Scrapy 框架结构及工作原理
1、下图为 Scrapy 框架的组成结构,并从数据流的角度揭示 Scrapy 的工作原理
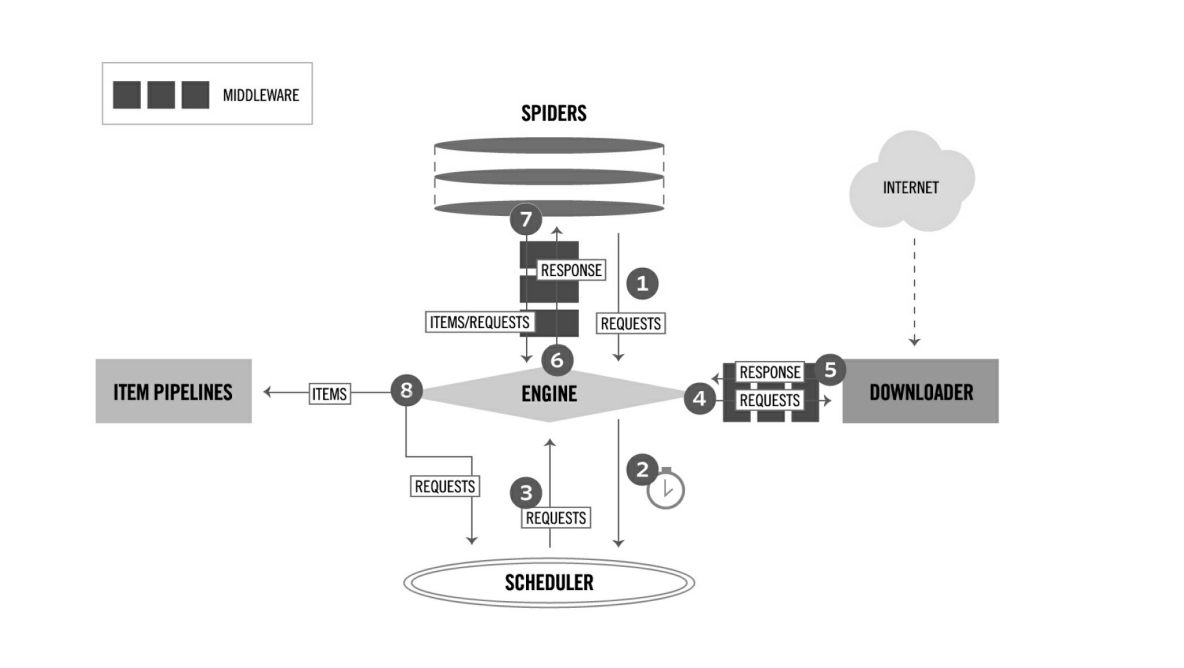 2、首先、简单了解一下 Scrapy 框架中的各个组件
2、首先、简单了解一下 Scrapy 框架中的各个组件
| 组 件 | 描 述 | 类 型 |
| ENGINE | 引擎,框架的核心,其他所有组件在其控制下协同工作 | 内部组件 |
| SCHEDULER | 调度器,负责对 SPIDER 提交的下载请求进行调度 | 内部组件 |
| DOWNLOADER | 下载器,负责下载页面(发送 HTTP 请求/接收 HTP 响应) | 内部组件 |
| SPIDER | 爬虫,负责提取页面中的数据,并产生对新页面的下载请求 | 外部组件 |
| MIDDLEWAERE | 中间件,负责对 Request 对象和 Response 对象进行处理 | 可选组件 |
| ITEM PIPELINE | 数据管道,负责对爬取到的数据进行处理 | 可选组件 |
对于用户来说,Spider 是最核心的组件,Scrapy 开发是围绕着 Spider 展开的
3、接下来,看一下框架中的数据流
| 对 象 | 描 述 |
| REQUEST | Scrapy 中的 HTTP 请求对象 |
| RESPONSE | Scrapy 中的 HTTP 响应对象 |
| ITEM | 从页面中爬取的一项数据 |
Request 和 Response 是 HTTP 协议的术语,即 HTTP 请求和 HTTP 响应,Scrapy 框架中定义了相应的 Request 和 Response 类,这里的 Item 带白哦Spider 从页面中爬取的一项数据
4、最后,我们来说明一下以上几种对象在框架中的流动过程
(1)当 Spider 要爬取某 URL 地址的页面时,需要用该 URL 构造一个 Request 对象,提交给 ENGINE.
(2)Request 对象随后进入 SCHEDULER 按某种算法进行排队,之后的某个时刻 SCHEDULER 将其出队,送往 DOWNLOADER
(3)DOWNLOADER 根据Request 对象中的 URL 地址发送一次 HTTP 请求到网站服务器,之后用服务器返回的 HTTP 响应构造出一个 Response 对象,其中包含页面的 HTML 文本
(4)Response 对象最终会被递交给 SPIDER 的页面解析函数(构造 Request 对象时指定)进行处理,页面解析函数从页面中提取带数据,封装成 Item 提交给 ENGINE,
item之后被送往 ITEM PIPELINES 进行处理,最终可能由 EXPORTER 易某种数据格式写入文件(csv, json)另一方面,页面解析函数还从页面中提取链接,构造新的
Request 对象提交给 ENGINE
理解了框架中的数据流,也就理解了 Scrapy 爬虫的工作原理,如果把框架中的组件比作人体的各个器官,Request 和 Response 对象便是血液,Item 则是代谢产物
Scrapy 框架结构及工作原理的更多相关文章
- scrapy框架结构与工作原理
组件: ENGINE:引擎,框架的核心,其他组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度 DOWNLOADER:下载器,负责下载页面,发送HTTP请求 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- 菜鸟学Struts2——Struts工作原理
在完成Struts2的HelloWorld后,对Struts2的工作原理进行学习.Struts2框架可以按照模块来划分为Servlet Filters,Struts核心模块,拦截器和用户实现部分,其中 ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
RAC 工作原理和相关组件(三) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- ThreadLocal 工作原理、部分源码分析
1.大概去哪里看 ThreadLocal 其根本实现方法,是在Thread里面,有一个ThreadLocal.ThreadLocalMap属性 ThreadLocal.ThreadLocalMap t ...
随机推荐
- java 实现一段文字中,出现次数最多的字
代码如下: public static void main(String[] args) { String str = "大批量,之前都没怎么注意过,这个问题确实不会,网上参考了下别人的,大 ...
- Django ORM中的模糊查询
ORM映射 什么是ORM映射?在笔者认为就是对SQL语句的封装,所写语句与SQL对应语句含义相同,使开发更加简单方便,不过也是存在弊端的,使程序运行效率下降.例如: UserInfo.objects. ...
- 最长公共子序列-Hdu1159
Common Subsequence Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Other ...
- Spark性能调优-高级篇
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- unittest和unittest2的区别差异、unittest2框架------执行原理
unittest和unittest2的区别差异 参考:https://pypi.org/project/unittest2/ unittest2是Python 2.7及更高版本中添加到unittest ...
- Airless Bottle-Can Be Used On Any Cream Product
Airless Bottle and Airless Pump are very effective at containing your makeup products. Although ...
- Python:re 模块
re模块是python内置的正则表达式模块
- ETCD实战
一.建立集群 1.在每台机器上建立环境变量 TOKEN=token-01 CLUSTER_STATE=new NAME_1=machine-1 NAME_2=machine-2 NAME_3=mach ...
- list中的对象或者map中的版本号排序 version排序
经常会用到版本号排序,直接把他封装成一个工具用起来比较方便. List<A> aList = new ArrayList<>(); ...aList 赋值 ... Collec ...
- AOP统一日志打印处理
在日常开发工作中,我们免不了要打印很多log.而大部分需要输出的log又是重复的(例如传入参数,返回值).因此,通过AOP方式来进行日志管理可以减少很多代码量,也更加优雅. Springboot通过A ...