MapReduce统计每个用户的使用总流量
1、原始数据

2、使用java程序
1)新建项目
2)导包
hadoop-2.7.3\share\hadoop\mapreduce
+hsfs的那些包
+common
3、写项目
1)实体类
注:属性直接定义为String和 Long定义更方便
package com.zy.flow; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable; public class Flow implements Writable{//Writable可序列化的(序列化:把对象变成二进制流 反序列化:把二进制流变成对象)
//包含 电话 上行流量 下行流量 总流量
private Text phone;
private LongWritable upflow;//上行
private LongWritable downflow;//下行
private LongWritable sumflow;//总流量
//这个对象以后要在集群中传输,所以要可序列化 //序列化反序列化顺序要一致
@Override//反序列化时会调用该方法
public void readFields(DataInput in) throws IOException {
phone=new Text(in.readUTF());
upflow=new LongWritable(in.readLong());
downflow=new LongWritable(in.readLong());
sumflow=new LongWritable(in.readLong());
} @Override//序列化时会调用该方法
public void write(DataOutput out) throws IOException {
out.writeUTF(phone.toString());
out.writeLong(upflow.get());
out.writeLong(downflow.get());
out.writeLong(sumflow.get()); }
public Text getPhone() {
return phone;
}
public void setPhone(Text phone) {
this.phone = phone;
}
public LongWritable getUpflow() {
return upflow;
}
public void setUpflow(LongWritable upflow) {
this.upflow = upflow;
}
public LongWritable getDownflow() {
return downflow;
}
public void setDownflow(LongWritable downflow) {
this.downflow = downflow;
}
public LongWritable getSumflow() {
return sumflow;
}
public void setSumflow(LongWritable sumflow) {
this.sumflow = sumflow;
}
public Flow() { }
public Flow(Text phone, LongWritable upflow, LongWritable downflow, LongWritable sumflow) {
super();
this.phone = phone;
this.upflow = upflow;
this.downflow = downflow;
this.sumflow = sumflow;
}
public Flow(LongWritable upflow, LongWritable downflow, LongWritable sumflow) {
super();
this.upflow = upflow;
this.downflow = downflow;
this.sumflow = sumflow;
} @Override//toString最后就是reduce中输出值的样式
public String toString() {
//输出样式
return upflow+"\t"+downflow+"\t"+sumflow;
} }
2)FlowMap类
package com.zy.flow; import java.io.IOException; import javax.security.auth.callback.LanguageCallback; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class FlowMap extends Mapper<LongWritable, Text, Text, Flow>{ @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Flow>.Context context)
throws IOException, InterruptedException {
//输入的值 value
//切分value 寻找有价值的列
String[] split = value.toString().split("\t");
int length=split.length;
//取哪几列split[1] split[length-3] split[length-2]
String phone=split[1];
Long upflow=Long.parseLong(split[length-3]);
Long downflow=Long.parseLong(split[length-2]);
Long sumflow=upflow+downflow;
//输出
context.write(new Text(phone), new Flow(new Text(phone), new LongWritable(upflow), new LongWritable(downflow),new LongWritable(sumflow)));
//对象里虽然用不到phone但是要给它赋值,不然序列化时会报空指针异常
}
}
3)Part(分区)类
package com.zy.flow;
import java.util.HashMap;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
// map的输出是suffer的输入
public class Part extends Partitioner<Text, Flow> {//分区
//逻辑自己写 HashMap<String,Integer> map = new HashMap(); public void setMap(){
map.put("135",0);
map.put("136", 1);
map.put("137",2);
map.put("138", 3);
map.put("139",4);
}
// 生成的文件 part-00000 part的编号的结尾就是这个int类型的返回值;
@Override
public int getPartition(Text key, Flow value, int arg2) { setMap();
//从输入的数据中获得电话的前三位跟map对比。决定分到哪个区中
String substring = key.toString().substring(0, 3);//例如截取135 return map.get(substring)==null?5:map.get(substring);//根据键取值 键135 取出0
//其他号码分到(编号为5)第6个区中
}
//在这个逻辑下partition分了6个区,所以以后要指定6个reducetask }
4)FlowReduce类
package com.zy.flow; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class FlowReduce extends Reducer<Text, Flow, Text, Flow>{
@Override
protected void reduce(Text key, Iterable<Flow> value, Reducer<Text, Flow, Text, Flow>.Context context)
throws IOException, InterruptedException {
//累加
long allup=0;
long alldown=0;
for (Flow flow : value) {
allup+=Long.parseLong(flow.getUpflow().toString());//同一个电话的上行流量累加
alldown+=Long.parseLong(flow.getDownflow().toString());//同一个电话的下行流量累加 }
long allsum=allup+alldown;
context.write(key, new Flow(new Text(key), new LongWritable(allup), new LongWritable(alldown), new LongWritable(allsum)));
} }
5)FlowApp类
package com.zy.flow; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowApp { public static void main(String[] args) throws Exception {
//创建配置对象
Configuration configuration = new Configuration();
//得到job实例
Job job = Job.getInstance(configuration);
//指定job运行类
job.setJarByClass(FlowApp.class); //指定job中的mapper
job.setMapperClass(FlowMap.class);
//指定mapper中的输出键和值类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Flow.class); //指定job中的reducer
job.setReducerClass(FlowReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Flow.class); //-----
//指定Partitioner使用的类
job.setPartitionerClass(Part.class);
//指定ReduceTask数量
job.setNumReduceTasks(6);
//----- //指定输入文件
FileInputFormat.setInputPaths(job, new Path(args[0]));//运行时填入参数
//指定输出文件
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交作业
job.waitForCompletion(true); } }
4、运行
1)打包
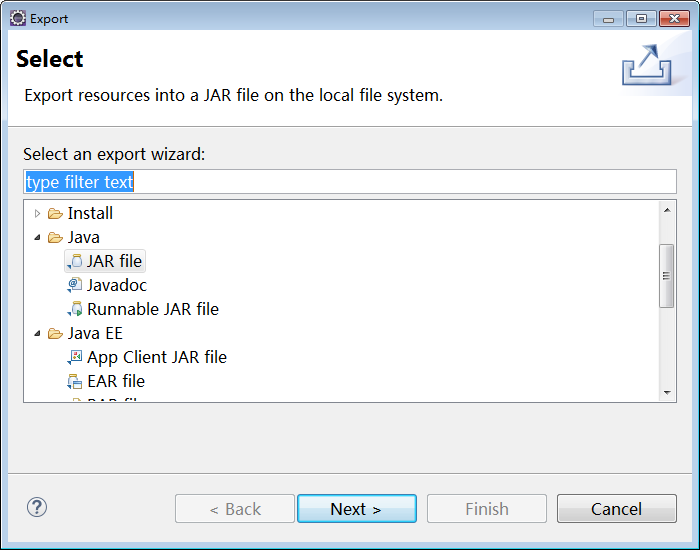
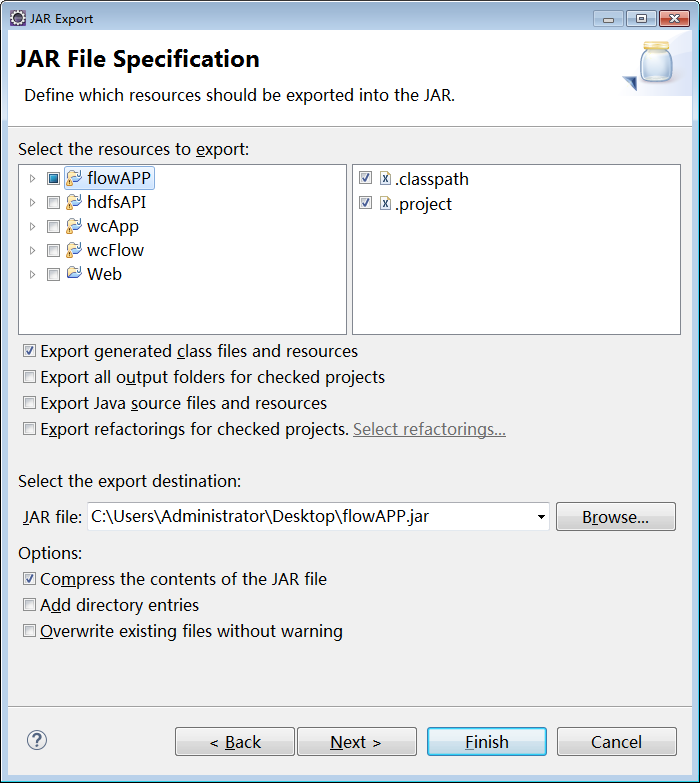
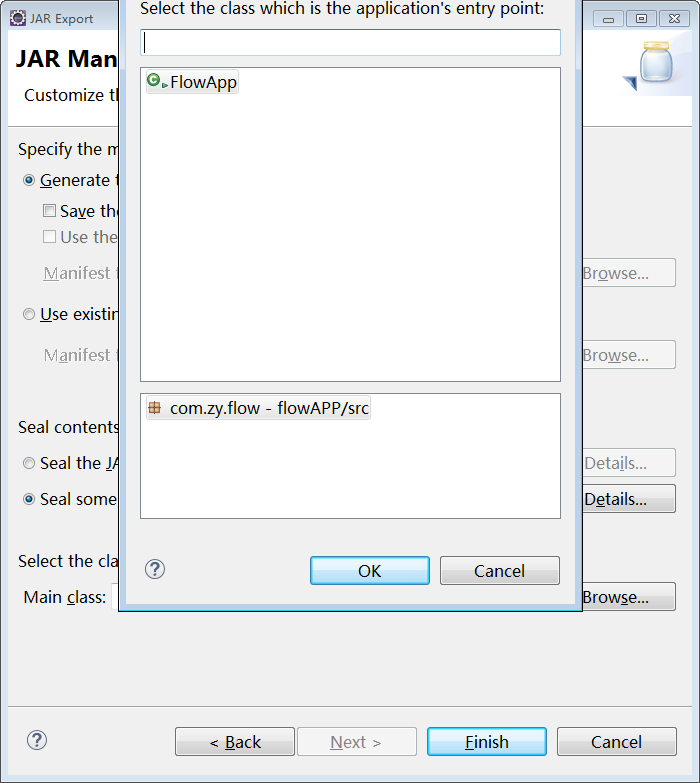
2)上传到linux
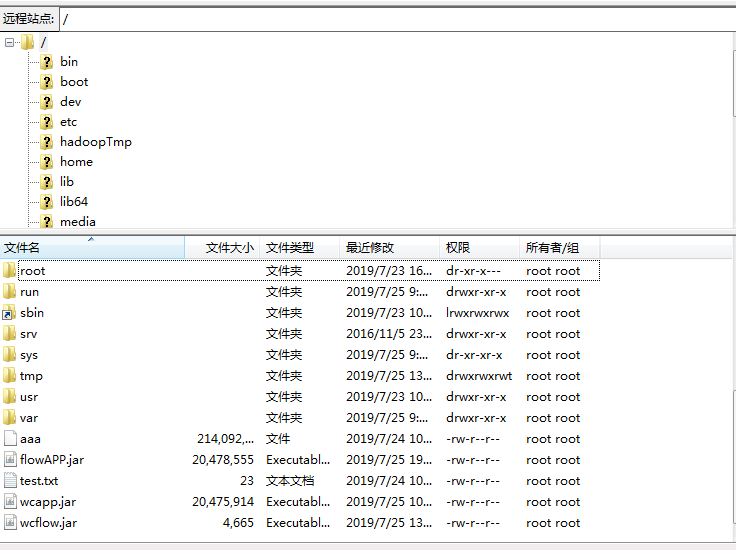
3)运行
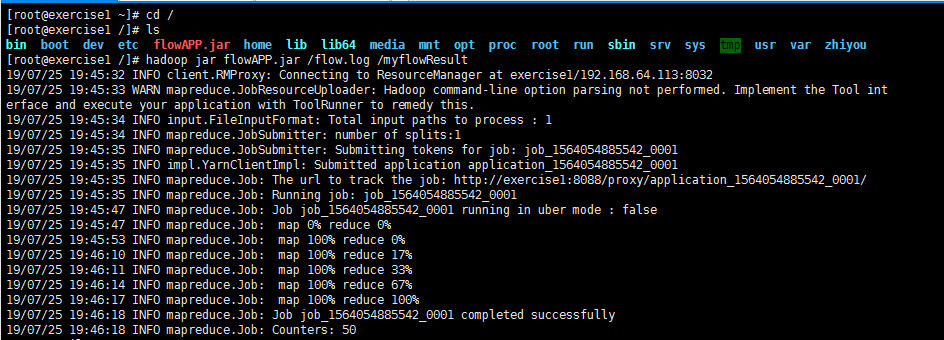

MapReduce统计每个用户的使用总流量的更多相关文章
- MongoDb 用 mapreduce 统计留存率
MongoDb 用 mapreduce 统计留存率(金庆的专栏)留存的定义采用的是新增账号第X日:某日新增的账号中,在新增日后第X日有登录行为记为留存 输出如下:(类同友盟的留存率显示)留存用户注册时 ...
- 使用 Redis 统计在线用户人数
在构建应用的时候, 我们经常需要对用户的一举一动进行记录, 而其中一个比较重要的操作, 就是对在线的用户进行记录. 本文将介绍四种使用 Redis 对在线用户进行记录的方案, 这些方案虽然都可以对在线 ...
- Hadoop基础-Map端链式编程之MapReduce统计TopN示例
Hadoop基础-Map端链式编程之MapReduce统计TopN示例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 对“temp.txt”中的数据进行分析,统计出各 ...
- Tomcat集群下获取memcached缓存对象数量,统计在线用户数据量
项目需要统计在线用户数量,系统部署在集群环境下,使用会话粘贴的方式解决Session问题.要想得到真实在线用户数,必须是所有节点的总和. 这里考虑使用memcached存放用户登录数据,key为use ...
- 用HttpSessionListener统计在线用户或做账号在线人数管理
使用HttpSessionListener接口可监听session的创建和失效 session是在用户第一次访问页面时创建 在session超时或调用request.getSession().inva ...
- 拼多多后台开发面试真题:如何用Redis统计独立用户访问量
众所周至,拼多多的待遇也是高的可怕,在挖人方面也是不遗余力,对于一些工作3年的开发,稍微优秀一点的,都给到30K的Offer,当然,拼多多加班也是出名的,一周上6天班是常态,每天工作时间基本都是超过1 ...
- 拼多多面试真题:如何用 Redis 统计独立用户访问量!
阅读本文大概需要 2.8 分钟. 作者:沙茶敏碎碎念 众所周至,拼多多的待遇也是高的可怕,在挖人方面也是不遗余力,对于一些工作 3 年的开发,稍微优秀一点的,都给到 30K 的 Offer. 当然,拼 ...
- 从GoogleClusterData统计每个用户的使用率、平均每次出价
之前将google cluster data导入了Azure上的MySQL数据库,下一步就是对这些数据进行分析, 挖掘用户的使用规律了. 首先,为了加快执行速度,对user,time等加入索引. 然后 ...
- 如何用 Redis 统计独立用户访问量
众所周至,拼多多的待遇也是高的可怕,在挖人方面也是不遗余力,对于一些工作3年的开发,稍微优秀一点的,都给到30K的Offer,当然,拼多多加班也是出名的,一周上6天班是常态,每天工作时间基本都是超过1 ...
随机推荐
- 解决 unknown filesystem type ntfs U盘/移动硬盘挂载出错问题
大内存U盘或者移动硬盘挂在再Linux 时,报错unknown filesystem type ntfs 1.安装ntfs-3g wget http://tuxera.com/opensource/n ...
- 壁球小游戏详解(附有源码.cpp)
1.在python中安装pygame 2.将下列源码复制过去,运行. #引用 import pygame, sys #初始化 pygame.init() size = width, height = ...
- Linux常用命令(df&dh)
在Linux下查看磁盘空间使用情况,最常使用的就是du和df了.然而两者还是有很大区别的,有时候其输出结果甚至非常悬殊. du的工作原理 du命令会对待统计文件逐个调用fstat这个系统调用,获取文件 ...
- 【MyBatis】MyBatis 连接池和事务控制
MyBatis 连接池和事务控制 文章源码 MyBaits 连接池 实际开发中都会使用连接池,因为它可以减少获取连接所消耗的时间.具体可查看 MyBatis 数据源配置在 SqlMapConfig.x ...
- 【Flutter】容器类组件之变换
前言 Transform可以在其子组件绘制时对其应用一些矩阵变换来实现一些特效. 接口描述 const Transform({ Key key, @required this.transform, t ...
- Invalid bound statement (not found): com.xxx.xxx.dao.ShopMapper.insertShop
mybatis在编写完SQL,进行测试的时候出现了错误,显示 org.apache.ibatis.binding.BindingException: Invalid bound statement ( ...
- Manjaro Linux 5.9.11-3安装和配置全局截图工具FlameShot教程
背景说明 截图工具是日常适用频率较高的一种系统工具,在Linux下也有不少常用截图工具,如deepin-screenshot等,但是今天我们要介绍的是FlameShot--一款更加精致的Linux全局 ...
- openpose c++ 配置教程 + python api
之前有介绍过基于tensorflow的openpose版本安装,但是我觉得没有caffe框架那么好用,很多功能也实现不了,比如调节net_resolution的调节,通过调节分辨率来提高检测的精确性和 ...
- su3和SU01中参数说明
对于SU3和SU01中的的"参数"tab栏中的参数可以自己添加和删除. 所有的参数都存在表TPARA中,并且有对应的参数的说明. 那么这些参数如何使用呢? 通常的使用是,通过类似 ...
- 低功耗降线性稳压器,24V转5V降压芯片
PW2330开发了一种高效率的同步降压DC-DC变换器3A输出电流.PW2330在4.5V到30V的宽输入电压范围内工作集成主开关和同步开关,具有非常低的RDS(ON)以最小化传导 损失.PW2330 ...