MySQL学习笔记——〇六SQLAlchemy框架
我们在前面所用的方法都是在可视化的视图软件或者terminal里直接写SQL语句来对数据库进行访问,这里我们大概讲一下一个新的框架——SQLAlchemy。
我们今天要用的SQLAlchemy,就是一种Python中最长用的OEM架构。
class Foo():
def __call__(self):
print('in __call__ func') def __getitem__(self,key):
print('in __getitem__',key) def __setitem__(self,key,value):
print('in __setitem__,key=%s,values=%s'%(key,value)) def __delitem__(self,key):
print('in __delitem__',key) f=Foo()
# f()
# in __call__ func
f[1,2,3,4]
# in __getitem__ (1, 2, 3, 4)
f[123]=''
# in __setitem__,key=123,values=112233
del f[123]
# in __delitem__ 123
上面是Python中的几种特殊的行为,今天会用到,一定要注意括号的种类。
MySQL的面向对象
在SQLAlchemy里,我们是用面向对象的思路对MySQL进行操作的,其中,table对应的就是类,而对象,就是table里的每一行的数据。我们要建立这样一个数据库文件,里面有两个表
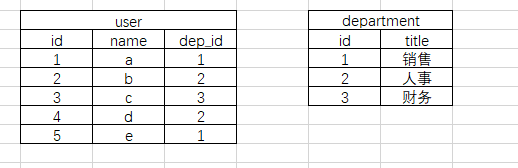
这就需要用两个类来描述
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Department(Base):
__tablename__='department' #指定表名
id=Column(Integer,primary_key=True,autoincrement=True)
title=Column(CHAR(10)) class User(Base):
__table__name='user' #指定表名
id=Column(Integer,primary_key=True,autoincrement=True)
name=Column(CHAR(15))
dep_id= Column(Integer,ForeignKey(UserType.id)) #指定外键
而数据就是依据类进行实例化
dep1 = Department(title='销售')
dep2=Department(title='人事')
user1=User(name='a',dep_id=1)
至于如何利用SQLAlchemy实现MySQL面向对象的编程方法 ,我们在下面简单说一下。
code first和db first
OEM框架有两种模式,code first和db first
db first 是手动创建数据库,再写代码。根据数据库的表生成类。
code first 是先写代码,后创建数据库。根据类创建数据库表。
我们在这里还是按照增删改查来说明其用法。
表的增、删
在用SQLAlchemy进行数据库读写的时候,首先要保证数据库内有要使用的database的存在,假设我们直接创建一个空的database,名字就叫test:
create database test default charset='utf8';
我们今天所有的操作都是基于这个数据库的。
进行表的操作需要先对类进行声明(前面的例子)
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index,CHAR,VARCHAR
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine Base = declarative_base() class Department(Base):
__tablename__='department' #指定表名
id=Column(Integer,primary_key=True,autoincrement=True)
title=Column(CHAR(10)) class User(Base):
__tablename__='user' #指定表名
id=Column(Integer,primary_key=True,autoincrement=True)
name=Column(CHAR(15))
dep_id= Column(Integer,ForeignKey(Department.id)) #指定外键 def create_db():
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/test?charset=utf8", max_overflow=5)
Base.metadata.create_all(engine) def drop_db():
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/test?charset=utf8", max_overflow=5)
Base.metadata.drop_all(engine) create_db() #创建表
drop_db() #删除表
上面的代码就说明了如何通过SQLAlchemy来实现数据库中表的创建和删除。这里的create_db()和drop_db()两个方法在执行的时候会先把数据库中的表和代码中的类进行比对,如果类中在,就进行相关的操作,比方我们把User那个类注释掉,执行drop的方法只会删除department这个表(例子中的并不会,因为我们在类的声明中指定了外键,department这个表是不能被先删除的。)
连接初始化
我们看一看上面表操作的时候有一段共同的代码
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/test?charset=utf8", max_overflow=5)
因为SQLAlchemy不能直接进行数据库的操作,必须通过第三方的工具来实现(如下图)

因为我们用的数据库是MySQL,在Python中对应的工具是pymysql
mysql+pymsql表明白我们用的数据库种类和所使用的API
root:是登录名后面可以加密码:root:123456(由于本机安装MySQL的时候是没有定义root用户密码,所以:后为空)
127.0.0.1:3306是对应的MySQL服务器的IP和端口,由于是本机,所以用的127.0.0.1,默认端口3306
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/test?charset=utf8", max_overflow=5,echo=True)
就可以返回执行的SQL语句。
然后就是创建节点session并绑定engine
engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/test?charset=utf8", max_overflow=5,echo=True)
Session=sessionmaker(bind=engine)
session=Session()
下面我们就可以对数据库进行增删改查的操作了。
添加数据
被添加的数据要按照类进行初始化,然后添加
添加添加单条数据
department1=Department(title='销售')
department2=Department(title='人事')
department3=Department(title='财务')
session.add(department1)
session.add(department2)
session.add(department3) session.commit()
还可以进行批量操作,关键字为add_all()
users=[User(name='a',dep_id=1),
User(name='b',dep_id=2),
User(name='c',dep_id=3),
User(name='d',dep_id=2),
User(name='e',dep_id=1),
]
session.add_all(users)
要注意一点:进行添加操作以后要执行下面的代码:一定不能忘记,删和改操作也一样。
session.commit()
查询操作
除了添加操作意外,删除和修改数据都是基于查询的操作基础上的,所以查询操作就比较重要。
users=session.query(User)
print(users)
看一看打印出的结论是什么:
users: SELECT user.id AS user_id, user.name AS user_name, user.dep_id AS user_dep_id
FROM use
也就是说,query方法返回的值是一段SQL语句。我们需要的是查询的返回对象,那么就要加一个all()方法,然后在打印一下看看结论是什么(user表数据有点多,这里改成department表)
deps=session.query(Department).all()
print(deps) ##########输出##########
[<__main__.Department object at 0x0000020C2A0C3A88>, <__main__.Department object at 0x0000020C2A0C3708>, <__main__.Department object at 0x0000020C2A0C3188>]
可以看出来,是个列表,用切片截取一个,用type查一下类型,可以发现是个对象
<class '__main__.Department'>
看看那个对象的名称,Department,我们试试按照当时构造类的情形取一下里面的值
deps=session.query(Department).all()
print(deps[0].id,deps[0].title) ##########输出##########
1 销售
这样就取出了table里的内容。我们可以用for循环获取所有的select结论
deps=session.query(Department).all()
for i in deps:
print(i.id,i.title) ##########输出##########
1 销售
2 人事
3 财务
如果我们需要在实现select后面加上where实现筛选的效果。
deps=session.query(Department).filter(Department.id>2).all()
我们在select的时大部分操作都是指定了字段,那么就要这么做
deps=session.query(Department.id,Department.title)
在query后加上参数就是对指定的字段直接进行索引。
查询的方法还有很多可以讲的,我们后面慢慢再讲。
删除操作
删除操作就是把筛选出来的数据加上delete()方法就可以了。
session.query(Department).filter(Department.id>3).delete()
session.commit() #切记要加上这一段
修改操作
修改操作也是基于查询操作上的
session.query(Department).filter(Department.id==3).update({'title':'财务'}) #用字典的方式来改
session.query(Department).filter(Department.id>0).update({Department.title:Department.title+''},synchronize_session=False)
#利用原有基础上修改,一定要加后面的参数synchronize_session,字符串给定参数值为False
session.query(Department).filter(Department.id>0).update({Department.title:Department.title+3},synchronize_session='evaluate')
#如果要改变的参数为数字类型,进行修改时synchronize_session,字符串给定参数值为'evaluate'
下面我们来仔细的看看查询操作:分组、连表、通配符、子查询、limit、还有原生SQL。
条件查询filter和filter_by
常用的条件查询是filter和filter_by,首先,要知道下面的语句都是成立的
result = session.query(Department).filter_by(title='销售').all()
result = session.query(Department).filter_by(title='销售',id=1).all()
result = session.query(Department).filter(Department.title=='销售').all()
特别注意的是filter和filter_by两个方法的使用区别,
| 模块 | 语法 | ><(大于和小于)查询 | and_和or_查询 |
|---|---|---|---|
| filter_by() | 直接用属性名,比较用= | 不支持 | 不支持 |
| filter() | 用类名.属性名,比较用== | 支持 | 支持 |
filter_by()可以实现下面的查询要求(值截取表达式后面的部分,前面的result都省略掉):
user表里name为a的
session.query(User).filter_by(name='a').all()
user里name为a并且部门id为1
session.query(User).filter_by(name='a',dep_id=1).all()
但是如果想查询名字为a或者部门id为1的就不能满足了.
filter()能够实现的要求
user表内名字为a的
session.query(User).filter(User.name=='a').all()
名字为a并且部门id为1
session.query(User).filter(User.name=='a',User.dep_id==1).all()
总之,filter_by()只接受键值对参数,所以不支持所有比较性质(包括大小和与或)的查询
in和not in
还有一个常用的方法就是where ..in
result = session.query(User).filter(User.id.in_([1,3]))
result = session.query(User).filter(~User.id.in_([1,3]))
注意in的用法,in后面是跟了个下划线的,并且后面给定的参数一用()括起来的列表。
第二行的~表示not,相当于not in的效果。
与或筛选
我们在上面提到了与或的筛选,要实现与或的要先导入一个新的库
from sqlalchemy import and_,or_
我们继续看看,如果想要筛选出user表内名字为a并且部门id为1的数据
session.query(User).filter(and_(User.name=='a',User.dep_id==1)).all()
可以看出来和前面那个方法结果是一样的,所以,filter里默认的关系是and。
筛选名字为a或者部门id为1的数据
session.query(User).filter(or_(User.name=='a',User.dep_id==1)).all()
通配符
通配符的用法和SQL差不多,就是在筛选的时候加上反复like(),匹配的关键字和SQL语句是一样的,下划线匹配单个字符,百分号匹配多个字符
result = session.query(User).filter(User.name.like('_a%')).all()
排序
result = session.query(User).order_by(User.id.desc()).all()
result = session.query(User).order_by(User.id.asc()).all()
result = session.query(User).order_by(User.id.desc(),User.name.desc()).all()
第三行代码是先按id的降序,在按照name的升序。
limit分页
因为我们用query返回的对象是个列表,可以直接用切片的方法来实现limit的效果。
result = session.query(User)[2:4]
注意这里,切片的时候一定不要用all()。
join连表
SQLAlchemy连表时必须在类中定义好外键关系,否则无法连表。
这里先讲一下比较笨的join方法,后面我们还可以利用SQLAlchemy提供的比较便利的方法实现连表的功能。
result = session.query(User.id,User.name,Department.title).join(Department).all()for i in result:
print(i.id,i.name,i.title)
我们可以通过打印不带all函数的result,查看SQL语句
result = session.query(User.id,User.name,Department.title).join(Department)
print(result) ##########输出##########
SELECT user.id AS user_id, user.name AS user_name, department.title AS department_title
FROM user INNER JOIN department ON department.id = user.dep_id
可以发现,默认的join的形式是inner join,但是如果我们需要用left join,就需要一个参数
result = session.query(User.id,User.name,Department.title).join(Department,isouter=True)
print(result) ##########输出##########
SELECT user.id AS user_id, user.name AS user_name, department.title AS department_title
FROM user LEFT OUTER JOIN department ON department.id = user.dep_id
SQLAlchemy是不支持right join的,但是我们可以通过改变两个join对象的位置实现right join的效果。
字段的获取
我们上面的例子都是指获取了User里的两个字段和department里的一个字段,所以都写在query里比较方便,但是如果需要多个字段或者要join多个表的话,这样写是不合适的,这样就有下面的方法
result = session.query(User,Department).join(Department)
for i in result:
print(i)
我们先看一看打印出来的结果
(<__main__.User object at 0x0000022694D9C048>, <__main__.Department object at 0x0000022694D9C408>)
(<__main__.User object at 0x0000022694D9C548>, <__main__.Department object at 0x0000022694D9C5C8>)
(<__main__.User object at 0x0000022694D9C648>, <__main__.Department object at 0x0000022694D9C6C8>)
(<__main__.User object at 0x0000022694D9C748>, <__main__.Department object at 0x0000022694D9C5C8>)
(<__main__.User object at 0x0000022694D9C808>, <__main__.Department object at 0x0000022694D9C408>)
在对result进行遍历的时候,每次打印的i都是一个元组,这么我们就可以对这个元组进行切片然后取到所需的数据
result = session.query(User,Department).join(Department).all()
for i in result:
print(i[0].id,i[0].name,i[1].id,i[1].title)
这样也是可以的。
笛卡尔积
前面的join连表还是可以利用笛卡尔及的方法,但是这种方法是不推荐的,我们只需要知道有这么个方法就可以了。
result = session.query(User,Department).filter(User.dep_id==Department.id).all() print(result)
for i in result:
print(i.User.id,i.User.name,i.Department.title)
union连表
union连表需要把两个query对象直接连起来就可以了
q1 = session.query(User.id,User.name)
q2 = session.query(Department.id,Department.title)
result = q1.union(q2)
print(result)
for i in result:
print(i.id,i.name)
注意后面取值的方法,字段的标题是要用union前面的那个表的字段。同样连表的时候要求字段数量一致。
分组group_by()
分组功能常用的聚合函数也需要在使用前导入,
from sqlalchemy.sql import func #func为聚合函数
result = session.query(User.dep_id,func.count(User.id)).group_by(User.dep_id).all()
print(result) ##########输出##########
[(1, 2), (2, 2), (3, 1)]
分组以后的输出直接就是一个列表,列表里的数据是依据query函数生成的元组。
带筛选的分组
筛选的关键字和SQL语句的一样,都是having
result = session.query(User.dep_id,func.count(User.id)).group_by(User.dep_id).having(User.dep_id>2).all()
print(result)
虚拟表
我们又是后会用到select...from (select ...from) as t1;这样的虚拟表,在SQLAlchemy里是这用的,比方我们需要获取department为销售的员工信息
t1 = session.query(Department.id).filter_by(title='销售').subquery() #此处不可加all()
result = session.query(User).filter(User.dep_id.in_(t1)).all()
for i in result:
print(i.id,i.name)
上面的t1,就类似一个虚拟表。
子查询
我们在前面将使用案例的时候(第16题)使用过一个方法,代码是这样的
SELECT
student_id,
( SELECT num FROM score AS s2 WHERE s2.student_id = s1.student_id AND course_id = 1 ) AS 'course1_num',
( SELECT num FROM score AS s2 WHERE s2.student_id = s1.student_id AND course_id = 2 ) AS 'course2_num',
( SELECT num FROM score AS s2 WHERE s2.student_id = s1.student_id AND course_id = 3 ) AS 'course3_num'
FROM
score AS s1
GROUP BY
student_id
就是把一个搜索的结论作为一个映射放在select里。这样的方式在SQLAlchemy里也是可以实现的 。
首先看一看怎么实现把结论作为映射
result = session.query(User.name,session.query(User.dep_id).filter(User.id==1).as_scalar())
这么就起到了下面语句的效果
select name,(SELECT dep_id from user where id=1) from user;
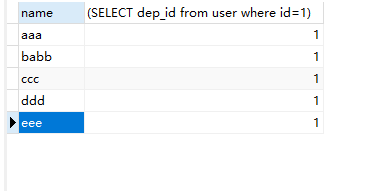
上面最后的as_scalar()就是把索引的结果作为一项拿出来.。
那如何把外面的循环的项放在里面循环使用呢?
result = session.query(User.name,session.query(User).filter(User.id==User.dep_id).as_scalar())
这个方法应该可以,但是我试了没成功,不知道是不是表的结构有问题。
正向关系操作
我们在上面讲连表的时候讲过那个join是一个比较笨的方法,因为SQLAlchemy里提供了一些比较便利的用法:这里先讲一下连表的用法。
我们在定义外键的时候,可以定义一下外键的关系
class User(Base):
__tablename__='user' #指定表名
id=Column(Integer,primary_key=True,autoincrement=True)
name=Column(CHAR(15))
dep_id= Column(Integer,ForeignKey(Department.id)) #指定外键
dep=relationship(Department)
在声明类的时候,我们最后指定了User的外键是那个表,那么我们在查询user表的时候,可以看一下dep
result = session.query(User)
print(result)
for i in result:
print(i.dep) ##########输出##########
<__main__.Department object at 0x000002C3DA3AE588>
<__main__.Department object at 0x000002C3DA3AE948>
<__main__.Department object at 0x000002C3DA3BB308>
<__main__.Department object at 0x000002C3DA3AE948>
<__main__.Department object at 0x000002C3DA3AE588>
dep对应的是department对象。,就可以直接获取通过外键连表对应的字段
result = session.query(User)
print(result)
for i in result:
print(i.id,i.name,i.dep.title) ##########输出##########
1 aaa 销售
2 babb 人事
3 ccc 财务
4 ddd 人事
5 eee 销售
反向关系操作
这时候如果我们需要查询每个部门的员工,要怎么做呢?先看看比较复杂的方法
result = session.query(Department)
print(result)
for i in result:
print(i.id,i.title,session.query(User.name).filter(User.dep_id==i.id).all()) ##########输出##########
1 销售 [('aaa',), ('eee',)]
2 人事 [('babb',), ('ddd',)]
3 财务 [('ccc',)]
用关系操作的反向操作
class User(Base):
__tablename__='user' #指定表名
id=Column(Integer,primary_key=True,autoincrement=True)
name=Column(CHAR(15))
dep_id= Column(Integer,ForeignKey(Department.id)) #指定外键
dep=relationship(Department,backref='aabbcc')
我们把把关系做了个类似回调的效果,这个新添加的aabbcc就可以作为Department的项目被调用,我们可以试一试
result = session.query(Department)
print(result)
for i in result:
print(i.id,i.title,i.aabbcc) ##########输出##########
1 销售 [<__main__.User object at 0x0000015B58E14948>, <__main__.User object at 0x0000015B58E14AC8>]
2 人事 [<__main__.User object at 0x0000015B58DED488>, <__main__.User object at 0x0000015B58DED288>]
3 财务 [<__main__.User object at 0x0000015B58DED248>]
可以发现,aabbcc就成了一个列表(我们的外键是一对多的)。也就是我们的aabbcc执行了一段这样的代码
session.query(User).filter(User.dep_id=i.id).all()
想实现前面的效果就要这么做
result = session.query(Department)
print(result)
for i in result:
print(i.id,i.title)
for employee in i.aabbcc:
print(employee.name) ##########输出##########
1 销售
aaa
eee
2 人事
babb
ddd
3 财务
ccc
MySQL学习笔记——〇六SQLAlchemy框架的更多相关文章
- MySQL学习笔记(六)
好耶,七天课程的最后一天!我当然还没精通了,,,之后可能是多练习题目然后再学学其他的东西吧.mysql新的知识点也会在后面补充的. 一.杂七杂八补充 1. 当多个函数共用同样的参数时,可以转变成类进行 ...
- Mysql学习笔记(六)增删改查
PS:数据库最基本的操作就是增删改查了... 学习内容: 数据库的增删改查 1.增...其实就是向数据库中插入数据.. 插入语句 insert into table_name values(" ...
- MySQL学习笔记(六)—— MySQL自连接
有的时候我们需要对同一表中的数据进行多次检索,这个时候我们可以使用之前学习过的子查询,先查询出需要的数据,再进行一次检索. 例如:一张products表,有产品id,供应商id(vend_id),产品 ...
- MySQL学习笔记——〇三 MySQL习题
在前面讲了MySQL的初步使用方法以后,在这里放出来一些案例来看看怎么做. 先看看database的结构,一共5个表 外键关系: class的cid是student的class_id的外键,teach ...
- MySQL学习笔记十六:锁机制
1.数据库锁就是为了保证数据库数据的一致性在一个共享资源被并发访问时使得数据访问顺序化的机制.MySQL数据库的锁机制比较独特,支持不同的存储引擎使用不同的锁机制. 2.MySQL使用了三种类型的锁机 ...
- MySQL学习笔记(六)MySQL8.0 配置笔记
今天把数据库配置文件修改了,结果重启不了了 需要使用 mysqld --initialize 或 mysqld --initialize-insecure 命令来初始化数据库 1.mysqld --i ...
- MYSQL学习笔记 (六)explain分析查询
使用EXPLAIN可以模拟优化器执行SQL语句,从而知道MYSQL是如何处理你的SQL,从而分析查询语句或者表结构的瓶颈.
- Java基础学习笔记十六 集合框架(二)
List List接口的特点: 它是一个元素存取有序的集合.例如,存元素的顺序是11.22.33.那么集合中,元素的存储就是按照11.22.33的顺序完成的. 它是一个带有索引的集合,通过索引就可以精 ...
- 初识mysql学习笔记
使用VMVirtualBox导入Ubuntu后,可以通过sudo apt-get install mysql-server命令下载mysql. 在学习过程中,我遇到了连接不上Xshell的问题.最终在 ...
随机推荐
- Java 日期与时间
章节 Java 基础 Java 简介 Java 环境搭建 Java 基本语法 Java 注释 Java 变量 Java 数据类型 Java 字符串 Java 类型转换 Java 运算符 Java 字符 ...
- created a ThreadLocal with key of type [oracle.jdbc.driver.AutoKeyInfo$1]
环境: spring4.3, mybatis3.5.2, ojdbc8_8c(oracle 18c jdbc) 调试状态下退出时,提示: 严重 [main] org.apache.catalina.l ...
- P1045 快速排序
P1045 快速排序 转跳点:
- 126-PHP类__get()魔术方法
<?php class ren{ //定义人类 //定义成员属性 private $name='Tom'; private $age=15; //定义__get()魔术方法 public fun ...
- 113-PHP使用instanceof判断变量是否为某个类对象
<?php class ren{ //定义人类 } class mao{ //定义猫类 } $ren=new ren(); //实例化一个人类的对象 $mao=new mao(); //实例化一 ...
- ISO处理jq事件
jq事件在IOS上,如果标签本身不具备某些功能,而我们通过document或者body绑定上去的话,有些事件是不起作用的,同时在IOS上jq事件也存在延迟. 事件不起作用 这里点击事件为例,在IOS中 ...
- AI 伴游小精灵
北京市商汤科技开发有限公司面向青少年研发了一款智能伴游机器人-- AI 伴游小精灵.一经推出,深受孩子们的喜爱,可爱又机智的小精灵会想出很多有趣的小游戏来启迪孩子们思考.今天,小精灵给你提出了一个神奇 ...
- PHP购物网站
我使用的phpsteam经常用着用着就闪退,所以做起来挺麻烦的.里面的代码有抄袭借鉴网上的代码,就是那个php做购物网站点击量最高的那个. 但是我很多代码也是自己写的不和其相同. PHP是一门选修课, ...
- volatile作用与处理器嗅探的简解
先贴一下 volatile 的作用定义 如果一个字段被声明成volatile,Java线程内存模型确保所有线程看到这个变量的值是一致的 首先问题就来了,一个共享变量再被volatile修饰过后,怎么被 ...
- Oracle学习笔记(2)
2.Oracle用户管理 (1)创建用户:create user 用户名 identified by 密码(需要dba权限); sql>create user yzw identified by ...