入门大数据---Spark简介
一、简介
Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目。相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升,因此它成为继 MapReduce 之后,最为广泛使用的分布式计算框架。
二、特点
Apache Spark 具有以下特点:
- 使用先进的 DAG 调度程序,查询优化器和物理执行引擎,以实现性能上的保证;
- 多语言支持,目前支持的有 Java,Scala,Python 和 R;
- 提供了 80 多个高级 API,可以轻松地构建应用程序;
- 支持批处理,流处理和复杂的业务分析;
- 丰富的类库支持:包括 SQL,MLlib,GraphX 和 Spark Streaming 等库,并且可以将它们无缝地进行组合;
- 丰富的部署模式:支持本地模式和自带的集群模式,也支持在 Hadoop,Mesos,Kubernetes 上运行;
- 多数据源支持:支持访问 HDFS,Alluxio,Cassandra,HBase,Hive 以及数百个其他数据源中的数据。

三、集群架构
| Term(术语) | Meaning(含义) |
|---|---|
| Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
| Driver program | 主运用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
| Cluster manager | 集群资源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 执行计算任务的工作节点 |
| Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
| Task | 被发送到 Executor 中的工作单元 |
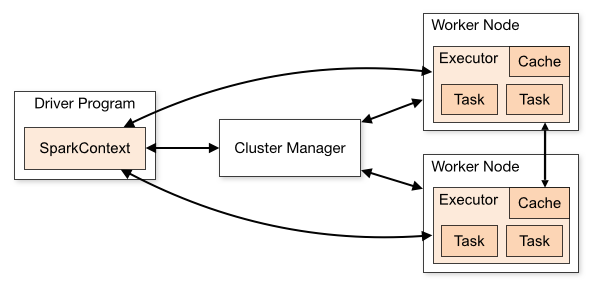
执行过程:
- 用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;
- Driver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
- Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
四、核心组件
Spark 基于 Spark Core 扩展了四个核心组件,分别用于满足不同领域的计算需求。

3.1 Spark SQL
Spark SQL 主要用于结构化数据的处理。其具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC;
- 支持 HiveQL 语法以及用户自定义函数 (UDF),允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性,以提高查询效率。
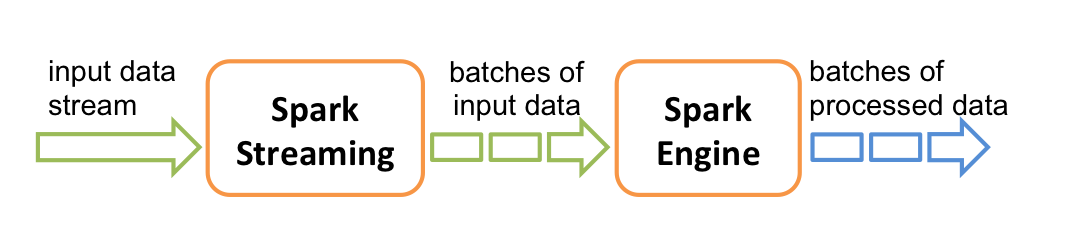
3.2 Spark Streaming
Spark Streaming 主要用于快速构建可扩展,高吞吐量,高容错的流处理程序。支持从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,并进行处理。

Spark Streaming 的本质是微批处理,它将数据流进行极小粒度的拆分,拆分为多个批处理,从而达到接近于流处理的效果。
3.3 MLlib
MLlib 是 Spark 的机器学习库。其设计目标是使得机器学习变得简单且可扩展。它提供了以下工具:
- 常见的机器学习算法:如分类,回归,聚类和协同过滤;
- 特征化:特征提取,转换,降维和选择;
- 管道:用于构建,评估和调整 ML 管道的工具;
- 持久性:保存和加载算法,模型,管道数据;
- 实用工具:线性代数,统计,数据处理等。
3.4 Graphx
GraphX 是 Spark 中用于图形计算和图形并行计算的新组件。在高层次上,GraphX 通过引入一个新的图形抽象来扩展 RDD(一种具有附加到每个顶点和边缘的属性的定向多重图形)。为了支持图计算,GraphX 提供了一组基本运算符(如: subgraph,joinVertices 和 aggregateMessages)以及优化后的 Pregel API。此外,GraphX 还包括越来越多的图形算法和构建器,以简化图形分析任务。
入门大数据---Spark简介的更多相关文章
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- 入门大数据---Spark累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- 入门大数据---Spark车辆监控项目
一.项目简介 这是一个车辆监控项目.主要实现了三个功能: 1.计算每一个区域车流量最多的前3条道路. 2.计算道路转换率 3.实时统计道路拥堵情况(当前时间,卡口编号,车辆总数,速度总数,平均速度) ...
- 入门大数据---Flume 简介及基本使用
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- 入门大数据---Sqoop简介与安装
一.Sqoop 简介 Sqoop 是一个常用的数据迁移工具,主要用于在不同存储系统之间实现数据的导入与导出: 导入数据:从 MySQL,Oracle 等关系型数据库中导入数据到 HDFS.Hive.H ...
- 入门大数据---Kafka简介
一.简介 ApacheKafka 是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于 RabbtMQ.ActiveMQ 等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: ...
- 入门大数据---Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 入门大数据---Spark部署模式与作业提交
一.作业提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作业,其格式如下: ./bin/spark-submit \ --class <ma ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
随机推荐
- day 7 while循环
#隐式布尔值: 0 none 空# 一.流程控制# 短路运算:偷懒原则,偷懒到哪个位置,就把当前位置的值返回# 为0# (10>3 and 10 and 0 and 10 )or( 10> ...
- 关于ueditor编译器
取消自动保存提示.edui-editor-messageholder.edui-default{ visibility:hidden;} Qiyuwen 1033935470@qq.com
- jchdl - RTL实例 - Counter4
https://mp.weixin.qq.com/s/xtvMj5f-Uvx3vesVnH0P_A 计数器. 参考链接 https://github.com/wjcdx/jchdl/blob/ ...
- Java实现 LeetCode 753 破解保险箱(递归)
753. 破解保险箱 有一个需要密码才能打开的保险箱.密码是 n 位数, 密码的每一位是 k 位序列 0, 1, -, k-1 中的一个 . 你可以随意输入密码,保险箱会自动记住最后 n 位输入,如果 ...
- (Java实现) 昆虫繁殖
昆虫繁殖 时间限制: 1 Sec 内存限制: 128 MB 提交: 25 解决: 16 [提交][状态][讨论版][命题人:quanxing] 题目描述 科学家在热带森林中发现了一种特殊的昆虫,这种昆 ...
- Java实现蓝桥杯二项式的系数规律
二项式的系数规律,我国数学家很早就发现了. 如[图1.png],我国南宋数学家杨辉1261年所著的<详解九章算法>一书里就出现了. 其排列规律: 1 1 1 2 1 3 3 1 4 6 4 ...
- java实现顺时针螺旋填入
从键盘输入一个整数(1~20) 则以该数字为矩阵的大小,把 1,2,3-n*n 的数字按照顺时针螺旋的形式填入其中.例如: 输入数字 2,则程序输出: 1 2 4 3 输入数字 3,则程序输出: 1 ...
- java实现第七届蓝桥杯交换瓶子
交换瓶子 交换瓶子 有N个瓶子,编号 1 ~ N,放在架子上. 比如有5个瓶子: 2 1 3 5 4 要求每次拿起2个瓶子,交换它们的位置. 经过若干次后,使得瓶子的序号为: 1 2 3 4 5 对于 ...
- cuda 9.0
https://docs.nvidia.com/cuda/archive/9.0/index.html cuda9.0工具包
- 呀,葵花宝典![IT项目经理成长晋升记2]
走出办公室时,老吴让王小白认真看下公司的项目管理体系和质量管理体系培训材料.公司这几年连续通过了ISO质量体系认证,通过了CMMI3,已有一套完整的组织过程体系. 因为从投标开始,到公示,还有一周时间 ...