centos7搭建hadoop2.10完全分布式
本篇介绍在centos7中大家hadoop2.10完全分布式,首先准备4台机器:1台nn(namenode);3台dn(datanode)
| IP | hostname | 进程 |
| 192.168.30.141 | s141 | nn(namenode) |
| 192.168.30.142 | s142 | dn(datanode) |
| 192.168.30.143 | s143 | dn(datanode) |
| 192.168.30.144 | s144 | dn(datanode) |
由于本人使用的是vmware虚拟机,所以在配置好一台机器后,使用克隆,克隆出剩余机器,并修改hostname和IP,这样每台机器配置就都统一了每台机器配置 添加hdfs用户及用户组,配置jdk环境,安装hadoop 见 :centos7搭建hadoop2.10伪分布模式
下面是安装完全分布式的一些步骤和细节:
1.设置每台机器的hostname 和 hosts
设置hostname,这里用s+ip最后一组数字(如:192.168.30.141为s141),修改一下文件
vim /etc/hostname
修改hosts文件,hosts设置有后可以使用hostname访问机器,这样比较方便,修改如下:
127.0.0.1 locahost
192.168.30.141 s141
192.168.30.142 s142
192.168.30.143 s143
192.168.30.144 s144
2.配置无密登录,即ssh无密登录
我们将s141设置为nn,就需要s141能够通过ssh无密登录到其他机器,这样就需要在s141机器hdfs用户下生成密钥对,并将s141公钥发送到其他机器放到~/.ssh/authorized_keys文件中
在s141机器上生成密钥对:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
执行命令后

说明成功了,查看 ~/.ssh下是否生成密钥对:

将id_rsa.pub文件内容追加到s141-s144机器的/home/centos/.ssh/authorized_keys中,现在其他机器暂时没有authorized_keys文件,我们就将id_rsa.pub更名为authorized_keys即可,如果其他机器已存在authorized_keys文件可以将id_rsa.pub内容追加到该文件后,远程复制可以使用scp命令:
scp id_rsa.pub hdfs@s141:/home/hdfs/.ssh/authorized_keys
scp id_rsa.pub hdfs@s142:/home/hdfs/.ssh/authorized_keys
scp id_rsa.pub hdfs@s143:/home/hdfs/.ssh/authorized_keys
scp id_rsa.pub hdfs@s144:/home/hdfs/.ssh/authorized_keys
s141机器可以使用cat生成authorized_keys文件
cat id_rsa.pub >> authorized_keys
此时authorized_keys文件权限需要改为644(注意,经常会因为这个权限问题导致ssh无密登录失败)
chmod authorized_keys
3.配置hadoop配置文件(${hadoop_home}/etc/hadoop/)
core-sit.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s141/</value>
</property>
</configuration>
hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
slaves(指定数据节点):
s142
s143
s144
hadoop-env.sh(配置jdk环境变量):
export JAVA_HOME=/opt/soft/jdk
4.将s141中hadoop配置文件分发大其他机器上,使用scp
scp -r hadoop hdfs@s142:/opt/soft/hadoop/etc/
scp -r hadoop hdfs@s143:/opt/soft/hadoop/etc/
scp -r hadoop hdfs@s144:/opt/soft/hadoop/etc/
5.格式化hdfs
首先删除/tmp/下相关hadoop文件,可以直接清空,删除${hadoop_home}/logs 下日志文件
格式化文件系统
hadoop namenode -format
6.启动hadoop
start-all.sh
7.验证启动是否成功
使用jps查看进程
nn: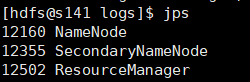
dn: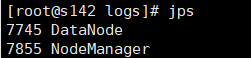
页面访问:http://192.168.30.141:50070
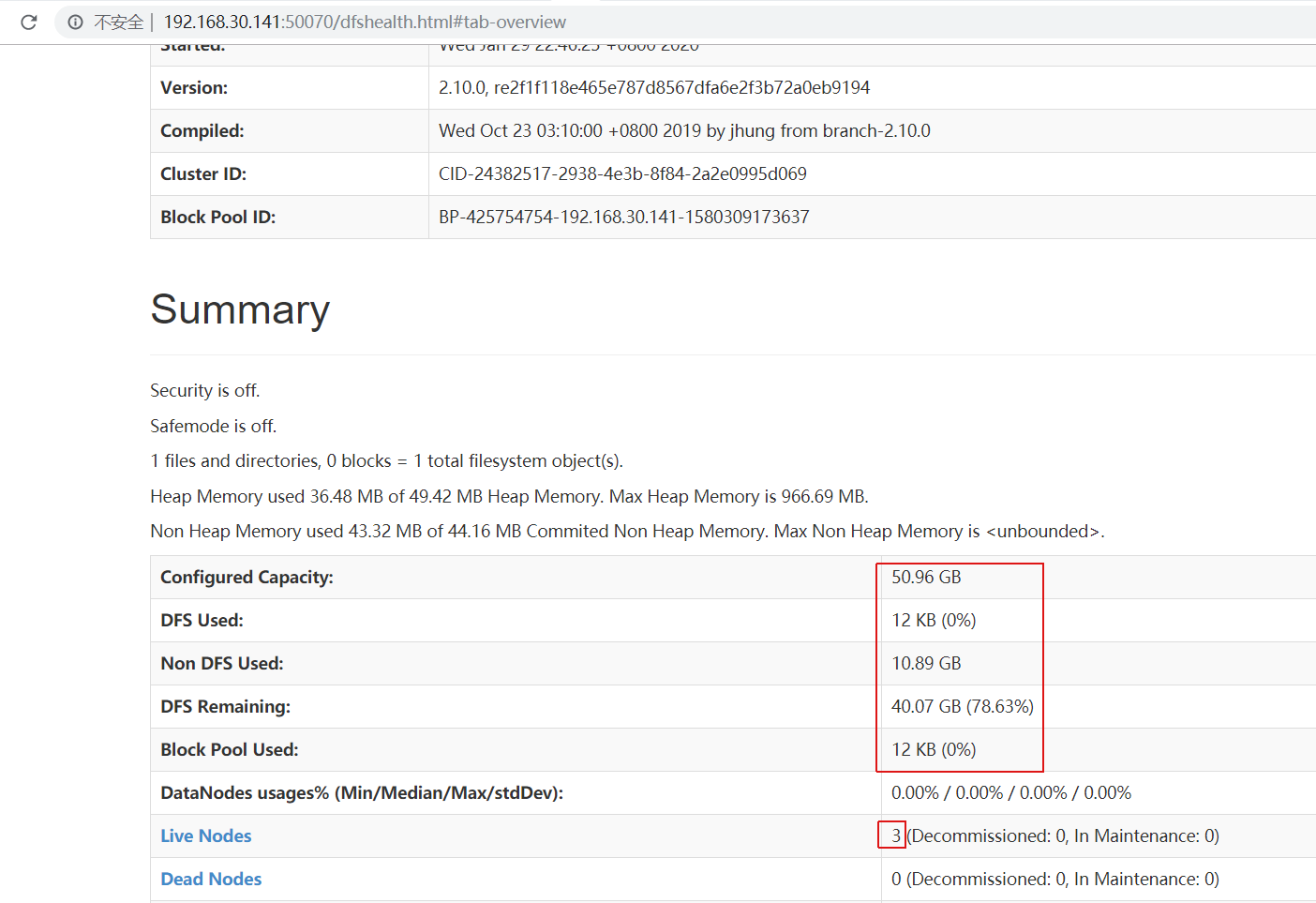
说明启动成功
centos7搭建hadoop2.10完全分布式的更多相关文章
- centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode):3台jns(journalnodes) IP hostnam ...
- centos7搭建hadoop2.10伪分布模式
1.准备一台Vmware虚拟机,添加hdfs用户及用户组,配置网络见 https://www.cnblogs.com/qixing/p/11396835.html 在root用户下 添加hdfs用户, ...
- CentOS7搭建FastDFS V5.11分布式文件系统及Java整合详细过程
1.1 FastDFS的应用场景 FastDFS是为互联网应用量身定做的一套分布式文件存储系统,非常适合用来存储用户图片.视频.文档等文件.对于互联网应用,和其他分布式文件系统相比,优势非常明显.其中 ...
- centos7搭建hadoop-2.7.3,zookeeper-3.4.6,hbase-1.2.5(root用户)
环境:[centos7.hadoop-2.7.3.zookeeper-3.4.6.hbase-1.2.5] 两个节点:[主节点,主机名为Master,用户为root:从节点,主机名为Slave,用户为 ...
- Docker中自动化搭建Hadoop2.6完全分布式集群
这一节将在<Dockerfile完成Hadoop2.6的伪分布式搭建>的基础上搭建一个完全分布式的Hadoop集群. 1. 搭建集群中需要用到的文件 [root@centos-docker ...
- CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明 示例环境 主机名 IP 角色 系统版本 数据目录 Hadoop版本 master 192.168.174.200 nameNode CentOS Linux release 7.4.1708 ...
- CentOS7搭建FastDFS V5.11分布式文件系统-第一篇
1.绪论 最近要用到fastDFS,所以自己研究了一下,在搭建FastDFS的过程中遇到过很多的问题,为了能帮忙到以后搭建FastDFS的同学,少走弯路,与大家分享一下.FastDFS的作者淘宝资深架 ...
- CentOS7搭建FastDFS V5.11分布式文件系统(二)
1.CentOS7 FastDFS搭建 前面已下载好了要用到的工具集,下面就可以开始安装了: 如果安装过程中出现问题,可以下载我提供的,当前测试可以通过的工具包: 点这里点这里 1.1 安装libfa ...
- CentOS7搭建FastDFS V5.11分布式文件系统(一)
1.绪论 最近要用到fastDFS,所以自己研究了一下,在搭建FastDFS的过程中遇到过很多的问题,为了能帮忙到以后搭建FastDFS的同学,少走弯路,与大家分享一下.FastDFS的作者淘宝资深架 ...
随机推荐
- h5 datalist标签获取值
今天使用datalist标签时,想要获得选中的值,发现使用datalist标签上的val()输出结果一直都是空的 后面改用配套的input获得值 代码如下 <!DOCTYPE html> ...
- redis哈希操作
用户可以通过执行hset命令为哈希中的指定字段设置值: 127.0.0.1:6379> hset hash field value 根据给定的字段是否存在于散列中,hset命令的行为也会有所不同 ...
- eclipse从svn导入静态文件
1.从eclipse 选择 导入 2.选择仓库和项目,选择finish 3.选择project项目导出
- CSS学习(9)块盒模型应用
1.改变宽高范围 默认情况下,width和height设置的是内容盒的宽高 页面重构师:将psd文件(设计稿)制作为静态页面 衡量设计稿尺寸的时候,往往使用的是边框盒 CSS3中 box-sizing ...
- js的基本分类(0.1)
js分内嵌,内联,外部样式表三种, js的组成分,ES(变量,函数,对象,数组,判断,循环),BOM(浏览器对象模型),DOM(文档对象模型), js的五种输出语句,alert(警告框),confir ...
- js将后台传入得时间格式化
//格式化时间函数Date.prototype.Format = function (fmt) { var o = { "M+": this.getMonth() + 1, //月 ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之D ...
- Python学习之面向对象进阶
面向对象进阶当然是要谈谈面向对象的三大特性:封装.继承.多态 @property装饰器 python虽然不建议把属性和方法都设为私有的,但是完全暴露给外界也不好,这样,我们给属性赋值的有效性九无法保证 ...
- 《实战Java高并发程序设计》读书笔记三
第三章 JDK并发包 1.同步控制 重入锁:重入锁使用java.util.concurrent.locks.ReentrantLock类来实现,这种锁可以反复使用所以叫重入锁. 重入锁和synchro ...
- appium可通过SDK自带的uiautomatorviewer或monitor工具,来查看页面元素(Android)
工具一:uiautomatorviewer 1.在SDK的tools目录中找到uiautomatorviewer,双击打开若出现闪退一般是jdk版本不匹配(建议安装jdk1.8的): 2.在使用这个工 ...