Python机器学习笔记 集成学习总结
集成学习(Ensemble learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比单个学习器显著优越的泛化性能。它不是一种单独的机器学习算法啊,而更像是一种优化策略。因为单个机器学习模型所能解决的问题有限,泛化能力差,但是通过构建组合多个学习器来完成学习任务往往能够获得奇效,这些学习器可以看成一个个基本单元,由他们组合最终形成一个强大的整体,该整体可以解决更复杂的问题,其思想可以形象的概括为三个臭皮匠赛过诸葛亮。
集成学习是机器学习的一大分支,他通过建立几个模型组合来解决单一预测问题。他的工作原理是生成多个分类器模型,各个独立的学习和做出预测。这些预测最后结合成单预测,最后由任何一个单分类做出预测。
集成学习的一般结构是,先产生一组个体学习器,再用某种结合策略将他们结合起来。

集成学习是一种技术框架,其按照不同的思路来组合基础模型,从而达到其利断金的目的。目前,有三种常用的集成学习框架:bagging ,Boosting和stacking。国内南京大学的周志华教授对集成学习有很深的研究,其在09年发表的一篇概述性论文《Ensemble Learning》对这三种集成学习框架有了明确的定义,大家可以百度搜索这篇论文。
集成学习优势
1,个体学习器之间存在一定的差异性,这会导致分类边界不同,也就是说可能存在错误。那么将多个个体学习器合并后,就可以得到更加合理的边界,减少整体的错误率,实现更好的效果。
2,对于数据集过大或者过小的情况,可以分别进行划分和有放回的操作,产生不同的数据子集,然后使用数据子集训练不同的学习器,最终再合并成为一个强学习器;
3,如果数据的划分边界过于复杂,使用线性模型很难描述情况,那么可以训练多个模型,然后再进行模型的融合。
4,对于多个异构的特征集的时候,很难直接融合,那么可以考虑使用每个数据集构建一个分类模型,然后将多个模型融合。
常见的集成学习框架
根据上述所说的单个学习器的产生过程不同,集成学习大致可以分为两类:串行,并行
串行:个体学习器们的产生依赖彼此,比如当前学习器的产生依赖上一个学习器的参数,所以最终将单个学习器们组合形式可以看做是串行序列化方法,代表是Boosting。
并行:个体学习器间不存在强依赖关系,可以并行化同时产生,代表是Bagging。
下面就说一下三个常用的集成学习框架:
- 1,用于减少方差的Bagging
- 2,用于减少偏差的Boosting
- 3,用于提升预测结果的Stacking
1,Bagging(bootstrap aggregating)
Bagging也叫自举汇聚法(bootstrap aggregating)或者套袋法,指从训练集中进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果 (说白了就是并行训练一堆分类器)。最典型的代表就是随机森林了。
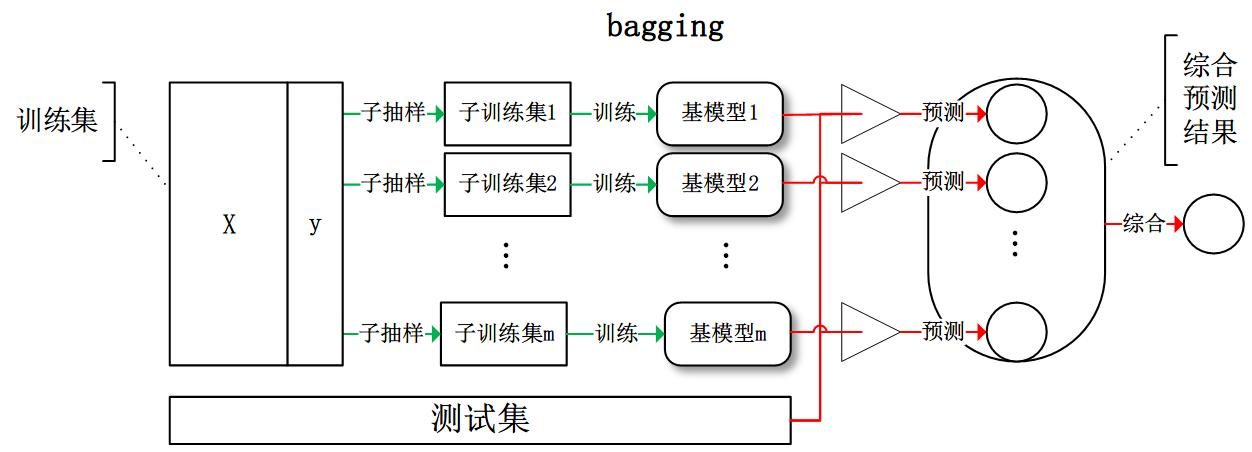
或者这个图:
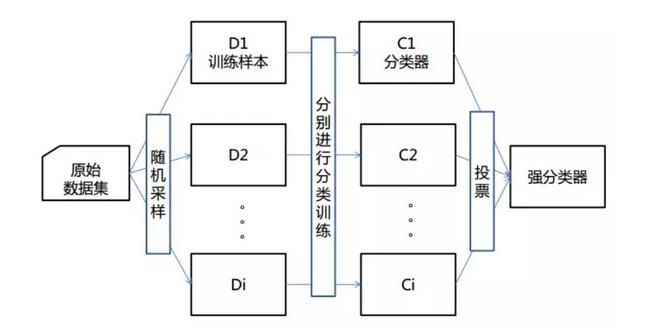
Bagging是一种在原始数据集上通过有放回抽样重新选出K个新数据集来训练分类器的集成技术。它使用训练出来的分类器的集合来对新样本进行分类,然后用的多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即为最终标签,此类算法可以有效降低bias,并能够降低variance。
1.1 Bagging的算法步骤
Bagging算法过程如下:
(A) 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootsraping的方法抽取n个训练样本(在初始训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽取中)。共进行K轮抽取,得到K个训练集(k 个训练集之间是相互独立的),其中初始训练集中约有63.2%的样本出现在采样集中。
(B)每次使用一个训练集得到一个模型,K个训练集共得到K个模型(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或者回归方法,如决策树,感知器等)
(C)对于分类问题:将上步得到的K个模型采用投票的方式得到分类结果;
对于回归问题:计算上述模型的均值作为最后的结果(所有模型的重要性相等)

Bagging的优点:
- 1,训练一个Bagging集成与直接使用基分类器算法训练一个学习器的复杂度同阶,说明Bagging是一个高效的集成学习算法
- 2,与标准的Adaboost算法只适用于二分类问题不同,Bagging能不经过修改用于多分类,回归等任务
- 3,由于每个基学习器只使用了 63.2%的数据,所以剩下的36.8%的数据可以用来做验证集来对泛化性能进行“包外估计”
1.2 Bagging的偏差和方差
Bagging:训练多个分类器取平均,其函数如下
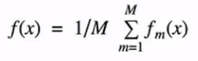
对于bagging来说,每个基模型的权重等于1/m且期望近似相等(子训练集都是从原训练集进行子抽样),故我们可以进一步简化得到:
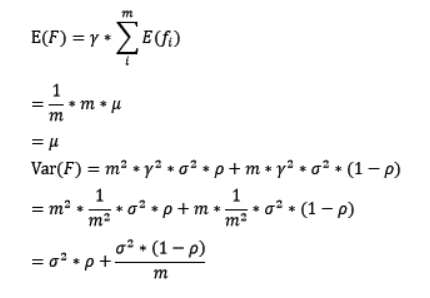
根据上式我们可以看到,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
简单来说:Boosting 主要关注减少偏差,而Bagging主要关注降低方差,也说明Boosting在弱学习器上表现更好,而降低方差可以减少过拟合的风险,所以Bagging通常在强分类和复杂模型上表现的很好。
1.3 Bagging框架的代表算法——随机森林
这里不详细学习随机森林,如果想学习可以参考我的博客,里面详细学习了随机森林:
Python机器学习笔记——随机森林算法
RandomForest 是典型的基于bagging框架的模型,其在bagging的基础上,进一步降低了模型的方差。RandomForest 中基模型是树模型,在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,第一项显著降低,第二项稍微增加,整体方差仍然减少。
随机森林简单分析一下:随机:数据采用随机,特征选择随机;森林:很多个决策树并行放在一起。
在随机森林中,集成中的每棵树都是从训练集中抽取的样本(即bootstrap样本)构建的。另外,与使用所有特征不同,这里随机选择特征子集,从而进一步达到对树的随机化目的。因此,随机森林产生的偏差略有增加,但是由于对相关性较小的树计算平均值,估计方差减少了,导致模型的整体效果更好。比如构造树模型,由于二重随机性,使得每个树基本上都不会一样,最终的结果也会不一样,我们用图展示如下
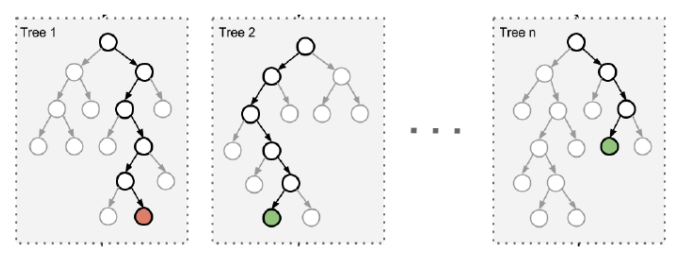
那么一个简化的随机森林树如下:

Bagging模型之所以要进行随机,是要保证泛化能力,如果树都一样,那就没意义了。下面说一下随机森林的优势:
- 1,它能够处理很高维度(feature很多)的数据,并且不用做特征选择
- 2,在训练完后,它能够给出哪些 feature比较重要
- 3,容易做成并行化方法,速度比较快
- 4,可以进行可视化展示,便于分析
Bagging与随机森林的比较:
两者的收敛性相似,但是RF的起始性能相对较差,特别是只有一个基学习器时,随着基学习器的数量的增加,随机森林通常会收敛到更低的泛化误差。随机森林的训练效率常由于Bagging,因为Bagging是“确定性”决策树,而随机森林使用“随机性”决策树。
其实Bagging模型不止有随机森林,还可以集成KNN模型,决策树模型,如下:

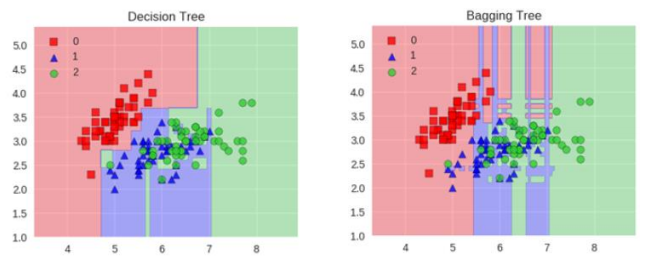
但是一般KNN模型不适合做集成学习,因为很难去随机让泛化能力变强!
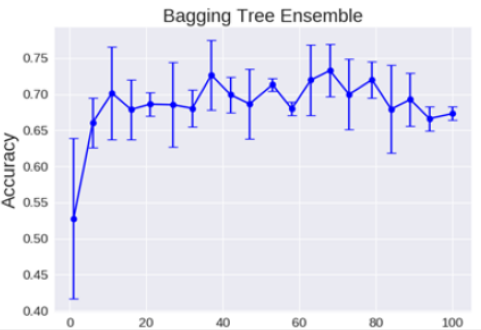
理论上越多的树效果会越好,但是实际上基本超过一定数量的就差不多上下浮动了。
下面我们可以看一个随着树的数量增加,模型的Bagging集成树的准确率:
1.4 sklearn中 bagging 的分析
在sklearn中Bagging算法的函数及其参数意义(官方文档):
(这里以分类为例,回归就直接去官网看吧)
- class BaggingClassifier(BaseBagging, ClassifierMixin):
- """
- Parameters
- ----------
- base_estimator : object or None, optional (default=None)
- The base estimator to fit on random subsets of the dataset.
- If None, then the base estimator is a decision tree.
- n_estimators : int, optional (default=10)
- The number of base estimators in the ensemble.
- max_samples : int or float, optional (default=1.0)
- The number of samples to draw from X to train each base estimator.
- - If int, then draw `max_samples` samples.
- - If float, then draw `max_samples * X.shape[0]` samples.
- max_features : int or float, optional (default=1.0)
- The number of features to draw from X to train each base estimator.
- - If int, then draw `max_features` features.
- - If float, then draw `max_features * X.shape[1]` features.
- bootstrap : boolean, optional (default=True)
- Whether samples are drawn with replacement. If False, sampling
- without replacement is performed.
- bootstrap_features : boolean, optional (default=False)
- Whether features are drawn with replacement.
- oob_score : bool, optional (default=False)
- Whether to use out-of-bag samples to estimate
- the generalization error.
- warm_start : bool, optional (default=False)
- When set to True, reuse the solution of the previous call to fit
- and add more estimators to the ensemble, otherwise, just fit
- a whole new ensemble. See :term:`the Glossary <warm_start>`.
- .. versionadded:: 0.17
- *warm_start* constructor parameter.
- n_jobs : int or None, optional (default=None)
- The number of jobs to run in parallel for both `fit` and `predict`.
- ``None`` means 1 unless in a :obj:`joblib.parallel_backend` context.
- ``-1`` means using all processors. See :term:`Glossary <n_jobs>`
- for more details.
- random_state : int, RandomState instance or None, optional (default=None)
- If int, random_state is the seed used by the random number generator;
- If RandomState instance, random_state is the random number generator;
- If None, the random number generator is the RandomState instance used
- by `np.random`.
- verbose : int, optional (default=0)
- Controls the verbosity when fitting and predicting.
这里以iris数据集为例,代码如下:
- from sklearn.ensemble import BaggingClassifier
- from sklearn.tree import DecisionTreeClassifier
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
- from sklearn.svm import SVC
- iris = datasets.load_iris()
- X, y = iris.data[:, 1:3], iris.target
- X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
- clf = DecisionTreeClassifier()
- clfb = BaggingClassifier(base_estimator=DecisionTreeClassifier(),
- max_samples=0.5, max_features=0.5)
- clfb1 = BaggingClassifier(base_estimator=SVC(),
- max_samples=0.5, max_features=0.5)
- model1 = clf.fit(X, y)
- model2 = clfb.fit(X, y)
- model3 = clfb1.fit(X, y)
- predict = model1.score(X_test, y_test)
- predictb = model2.score(X_test, y_test)
- predictb1 = model3.score(X_test, y_test)
- print(predict) # 1.0
- print(predictb) # 0.9473684210526315
- print(predictb1) # 0.9210526315789473
讲道理,这里集成效果还不如决策树单个分类效果。
2,Boosting模型
Boosting的思想源于1986年Valiant提出的PCA(probably Approximately Correct)学习模型。Valiant和Kearns提出了弱学习和强学习的概念。识别错误率小于1/2,也即准确率仅比随机猜测略高的学习算法称为弱学习算法;识别准确率很高并能在多项式时间内完成的学习算法称为强学习算法。同时,Valiant和Kearns首次提出了PAC学习模型中弱学习算法和强学习算法的等价性问题,即任意给定仅比随机猜测略好的弱学习算法就可以将其提升为强学习算法,而不必寻找很难获得的强学习算法。1990年,Schapire最先构造出一种多项式级的算法,对该问题做了肯定的证明,这就是最初的Boosting算法。一年后,Freund提出了一种效率更高的Boosting算法。但是这两种算法存在共同的实践上的缺陷,那就是都要求事先知道弱学习算法学习正确的下限,1995年,Freund和schap ire改进了Boosting算法,提出了AdaBoost(Adap tive Boosting)算法,该算法效率和Freund于1991年提出的Boosting算法几乎相同,但是不需要任何关于弱分类器的先验知识,因而更容易应用到实际问题当中。
Boosting模型的训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转换。对所有基模型预测的结果进行线性综合产生最终的预测结果。Boosting模型的典型代表:AdaBoost,XGBoost,其中AdaBoost会根据前一次的分类效果调整数据权重
2.1 Boosting模型的工作机制
这一类算法的工作机制大致如下:先从初始训练集练出一个集学习器,再根据即学习器的表现对训练样本进行调整,使得先前基学习器做错的样子在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值,最终将这T个基学习器进行加权结合。
Boosting模型简单来说就是如果在某一个数据在这次分错了,那么在下一次我就会给他更大的权重,最终的结果就是:每个分类器根据自身的准确性来确定各自的权重,再合体。
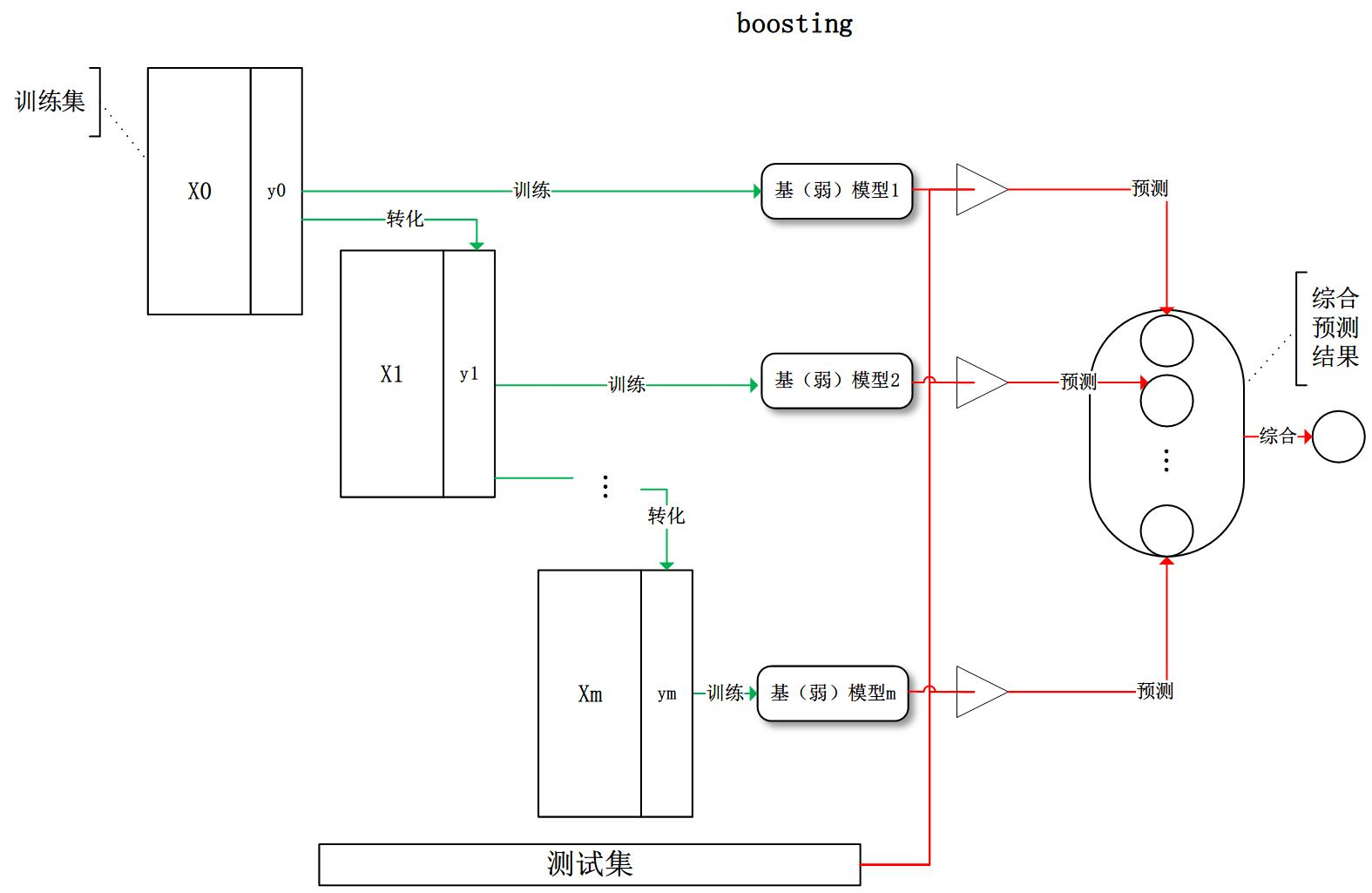
2.2 Boosting模型的两个核心问题
Boosting模型的主要思想是将弱分类器组装成一个强分类器。在PAC(概率近似正确)学习框架下,则一定可以将弱分类器组装成一个强分类器。关于Boosting的两个核心问题:
(1)在每轮如何改变训练数据的权值或者概率分布?
通过提高哪些在前一轮被弱分类器分错样例的权值,减少前一轮分对样本的权值,来使得分类器对误分的数据有较好的效果
(2)通过什么方式来组合弱分类器
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减少错误率较大的分类器的权值。而提升树通过拟合残差的方式逐步减少残差,将每一步生成的模型叠加得到最终模型。
对于分类问题而言,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易的多。Boosting方法就是从“弱学习器”出发,反复学习,得到一系列弱分类器,然后组合这些分类器,构成一个强分类器。
2.3 Boosting算法的偏差和方差
Boosting:从弱学习器开始加强,通过加权来进行训练
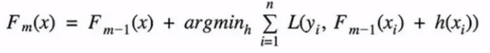
对于boosting来说,基模型的训练抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对Boosting化简公式:
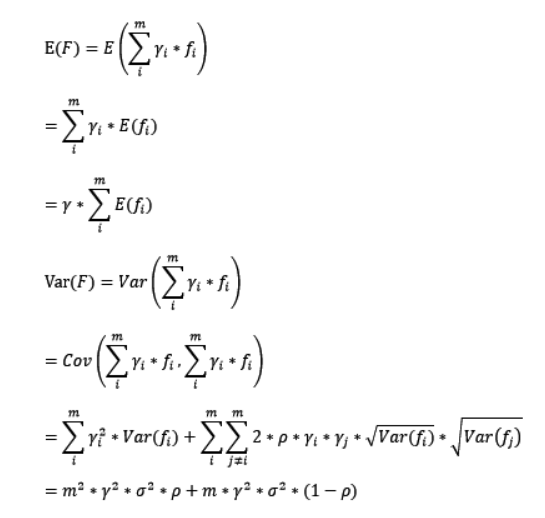
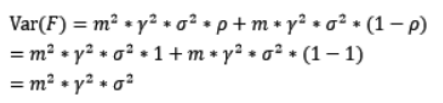
通过观察整体方差的表达式,我们容易发现,若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大。即无法达到防止过拟合的效果。因此,Boosting框架中的基模型必须为弱模型。
因为基模型为弱模型,导致了每个基模型的准确度都不是很高(因为其在训练集上的准确度不高)。随着基模型数的增多,整体模型的期望值增加,更接近真实值。因此,整体模型的准确度提高。但是准确度一定会无限逼近于1吗?让然并不一定,因为训练过程中的准确度提高,而随着训练的进行,整体模型的方差变大,导致防止过拟合的能力变弱,最终导致了准确度反而有所下降。
基于Boosting框架的Gradient Tree Boosting 模型中基模型也为树模型,同Random Forest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
2.4 Boosting框架的代表算法——XGBoost算法,Adaboost算法
XGBoost, Adaboost的具体内容这里也不说了,具体可以参考我的博文:
Python机器学习笔记:XgBoost算法
Python机器学习笔记:Adaboost算法
这里简单的学习一下Adaboost的工作流程:就是每次切一刀,最终合在一起,弱分类器这就升级了
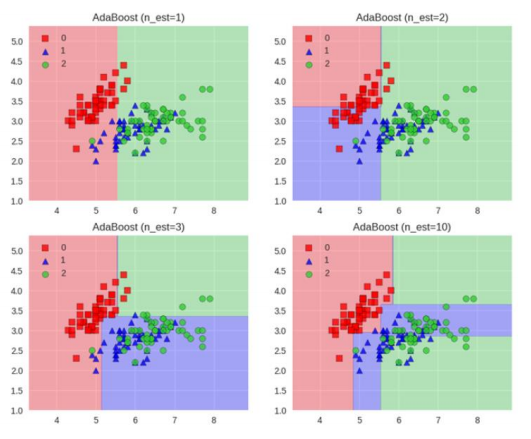
这里主要涉及两个权重的计算问题:
(1) 样本的权值
- 没有先验知识的情况下,初始的分布应为等概分布,样本数目为n,权值为1/n
- 每一次的迭代更新权值,提高分错样本的权重
(2) 弱学习器的权值
- 最后的强学习器是通过多个基学习器通过权值组合得到的
- 通过权值体现不同基学习器的影响,正确率高的基学习器权重高,实际上是分类误差的一个函数
3,Stacking模型
在Stacking中,我们把个体学习器称为初级学习器,用于结合的学习器称为次学习器或者元学习器。
Stacking的主要思想为:先从初始数据集训练处初级学习器,然后‘生成’一个新的数据集用于训练次级学习器。生成的该数据中,初级学习器的输入被当做样例输入特征,而初始样本的标记仍然被当做样例标记。也就是说,假设初级学习器有M个,那么对于一个原始数据集中的样本(x, y),通过M个初级学习器有M个输出{h1(x),h2(x),...,hM(x)},把{h1(x),h2(x),...,hM(x); y}当做新数据的一个样本,所以一个初级学习器的输出作为新数据集中对应样本的一个特征,而其标记为原始数据中该样本的标记。
stacking:聚合多个分类或回归模型(可以分阶段来做),从名字就可以知道是堆叠,很暴力,拿来一堆直接上(各种分类器就都来了)。可以堆叠各种各样的分类器(KNN,SVM,RF等等)。下面看看其算法描述(来自周志华《机器学习》),假定初级学习器使用不同的算法,如LR,RF,SVM,GBDT等。

Stacking将训练好的所有基模型进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测。
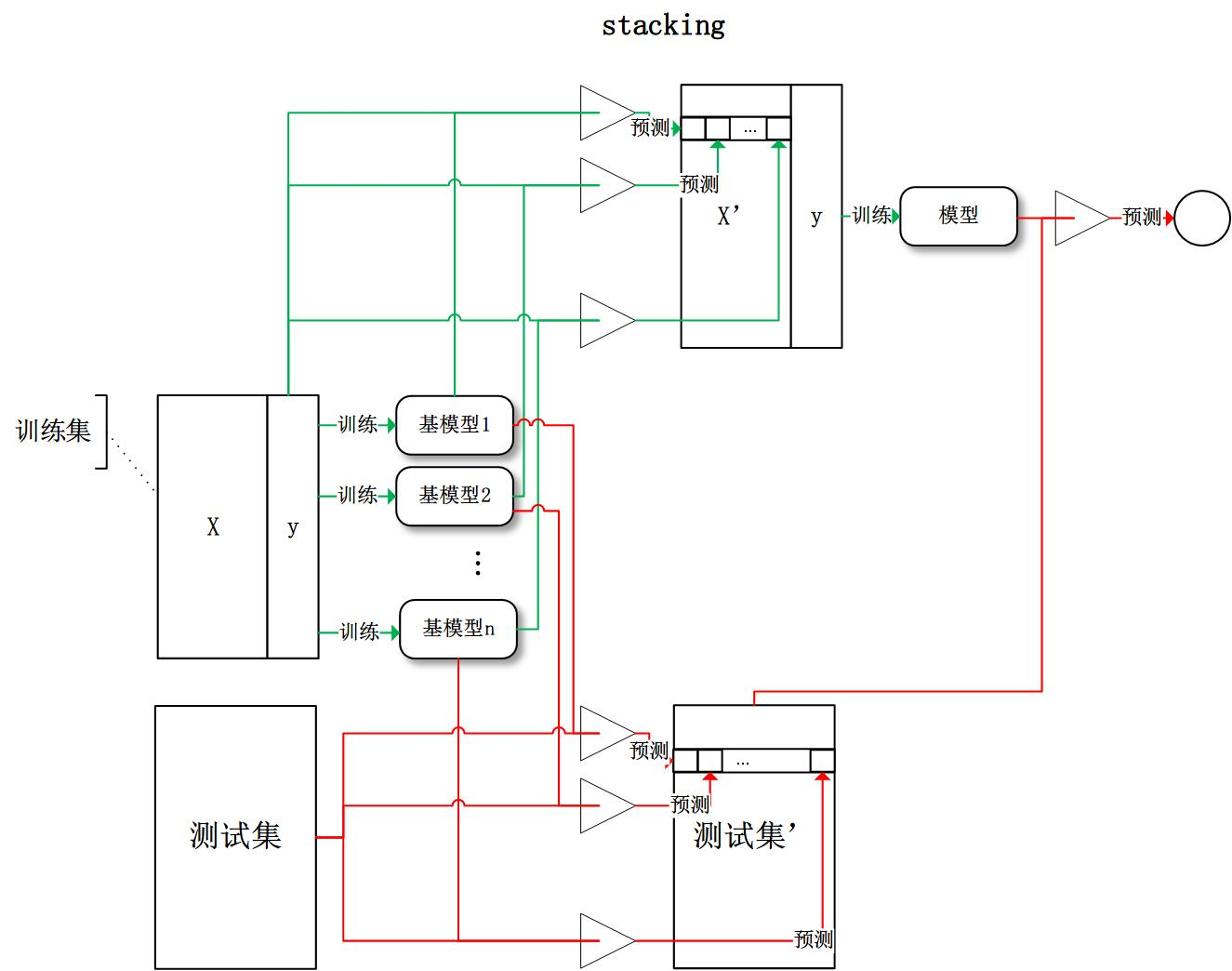
下面学习一个堆叠算法的常用套路:stacking模型分为两个阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练。
怎么理解呢?如下图所示:
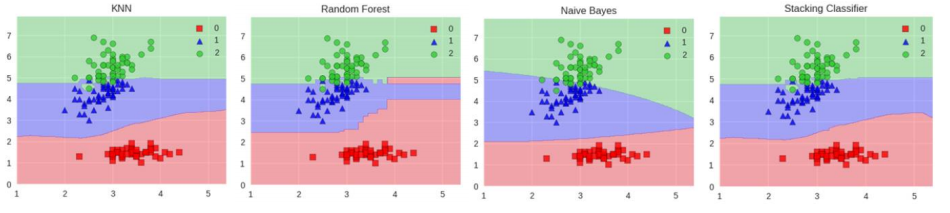
第一个阶段就是:假设我们有三个算法:KNN, RF, NB,得到了三个分类器的各自的结果
第二个阶段就是:三个分类器有三个结果,而我们只需要最终的值,所以我们需要对第一阶段各个分类器做的结果当做第二个阶段的输入,假设我们利用LR,得到最终的分类结果,就是最终的Stacking分类器结果。
在训练阶段,次级学习器(用来结合结果的学习器)的训练数据集是利用初级学习器来产生的,若直接用初级学习器的训练集来产生训练数据集,则很有可能出现过拟合,也就是过拟合风险较大;所以一般在使用stacking时,采用交叉验证或留一法的方式,用训练初级学习器未使用的样本来产生次级学习器的训练样本,下面以K=5折交叉验证为例:

首先把整个数据集分成训练集(Training Data)和测试集(Test Data)两部分,上图最左边,然后把训练数据集进行k折,此处k=5,即把训练数据分成五分,在进行第j折的时候,使用其余四份进行初级学习器的训练,得到一个初级学习器,并用该初始学习器把该折(即留下用来验证的)数据进行预测,进行完所有的折数,把预测输出作为新数据集的特征,即次级学习器的训练数据集,其中标记没变,用该新的数据集训练次级学习器,从而得到一个完整的stacking,最后用原始数据的测试集来对该stacking进行测试估计。
次级学习器的输入属性表示和次基学习算法的选择对Stacking集成的泛化性能有很大影响。有研究表明,将初级学习器的输出类概率作为次级学习器的输入属性,用多响应线性回归(Multi-reponse Linear Regression,简称MLR)作为次级学习器算法效果更好,在MLR中使用不同的属性集更好。
注意:MLR是基于线性回归的分类器,其对每个类分别进行线性回归,属于该类的训练样本所对应的输出为1,其他类置为零,测试示例将被分给输出值最大的类。
堆叠算法是可以防止过拟合的,但是具体防止多少呢?其实我们并不知道,因为各个算法的防止过拟合的效果并不明确。堆叠算法将各个算法堆叠在一起确实可以使得准确率提高,但是缺点也很明显,就是速度问题。不过集成算法是竞赛与论文神奇,当我们更关注结果时不妨可以试试,所以说为了刷结果,不择手段。哈哈哈。
sklearn中 StackingClassifier
做stacking,首先需要安装mlxtend库。安装方法:进入Anaconda Prompt,输入命令 pip install mlxtend 即可。
stacking的函数如下:
- class StackingClassifier(_BaseXComposition, _BaseStackingClassifier,
- TransformerMixin)
函数的参数及意义如下(意思明显,这里就不再翻译了):
- Parameters
- ----------
- classifiers : array-like, shape = [n_classifiers]
- A list of classifiers.
- Invoking the `fit` method on the `StackingClassifer` will fit clones
- of these original classifiers that will
- be stored in the class attribute
- `self.clfs_`.
- meta_classifier : object
- The meta-classifier to be fitted on the ensemble of
- classifiers
- use_probas : bool (default: False)
- If True, trains meta-classifier based on predicted probabilities
- instead of class labels.
- drop_last_proba : bool (default: False)
- Drops the last "probability" column in the feature set since if `True`,
- because it is redundant:
- p(y_c) = 1 - p(y_1) + p(y_2) + ... + p(y_{c-1}).
- This can be useful for meta-classifiers that are sensitive to
- perfectly collinear features. Only relevant if `use_probas=True`.
- average_probas : bool (default: False)
- Averages the probabilities as meta features if `True`.
- Only relevant if `use_probas=True`.
- verbose : int, optional (default=0)
- Controls the verbosity of the building process.
- - `verbose=0` (default): Prints nothing
- - `verbose=1`: Prints the number & name of the regressor being fitted
- - `verbose=2`: Prints info about the parameters of the
- regressor being fitted
- - `verbose>2`: Changes `verbose` param of the underlying regressor to
- self.verbose - 2
- use_features_in_secondary : bool (default: False)
- If True, the meta-classifier will be trained both on the predictions
- of the original classifiers and the original dataset.
- If False, the meta-classifier will be trained only on the predictions
- of the original classifiers.
- store_train_meta_features : bool (default: False)
- If True, the meta-features computed from the training data used
- for fitting the meta-classifier stored in the
- `self.train_meta_features_` array, which can be
- accessed after calling `fit`.
- use_clones : bool (default: True)
- Clones the classifiers for stacking classification if True (default)
- or else uses the original ones, which will be refitted on the dataset
- upon calling the `fit` method. Hence, if use_clones=True, the original
- input classifiers will remain unmodified upon using the
- StackingClassifier's `fit` method.
- Setting `use_clones=False` is
- recommended if you are working with estimators that are supporting
- the scikit-learn fit/predict API interface but are not compatible
- to scikit-learn's `clone` function.
最基本的使用方法,如上面所讲,我们使用RF,SVR作为基分类器进行分类,然后用LR对基类的结果进行分类,得到最终的结果,这里我们以鸢尾花数据为例(这里官网的例子,我稍作修改):
- from mlxtend.classifier import StackingClassifier
- from sklearn.datasets import load_iris
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.svm import LinearSVC
- from sklearn.linear_model import LogisticRegression
- from sklearn.preprocessing import StandardScaler
- from sklearn.pipeline import make_pipeline
- from sklearn.model_selection import train_test_split
- X, y = load_iris(return_X_y=True)
- estimators = [
- RandomForestClassifier(n_estimators=10, random_state=42),
- make_pipeline(StandardScaler(),
- LinearSVC(random_state=42))]
- clf = StackingClassifier(
- classifiers=estimators,
- meta_classifier=LogisticRegression()
- )
- X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
- model = clf.fit(X_train, y_train)
- score = model.score(X_test, y_test)
- print(score) # 0.868421052631579
stacking的几种使用方法
下面使用代码来展示stacking的几种使用方法。
1,最基本的使用方法就是使用基分类器所产生的预测类别作为 meta-classifier特征的输入数据(其实和上面代码差不多)
- from sklearn import datasets
- iris = datasets.load_iris()
- X, y = iris.data[:, 1:3], iris.target
- from sklearn import model_selection
- from sklearn.linear_model import LogisticRegression
- from xgboost.sklearn import XGBClassifier
- import lightgbm as lgb
- from sklearn.ensemble import RandomForestClassifier
- from mlxtend.classifier import StackingClassifier
- import numpy as np
- basemodel1 = XGBClassifier()
- basemodel2 = lgb.LGBMClassifier()
- basemodel3 = RandomForestClassifier(random_state=1)
- lr = LogisticRegression()
- sclf = StackingClassifier(classifiers=[basemodel1, basemodel2, basemodel3],
- meta_classifier=lr)
- print('5-fold cross validation:\n')
- for basemodel, label in zip([basemodel1, basemodel2, basemodel3, sclf],
- ['xgboost',
- 'lightgbm',
- 'Random Forest',
- 'StackingClassifier']):
- scores = model_selection.cross_val_score(basemodel,X, y,
- cv=5, scoring='accuracy')
- print("Accuracy: %0.2f (+/- %0.2f) [%s]"
- % (scores.mean(), scores.std(), label))
2,第二种方法就是使用第一层所有基分类器所产生的类别概率值作为 meta-classifier的输入,需要在StackingClassifer 中增加一个参数设置: use_probas=True。
那么这些基分类器所产出的概率值将按照列被平均,否则会拼接。
例如:
基分类器1:predictions=[0.2,0.2,0.7]
基分类器2:predictions=[0.4,0.3,0.8]
基分类器3:predictions=[0.1,0.4,0.6]
1)若 use_probas=True,average_probas=True,则产生的 meta-feature 为 [0.233, 0.3, 0.7]
2)若use_probas=True, average_probas=False,则产生的 meta-feature为:[0.2,0.2,0.7,0.4,0.3,0.8,0.1,0.4,0.6]
- from sklearn import datasets
- iris = datasets.load_iris()
- X, y = iris.data[:, 1:3], iris.target
- from sklearn import model_selection
- from sklearn.linear_model import LogisticRegression
- from xgboost.sklearn import XGBClassifier
- import lightgbm as lgb
- from sklearn.ensemble import RandomForestClassifier
- from mlxtend.classifier import StackingClassifier
- import numpy as np
- basemodel1 = XGBClassifier()
- basemodel2 = lgb.LGBMClassifier()
- basemodel3 = RandomForestClassifier(random_state=1)
- lr = LogisticRegression()
- sclf = StackingClassifier(classifiers=[basemodel1, basemodel2, basemodel3],
- use_probas=True,
- average_probas=False,
- meta_classifier=lr)
- print('5-fold cross validation:\n')
- for basemodel, label in zip([basemodel1, basemodel2, basemodel3, sclf],
- ['xgboost',
- 'lightgbm',
- 'Random Forest',
- 'StackingClassifier']):
- scores = model_selection.cross_val_score(basemodel,X, y,
- cv=5, scoring='accuracy')
- print("Accuracy: %0.2f (+/- %0.2f) [%s]"
- % (scores.mean(), scores.std(), label))
3,这一种方法是对基分类器训练的特征维度进行操作的,并不是给每个基分类器全部的特征,而是赋予不同的基分类器不同的特征。比如:基分类器1训练前半部分的特征,基分类器2训练后半部分的特征。这部分的操作时通过 sklearn中 popelines实现。最终通过StackingClassifier组合起来。
- from sklearn.datasets import load_iris
- from mlxtend.classifier import StackingClassifier
- from mlxtend.feature_selection import ColumnSelector
- from sklearn.pipeline import make_pipeline
- from sklearn.linear_model import LogisticRegression
- from xgboost.sklearn import XGBClassifier
- from sklearn.ensemble import RandomForestClassifier
- iris = load_iris()
- X = iris.data
- y = iris.target
- #基分类器1:xgboost
- pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)),
- XGBClassifier())
- #基分类器2:RandomForest
- pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)),
- RandomForestClassifier())
- sclf = StackingClassifier(classifiers=[pipe1, pipe2],
- meta_classifier=LogisticRegression())
- sclf.fit(X, y)
4,结合策略
通过上面,我们对集成学习算法也有了大概的了解,简单来说,集成算法就是训练一堆基学习器,然后通过某种策略把各个基学习器的结果进行合成,从而得到集成学习器的结果。下面学习一下常用的结合策略。
4.1,平均法(Averaging)
对于数值型(连续)输出 hi(x)€ R ,最常见的结合策略为平均法。
——简单平均法(Sample averaging)
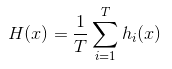
——加权平均法(weighted averaging)
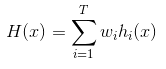
其中 Wi 为权重,通常Wi 要求:
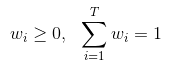
注意:加权平均法的权重一般从训练数据中学习而得,对规模比较大的集成学习来说,要学习的权重比较多,比较容易过拟合,因此加权平均法就不一定优于简单平均法。一般而言,在个体学习器性能相差比较大时宜使用加权平均法,而在个体学习器性能相近时宜使用简单平均法。
4.2 投票法(Voting)
对于分类来说,学习器 hi(x) 将从类别集合中预测出一个类别标记,最常用的是投票法。投票法的基本思想就是组合不同的机器学习模型,通过投票或者平均的方法预测最后的标签。分类的机器学习算法输出有两种类型:一种是直接输出类标签,另外一种是输出类概率,使用前者进行投票叫做硬投票(Majority/Hard voting),使用后者进行分类叫做软投票(Soft voting)。
——绝对多数投票法(majority/Hard voting)
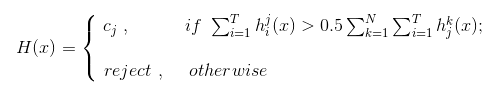
即如果某标记的投票过半数,则预计为该标记(直接输出标签);否则拒绝预测。
——相对多数投票法(plurality voting)
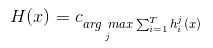
即预测为得票最多的标记,若同时出现多个票数最多,则任选其一(在算法中会将预测标签升序排列,选最上面的)。
——加权投票法(weighted voting)
与加权平均法类似。对分类器进行分配权重,这个权重不是我们自己分配的,是通过训练数据得到的。
sklearn代码实现投票法
首先我们看看其函数和参数意义:
- class VotingClassifier(_BaseVoting, ClassifierMixin):
- """Soft Voting/Majority Rule classifier for unfitted estimators.
- .. versionadded:: 0.17
- Read more in the :ref:`User Guide <voting_classifier>`.
- Parameters
- ----------
- estimators : list of (string, estimator) tuples
- Invoking the ``fit`` method on the ``VotingClassifier`` will fit clones
- of those original estimators that will be stored in the class attribute
- ``self.estimators_``. An estimator can be set to ``None`` or ``'drop'``
- using ``set_params``.
- voting : str, {'hard', 'soft'} (default='hard')
- If 'hard', uses predicted class labels for majority rule voting.
- Else if 'soft', predicts the class label based on the argmax of
- the sums of the predicted probabilities, which is recommended for
- an ensemble of well-calibrated classifiers.
- weights : array-like, shape (n_classifiers,), optional (default=`None`)
- Sequence of weights (`float` or `int`) to weight the occurrences of
- predicted class labels (`hard` voting) or class probabilities
- before averaging (`soft` voting). Uses uniform weights if `None`.
- n_jobs : int or None, optional (default=None)
- The number of jobs to run in parallel for ``fit``.
- ``None`` means 1 unless in a :obj:`joblib.parallel_backend` context.
- ``-1`` means using all processors. See :term:`Glossary <n_jobs>`
- for more details.
- flatten_transform : bool, optional (default=True)
- Affects shape of transform output only when voting='soft'
- If voting='soft' and flatten_transform=True, transform method returns
- matrix with shape (n_samples, n_classifiers * n_classes). If
- flatten_transform=False, it returns
- (n_classifiers, n_samples, n_classes).
下面用iris例子来测试:
- from sklearn.linear_model import LogisticRegression
- from sklearn.datasets import load_iris
- from sklearn.ensemble import RandomForestClassifier, VotingClassifier
- from sklearn.naive_bayes import GaussianNB
- from sklearn.model_selection import train_test_split
- X, y = load_iris().data, load_iris().target
- X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
- clf1 = LogisticRegression(random_state=1)
- clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
- clf3 = GaussianNB()
- # 绝对少数服从多数原则投票 如果某标记的投票过半数,则预计为该标记;否则拒绝预测
- eclf1 = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
- voting='hard')
- model1 = eclf1.fit(X_train, y_train)
- score1 = model1.score(X_test, y_test)
- print(score1) # 0.9210526315789473
- # 相对少数服从多数原则投票 预测为得票最多的标记,若同时出现多个票数最多,则任选其一
- eclf2 = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
- voting='soft')
- model2 = eclf2.fit(X_train, y_train)
- score2 = model2.score(X_test, y_test)
- print(score2) # 0.9210526315789473
- # 使用加权投票法
- eclf3 = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
- voting='soft', weights=[2, 1, 1], flatten_transform=True)
- model3 = eclf3.fit(X_train, y_train)
- score3 = model3.score(X_test, y_test)
- print(score3) # 0.9210526315789473
对于iris数据集来说,效果差别不大。
4.3 学习法
当数据很多时,一种更为强大的结合策略是使用“学习法”,即通过另一个学习器来结合。其中典型代表为Stacking。
注意:Stacking 本身就是一种出名的集成学习方法,且有不少集成学习方法可以认为是其变体或者特例,stacking也可以认为是一种结合策略。Stacking的具体内容见上面。
5,集成学习的总结
集成学习概述图:

4.1 Bagging和Boosting的区别
Bagging和Boosting都是将已有的分类或者回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法。Bagging(并行)和Boosting(串行)是两种常见的集成学习方法,这两者的区别在于集成的方式是并行还是串行。那下面我们详细的说一下二者的区别:
(1)样本选择上
- Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
(2)样例权重:
- Bagging:使用均匀取样,每个样例的权重相等
- Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
(3)预测函数:
- Bagging:所有预测函数的权重相等。
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
(4)并行计算:
- Bagging:各个预测函数可以并行生成
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
这两种方法都是将若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果,将不同的分类算法套入到此类算法框架中一定程度上会提高原单一分类器的分类效果,但是也增大了计算量。
4.2 模型的独立性
那么如何衡量基模型的独立性?我们说过,抽样的随机性决定了模型的随机性,如果两个模型的训练集抽样过程不独立,则这两个模型则不独立。这时候便有一个天大的陷阱在等着我们:bagging中基模型的训练样本都是独立的随机 抽样,但是基模型却不独立呢?
我们讨论模型的随机性时,抽样是针对样本的整体,而bagging中的抽样是针对于训练集(整体的子集)所以并不能称其为对整体的独立随机抽样,那么到底bagging中的基模型的相关性体现在哪呢?原作者总结bagging的抽样分为两个过程:
- 样本抽样:整体模型F(X1,X2,X3...Xn) 中各输入随机变量(X1,X2,X3...Xn)对样本的抽样
- 子抽样:从整体模型F(X1,X2,X3....Xn)中随机抽取若干输入随机变量成为基模型的输入随机变量
假若子抽样的过程中,两个基模型抽取的输入随机变量有一定的重合,那么这两个基模型对整体样本的抽样将不再独立,这时基模型之间便有了相关性。
4.3,模型的偏差和方差是什么?
广义的偏差(bias)描述的是预测值和真实值之间的差异,方差(variance)描述距的是预测值作为随机变量的离散程度。
模型的偏差是一个相对来说简单的概念:训练出来的模型在训练集上的准确度。
要解释模型的方差,首先需要重新审视模型:模型是随机变量。设样本容量为n的训练集为随机变量的集合(X1,X2,...Xn),那么模型是以这些随机变量为输入的随机变量函数(其本身仍然是随机变量):F(X1,X2,....Xn)。抽样的随机性带来了模型的随机性。
定义随机变量的值的差异是计算方差的前提条件,通常来说,我们遇到的都是数值型的随机变量,数值之间的差异再明显不过(减法运算)。但是模型之间的差异性呢?我们可以理解模型的差异性为模型的结构差异,例如:线性模型中权值向量的差异,树模型中树的结构差异等。在研究模型方差的问题上,我们并不需要对方差进行定量计算,只需要知道其概念即可。
研究模型的方差有什么现实的意义呢?我们认为方差越大的模型越容易过拟合:假设有两个训练集A和B,经过A训练的模型Fa与经过B训练的模型Fb差异很大。这意味着Fa在类A的样本集合上有更好的性能,而Fb反之,这边是我们所说的过拟合现象。
我们常说集成学习框架中的基模型是弱模型,通常来说弱模型是偏差高(在训练集上准确度低)方差小(防止过拟合能力强)的模型。但是,并不是所有集成学习框架中的基模型都是弱模型。bagging和stacking中的基模型为强模型(偏差低方差高),Boosting中的基模型为弱模型。
在bagging和Boosting框架中,通过计算基模型的期望和方差,我们可以得到模型整体的期望和方差。为了简化模型,我们假设基模型的权重,方差及两两间的相关关系相等,具体上面已经学习过了,这里就不再赘述了。
完整代码及其数据,请移步小编的GitHub
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote
关于sklearn中其他的集成分类器,请参考:https://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble 这里不再一一测试,参数意思大同小异。
参考文献:https://blog.csdn.net/weixin_42001089/article/details/84935462
https://blog.csdn.net/xuxiatian/article/details/53648751
http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html
http://www.cnblogs.com/jasonfreak/p/5657196.html
https://blog.csdn.net/perfect1t/article/details/83684995
https://www.cnblogs.com/Christina-Notebook/p/10063146.html
此学习笔记主要参考上面博文与《机器学习》这本书,结合大家的博文,我将自己的笔记整理于此。
Python机器学习笔记 集成学习总结的更多相关文章
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- Python机器学习笔记:使用Keras进行回归预测
Keras是一个深度学习库,包含高效的数字库Theano和TensorFlow.是一个高度模块化的神经网络库,支持CPU和GPU. 本文学习的目的是学习如何加载CSV文件并使其可供Keras使用,如何 ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- Python机器学习笔记:SVM(1)——SVM概述
前言 整理SVM(support vector machine)的笔记是一个非常麻烦的事情,一方面这个东西本来就不好理解,要深入学习需要花费大量的时间和精力,另一方面我本身也是个初学者,整理起来难免思 ...
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- Python机器学习笔记:奇异值分解(SVD)算法
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 奇异值分解(Singu ...
随机推荐
- python学习基础知识
学习python前最好知道的知识点: python之父:Guido van Rossum python是一种面向对象语言 目前python最新的版本是3.8,python2已经逐渐淘汰 python的 ...
- 利用EPX Studio将C/S程序转成B/S的方法详解(在线模块方式)
采用 EPX 的在线模块,是最简单的方法,包括实现简单,客户端不需任何设置,客户使用就简单. 1. 设置服务器端参数(EPServer) 1.1 在服务配置工具选项卡中,设置服务项中的名称,路径,激活 ...
- Java8 Stream流
第三章 Stream流 <Java8 Stream编码实战>的代码全部在https://github.com/yu-linfeng/BlogRepositories/tree/master ...
- [剑指Offer]41.和为S的两个数字 VS 和为S的连续正数序列
[剑指Offer]41 和为S的两个数字 VS 和为S的连续正数序列 Leetcode T1 Two Sum Given an array of integers, return indices of ...
- AdFind
C++实现(未开源),用于查询域内信息 http://www.joeware.net/freetools/tools/adfind/index.htm 常用命令如下: 列出域控制器名称: AdFind ...
- MS15-034漏洞复现、HTTP.SYS远程代码执行漏洞
#每次命令都百度去找命令,直接弄到博客方便些: 漏洞描述: 在2015年4月安全补丁日,微软发布的众多安全更新中,修复了HTTP.sys中一处允许远程执行代码漏洞,编号为:CVE-2015-1635( ...
- 洛谷1258 Tire字典树
直接上代码: #include<bits/stdc++.h> using namespace std; typedef unsigned int ui; typedef long long ...
- IOS(苹果手机)使用video播放HLS流,实现在内部播放及全屏播放(即非全屏和全屏播放)。
需求: 实现PC及移动端播放HLS流,并且可以自动播放,在页面内部播放及全屏播放功能. 初步:PC及安卓机使用hls.js实现hls流自动播放及全屏非全屏播放 首先使用了hls.js插件,可以实现在P ...
- 北邮oj 104. 912星球的研究生
104. 912星球的研究生 时间限制 1000 ms 内存限制 65536 KB 题目描述 最近912星球的研究生入学了,912星球的教务处因此忙的焦头烂额,要求yzr做一个信息管理系统登陆查询研究 ...
- 答应我,不会这些概念,简历不要写 “熟悉” zookeeper
整理了一些Java方面的架构.面试资料(微服务.集群.分布式.中间件等),有需要的小伙伴可以关注公众号[程序员内点事],无套路自行领取 一口气说出 9种 分布式ID生成方式,面试官有点懵了 面试总被问 ...