K近邻算法:机器学习萌新必学算法
摘要:K近邻(k-NearestNeighbor,K-NN)算法是一个有监督的机器学习算法,也被称为K-NN算法,由Cover和Hart于1968年提出,可以用于解决分类问题和回归问题。
1. 为什么要学习k-近邻算法
k-近邻算法,也叫KNN算法,是一个非常适合入门的算法
拥有如下特性:
● 思想极度简单
● 应用数学知识少(近乎为零)
● 对于各位开发者来说,很多不擅长数学,而KNN算法几乎用不到数学专业知识
● 效果好
○ 虽然算法简单,但效果出奇的好
○ 缺点也是存在的,后面会进行讲解
● 可以解释机器学习算法使用过程中的很多细节问题
○我们会利用KNN算法打通机器学习算法使用过程,研究机器学习算法使用过程中的细节问题
● 更完整的刻画机器学习应用的流程
○ 对比经典算法的不同之处
○ 利用pandas、numpy学习KNN算法
2. 什么是K-近邻算法
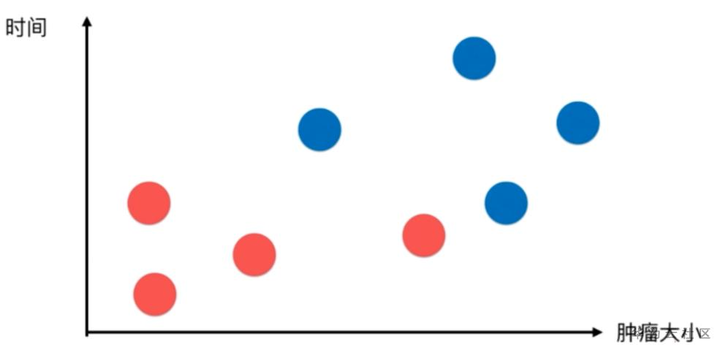
上图中的数据点是分布在一个特征空间中的,通常我们使用一个二维的空间演示
横轴表示肿瘤大小,纵轴表示发现时间。
恶性肿瘤用蓝色表示,良性肿瘤用红色表示。
此时新来了一个病人
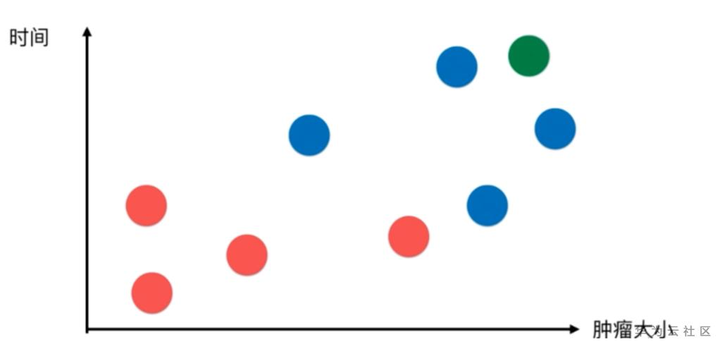
如上图绿色的点,我们怎么判断新来的病人(即绿色点)是良性肿瘤还是恶性肿瘤呢?
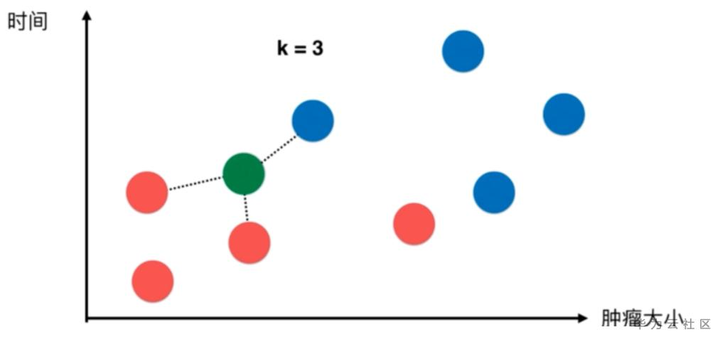
k-近邻算法的做法如下:
取一个值k=3(此处的k值后面介绍,现在大家可以理解为机器学习的使用者根据经验取得了一个经验的最优值)。
k近邻判断绿色点的依据就是在所有的点中找到距离绿色点最近的三个点,然后让最近的点所属的类别进行投票,我们发现,最近的三个点都是蓝色的,所以该病人对应的应该也是蓝色,即恶性肿瘤。
本质:两个样本足够相似,那么他们两个就具有更高概率属于同一个类别。
但如果只看一个,可能不准确,所以就需要看K个样本,如果K个样本中大多数属于同一个类别,则被预测的样本就很可能属于对应的类别。这里的相似性就依靠举例来衡量。
这里我再举一个例子
● 上图中和绿色的点距离最近的点包含两个红色和一个蓝色,此处红色点和蓝色点的数量比为2:1,则绿色点为红色的概率最大,最后判断结果为良性肿瘤。
● 通过上述发现,K近邻算法善于解决监督学习中的分类问题
K近邻算法:机器学习萌新必学算法的更多相关文章
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- K近邻 Python实现 机器学习实战(Machine Learning in Action)
算法原理 K近邻是机器学习中常见的分类方法之间,也是相对最简单的一种分类方法,属于监督学习范畴.其实K近邻并没有显式的学习过程,它的学习过程就是测试过程.K近邻思想很简单:先给你一个训练数据集D,包括 ...
- k近邻算法(k-nearest neighbor,k-NN)
kNN是一种基本分类与回归方法.k-NN的输入为实例的特征向量,对应于特征空间中的点:输出为实例的类别,可以取多类.k近邻实际上利用训练数据集对特征向量空间进行划分,并作为其分类的"模型&q ...
- K近邻算法小结
什么是K近邻? K近邻一种非参数学习的算法,可以用在分类问题上,也可以用在回归问题上. 什么是非参数学习? 一般而言,机器学习算法都有相应的参数要学习,比如线性回归模型中的权重参数和偏置参数,SVM的 ...
- 机器学习(Machine Learning)算法总结-决策树
一.机器学习基本概念总结 分类(classification):目标标记为类别型的数据(离散型数据)回归(regression):目标标记为连续型数据 有监督学习(supervised learnin ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
随机推荐
- spark textfile rdd 日记
批量处理模板方法, 核心处理方法为内部方法 def batchProces(sc: SparkContext, locationFlag: Int, minid: Int, maxid: Int, n ...
- 简述application.properties和application.yml 以及 @ConfigurationProperties 和@PropertySource @Value 和@ImportResource的用法,区别
问题: 如何在application.properties和application.yml中配置String,Date,Object,Map,List类型的属性,并且idea能提示 先写一个Perso ...
- Android Studio 自定义字体显示英文音标
android:fontFamily="serif" 网上查了很多自定义字体的方式,或多或少都有些麻烦,最后还是尝试着认为内置字体不应该实现不了英文音标问题,就一个一个字体试了一下 ...
- SQL错题集
查找最晚入职员工的所有信息 select * from employees where hire_date = (select max(hire_date) from employees) 查找入职员 ...
- python使用xpath(超详细)
使用时先安装 lxml 包 开始使用 和beautifulsoup类似,首先我们需要得到一个文档树 把文本转换成一个文档树对象 from lxml import etree if __name__ = ...
- matlab中fopen 打开文件或获得有关打开文件的信息
参考:https://ww2.mathworks.cn/help/matlab/ref/fopen.html?searchHighlight=fopen&s_tid=doc_srchtitle ...
- HNOI 2015 【亚瑟王】
看着洛谷里那一排任务计划,瑟瑟发抖...... 题目大意: 你有n张牌,每一张牌有一个发动的概率和造成的伤害值,游戏一共有r轮.对于每一轮游戏,你只能发动一张牌(在之前回合发动过的牌会被跳过,不予考虑 ...
- Oracle数据库中的大对象(LOB)数据类型介绍
一.LOB数据类型的介绍 大对象(LOB)数据类型允许我们保存和操作非结构化和半结构化数据,如文档.图形图像.视频片段.声音文件和XML文件等.DMBS_LOB 包被设计用于操作 LOB 数据类型.从 ...
- ansible-playbook调试
1. ansible-playbook 1)ansible-playbook的语法检测 1 [root@test-1 bin]# ansible-playbook --syntax-check ng ...
- MeteoInfoLab脚本示例:Hamawari-8 netCDF data
示例数据:ftp://ftp.bom.gov.au/anon/sample/catalogue/Satellite/IDE00220.201507140300.nc 该数据的分辨率很高(22000*2 ...