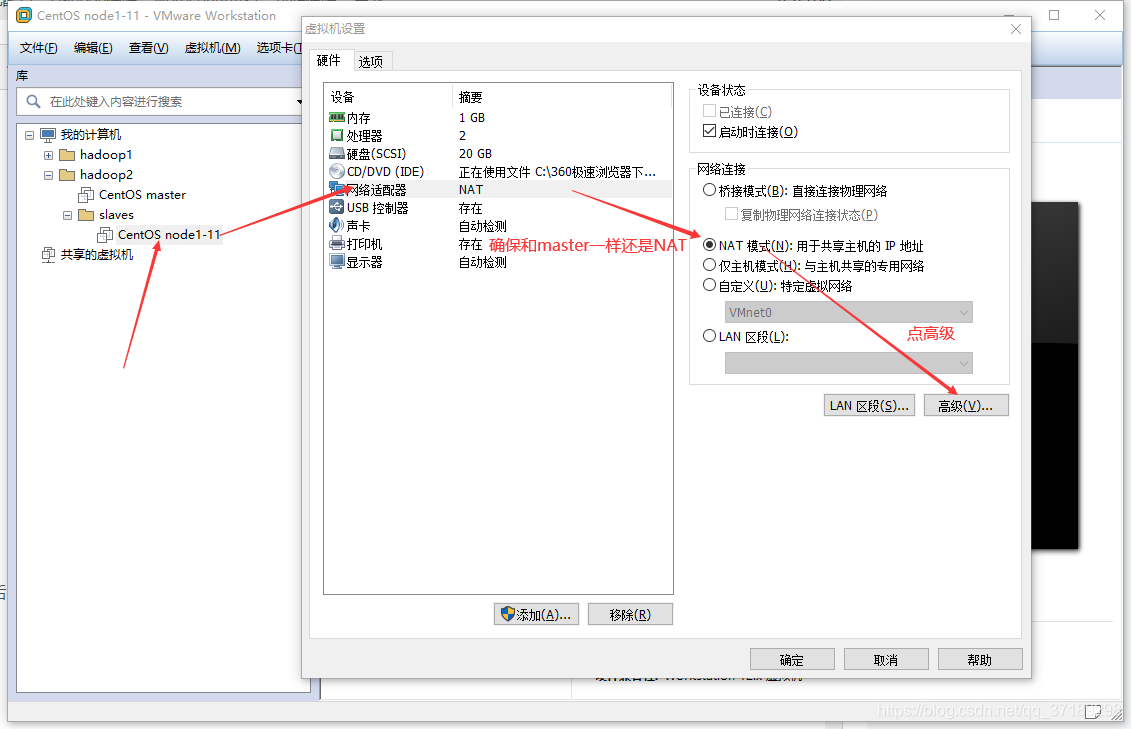

点击确定,回到虚拟机主界面,打开node1,因为是克隆master,所以用户名密码都是一样的,命令行的记录都还在。现在要修改三个文件:ifcfg-ens33、network、hostname,命令忘了就按键盘的上往前翻,改完ESC,:wq保存并退出:


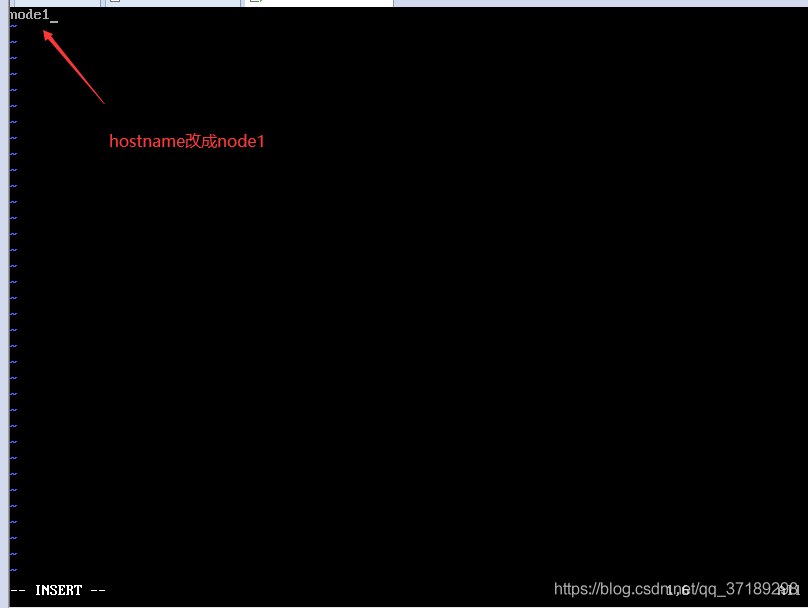
改完输入reboot,重启一下,可以看到机器名变node1了,能ping百度还有外部主机(192.168.157.2)了,你如果把master打开也能ping的通:

node1克隆、配置好后,同样的克隆、配置一下node2:物理地址重新生成一下,把ifcfg-ens33、hostname、network对应的地方改一下,重启一下,OK!
最后配置ssh,打开master、node1、node2,登录root用户。
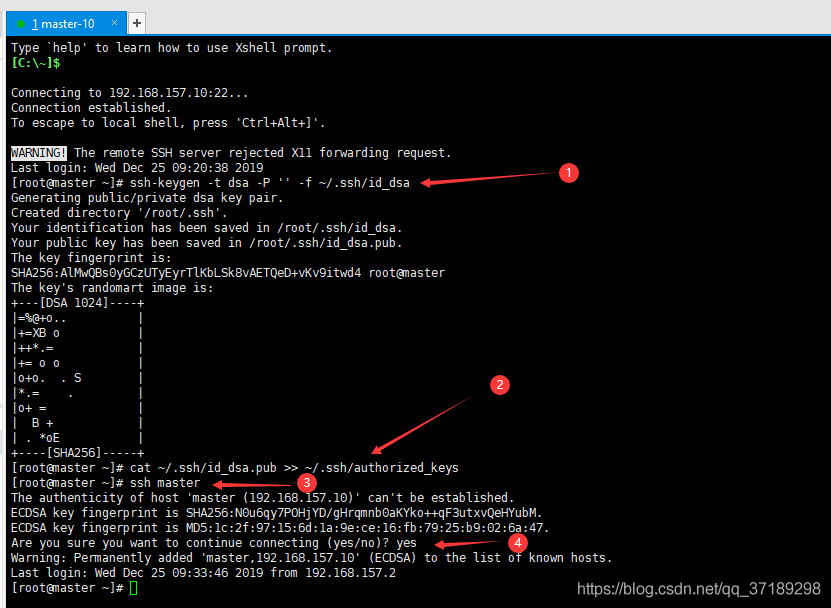
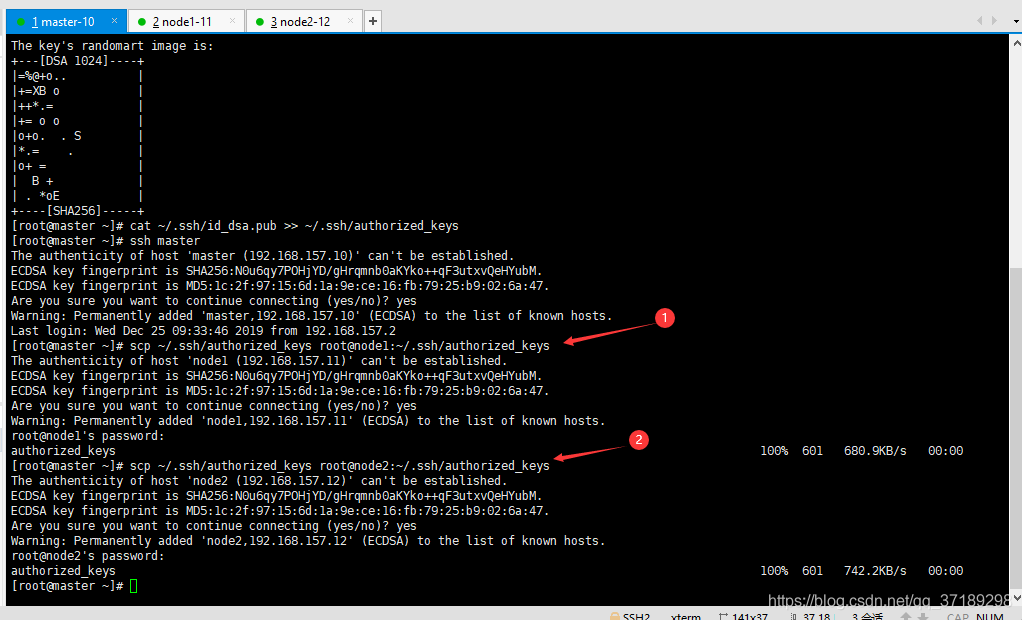
——在master机器上输入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建一个无密码的公钥。
——在master机器上输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进keys,这样就可以实现无密登陆ssh。
——在master机器上输入 ssh master 测试免密码登陆,出现询问,输入yes,回车继续。
我是在XShell上复制粘贴代码的,这一步我也不是很懂,但是的确可行,截图如下:
——在node1主机上执行 mkdir ~/.ssh,在node2主机上执行 mkdir ~/.ssh。
——在master机器上输入 scp ~/.ssh/authorized_keys root@node1:~/.ssh/authorized_keys 将主节点的公钥信息导入node1节点,导入时要输入一下node1机器的登陆密码。
——在master机器上输入 scp ~/.ssh/authorized_keys root@node2:~/.ssh/authorized_keys 将主节点的公钥信息导入node2节点,导入时要输入一下node2机器的登陆密码。
——在三台机器上分别执行 chmod 600 ~/.ssh/authorized_keys 赋予密钥文件权限。
——在master节点上分别输入 ssh node1 和 ssh node2 测试是否配置ssh成功:
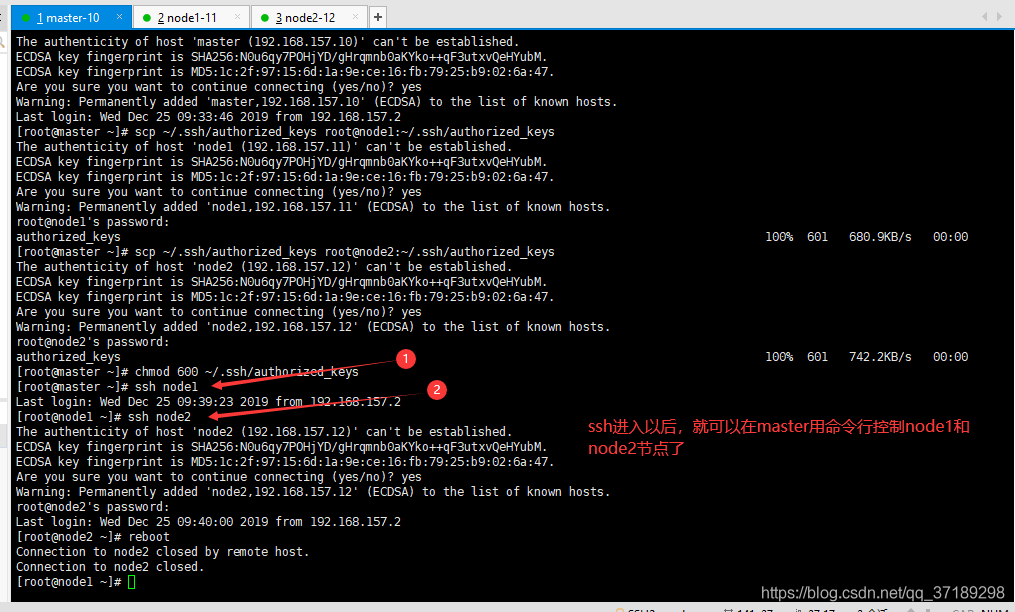
——在master机器上,任意目录输入 hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之后就不用再格式化,如果改一些配置文件了,可能还需要再次格式化:

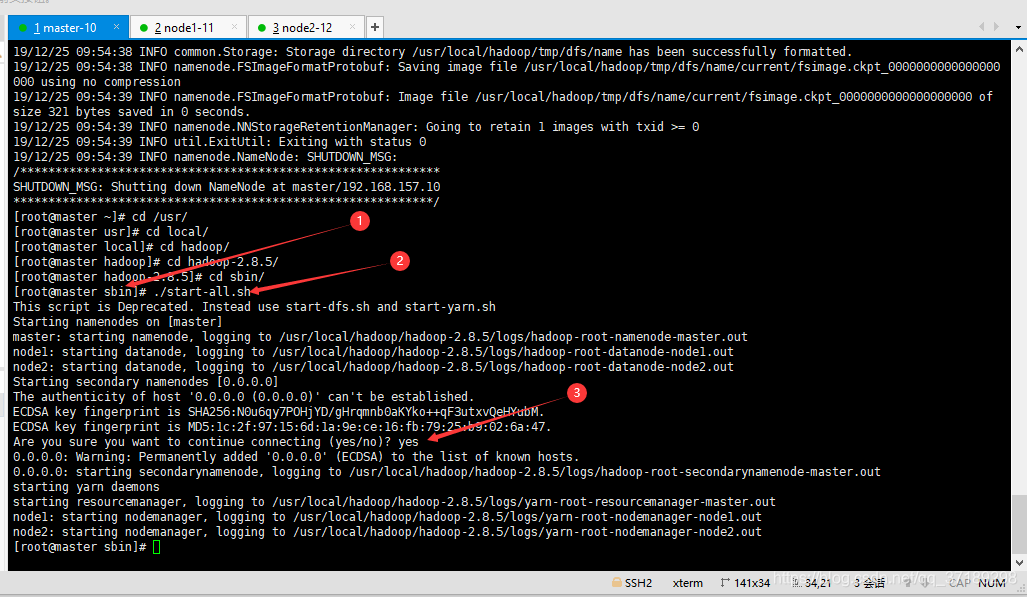
到这里,hadoop终于完全搭建好了!
在master机器上,进入hadoop的sbin目录,输入 ./start-all.sh ,可以启动hadoop:
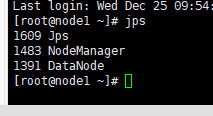
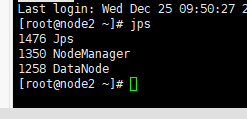
——输入 jps 查看当前java的进程,该命令是JDK1.5开始有的,作用是列出当前java进程的PID和Java主类名,nameNode节点除了JPS,还有3个进程,启动成功!如图:
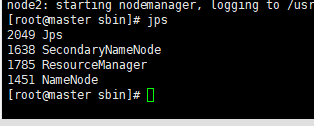
node1、node2输入jps查看进程如下:
——在浏览器访问192.168.157.10的8088端口和50070端口可以查看hadoop的运行状况(如果打不开,有可能是master虚拟机的防火墙没有关闭,检查一下):
8088端口:

50070端口:

WordCount运行
配置好hadoop后,现在可以运行数据库世界的"Hello world!"程序了,WordCount就是数据库的"Hello world!",WordCount是用来统计一个文本每个词汇的出现数量的程序。
在hadoop文件里面自带有WordCount作为hadoop的demo了,我们直接使用它来运行一下。
首先进入hadoop文件夹:cd /usr/local/hadoop/hadoop-2.8.5,里面有个LISENCE.txt,里面有很多英语单词,我这里直接统计它的词汇。
cat LISENCE.txt查看一下:
用hadoop fs -mkdir /input命令在hadoop库中创建input目录,然后hadoop fs -ls /查看一下:

用hadoop fs -put LICENSE.txt /input把LISENCE.txt放到input目录下,hadoop fs -ls /input查看:

接下来用hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /input /output,把input中的txt进行统计就行了(WordCount程序包的具体位置看这条命令,不同版本可能不同):
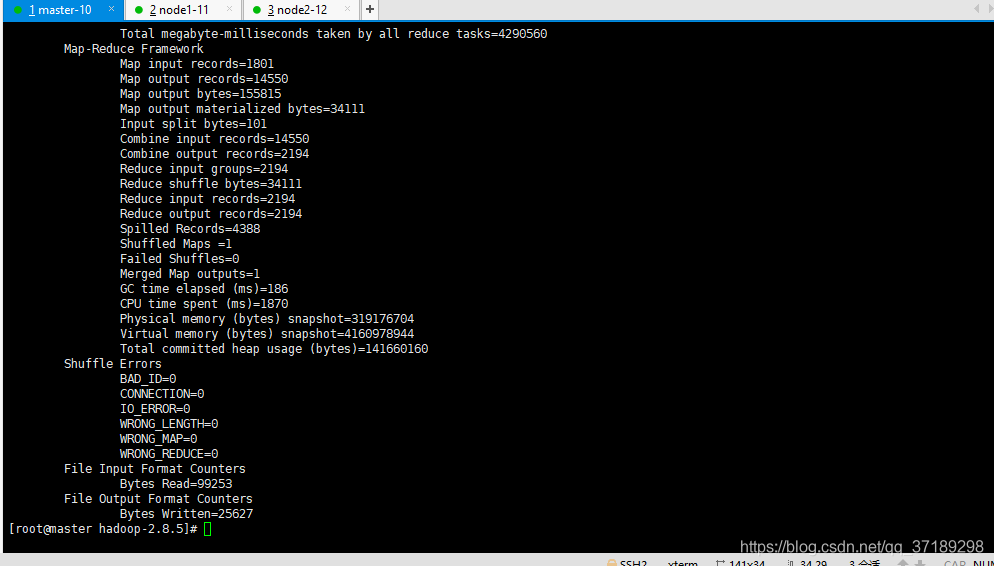
命令hadoop fs -ls /看出,HDFS系统下多了个/output 和/tmp目录。打开/output目录可以看到下面有两个文件(_SUCCESS和part-r-00000),说明已经运行成功了:
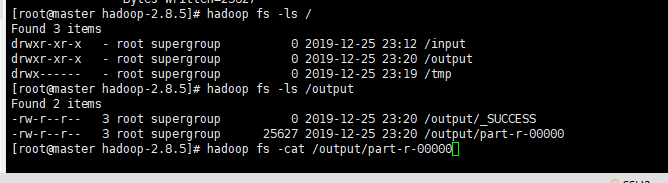
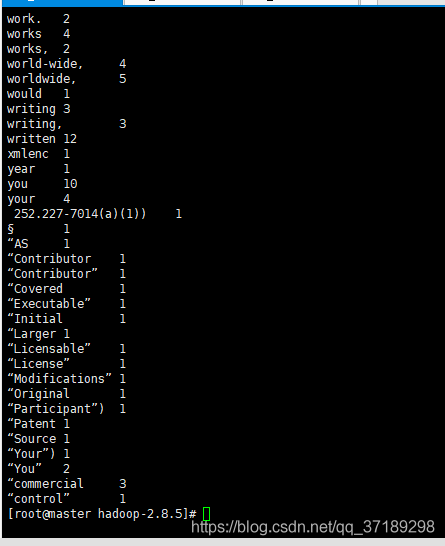
命令hadoop fs -cat /output/part-r-00000,打开part-r-00000查看结果:
参考链接:
CentOS7搭建:https://www.osyunwei.com/archives/7829.html
WordCount运行:https://blog.csdn.net/u010285974/article/details/81636719
CentOS7虚拟机配置、Hadoop搭建、wordCount DEMO运行的更多相关文章
- IDEA配置Hadoop开发环境&编译运行WordCount程序
有关hadoop及java安装配置请见:https://www.cnblogs.com/lxc1910/p/11734477.html 1.新建Java project: 选择合适的jdk,如图所示: ...
- 【Linux】 CentOS7 虚拟机配置
Linux虚拟机配置 从去年开始实习开始,公司电脑换了两个,自己的电脑也换了一个,每换一个新电脑,总免不了要去装一个Linux的虚拟机作为试验用.但是每次新装一个机器总是会遇到各种各样的问题让我用的不 ...
- CentOS7虚拟机配置git仓库(配置虚拟机,网络,git仓库,windows端git访问)
想要达成的目的:从windows使用git访问CentOS7服务器上搭建的git仓库 用到的软件: (1)VMware-workstation-full-15.5.0-14665864.exe (2) ...
- Macbook中VMWare的Centos7虚拟机配置静态IP并允许上网的配置方法
一.检查Macbook本身的配置 1.打开[系统偏好设置]-[网络]- 选中[Wi-Fi]项(如果您是WIFI上网请选择此项)- 点右侧[高级] 选择[TCP/IP]选项卡,记录好[子网掩码].[路由 ...
- hadoop的wordcount例子运行
可以通过一个简单的例子来说明MapReduce到底是什么: 我们要统计一个大文件中的各个单词出现的次数.由于文件太大.我们把这个文件切分成如果小文件,然后安排多个人去统计.这个过程就是”Map”.然后 ...
- 【Java学习系列】第1课--Java环境搭建和demo运行
本文地址 分享提纲: 1. java环境的搭建 2. java demo代码运行 3.参考文档 本人是PHP开发者,一直感觉Java才是程序的王道(应用广,科班出身),所以终于下决心跟一跟. 主要是给 ...
- 【大数据】Summingbird(Storm + Hadoop)的demo运行
一.前言 为了运行summingbird demo,笔者走了很多的弯路,并且在国内基本上是查阅不到任何的资料,耗时很久才搞定了demo的运行.真的是一把辛酸泪,有兴趣想要研究summingbird的园 ...
- react介绍、环境搭建、demo运行实例
React官网:https://reactjs.org/docs/create-a-new-react-app.html cnpm网址:http://npm.taobao.org/ 1.react介绍 ...
- CentOS7虚拟机配置ip地址
首先安装后的虚拟机选NAT模式配置vm的虚拟网络编辑器(vmware中的编辑),NAT模式中查看DHCP的范围,配置子网(写成和电脑一样),在linux中进入/etc/sysconfig/networ ...
随机推荐
- 【转】使用普通用户执行docker
原文:https://www.cnblogs.com/klvchen/p/9098745.html CentOS 版本 7.4,Docker 版本 docker-1.13 及以下 ll /var/ru ...
- Codeforces Round #588 (Div. 2)E(DFS,思维,__gcd,树)
#define HAVE_STRUCT_TIMESPEC#include<bits/stdc++.h>using namespace std;long long a[100007];vec ...
- 命令关闭tomcat
1.netstat -ano|findstr 8080(默认端口为8080) 2. taskkill /F /PID 17652 关闭后面的进程号(17652),直到输入上面第三个命令查不到占用808 ...
- SearchRequest用于与搜索文档、聚合、定制查询有关的任何操作
SearchRequest用于与搜索文档.聚合.定制查询有关的任何操作,还提供了在查询结果的基于上,对于匹配的关键词进行突出显示的方法. 1,首先创建搜索请求对象:SearchRequest sear ...
- 解决fastjson反序列化日期0000-00-00失败的方案
解决fastjson反序列化日期0000-00-00失败的方案 22 Jul 2016 一.案例场景复原 示例场景里涉及两个class:TestDemo.java, DateBeanDemo.java ...
- Mac旧机「焕」新机过程记录
一.首先我做了非硬件上的优化处理,在升级到10.14之前还是挺管用的.但是为了使用最新的iOS SDK,升级到10.14以后,已经不管用了. 1.设置->通用 将动画相关的选项去掉. 2.设置- ...
- 微信小程序 列表倒计时
最近要实现一个列表倒计时的功能,写了个demo 展示图 <view class="center colu"> <view class="time&quo ...
- 文件目录T位
场景: 共享目录设置T标志 可以看别人的文件,但不可以删除.修改别人的文件 除非是ROOT,目录的拥有者
- 吴裕雄--天生自然ORACLE数据库学习笔记:SQL语言基础
select empno,ename,sal from scott.emp; SELECT empno,ename,sal FROM scott.emp; selECT empno,ename,sal ...
- Android开发之显示分辨率及单位
Android 各种屏幕分辨率: VGA: Video Graphics Array,即:显示绘图矩阵,相当于640×480 像素: HVGA: Half-size VGA ...