09.Django-数据库优化
Django查询数据库性能优化
现在有一张记录用户信息的UserInfo数据表,表中记录了10个用户的姓名,呢称,年龄,工作等信息.
models文件
from django.db import modelsclass Job(models.Model):title=models.CharField(max_length=32)class UserInfo(models.Model):username=models.CharField(max_length=32)nickname=models.CharField(max_length=32)job=models.ForeignKey(to="Job",to_field="id",null=True)
数据表中记录:
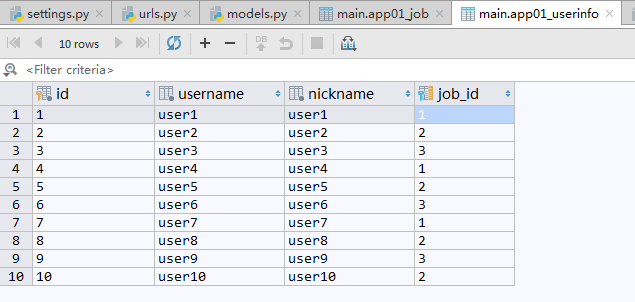
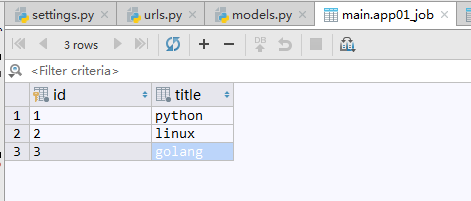
另一张数据表记录用户工作的Job表,关联用户的工作字段.
要查出每个用户的用户名,呢称和工作等信息
def index(request):user_list=models.UserInfo.objects.all()print(user_list.query) # 打印查询时使用的语句print(type(user_list)) # 打印查询结果的数据类型for user in user_list:print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))return render(request,'index.html')
打印信息:
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"<class 'django.db.models.query.QuerySet'>user1-->user1-->pythonuser2-->user2-->linuxuser3-->user3-->golanguser4-->user4-->pythonuser5-->user5-->linuxuser6-->user6-->golanguser7-->user7-->pythonuser8-->user8-->linuxuser9-->user9-->golanguser10-->user10-->linux
在服务端进行这些操作,这些查询语句的性能是很低的,遍历取出这10个用户的姓名,呢称,工作等信息要在两张数据库中执行11次查询操作.
首先只从UserInfo表中查出所有的用户记录,需要执行一次查询操作.
查询Job数据表,每循环一次用户信息的列表,都需要从Job表中查询一次用户的工作信息.
数据表中总共记录了10条用户记录,所以还需要循环10次才能从Job表中查询完成所有用户的工作信息.所以一共需要执行11次数据库查询操作.
那有没有什么好的方法能够提高数据库查询的效率呢???
def index(request):user_list=models.UserInfo.objects.values("username","nickname","job")print(user_list.query) # 打印查询时使用的语句print(type(user_list)) # 打印查询结果的数据类型print("user_list:",user_list)for user in user_list:print(user["username"], user["nickname"], user["job"])return render(request,'index.html')
运行程序,在服务端后台打印信息:
SELECT "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"<class 'django.db.models.query.QuerySet'>user_list: <QuerySet [{'username': 'user1', 'nickname': 'user1', 'job': 1}, {'username': 'user2', 'nickname': 'user2', 'job': 2}, {'username': 'user3', 'nickname': 'user3', 'job': 3}, {'username': 'user4', 'nickname': 'user4', 'job': 1}, {'username': 'user5', 'nickname': 'user5', 'job': 2}, {'username': 'user6', 'nickname': 'user6', 'job': 3}, {'username': 'user7', 'nickname': 'user7', 'job': 1}, {'username': 'user8', 'nickname': 'user8', 'job': 2}, {'username': 'user9', 'nickname': 'user9', 'job': 3}, {'username': 'user10', 'nickname': 'user10', 'job': 2}]>user1 user1 1user2 user2 2user3 user3 3user4 user4 1user5 user5 2user6 user6 3user7 user7 1user8 user8 2user9 user9 3user10 user10 2
可以看到,查询的结果user_list依然是一个QuerySet,但这个对象集合内部却是一个字典.
而且这次的查询只执行了两次数据库查询操作.
通过这种方式,只需要两次查询就能得到想要的数据,优化了数据库的查询效率.
Django数据库优化操作之select_related主动联表查询
上面的例子里,取对象集合的时候,难道只能查询当前数据表,不能查询其他数据表吗??
当然不是,在这里还可以使用select_related这个方法.
在第一次查询的时候,在all()后面加上一个select_related来做主动的联表查询.
在创建这两张数据表时,job在UserInfo数据表中是做为一个ForeignKey存在的,所以加上select_related后不仅只查询到了UserInfo数据库的记录,同时也查询了Job数据表中的记录.
def index(request):user_list=models.UserInfo.objects.all().select_related("job")print(user_list.query) # 打印查询时使用的语句print(type(user_list)) # 打印查询结果的数据类型print("user_list:",user_list)for user in user_list:print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))return render(request,'index.html')
服务端打印结果
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id", "app01_job"."id", "app01_job"."title" FROM "app01_userinfo" LEFT OUTER JOIN "app01_job" ON ("app01_userinfo"."job_id" = "app01_job"."id")<class 'django.db.models.query.QuerySet'>user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>user1-->user1-->pythonuser2-->user2-->linuxuser3-->user3-->golanguser4-->user4-->pythonuser5-->user5-->linuxuser6-->user6-->golanguser7-->user7-->pythonuser8-->user8-->linuxuser9-->user9-->golanguser10-->user10-->linux
查看打印出来的查询语句,其中有"FROM "app01_userinfo" LEFT OUTER JOIN "app01_job" ON ("app01_userinfo"."job_id" = "app01_job"."id")"用来做联表查询,只需要一次就可以查询所有的数据了.
同样的,如果还想继续联表,例如在Job表中再加一个外键字段desc,只需要在查询语句中把desc加入进来就可以了
user_list=models.UserInfo.objects.all().select_related("job__desc")
这样一来就把三张表联系起来做联表查询了,但是一定要确保所加的字段为ForeignKey.
如果使用类似models.UserInfo.objects.all()语句进行查询时,不要做跨表查询,只查询当前表中有的数据,否则查询语句的性能会下降很多.
如果想查其他表中的数据,就加上select_related(ForeignKey字段名);
如果想取多个ForeignKey字段的数据,则可以使用select_related(ForeignKey字段1,ForeignKey字段2,...)
联表查询操作性能也会降低,select_related就是用来做主动联表查询的.
Django数据库优化操作之perfetch_related非主动联表查询
perfetch_related方法是既非主动联表查询,又不进行很多查询语句的一种折衷方案
修改视图函数index
def index(request):user_list=models.UserInfo.objects.all().prefetch_related("job")print(user_list.query) # 打印查询时使用的语句print(type(user_list)) # 打印查询结果的数据类型print("user_list:",user_list)for user in user_list:print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title))return render(request,'index.html')
后端打印结果
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"<class 'django.db.models.query.QuerySet'>user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>user1-->user1-->pythonuser2-->user2-->linuxuser3-->user3-->golanguser4-->user4-->pythonuser5-->user5-->linuxuser6-->user6-->golanguser7-->user7-->pythonuser8-->user8-->linuxuser9-->user9-->golanguser10-->user10-->linux
使用prefetch_related方法未联表执行两次查询操作
先查询用户表中的所有数据,把用户表中所有的job_id全部查询出来,并执行去重操作;
结果查询出用户的3种工作,接下来执行"select"语句查询"Job"数据表中的"title"字段
这样一来就只执行了两次数据表的查询操作
在prefetch_related方法中加入一个字段"job",执行了两次数据库查询操作;
如果再加一个字段,则会再多加一次数据为操作操作.
Django数据库优化操作之only方法
def index(request):user_list=models.UserInfo.objects.all().only("username")print(user_list.query) # 打印查询时使用的语句print(type(user_list)) # 打印查询结果的数据类型print("user_list:",user_list)for user in user_list:print("%s-->%s" %(user.username,user.nickname))return render(request,'index.html')
服务端后台打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."username" FROM "app01_userinfo"<class 'django.db.models.query.QuerySet'>user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>user1-->user1user2-->user2user3-->user3user4-->user4user5-->user5user6-->user6user7-->user7user8-->user8user9-->user9user10-->user10
执行查询操作的时候加上only方法,其查询结果还是一个对象集合,但是从打印出的查询语句可以看到,执行查询操作时只查询了用户的id字段和username字段,并没有查询nickname字段.
但是在后面的循环中,又可以打印用户的nikename信息.为什么呢,因为又执行了一次查询的请求操作.由此得知,查询操作使用了only方法,在only方法中加入哪个查询字段,在后面就使用哪个查询字段.
加only参数是从查询结果中只取某个字段,而另外一个defer方法则是从查询结果中排除某个字段
Django数据库优化操作之defer方法
修改index视图函数
def index(request):user_list=models.UserInfo.objects.all().defer("username")print(user_list.query) # 打印查询时使用的语句print(type(user_list)) # 打印查询结果的数据类型print("user_list:",user_list)for user in user_list:print("%s" % user.nickname)return render(request,'index.html')
服务端打印信息
SELECT "app01_userinfo"."id", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"<class 'django.db.models.query.QuerySet'>user_list: <QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>user1user2user3user4user5user6user7user8user9user10
通过打印的查询语句可以知道,使用defer方法后,只从数据库中查询了用户的id字段和用户的nickname字段操作,并没有查询username字段,由此也可以提高Django查询数据库的性能.
09.Django-数据库优化的更多相关文章
- $Django 站点:样式--文章--分类文章--文章详情--文章评论点赞--文章评论点赞统计(数据库优化)
<h3>个人站点下的</h3> 知识点 url (r'(?P<username>\w+)/p/(?P<id>\d+)', xiangxi,name='x ...
- Django 数据库访问性能优化
使用标准的数据库优化技术: 在进行Django数据库访问性能优化之前,首先应该使用标准的数据库技术对其进行优化,比如给字段加索引,通过使用 django.db.models.Field.db_inde ...
- django性能优化
1. 内存.内存,还是加内存 2. 使用单独的静态文件服务器 3. 关闭KeepAlive(如果服务器不提供静态文件服务,如:大文件下载) 4. 使用memcached 5. 使用select_rel ...
- Django - 02 优化一个应用
Django - 02 优化一个应用 上一篇中我们已经创建了一个blog app,现在来用一下~ 2.1 添加第一篇blog 这个post 列表很丑陋哦,连标题都木有显示~ 2.2 自定义bl ...
- Django 数据库查询优化
Django数据层提供各种途径优化数据的访问,一个项目大量优化工作一般是放在后期来做,早期的优化是“万恶之源”,这是前人总结的经验,不无道理.如果事先理解Django的优化技巧,开发过程中稍稍留意,后 ...
- Django数据库操作性能相关
Django数据库操作性能相关 案例: 现在我们的数据库中有两张表如下: 1.职员表: class UserInfo(models.Model): name = models.CharField(ma ...
- mysql数据库优化 pt-query-digest使用
mysql数据库优化 pt-query-digest使用 一.pt-query-digest工具简介 pt-query-digest是用于分析 mysql慢查询的一个工具,它可以分析binlog.Ge ...
- Django数据库查询优化-事务-图书管理系统的搭建
数据库查询优化 优化:虽然减轻了数据库的压力,但查询速度大大的减慢 ORM内所有的语句操作,默认都是惰性查询,只有你在真正的需要数据的时候才会走数据, 如果你只是写ORM语句时,是不会走数据库的,这样 ...
- 06 ORM常用字段 关系字段 数据库优化查询
一.Django ORM 常用字段和参数 1.常用字段 models中所有的字段类型其实本质就那几种,整形varchar什么的,都没有实际的约束作用,虽然在models中没有任何限制作用,但是还是要分 ...
- 数据库优化案例——————某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
随机推荐
- 你还不了解基于session的授权认证吗?
前言 在漫长的开发过程中,权限认证是一个永恒不变的话题,随着技术的发展,从以前的基于sessionId的方式,变为如今的token方式.session常用于单体应用,后来由于微服务的兴起,分布式应用占 ...
- ES[7.6.x]学习笔记(九)搜索
搜索是ES最最核心的内容,没有之一.前面章节的内容,索引.动态映射.分词器等都是铺垫,最重要的就是最后点击搜索这一下.下面我们就看看点击搜索这一下的背后,都做了哪些事情. 分数(score) ES的搜 ...
- 接触Ubuntu的第一周大致总结
VB上安装,很简单,和入门的帮助,man,--help. 基础的分区,FDISK,文件系统,目录 ,LS,cd,文件操作mkdir,rm,cp等,文件查看,cat,tac,less,等,文件查找loc ...
- H3C S5500V2交换机误格式化恢复
一.格式化后,bin文件及视图全部被删除需要联系H3C客服报交换机后面的序列号,然后根据工单中给你的账号密码去H3C官网下载对应的软件包. 二.下载3CDaemon使用TFTP方式将解压出来的.ipe ...
- Java的集合(一)
转载:https://blog.csdn.net/hacker_zhidian/article/details/80590428 Java集合概况就三个:List.set和map list(Array ...
- 二、工具类ImageUtil——图片处理
这个工具类完成的工作如下: 1.第一个static方法,完成图片格式的转换.统一转换成.jpg格式. package util; import java.awt.Toolkit; import jav ...
- 四使用浮动div布局
刚开始学习的小白,如有不足之处还请各位补充,感激涕零.在html中有两种方式布局<table>表格和<div>,个人剧的使用表格布局可以避免bug产生,并且表格布局相对来说要容 ...
- lunix如何查看防火墙是否关闭和关闭开启防火墙命令
查看防火墙是否关闭的命令如下: 1.通过 /etc/init.d/iptables status 或者 service iptables status命令 2.通过 iptables -L命令 查看 ...
- 对于使用progisp软件进行ISP编程时进入不了编程模式的解决方法
标题: 对于使用progisp软件进行ISP编程时无法进入编程模式的解决方法 作者: 梦幻之心星 347369787@QQ.com 标签: [progisp, 软件] 目录: 软件 日期: 2019- ...
- 用python做时间序列预测一:初识概念
利用时间序列预测方法,我们可以基于历史的情况来预测未来的情况.比如共享单车每日租车数,食堂每日就餐人数等等,都是基于各自历史的情况来预测的. 什么是时间序列? 时间序列,是指同一个变量在连续且固定的时 ...