ShardingJDBC的基本配置和使用
原创不易,如需转载,请注明出处https://www.cnblogs.com/baixianlong/p/12644027.html,希望大家多多支持!!!
一、ShardingSphere介绍
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。详细一点的介绍直接看官网:https://shardingsphere.apache.org/document/current/cn/overview/
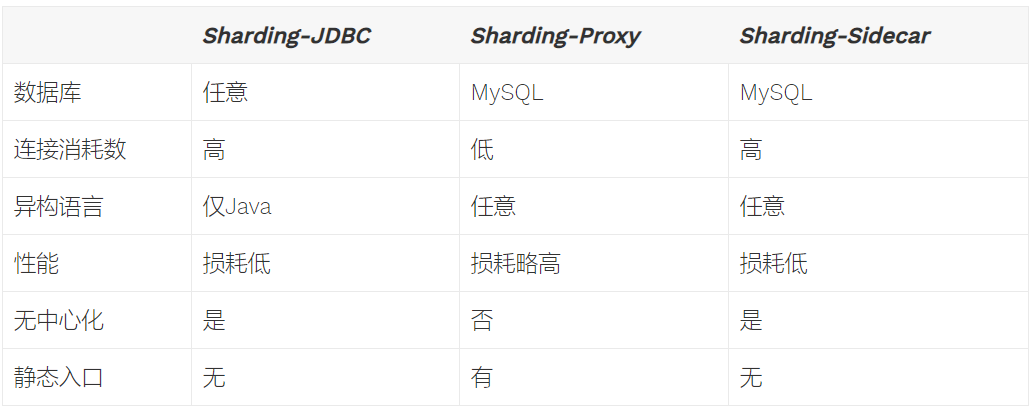
本章我们主要探讨如何集成ShardingJDBC, 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。特点如下:
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
二、Springboot整合ShardingJDBC
方式一:基于配置文件集成,方便简单但是不够灵活,这种方式直接看代码:https://github.com/xianlongbai/sharding-jdbc-boot-demo
<!--主要有以下依赖,分库分表策略直接在application.properties做相关配置即可-->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0.M1</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>3.1.0.M1</version>
</dependency>
方式二:这里我们主要基于java config的方式来集成到springboot中,更适合学习和理解。直接上代码:
//相关依赖
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>3.1.0</version>
</dependency>
<!--<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-transaction-2pc-xa</artifactId>
<version>3.1.0</version>
</dependency>-->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-orchestration</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-orchestration-reg-zookeeper-curator</artifactId>
<version>3.1.0</version>
</dependency>
//数据源、分库分表总体配置
@Configuration
@MapperScan(basePackages = "com.bxl.dao.shardingDao", sqlSessionTemplateRef = "shardingSqlSessionTemplate")
public class ShardingDataSourceConfig {
private static final Logger logger = LoggerFactory.getLogger(ShardingDataSourceConfig.class);
//这里直接注入你项目中配置的数据源
@Resource
private DataSource dataSourceOne;
@Resource
private DataSource dataSourceTwo;
//注释掉的先不用看,后边会介绍
@Bean(name = "shardingDataSource")
public DataSource dataSource() throws SQLException {
TransactionTypeHolder.set(TransactionType.LOCAL);
//1、指定需要分库分表的数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds0", dataSourceOne);
dataSourceMap.put("ds1",dataSourceTwo);
//2、分库分表配置
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
//2.1、配置默认自增主键生成器
shardingRuleConfig.setDefaultKeyGenerator(new DefaultKeyGenerator());
//2.2、配置各个表的分库分表策略,这里只配了一张表的就是t_order
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
//2.3、配置绑定表规则列表,级联绑定表代表一组表,这组表的逻辑表与实际表之间的映射关系是相同的
// shardingRuleConfig.getBindingTableGroups().add("t_order","t_order_item");
//2.4、配置广播表规则列表,利用广播小表提高性能
// shardingRuleConfig.getBroadcastTables().add("t_config");
//2.5、配置默认分表规则
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new NoneShardingStrategyConfiguration());
//2.6、配置默认分库规则(不配置分库规则,则只采用分表规则)
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new NoneShardingStrategyConfiguration());
//2.7、配置默认数据源
shardingRuleConfig.setDefaultDataSourceName("ds0");
//2.8、配置读写分离规则
// shardingRuleConfig.setMasterSlaveRuleConfigs();
//3、属性配置项,可以为以下属性
Properties propertie = new Properties();
//是否打印SQL解析和改写日志
propertie.setProperty("sql.show",Boolean.TRUE.toString());
//用于SQL执行的工作线程数量,为零则表示无限制
propertie.setProperty("executor.size","4");
//每个物理数据库为每次查询分配的最大连接数量
propertie.setProperty("max.connections.size.per.query","1");
//是否在启动时检查分表元数据一致性
propertie.setProperty("check.table.metadata.enabled","false");
//4、用户自定义属性
Map<String, Object> configMap = new HashMap<>();
configMap.put("effect","分库分表");
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig,configMap,propertie);
//5、数据治理
//5.1、配置注册中心
// RegistryCenterConfiguration regConfig = new RegistryCenterConfiguration();
// regConfig.setServerLists("localhost:2181");
// regConfig.setNamespace("sharding-sphere-orchestration");
//regConfig.setDigest("data-centre");
//5.2、配置数据治理
// OrchestrationConfiguration orchConfig = new OrchestrationConfiguration("orchestration-sharding-data-source", regConfig, true);
//5.3、获取数据源对象
// DataSource dataSource = OrchestrationShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, configMap, propertie, orchConfig);
return dataSource;
}
@Bean(name = "shardingSqlSessionFactory")
public SqlSessionFactory sqlSessionFactorySharding(@Qualifier("shardingDataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setConfigLocation(new PathMatchingResourcePatternResolver().getResource("classpath:mybatis/mybatis-config.xml"));
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mybatis/mapper/shardingMapper/**/*.xml"));
return bean.getObject();
}
//本地事务
@Bean(name = "shardingTransactionManagerLOCAL")
public PlatformTransactionManager transactionManagerLocal(@Qualifier("shardingDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
//XA事务
// @Bean(name = "shardingTransactionManagerXA")
// public ShardingTransactionManager transactionManagerXA(@Qualifier("shardingDataSource") DataSource dataSource) {
// return new AtomikosTransactionManager();
// }
@Bean(name = "shardingSqlSessionTemplate")
public SqlSessionTemplate sqlSessionTemplateThree(@Qualifier("shardingSqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
/**
* Sharding提供了5种分片策略:
* StandardShardingStrategyConfiguration:标准分片策略, 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
* ComplexShardingStrategyConfiguration:复合分片策略, 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
* InlineShardingStrategyConfiguration:Inline表达式分片策略, 使用Groovy的Inline表达式,提供对SQL语句中的=和IN的分片操作支持
* HintShardingStrategyConfiguration:通过Hint而非SQL解析的方式分片的策略
* NoneShardingStrategyConfiguration:不分片的策略
* Sharding提供了以下4种算法接口:
* PreciseShardingAlgorithm
* RangeShardingAlgorithm
* HintShardingAlgorithm
* ComplexKeysShardingAlgorithm
* @return
*/
TableRuleConfiguration getOrderTableRuleConfiguration() {
TableRuleConfiguration result = new TableRuleConfiguration();
//1、指定逻辑索引(oracle/PostgreSQL需要配置)
// result.setLogicIndex("order_id");
//2、指定逻辑表名
result.setLogicTable("t_order");
//3、指定映射的实际表名
result.setActualDataNodes("ds${0..1}.t_order_${0..1}");
//4、配置分库策略,缺省表示使用默认分库策略
result.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id","ds${user_id % 2}"));
//result.setDatabaseShardingStrategyConfig(new HintShardingStrategyConfiguration(new OrderDataBaseHintShardingAlgorithm()));
//5、配置分表策略,缺省表示使用默认分表策略
result.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order_${order_id % 2}"));
//result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("order_id",new orderPreciseShardingAlgorithm(),new orderRangeShardingAlgorithm()));
//result.setTableShardingStrategyConfig(new ComplexShardingStrategyConfiguration("order_id,user_id",new orderComplexKeysShardingAlgorithm()));
//result.setTableShardingStrategyConfig(new HintShardingStrategyConfiguration(new OrderTableHintShardingAlgorithm()));
//6、指定自增字段以及key的生成方式
result.setKeyGeneratorColumnName("order_id");
result.setKeyGenerator(new DefaultKeyGenerator());
return result;
}
//PreciseShardingAlgorithm接口实现(用于处理 = 和 in 的路由)
class orderPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
logger.info("collection:" + JSON.toJSONString(collection) + ",preciseShardingValue:" + JSON.toJSONString(preciseShardingValue));
for (String name : collection) {
if (name.endsWith(preciseShardingValue.getValue() % collection.size() + "")) {
logger.info("return name:"+name);
return name;
}
}
return null;
}
}
//RangeShardingAlgorithm接口实现(用于处理BETWEEN AND分片),这里的核心是找出这个范围的数据分布在那些表(库)中
class orderRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
logger.info("Range collection:" + JSON.toJSONString(collection) + ",rangeShardingValue:" + JSON.toJSONString(rangeShardingValue));
Collection<String> collect = new ArrayList<>();
Range<Long> valueRange = rangeShardingValue.getValueRange();
for (Long i = valueRange.lowerEndpoint(); i <= valueRange.upperEndpoint(); i++) {
for (String each : collection) {
if (each.endsWith(i % collection.size() + "")) {
collect.add(each);
}
}
}
return collect;
}
}
//ComplexShardingStrategy支持多分片键
class orderComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm{
@Override
public Collection<String> doSharding(Collection<String> collection, Collection<ShardingValue> shardingValues) {
logger.info("collection:" + JSON.toJSONString(collection) + ",shardingValues:" + JSON.toJSONString(shardingValues));
Collection<Long> orderIdValues = getShardingValue(shardingValues, "order_id");
Collection<Long> userIdValues = getShardingValue(shardingValues, "user_id");
List<String> shardingSuffix = new ArrayList<>();
/**例如:根据 user_id + order_id 双分片键来进行分表*/
//Set<List<Integer>> valueResult = Sets.cartesianProduct(userIdValues, orderIdValues);
for (Long userIdVal : userIdValues) {
for (Long orderIdVal : orderIdValues) {
String suffix = userIdVal % 2 + "_" + orderIdVal % 2;
collection.forEach(x -> {
if (x.endsWith(suffix)) {
shardingSuffix.add(x);
}
});
}
}
return shardingSuffix;
}
private Collection<Long> getShardingValue(Collection<ShardingValue> shardingValues, final String key) {
Collection<Long> valueSet = new ArrayList<>();
Iterator<ShardingValue> iterator = shardingValues.iterator();
while (iterator.hasNext()) {
ShardingValue next = iterator.next();
if (next instanceof ListShardingValue) {
ListShardingValue value = (ListShardingValue) next;
/**例如:根据user_id + order_id 双分片键来进行分表*/
if (value.getColumnName().equals(key)) {
return value.getValues();
}
}
}
return valueSet;
}
}
//表的强制分片策略
class OrderTableHintShardingAlgorithm implements HintShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection<String> collection, ShardingValue shardingValue) {
logger.info("collection:" + JSON.toJSONString(collection) + ",shardingValues:" + JSON.toJSONString(shardingValue));
Collection<String> result = new ArrayList<>();
String logicTableName = shardingValue.getLogicTableName();
ListShardingValue<Integer> listShardingValue = (ListShardingValue<Integer>) shardingValue;
List<Integer> list = Lists.newArrayList(listShardingValue.getValues());
String res = logicTableName + "_" + list.get(0);
result.add(res);
return result;
}
}
//库的强制分片策略
class OrderDataBaseHintShardingAlgorithm implements HintShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection<String> collection, ShardingValue shardingValue) {
logger.info("collection:" + JSON.toJSONString(collection) + ",shardingValues:" + JSON.toJSONString(shardingValue));
Collection<String> result = new ArrayList<>();
ListShardingValue<Integer> listShardingValue = (ListShardingValue<Integer>) shardingValue;
List<Integer> list = Lists.newArrayList(listShardingValue.getValues());
for (String db : collection) {
if (db.endsWith(list.get(0).toString())) {
result.add(db);
}
}
return result;
}
}
//分布式唯一主键
@Bean("myKeyGenerator")
public KeyGenerator keyGenerator() {
return new DefaultKeyGenerator();
}
}
以上就是springboot基于mybatis整合ShardingJdbc的基本配置,其中就是关于t_order表的分库分表最简单的一个配置,使用和平常一样。关于mybatis的配置就不多说了,我简单粘一下我的dao层和xml。只需要注意一点就是我们在写sql的时候,表明使用的是逻辑表明,像这里就是使用的t_order,而实际在我的库里存的是t_order_0,t_order_1
//编写我们的dao层接口,具体对应的对应的sql写在xml中
@Repository
public interface OrderDao {
void saveToOne(Order order);
List<Order> findAllData();
List<Order> findByIds(List<Long> list);
List<Order> findByBetween(Map<String, Object> map);
List<Order> findByOrderIdAndUserId(Map<String, Object> param);
void updateByOrderIds(Map<String, Object> map);
void deleteByOrderIds(long[] longs);
}
//对应的OrderMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.bxl.dao.shardingDao.OrderDao" >
<insert id="saveToOne" parameterType="com.bxl.entity.Order" useGeneratedKeys="true" keyProperty="orderId">
insert into t_order(`order_id`, `user_id`)
values (#{orderId}, #{userId})
</insert>
<select id="findAllData" resultType="com.bxl.entity.Order">
SELECT
`order_id` orderId,
`user_id` userId
FROM t_order
</select>
<select id="findByIds" resultType="com.bxl.entity.Order" parameterType="java.lang.Long">
SELECT
`order_id` orderId,
`user_id` userId
FROM t_order where order_id in
<foreach collection="list" item="item" index="index" open="(" separator="," close=")">
#{item}
</foreach>
</select>
<select id="findByBetween" resultType="com.bxl.entity.Order" parameterType="java.util.Map">
SELECT
`order_id` orderId,
`user_id` userId
FROM t_order where order_id BETWEEN #{start} AND #{end}
</select>
<select id="findByOrderIdAndUserId" resultType="com.bxl.entity.Order" parameterType="java.util.Map">
SELECT
`order_id` orderId,
`user_id` userId
FROM t_order where order_id = #{orderId} and user_id = #{userId}
</select>
<update id="updateByOrderIds" parameterType="java.util.Map">
update t_order set user_id=#{userId} where order_id in
<foreach collection="orderIds" item="item" index="index" open="(" separator="," close=")" >
#{item}
</foreach>
</update>
<delete id="deleteByOrderIds" parameterType="java.lang.Long">
delete from t_order where order_id in
<foreach collection="array" item="item" index="index" open="(" separator="," close=")" >
#{item}
</foreach>
</delete>
</mapper>
//建表语句
CREATE TABLE `t_order_0` (
`order_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
这个简单的样例我们是基于InlineShardingStrategyConfiguration分片策略来做的,它可以通过使用Groovy的Inline表达式来配置自己的分片策略,提供对SQL语句中的=和IN的分片操作支持,但不支持between,但可以转化为>、<来完成类似的查询。
三、ShardingJDBC提供了5种分片策略及分片算法
分片策略包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
- StandardShardingStrategyConfiguration:标准分片策略, 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
- ComplexShardingStrategyConfiguration:复合分片策略, 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
- InlineShardingStrategyConfiguration:Inline表达式分片策略, 使用Groovy的Inline表达式,提供对SQL语句中的=和IN的分片操作支持
- HintShardingStrategyConfiguration:通过Hint而非SQL解析的方式分片的策略
- NoneShardingStrategyConfiguration:不分片的策略
分片键用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
分片算法支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。四种算法接口如下:
- PreciseShardingAlgorithm:精确分片算法,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
- RangeShardingAlgorithm:范围分片算法,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
- HintShardingAlgorithm:Hint分片算法,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
- ComplexKeysShardingAlgorithm:复合分片算法,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
具体的使用特点及注意事项:
使用Inline表达式分片策略,使用相对简单的Groovy表达式就可以实现分片功能,但适合一些分片简单的场景,而且这种方式不支持between...and...的查询方式。
使用标准分片策略(常用方式),需要我们自己实现两个分片算法,即PreciseShardingAlgorithm和RangeShardingAlgorithm,这种方式就比较灵活多了,而且支持between...and...的查询方式。
使用复合分片策略,需要自己实现ComplexKeysShardingAlgorithm复合分片算法,这种方式一般用于处理使用多键作为分片键进行分片的场景。
通过强制(Hint)分片的策略,主要是为了应对分片字段不存在SQL中、数据库表结构中,而存在于外部业务逻辑,或者是为了强制在主库进行某些数据操作。这块的代码编写有点特殊:
//首先配置实现自己的强制分片算法,包括库和表,具体看上边代码
result.setDatabaseShardingStrategyConfig(new HintShardingStrategyConfiguration(new OrderDataBaseHintShardingAlgorithm()));
result.setTableShardingStrategyConfig(new HintShardingStrategyConfiguration(new OrderTableHintShardingAlgorithm())); //业务层代码,其中分片的值可以不是当前表的字段,例如可以是系统缓存的用户id等等
public void addservice() {
//基于强制路由算法进行分库分表插入数据
for (int i = 0; i < 100; i++) {
//生成分布式主键,这里利用的就是snowflake算法生成
//order.setOrderId(KeyGenerator.generateKey().longValue());
Order order = new Order();
order.setOrderId((long)i+1);
int number = new Random().nextInt(500) + 1;
order.setUserId((long) number);
try (HintManager hintManager = HintManager.getInstance()) {
//添加数据源分片键值
hintManager.addDatabaseShardingValue("t_order", 1);
//添加表分片键值
hintManager.addTableShardingValue("t_order", 1);
orderDao.saveToOne(order);
} catch (Exception e){
System.out.println("插入数据发生异常!!!");
}
}
} //查询业务
public List<Order> findAllDataByHint() {
List<Order> res = new ArrayList<>();
try (HintManager hintManager = HintManager.getInstance()) {
//分库不分表情况下,强制路由至某一个分库时,可使用hintManager.setDatabaseShardingValue方式添加分片。通过此方式添加分片键值后,将跳过SQL解析和改写阶段,从而提高整体执行效率。
//hintManager.setDatabaseShardingValue(1);
hintManager.addDatabaseShardingValue("t_order", 1);
hintManager.addTableShardingValue("t_order", 1);
//使用hintManager.setMasterRouteOnly设置主库路由,强制读主库
//在配置了主从库时,那么我们的查询逻辑会落到从库上,但有些场景必须查主库,这是就需要强制走主库查询
hintManager.setMasterRouteOnly();
res = orderDao.findAllData();
}
return res;
} //删除业务
public void deleteData() {
//强制路由下的删除操作
try (HintManager hintManager = HintManager.getInstance()) {
hintManager.addDatabaseShardingValue("t_order", 0);
hintManager.addTableShardingValue("t_order", 1);
orderDao.deleteAll();
}
}
注意:ShardingJdbc使用ThreadLocal管理分片键值进行Hint强制路由。可以通过编程的方式向HintManager中添加分片值,该分片值仅在当前线程内生效,所以需要在操作结束时调用hintManager.close()来清除ThreadLocal中的内容。由于hintManager实现了AutoCloseable接口,推荐使用try with resource自动关闭。
四、綁定表和广播表
1、绑定表
配置方式:
//在配置分库分表策略中添加如下配置,就表明将t_order和t_order_item进行了绑定
shardingRuleConfig.getBindingTableGroups().add("t_order", "t_order_item");
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
2、广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
//配置如下;
shardingRuleConfig.getBroadcastTables().add("t_config");
五、分布式主键
既然涉及到分库分表,那么如何生成一个分布式主键,这里提供几种方式供大家参考:
- 采用UUID.randomUUID()的方式产生分布式主键。
- 使用雪花算法(snowflake)生成64bit的长整型数据,雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。shardingjdbc默认支持snowflake。
- 可以采用一个集中式ID生成器,它可以是Redis,也可以是ZooKeeper,甚至是DB,缺点是复杂性太高,需要严重依赖第三方服务。
六、使用规范
路由至单数据节点:100%全兼容(目前仅MySQL,其他数据库完善中)。
路由至多数据节点:
- 全面支持DML、DDL、DCL、TCL和部分DAL。支持分页、去重、排序、分组、聚合、关联查询(不支持跨库关联)。
- 不支持CASE WHEN、HAVING、UNION (ALL),有限支持子查询。
- 运算表达式和函数中的分片键会导致全路由。
由于ShardingSphere只能通过SQL字面提取用于分片的值,因此当分片键处于运算表达式或函数中时,ShardingSphere无法提前获取分片键位于数据库中的值,从而无法计算出真正的分片值。当出现此类分片键处于运算表达式或函数中的SQL时,ShardingSphere将采用全路由的形式获取结果。 - 查询偏移量过大的分页会导致数据库获取数据性能低下,如(mysql):SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
七、关于分库分表的思考
1、分库分表为了什么?
分库分表就是为了解决由于数据量过大而导致数据库性能(IO瓶颈,CPU瓶颈)降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
2、数据库的分区、垂直分库、垂直分表、水平分库、水平分表各自解决那些问题?
分区表
- 分区表的分区方式有range、list、hash、key四种方式,但常用的是range、list方式
- 分区表可以单独对分区数据进行操作,在特定的场景下,方便对数据的老化和查询
- 分区表可以提高单表的存储,并且数据还可以分布在不同的物理设备上
垂直分库
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
垂直分表(将一张表拆成多张表)
- 为了避免IO争抢并减少锁表的几率
- 充分发挥热数据的操作效率
- 可以把不常用的字段单独放在一张表,如一些详细信息以及text,blob等大字段
水平分库
- 解决了单库大数据,高并发的性能瓶颈
- 提高了系统的稳定性及可用性
水平分表
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
3、分库分表的策略一般在什么情况下使用,使用哪种?
- 首先一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库、垂直分表的方案。
- 当数据量随着业务凉的提升不断增大,但访问压力还不是特别大的情况下,我们首先考虑缓存、读写分离、索引等技术方案。
- 当数据量增长到特别大且持续增长时,即将或者已经出现性能瓶颈时,再考虑水平分库水平分表的方案。
4、水平分库表如何解决扩容、热点问题?
- 最好的方式莫过于设计前期对数据量的正确预估和业务场景的判断,尽量避免后期出现热点问题和扩容问题。
- 对于通过hash取模方案,没有热点问题,但会出现扩容问题,解决方案有:
- 停服迁移
- 升级从库
- 双写迁移
- 对于通过range方案,无需迁移数据,但肯能出现热点问题。所以在实际业务中,我们可以通过range+hash的配合使用来达到即支持扩容又尽可能避免热点。
5、分库分表如何解决跨库事务?
- 2PC两阶段提交协议
- TCC事务补偿机制
- 最终一致性方案
- 最大努力通知型
个人博客地址:
cnblogs:https://www.cnblogs.com/baixianlong
github:https://github.com/xianlongbai
ShardingJDBC的基本配置和使用的更多相关文章
- sharding-jdbc数据分片配置
数据分片 不使用Spring 引入Maven依赖 <dependency> <groupId>org.apache.shardingsphere</groupId> ...
- sharding jdbc(sphere) 3.1.0 spring boot配置
sharding jdbc 2.x系列详解参见https://www.cnblogs.com/zhjh256/p/9221634.html. 最近将sharding jdbc的配置从xml切换到了sp ...
- Sharding-JDBC基本使用,整合Springboot实现分库分表,读写分离
结合上一篇docker部署的mysql主从, 本篇主要讲解SpringBoot项目结合Sharding-JDBC如何实现分库分表.读写分离. 一.Sharding-JDBC介绍 1.这里引用官网上的介 ...
- 一个注解解决ShardingJdbc不支持复杂SQL
背景介绍 公司最近做分库分表业务,接入了 Sharding JDBC,接入完成后,回归测试时发现好几个 SQL 执行报错,关键这几个表都还不是分片表.报错如下: 这下糟了嘛.熟悉 Sharding J ...
- (二)基于shard-jdbc中间件,实现数据分库分表
基于shard-jdbc中间件,实现数据分库分表 Sharding-JDBC简介 Sharding配置示意图 1.水平分割 1.1 水平分库 1.2 水平分表 2.Shard-jdbc中间件 2.1 ...
- 41 位 Contributor 参与,1574 个 PR,不容错过的版本更新!
6 月 25 日,在商业公司 SphereEx 正式成立一月之余的今天,我们很高兴的宣布 Apache ShardingSphere 迎来了 5.0.0-beta 版本的正式发布.经过半年多的优化和打 ...
- 分库分表利器之Sharding Sphere(深度好文,看过的人都说好)
Sharding-Sphere Sharding-JDBC 最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为 S ...
- Sharding Sphere的分库分表
什么是 ShardingSphere? 1.一套开源的分布式数据库中间件解决方案 2.有三个产品:Sharding-JDBC 和 Sharding-Proxy 3.定位为关系型数据库中间件,合理在分布 ...
- dynamic + shardingsphere(4.1.1) 实现动态分库分表
1. 主要依赖: <dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-da ...
随机推荐
- OpenCV图像增强(python)
为了得到更加清晰的图像我们需要通过技术对图像进行处理,比如使用对比度增强的方法来处理图像,对比度增强就是对图像输出的灰度级放大到指定的程度,获得图像质量的提升.本文主要通过代码的方式,通过OpenCV ...
- web前端问题整理
1.常用那几种浏览器测试?有哪些内核(Layout Engine)? (Q1)浏览器:IE,Chrome,FireFox,Safari,Opera (Q2)内核:Trident,Gecko,Prest ...
- JS如何进行对象的深克隆(深拷贝)?
JS中,一般的赋值传递的都是对象/数组的引用,并没有真正的深拷贝一个对象,如何进行对象的深拷贝呢? var a = {name : 'miay'}; var b = a; b.name = 'Jone ...
- mongoose基本增删改查
1.安装 打开命令行 npm i mongoose 2.连接数据库 // 引入安装的包 var mongoose = require('mongoose'); mongoose.connect('mo ...
- 遍历Map的四种方式(Java)
public static void main(String[] args) { Map<String, String> map = new HashMap<String, Stri ...
- Python数据科学手册(1) IPython:超越Python
1.1 shell还是Notebook Jupyter Notebook 是 IPython shell 基于浏览器的图形界面,提供了一系列丰富的动态展示功能.Jupyter Notebook 不仅可 ...
- 五分钟学Java:如何学习Java面试必考的网络编程
原创声明 本文作者:黄小斜 转载请务必在文章开头注明出处和作者. 本文思维导图 简介 Java作为一门后端语言,对于网络编程的支持是必不可少的,但是,作为一个经常CRUD的Java工程师,很多时候都不 ...
- C#读取静态类常量属性和值
1.背景最近项目中有一个需求需要从用户输入的值找到该值随对应的名字,由于其它模块已经定义了一份名字到值的一组常量,所以想借用该定义.2.实现实现的思路是采用C#支持的反射.首先,给出静态类中的常量属性 ...
- mysql索引查找原理及优化
常见查找方法 1.顺序查找(linear search ) 1. 最基本的查询算法当然是顺序查找(linear search),也就是对比每个元素的方法,不过这种算法在数据量很大时效率是极低的. 2. ...
- .NET 5 Preview 1的深度解读和跟进
这几天微软.NET 团队发布了.NET 5 Preview-1, 如约而至.很兴奋,因为.NET Core和.NET Framework终于实现了大一统,同时也很期待,期待.NET 5能给我们带来哪些 ...