Redis的安装配置及简单集群部署
最近针对中铁一局项目,跟事业部讨论之后需要我们的KF平台能够接入一些开源的数据库,于是这两天研究了一下Redis的原理。
1. Redis的数据存储原理及简述
1.1Redis简述
Redis是一个基于内存且支持持久化的key-value的NoSQL数据库,其中每个key和value都是使用对象表示的,具有以以下特征:多样数据类型、持久化、主从同步。它支持存储的value类型包括string(字符串)、list(链表)、hash(哈希)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
为了保证效率,Redis数据都是缓存在内存中,且Redis有一个很重要的特点就是它可以实现持久化数据,通过两种方式可以实现数据持久化:使用RDB快照的方式,将内存中的数据不断写入磁盘;或使用类似MySQL的AOF日志方式,记录每次更新的日志。前者性能较高,但是可能会引起一定程度的数据丢失;后者相反。 Redis支持将数据同步到多台从数据库上,这种特性对提高读取性能非常有益。
Redis3.0版本允许单点故障,它没有中心节点,各个节点地位一样,扩展性很好,节点间的采用二进制通信,节点与客户端采用ascII协议通信。
综上所述,Redis作为一个典型的非关系型数据库,Redis可用于缓存、数据库、消息中间件。它十分适合存储少、访问量巨大的场景,所有数据全部in-memory保证了数据的高速访问。
1.2Redis存储原理及实现方式
Redis内部使用一个redisObject对象来表示所有的Key和Value,redisObject最主要的信息如图所示:
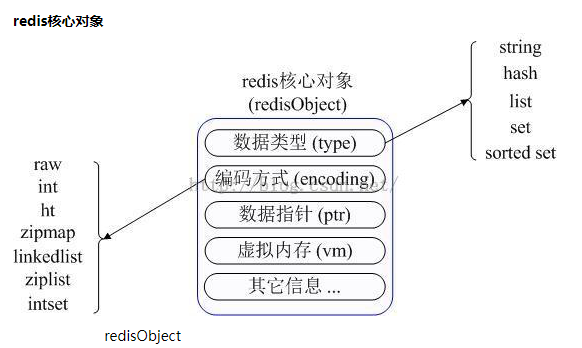
type代表一个value对象具体是何种数据类型
encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
vm字段,只有打开了Redis的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的。
五种数据类型的使用和内部实现方式:
1)String
常用命令:set/get/decr/incr/mget等;
应用场景:String是最常用的一种数据类型,普通的key/value存储都可以归为此类;
实现方式:String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr、decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
2)Hash
常用命令:hget/hset/hgetall等
应用场景:我们要存储一个用户信息对象数据,其中包括用户ID、用户姓名、年龄和生日,通过用户ID我们希望获取该用户的姓名或者年龄或者生日;
实现方式:Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口。如图2所示,Key是用户ID, value是一个Map。这个Map的key是成员的属性名,value是属性值。这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据。当前HashMap的实现有两种方式:当HashMap的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
3)List
常用命令:lpush/rpush/lpop/rpop/lrange等;
应用场景:Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现;
实现方式:Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
4)Set
常用命令:sadd/spop/smembers/sunion等;
应用场景:Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的;
实现方式:set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
5)Sorted Set
常用命令:zadd/zrange/zrem/zcard等;
应用场景:Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
1.3 Redis持久化
Redis虽然是基于内存的存储系统,但是它本身是支持内存数据持久化的,而且提供两种主要的持久化策略:RDB快照和AOF日志。
RDB快照:Redis支持将当前数据的快照存成一个数据文件的持久化机制。
但是一个持续写入的数据库如何生成快照呢?Redis借助了fork命令的copy on write机制。在生成快照时,将当前进程fork出一个子进程,然后在子进程中循环所有的数据,将数据写成为RDB文件。
我们可以通过Redis的save指令来配置RDB快照生成的时机,比如你可以配置当10分钟以内有100次写入就生成快照,也可以配置当1小时内有1000次写入就生成快照,也可以多个规则一起实施。这些规则的定义就在Redis的配置文件中,你也可以通过Redis的CONFIG SET命令在Redis运行时设置规则,不需要重启Redis。
Redis的RDB文件不会坏掉,因为其写操作是在一个新进程中进行的,当生成一个新的RDB文件时,Redis生成的子进程会先将数据写到一个临时文件中,然后通过原子性rename系统调用将临时文件重命名为RDB文件,这样在任何时候出现故障,Redis的RDB文件都总是可用的。同时,Redis的RDB文件也是Redis主从同步内部实现中的一环。
但是,我们可以很明显的看到,RDB有他的不足,就是一旦数据库出现问题,那么我们的RDB文件中保存的数据并不是全新的,从上次RDB文件生成到Redis停机这段时间的数据全部丢掉了。在某些业务下,这是可以忍受的,我们也推荐这些业务使用RDB的方式进行持久化,因为开启RDB的代价并不高。但是对于另外一些对数据安全性要求极高的应用,无法容忍数据丢失的应用,RDB就无能为力了,所以Redis引入了另一个重要的持久化机制:AOF日志。
AOF日志:AOF日志的全称是append only file,从名字上我们就能看出来,它是一个追加写入的日志文件。
一般数据库的binlog不同的是,AOF文件是可识别的纯文本,它的内容就是一个个的Redis标准命令。当然,并不是发送发Redis的所有命令都要记录到AOF日志里面,只有那些会导致数据发生修改的命令才会追加到AOF文件。
那么每一条修改数据的命令都生成一条日志,那么AOF文件是不是会很大?答案是肯定的,AOF文件会越来越大,所以Redis又提供了一个功能,叫做AOF rewrite。其功能就是重新生成一份AOF文件,新的AOF文件中一条记录的操作只会有一次,而不像一份老文件那样,可能记录了对同一个值的多次操作。其生成过程和RDB类似,也是fork一个进程,直接遍历数据,写入新的AOF临时文件。在写入新文件的过程中,所有的写操作日志还是会写到原来老的AOF文件中,同时还会记录在内存缓冲区中。当重完操作完成后,会将所有缓冲区中的日志一次性写入到临时文件中。然后调用原子性的rename命令用新的AOF文件取代老的AOF文件。
AOF是一个写文件操作,其目的是将操作日志写到磁盘上,所以它也同样会遇到我们上面说的写操作的5个流程。那么写AOF的操作安全性又有多高呢。实际上这是可以设置的,在Redis中对AOF调用write(2)写入后,何时再调用fsync将其写到磁盘上,通过appendfsync选项来控制,下面appendfsync的三个设置项,安全强度逐渐变强。
1)appendfsync no
当设置appendfsync为no的时候,Redis不会主动调用fsync去将AOF日志内容同步到磁盘,所以这一切就完全依赖于操作系统的调试了。对大多数Linux操作系统,是每30秒进行一次fsync,将缓冲区中的数据写到磁盘上。
2)appendfsync everysec
当设置appendfsync为everysec的时候,Redis会默认每隔一秒进行一次fsync调用,将缓冲区中的数据写到磁盘。但是当这一次的fsync调用时长超过1秒时。Redis会采取延迟fsync的策略,再等一秒钟。也就是在两秒后再进行fsync,这一次的fsync就不管会执行多长时间都会进行。这时候由于在fsync时文件描述符会被阻塞,所以当前的写操作就会阻塞。所以结论就是,在绝大多数情况下,Redis会每隔一秒进行一次fsync。在最坏的情况下,两秒钟会进行一次fsync操作。这一操作在大多数数据库系统中被称为group commit,就是组合多次写操作的数据,一次性将日志写到磁盘。
3)appednfsync always
当设置appendfsync为always时,每一次写操作都会调用一次fsync,这时数据是最安全的,当然,由于每次都会执行fsync,所以其性能也会受到影响。
1.4Redis的内存管理机制
Redis的内存管理机制主要通过源码中的zmalloc.h和zmalloc.c两个文件来实现的。Redis为了方便内存的管理,在分配一块内存之后,会将这块内存的大小存入内存的头部。

如图所示,real_ptr是redis调用malloc后返回的指针。redis将内存的大小size存入头部,size所占据的内存大小是已知的,为size_t类型的长度,然后返回ret_ptr。当需要释放内存的时候,ret_ptr被传给内存管理程序。通过ret_ptr,程序可以很容易的计算出real_ptr的值,然后将real_ptr传给free释放内存。
Redis通过定义一个数组来记录所有的内存分配情况,这个数组的长度为ZMALLOC_MAX_ALLOC_STAT.数组的每一个元素代表当前程序所分配的内存块的个数,且内存块的个数,且内存块的大小为该元素的下标。
在源码中,这个数组为zmalloc_allocations。zmalloc_allocations[16]代表已经分配的长度为16bytes的内存块的个数。zmalloc.c中有一个静态变量used_memory用来记录当前分配的内存总大小。所以,总的来看,Redis采用的是包装的mallc/free,相较于Memcached的内存管理方法来说,要简单很多。
2. Redis的数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
2.1 String(字符串)
string 是 redis 最基本的类型,是二进制安全的,意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象,string 类型的值最大能存储 512MB。
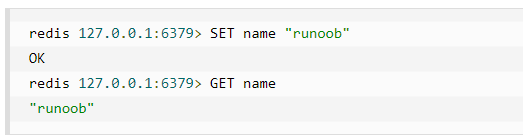
在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 name,对应的值为 runoob。
2.2 Hash(哈希)
Redis hash 是一个键值(key=>value)对集合, 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
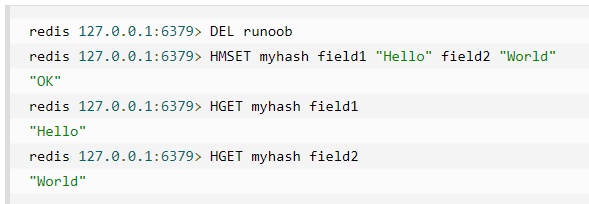
DEL runoob 用于删除前面测试用过的 key,不然会报错:(error) WRONGTYPE Operation against a key holding the wrong kind of value。实例中我们使用了 Redis HMSET, HGET 命令,HMSET 设置了两个 field=>value 对, HGET 获取对应 field 对应的 value。
每个 hash 可以存储 232 -1 键值对(40多亿)。
2.3 List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。

列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
2.4 Set(集合)
Redis的Set是string类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
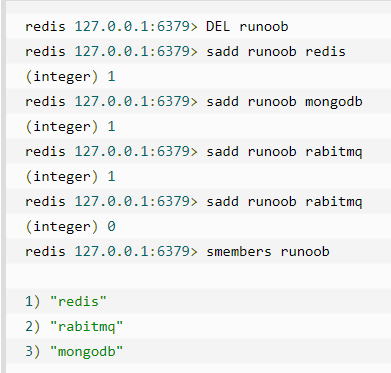
注意:以上实例中 rabitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。
2.5 zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
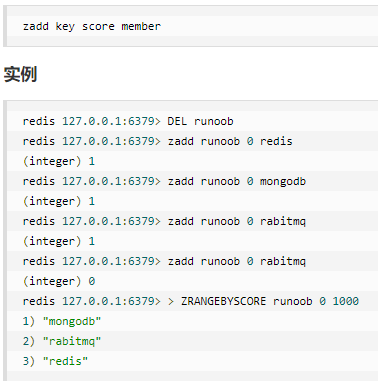
zadd 命令
添加元素到集合,元素在集合中存在则更新对应score
3. Redis基本安装过程及简单使用
本次安装是在vmware虚拟机下,使用的是centos6.9x64版本的Linux系统。
3.1.在官网http://www.redis.cn/download.html下载Redis压缩包(见附件)
3.2.把redis软件上传到虚拟机中/rdtar/中:

3.3.对压缩包进行解压并make编译:
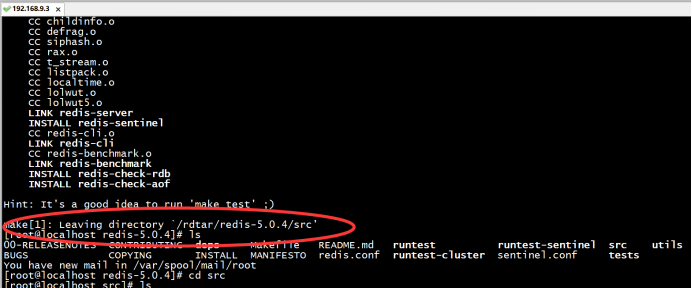
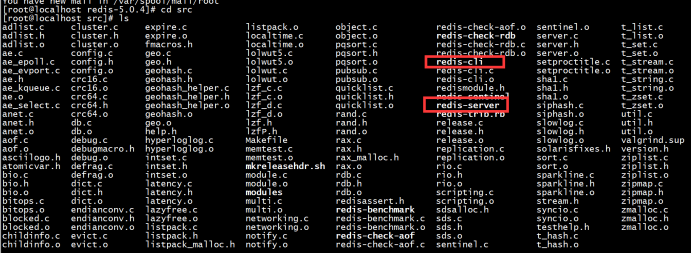
3.4打开redis文件夹中的src目录,找到redis.server和redis.cli文件:
其中前者是服务端文件,后者是客户端文件。
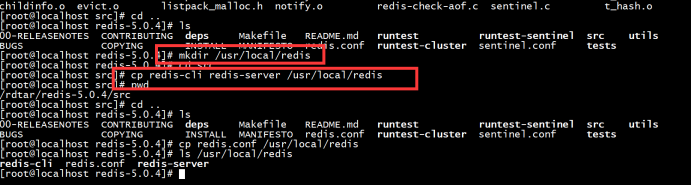
3.5创建redis运行目录并将redis-server和redis-cli复制到运行目录中:
3.6将redis文件夹下的redis.conf配置文件也拷贝到redis运行目录下:

3.7前端运行redis-server:
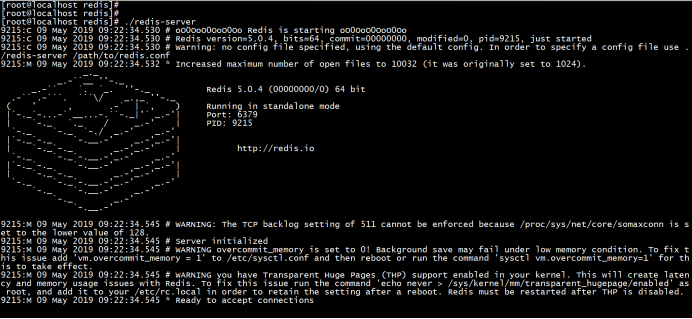
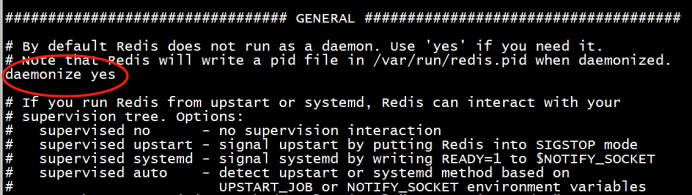
3.8后台运行redis-server时讲配置文件redis.conf中daemonize设置为yes:
3.9 redis-server的后台启动:

3.10 redis-cli启动并且简单使用:
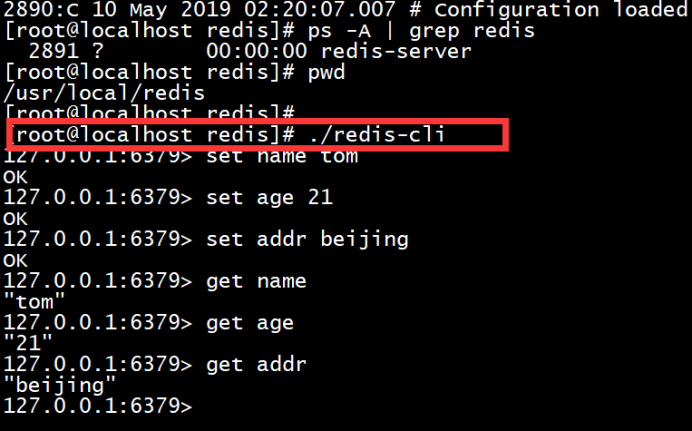
4. Redis简单集群

Redis Cluster是一个实现了分布式且允许单点故障的Redis高级版本,它没有中心节点,各个节点地位一致,具有线性可伸缩的功能。Redis Cluster的分布式存储结构,其中节点与节点之间通过二进制协议进行通讯,节点与客户端之间通过ascii协议进行通信,在数据的放置策略上,Redis Cluster将整个key的数值域分成16384个哈希槽。每个节点上可以存储一个或多个哈希槽,也就是说当前Redis Cluster支持的最大节点就是16384
4.1Redis简单集群下所需的计算机资源要求
Redis集群至少需要3个节点,要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。因为没有那么多服务器,也启动不了那么多虚拟机,所在这里搭建的是伪分布式集群,即一台服务器虚拟运行6个redis实例,修改端口号为(9001-9006),当然实际生产环境的Redis集群搭建和这里是一样的。
redis3.0版本之前只支持单例模式,在3.0版本及以后才支持集群。redis集群采用P2P模式,是完全去中心化的,不存在中心节点或者代理节点;redis集群也没有统一的入口的,客户端(client)连接集群的时候连接集群中的任意节点(node)即可,集群内部的节点是相互通信的(PING-PONG机制),每个节点都是一个redis实例;每个Redis集群理论上最多可以有16384个节点。
4.2Redis简单集群搭建过程
创建文件夹
我们计划集群中 Redis 节点的端口号为9001-9006 ,端口号即集群下各redis实例文件夹。数据存放在端口号/data文件夹中。

复制执行脚本
把安装好的单机版redis bin目录下的执行脚本复制到redis集群文件夹下

复制配置文件
把解压目录下的redis配置文件redis.conf复制一份到各端口实例文件夹中

修改各端口实例中的配置文件选项

启动 9001-9006 六个实例节点

查看启动服务

根据节点创建集群
Redis 5.0开始不再使用ruby搭建集群,而是直接使用客户端命令 redis-cli 来创建。客户端命令:
./redis-cli --cluster create 127.0.0.1:9001 127.0.0.1:9002 127.0.0.1:9003 127.0.0.1:9004 127.0.0.1:9005 127.0.0.1:9006 --cluster-replicas 1

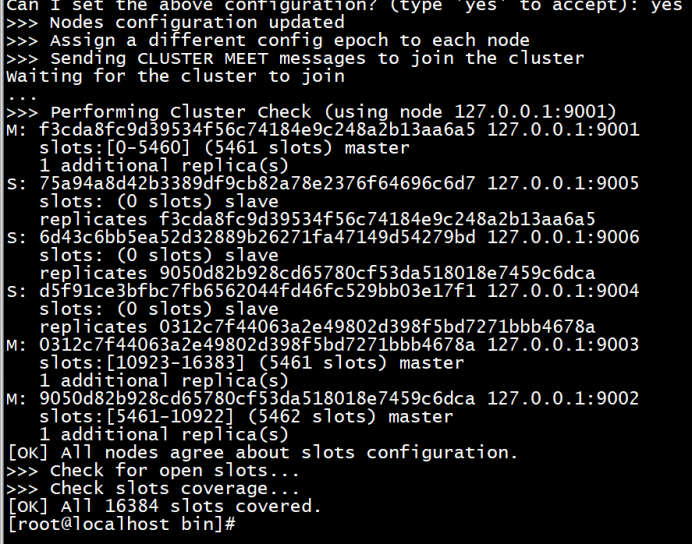
连接测试

Redis的安装配置及简单集群部署的更多相关文章
- 基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势)
基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势) 前言 前几天对Apollo配置中心的demo进行一个部署试用,现公司已决定使用,这两天进行分布式部署的时候 ...
- Spark standalone安装(最小化集群部署)
Spark standalone安装-最小化集群部署(Spark官方建议使用Standalone模式) 集群规划: 主机 IP ...
- RabbitMQ (简单集群部署操作)
RabbitMQ 集群部署 前期准备 第一步:三台linux系统(centos7.3) 主机名(hostname) 网卡ip node1 192.168.137.138 node2 192.168.1 ...
- CentO7 安装 redis, 主从配置,Sentinel集群故障转移切换
一.Redis的安装(前提是已经安装了EPEL) 安装redis: yum -y install redis 启动/停止/重启 Redis 启动服务: systemctl start re ...
- redis编译安装、哨兵、集群
编译安装 #下载源代码解压 wget https://download.redis.io/releases/redis-5.0.13.tar.gz -P /home/ tar -xvf /home/r ...
- CentOS和Ubuntu下安装配置Greenplum数据库集群(包括安装包和源码编译安装)
首先说一下,无论是CentOS/RedHat还是Ubuntu都可以按源码方式.安装包方式编译安装. 1. 规划 192.168.4.93(h93) 1个主master 2个主segm ...
- MongoDB ReplacaSet & Sharding集群安装 配置 和 非集群情况的安装 配置 -摘自网络
单台机器做sharding --单机配置集群服务(Sharding) --shard1_1 mongod --install --serviceName MongoDBServerShard1 --s ...
- 一步一步安装配置Ceph分布式存储集群
Ceph可以说是当今最流行的分布式存储系统了,本文记录一下安装和配置Ceph的详细步骤. 提前配置工作 从第一个集群节点开始的,然后逐渐加入其它的节点.对于Ceph,我们加入的第一个节点应该是Moni ...
- ZK安装、ZK配置、ZK集群部署
今天心血来潮,想搞一下zookeeper集群.具体步骤记录下吧~嘻嘻
随机推荐
- sshpass远程登陆
1,ssh ssh 端口为默认22的时候: sshpass -p 888888 scp -o StrictHostKeyChecking=no /root/images.zip root@21.1.9 ...
- kindeditor文件上传设置文件说明为上传文件名(JSP版)
编辑器换成kindeditor时发现文件上传后,直接点确定,<a>便签中的内容显示的是文件路径,不是我想要的文件名,我试了百度上的一些设置方法都不行的,百度上大部分都是修改pugins/i ...
- ScheduledThreadPoolExecutor与Timer
首先来看一下Timer类 例子如下: package cn.concurrent.executor; import java.util.Timer; import java.util.TimerTas ...
- 表与java类关系
总结: 表名对应类名,字段名对应属性名 java:多对多:各自类中添加一个对方类集合的属性 一对多:一的一方添加一个对方类集合的属性 ,多的一方添加一个对方类的属性 一对一:各自类中添加一个对 ...
- ExecutorService 的Future类
1.概述 在本文中,我们将了解Future.自Java 1.5以来一直存在的接口,在处理异步调用和并发处理时非常有用. 2.创建Future 简单地说,Future类表示异步计算的未来结果 - 这个结 ...
- 1、安装GPIO Zero(Installing GPIO Zero)
学习目录:树莓派学习之路-GPIO Zero 官网地址:http://gpiozero.readthedocs.io/en/stable/installing.html 环境:UbuntuMeta-1 ...
- tp5的输入和验证
规则和模板 好像要写一样名字,只需要引入模板
- WLC开机卡在launching....(变砖)
1.出现故障的原因:A.通过手动更换镜像导致Boot Loader Menu Run primary image (7.0.220.0) - ActiveRun backup image (7.0.2 ...
- WLC Crash采集什么信息?
WLC和思科的路由器交换机不同,Cisco的WLC采用的是AireOS. 如果WLC crash或无故重启,可以尝试采集如下信息: AireOS WLC version 8.0.140.0 or hi ...
- js里常见的三种请求方式$.ajax、$.post、$.get分析
$.post和$.get是$.ajax的一种特殊情况: $.post和$.get请求都是异步请求,回调函数里写return来返回值是无意义的, 回调函数里对外部变量进行赋值也是无意义的. 即使是$.a ...