MacOS下ElasticSearch学习(第二天)
ElasticSearch第二天
学于黑马和传智播客联合做的教学项目 感谢
黑马官网
传智播客官网
微信搜索"艺术行者",关注并回复关键词"elasticsearch"获取视频和教程资料!
b站在线视频
学习目标:
- 能够使用java客户端完成创建、删除索引的操作
- 能够使用java客户端完成文档的增删改的操作
- 能够使用java客户端完成文档的查询操作
- 能够完成文档的分页操作
- 能够完成文档的高亮查询操作
- 能够搭建Spring Data ElasticSearch的环境(重点)
- 能够完成Spring Data ElasticSearch的基本增删改查操作(重点)
- 能够掌握基本条件查询的方法命名规则
第一章 ElasticSearch编程操作
1.1 创建工程,导入坐标
1.1.1 启动三个节点组成集群
1.1.2 创建一个Maven工程,起名为ElasticSearchJavaClient
1.1.3 导入pom坐标
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
1.1.4 修改编译版本,在pom文件中添加
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
1.2 创建索引index
包结构
@Test
public void test1() throws Exception {
//创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//创建名称为blog2的索引
client.admin().indices().prepareCreate("blog2").get();
//释放资源
client.close();
}
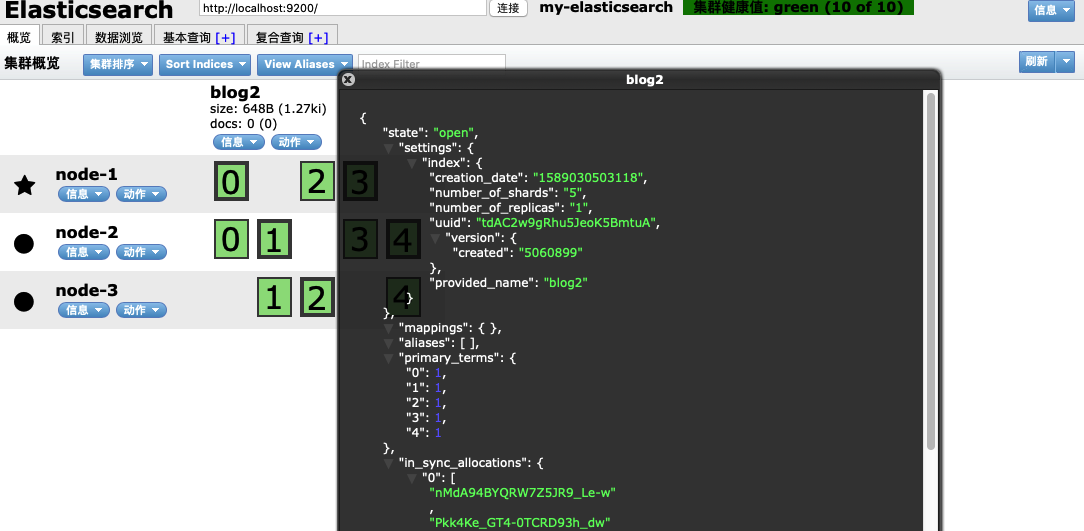
当前映射没有信息
1.3 创建映射mapping
@Test
public void test2() throws Exception {
//创建Client对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//添加映射
/*
* 格式:
* "mappings" : {
"article" : {
"properties" : {
"id" : { "type" : "integer" },
"title" : { "type" : "string" },
"content" : { "type" : "string" }
}
}
}
*/
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type", "integer")
.endObject()
.startObject("title")
.field("type", "string").field("store", "yes").field("analyzer", "ik_smart")
.endObject()
.startObject("content")
.field("type", "string").field("store", "yes").field("analyzer", "ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
//创建映射
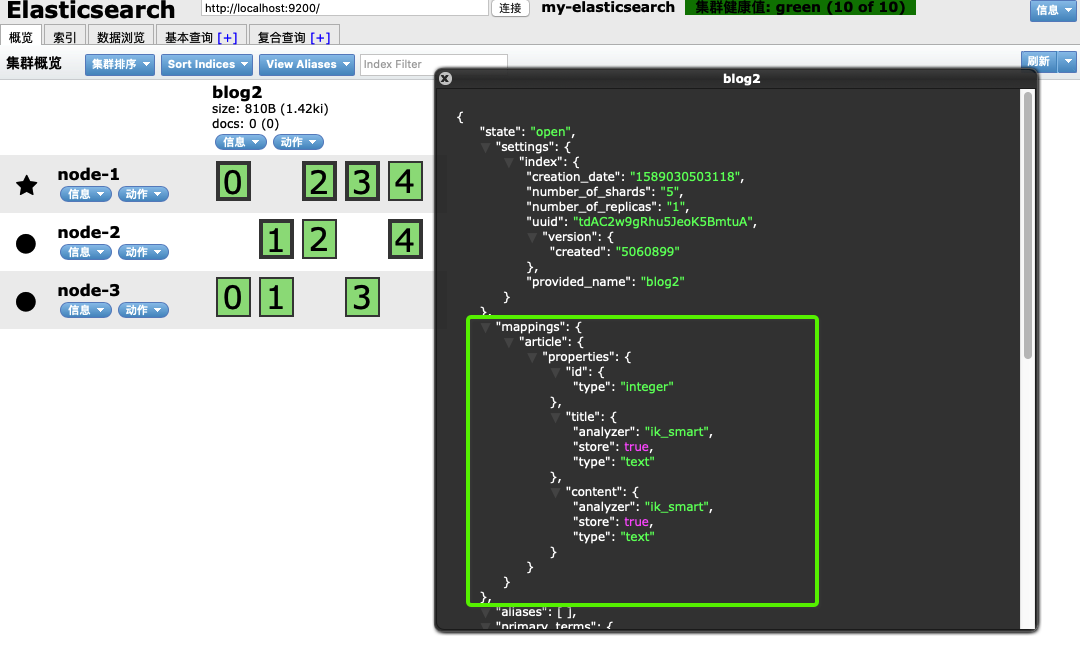
PutMappingRequest mapping = Requests.putMappingRequest("blog2")
.type("article").source(builder);
client.admin().indices().putMapping(mapping).get();
//释放资源
client.close();
}
1.4 建立文档document
1.4.1 建立文档(通过XContentBuilder)
@Test
//创建文档
public void test3() throws Exception {
//创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//创建文档信息
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("id", 1)
.field("title", "ElasticSearch是一个基于Lucene的搜索服务器")
.field("content", "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。")
.endObject();
//建立文档对象
/*
参数一:表示索引对象
参数二:类型
参数三:建立id
*/
client.prepareIndex("blog2", "article", "1").setSource(builder).get();
//释放资源
client.close();
}
1.4.2 建立文档(使用Jackson转换实体)
包结构
创建Article实体
package org.example.es.domain; /**
* @author HackerStar
* @create 2020-05-09 21:53
*/
public class Article {
private Integer id;
private String title;
private String content; public Integer getId() {
return id;
} public void setId(Integer id) {
this.id = id;
} public String getTitle() {
return title;
} public void setTitle(String title) {
this.title = title;
} public String getContent() {
return content;
} public void setContent(String content) {
this.content = content;
} @Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
'}';
}
}
添加jackson坐标到pom文件
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.8.1</version>
</dependency>
代码实现
import com.fasterxml.jackson.databind.ObjectMapper;//注意导入这个包
@Test
public void test4() throws Exception{
//创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//描述json数据(id:xxx, title:xxx, content:xxx)
Article article = new Article();
article.setId(2);
article.setTitle("搜索工作其实很快乐");
article.setContent("我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的问题。");
ObjectMapper objectMapper = new ObjectMapper();
//建立文档
client.prepareIndex("blog2", "article", article.getId().toString())
.setSource(objectMapper.writeValueAsString(article).getBytes(), XContentType.JSON).get();
//释放资源
client.close();
}
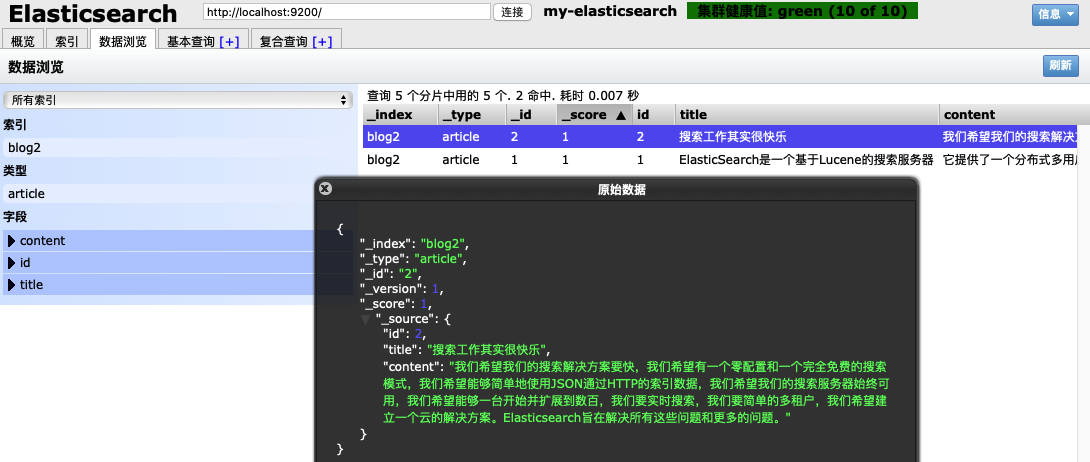
1.5 查询文档操作
1.5.1 字符串查询
@Test
public void testStringQuery() throws Exception {
//创建es客户端连接对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//设置搜索条件
SearchResponse searchResponse = client.prepareSearch("blog2")
.setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("搜索")).get();
//遍历搜索结果数据
SearchHits hits = searchResponse.getHits();//获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next();
System.out.println(searchHit.getSourceAsString());
System.out.println("title: " + searchHit.getSource().get("title"));
}
//释放资源
client.close();
}
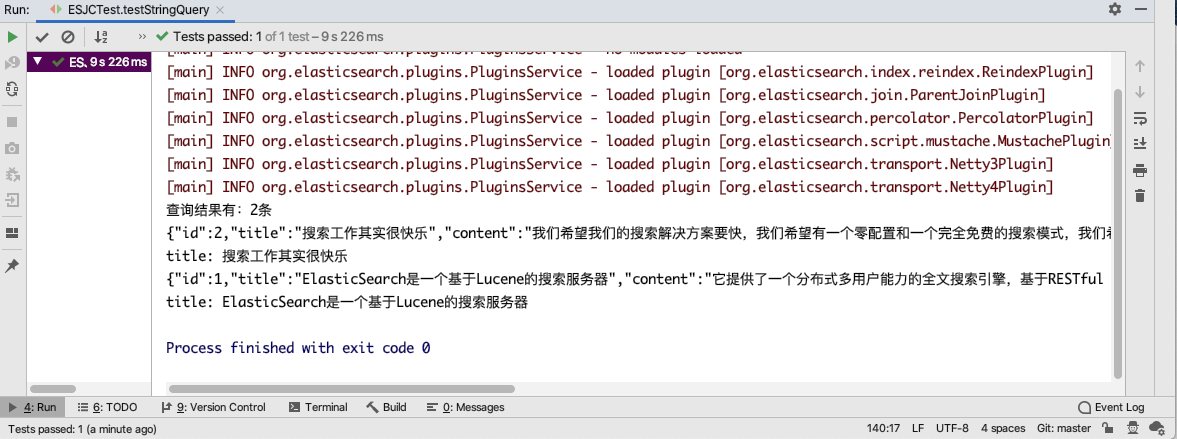
1.5.2 关键词查询
@Test
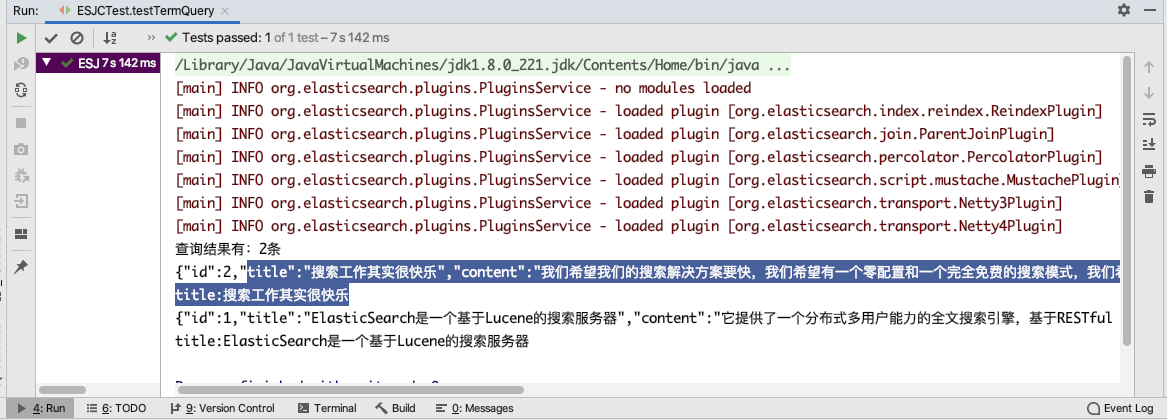
public void testTermQuery() throws Exception {
//创建es客户端连接对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//设置搜索条件
SearchResponse searchResponse = client.prepareSearch("blog2")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("content", "搜索")).get();
//遍历搜索结果数据
SearchHits hits = searchResponse.getHits();
System.out.println("查询结果有:" + hits.getTotalHits() + "条");//获取命中次数,查询结果有多少对象
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString());
System.out.println("title:" + searchHit.getSource().get("title"));
}
//释放资源
client.close();
}
1.5.3 使用文档ID查询文件
@Test
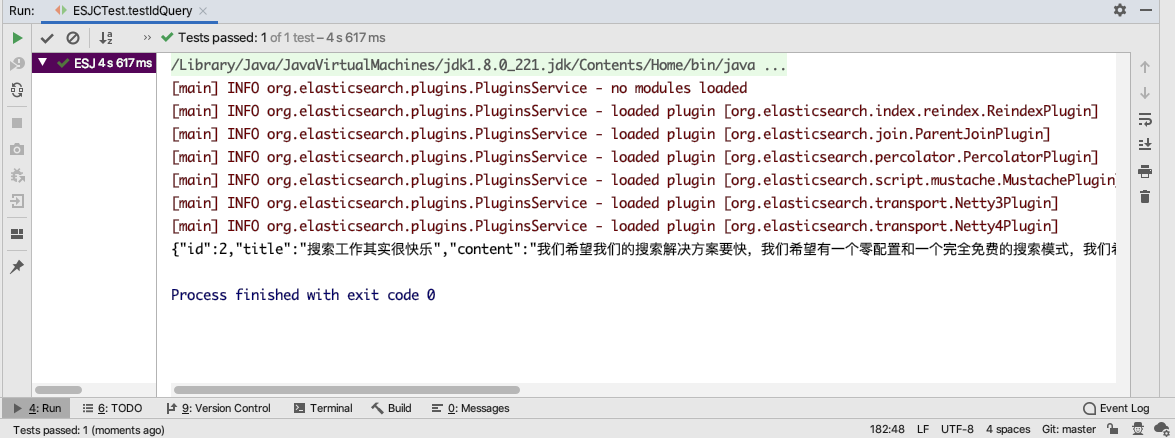
public void testIdQuery() throws Exception {
//创建es客户端连接对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
SearchResponse response = client.prepareSearch("blog2")
.setTypes("article")
//设置要查询的id
.setQuery(QueryBuilders.idsQuery().addIds("2"))
//执行查询
.get();
//取查询结果
SearchHits searchHits = response.getHits();
Iterator<SearchHit> iterator = searchHits.iterator();
while(iterator.hasNext()) {
SearchHit searchHit = iterator.next();
//打印整行数据
System.out.println(searchHit.getSourceAsString());
}
}
1.6 查询文档分页操作
1.6.1 批量插入数据
@Test
//批量插入100条数据
public void test5() throws Exception {
//创建client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
ObjectMapper objectMapper = new ObjectMapper();
for (int i = 1; i <= 100; i++) {
//描述json
Article article = new Article();
article.setId(i);
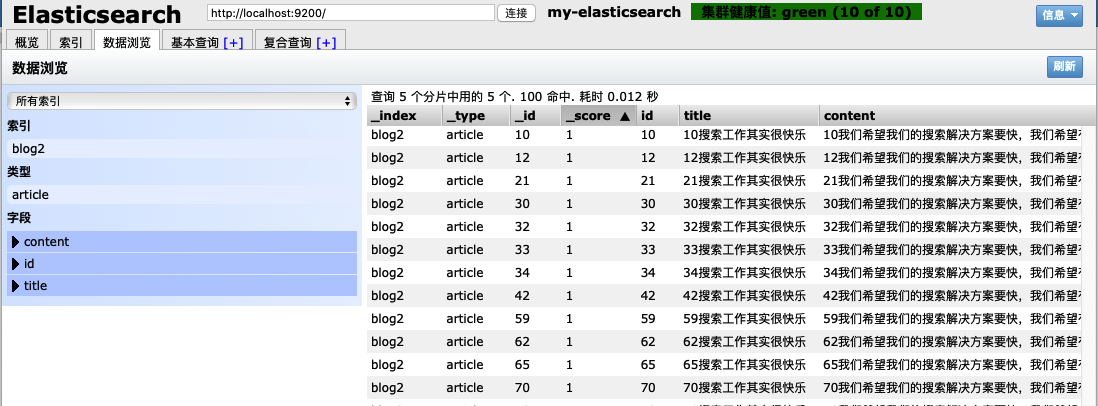
article.setTitle(i + "搜索工作其实很快乐");
article.setContent(i
+ "我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式," +
"我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用," +
"我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户," +
"我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的问题。");
//建立文档
client.prepareIndex("blog2", "article", article.getId().toString())
.setSource(objectMapper.writeValueAsString(article).getBytes(), XContentType.JSON).get();
}
//释放资源
client.close();
}
1.6.2 分页查询
@Test
public void test6() throws Exception {
//创建client对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300));
//搜索数据
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("blog2")
.setTypes("article")
.setQuery(QueryBuilders.matchAllQuery());//默认每页显示10条数据
//查询第2页数据,每页20条
//setFrom():从每页开始检索,默认是0
//setSize():每页最多的记录数
searchRequestBuilder.setFrom(0).setSize(5);
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
System.out.println("id:" + searchHit.getSource().get("id"));
System.out.println("title:" + searchHit.getSource().get("title"));
System.out.println("content:" + searchHit.getSource().get("content"));
System.out.println("-----------------------------------------");
}
//释放资源
client.close();
}

1.7 查询结果高亮操作
1.7.1 什么是高亮显示
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。
1.7.2 高亮显示的html分析
通过开发者工具查看高亮数据的html代码实现:
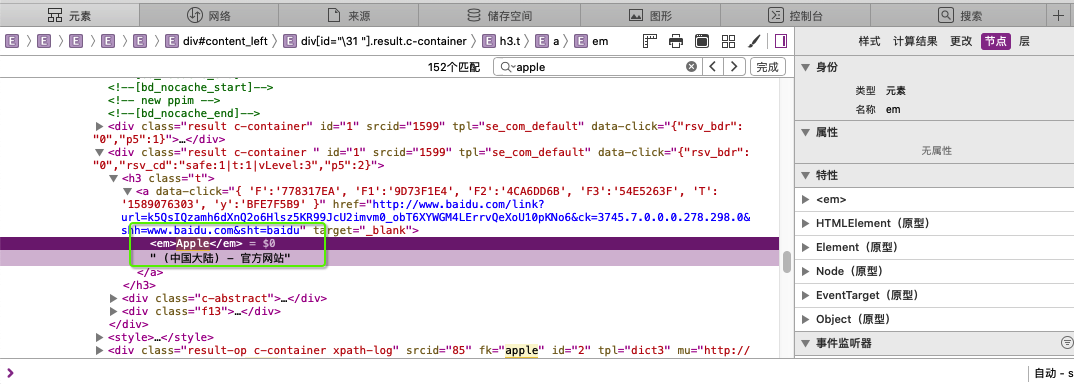
ElasticSearch可以对查询出的内容中关键字部分进行标签和样式的设置,但是你需要告诉ElasticSearch使用什么标签对高亮关键字进行包裹
1.7.3 高亮显示代码实现
@Test
//高亮查询
public void test7() throws Exception {
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 搜索数据
SearchRequestBuilder searchRequestBuilder = client
.prepareSearch("blog2").setTypes("article")
.setQuery(QueryBuilders.termQuery("title", "搜"));
//设置高亮数据
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font style='color:red>'");
highlightBuilder.postTags("</font>");
highlightBuilder.field("title");
searchRequestBuilder.highlighter(highlightBuilder);
//获取查询结果数据
SearchResponse searchResponse = searchRequestBuilder.get();
//获取查询结果集
SearchHits searchHits = searchResponse.getHits();
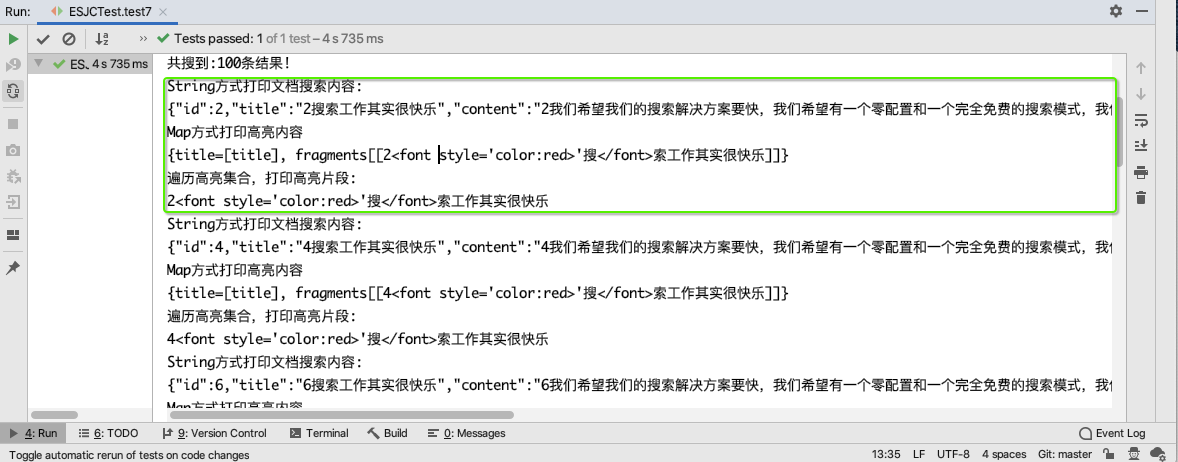
System.out.println("共搜到:"+searchHits.getTotalHits()+"条结果!");
//遍历结果
for(SearchHit hit:searchHits){
System.out.println("String方式打印文档搜索内容:");
System.out.println(hit.getSourceAsString());
System.out.println("Map方式打印高亮内容");
System.out.println(hit.getHighlightFields());
System.out.println("遍历高亮集合,打印高亮片段:");
Text[] text = hit.getHighlightFields().get("title").getFragments();
for (Text str : text) {
System.out.println(str);
}
}
//释放资源
client.close();
}
第二章 Spring Data ElasticSearch 使用
2.1 Spring Data ElasticSearch简介
2.1.1 什么是Spring Data
Spring Data是一个用于简化数据库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务。 Spring Data可以极大的简化JPA的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。
2.1.2 什么是Spring Data ElasticSearch
Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装 。Spring Data为Elasticsearch项目提供集成搜索引擎。Spring Data Elasticsearch POJO的关键功能区域为中心的模型与Elastichsearch交互文档和轻松地编写一个存储库数据访问层。
2.2 Spring Data ElasticSearch入门
1)导入Spring Data ElasticSearch坐标
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>3.0.5.RELEASE</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>transport-netty4-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.0.4.RELEASE</version>
</dependency>
</dependencies>
2)创建applicationContext.xml配置文件,引入elasticsearch命名空间
包结构
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd
">
</beans>
3)编写实体Article
package org.example.domain;
/**
* @author HackerStar
* @create 2020-05-10 15:18
*/
public class Article {
private Integer id;
private String title;
private String content;
@Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
4)编写Dao
package org.example.dao;
import org.example.domain.Article;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
/**
* @author HackerStar
* @create 2020-05-10 15:23
*/
public interface ArticleRepository extends ElasticsearchRepository<Article, Integer> {
}
5)编写Service
package org.example.service;
import org.example.domain.Article;
/**
* @author HackerStar
* @create 2020-05-10 15:20
*/
public interface ArticleService {
public void save(Article article);
}
package org.example.service.impl;
import org.example.dao.ArticleRepository;
import org.example.domain.Article;
import org.example.service.ArticleService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* @author HackerStar
* @create 2020-05-10 15:20
*/
@Service
public class ArticleServiceImpl implements ArticleService {
@Autowired
private ArticleRepository articleRepository;
public void save(Article article) {
articleRepository.save(article);
}
}
6) 配置applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd
">
<!-- 扫描Dao包,自动创建实例 -->
<elasticsearch:repositories base-package="org.example.dao"/>
<!-- 扫描Service包,创建Service的实体 -->
<context:component-scan base-package="org.example.service"/>
<!-- 配置elasticSearch的连接 -->
<elasticsearch:transport-client id="client" cluster-nodes="localhost:9300" cluster-name="my-elasticsearch"/>
<!-- ElasticSearch模版对象 -->
<bean id="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client"></constructor-arg>
</bean>
</beans>
7)配置实体
package org.example.domain;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
/**
* @author HackerStar
* @create 2020-05-10 15:18
*/
//@Document 文档对象(索引信息,文档类型)
@Document(indexName = "blog1", type = "article")
public class Article {
//@Id 文档主键 唯一标识
@Id
//@Field 每个文档的字段配置(类型、是否分词、是否存储、分词器 )
@Field(store = true, index = false, type = FieldType.Integer)
private Integer id;
@Field(store = true, analyzer = "ik_smart", index = true, searchAnalyzer="ik_smart",type = FieldType.text)
private String title;
@Field(store = true, analyzer = "ik_smart", index = true, searchAnalyzer="ik_smart",type = FieldType.text)
private String content;
@Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
其中,注解解释如下:
@Document(indexName="blob3",type="article"):
indexName:索引的名称(必填项)
type:索引的类型
@Id:主键的唯一标识
@Field(index=true,analyzer="ik_smart",store=true,searchAnalyzer="ik_smart",type = FieldType.text)
index:是否设置分词
analyzer:存储时使用的分词器
searchAnalyze:搜索时使用的分词器
store:是否存储
type: 数据类型
8)创建测试类SpringDataESTest
package org.example.test;
import org.elasticsearch.client.transport.TransportClient;
import org.example.domain.Article;
import org.example.service.ArticleService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
/**
* @author HackerStar
* @create 2020-05-10 15:35
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class SpringDateESTest {
@Autowired
private ArticleService articleService;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
//创建索引和映射
@Test
public void createIndex() {
elasticsearchTemplate.createIndex(Article.class);
elasticsearchTemplate.putMapping(Article.class);
}
//保存文档
@Test
public void saveArticle() {
Article article = new Article();
article.setId(100);
article.setTitle("测试SpringData ElasticSearch");
article.setContent("Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装 \n" +
"Spring Data为Elasticsearch Elasticsearch项目提供集成搜索引擎");
articleService.save(article);
}
}
2.3 Spring Data ElasticSearch的常用操作
2.3.1 增删改查方法测试
向ArticleService中添加代码
package org.example.service;
import org.example.domain.Article;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
/**
* @author HackerStar
* @create 2020-05-10 15:20
*/
public interface ArticleService {
//保存
public void save(Article article);
//删除
public void delete(Article article);
//查询全部
public Iterable<Article> findAll();
//分页查询
public Page<Article> findAll(Pageable pageable);
}
package org.example.service.impl;
import org.example.dao.ArticleRepository;
import org.example.domain.Article;
import org.example.service.ArticleService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;
/**
* @author HackerStar
* @create 2020-05-10 15:20
*/
@Service
public class ArticleServiceImpl implements ArticleService {
@Autowired
private ArticleRepository articleRepository;
public void save(Article article) {
articleRepository.save(article);
}
@Override
public void delete(Article article) {
articleRepository.delete(article);
}
@Override
public Iterable<Article> findAll() {
return articleRepository.findAll();
}
@Override
public Page<Article> findAll(Pageable pageable) {
return articleRepository.findAll(pageable);
}
}
测试代码
package org.example.test;
import org.elasticsearch.client.transport.TransportClient;
import org.example.domain.Article;
import org.example.service.ArticleService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
/**
* @author HackerStar
* @create 2020-05-10 15:35
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class SpringDateESTest {
@Autowired
private ArticleService articleService;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
//创建索引和映射
@Test
public void createIndex() {
elasticsearchTemplate.createIndex(Article.class);
elasticsearchTemplate.putMapping(Article.class);
}
//保存文档
@Test
public void saveArticle() {
Article article = new Article();
article.setId(100);
article.setTitle("测试SpringData ElasticSearch");
article.setContent("Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装 \n" +
"Spring Data为Elasticsearch Elasticsearch项目提供集成搜索引擎");
articleService.save(article);
}
//保存
@Test
public void save() {
Article article = new Article();
article.setId(1001);
article.setTitle("elasticSearch 3.0版本发布");
article.setContent("ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口");
articleService.save(article);
}
//更新
@Test
public void update() {
Article article = new Article();
article.setId(1001);
article.setTitle("elasticSearch 3.0版本发布...更新");
article.setContent("ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口");
articleService.save(article);
}
//删除
@Test
public void delete() {
Article article = new Article();
article.setId(1001);
articleService.delete(article);
}
//批量插入
@Test
public void save100() {
for (int i = 1; i <= 100; i++) {
Article article = new Article();
article.setId(i);
article.setTitle(i + "elasticSearch 3.0版本发布..,更新");
article.setContent(i + "ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口");
articleService.save(article);
}
}
//分页查询
@Test
public void findAllPage() {
Pageable pageable = PageRequest.of(1, 10);
Page<Article> page = articleService.findAll(pageable);
for (Article article : page.getContent()) {
System.out.println(article);
}
}
}
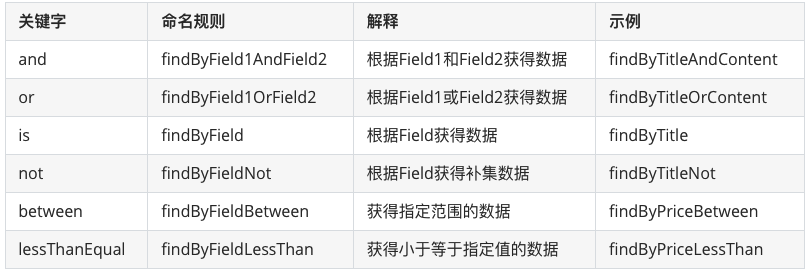
2.3.2 常用查询命名规则
2.3.3 查询方法测试
1)dao层实现
package org.example.dao;
import org.example.domain.Article;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
/**
* @author HackerStar
* @create 2020-05-10 15:23
*/
public interface ArticleRepository extends ElasticsearchRepository<Article, Integer> {
//根据标题查询
List<Article> findByTitle(String condition);
//根据标题查询(含分页)
Page<Article> findByTitle(String condition, Pageable pageable);
}
2)service层实现
package org.example.service;
import org.example.domain.Article;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import java.util.List;
/**
* @author HackerStar
* @create 2020-05-10 15:20
*/
public interface ArticleService {
//保存
public void save(Article article);
//删除
public void delete(Article article);
//查询全部
public Iterable<Article> findAll();
//分页查询
public Page<Article> findAll(Pageable pageable);
//根据标题查询
List<Article> findByTitle(String condition);
//根据标题查询(含分页)
Page<Article> findByTitle(String condition, Pageable pageable);
}
package org.example.service.impl;
import org.example.dao.ArticleRepository;
import org.example.domain.Article;
import org.example.service.ArticleService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* @author HackerStar
* @create 2020-05-10 15:20
*/
@Service
public class ArticleServiceImpl implements ArticleService {
@Autowired
private ArticleRepository articleRepository;
@Override
public List<Article> findByTitle(String condition) {
return articleRepository.findByTitle(condition);
}
@Override
public Page<Article> findByTitle(String condition, Pageable pageable) {
return articleRepository.findByTitle(condition, pageable);
}
}
3)测试代码
package org.example.test;
import org.elasticsearch.client.transport.TransportClient;
import org.example.domain.Article;
import org.example.service.ArticleService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
/**
* @author HackerStar
* @create 2020-05-10 15:35
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class SpringDateESTest {
@Autowired
private ArticleService articleService;
//条件查询
@Test
public void findByTitle(){
String condition = "版本";
List<Article> articleList = articleService.findByTitle(condition);
for(Article article:articleList){
System.out.println(article);
}
}
//条件分页查询
@Test
public void findByTitlePage(){
String condition = "版本";
Pageable pageable = PageRequest.of(2,10);
Page<Article> page = articleService.findByTitle(condition,pageable);
for(Article article:page.getContent()){
System.out.println(article);
}
}
}
2.3.4使用Elasticsearch的原生查询对象进行查询。
package org.example.test;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.example.domain.Article;
import org.example.service.ArticleService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
/**
* @author HackerStar
* @create 2020-05-10 15:35
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class SpringDateESTest {
@Test
public void findByNativeQuery() {
//创建一个SearchQuery对象
SearchQuery searchQuery = new NativeSearchQueryBuilder()
//设置查询条件,此处可以使用QueryBuilders创建多种查询
.withQuery(QueryBuilders.queryStringQuery("版本").defaultField("title"))
//还可以设置分页信息
.withPageable(PageRequest.of(1, 5))
//创建SearchQuery对象
.build();
//使用模板对象执行查询
elasticsearchTemplate.queryForList(searchQuery, Article.class)
.forEach(a -> System.out.println(a));
}
}
MacOS下ElasticSearch学习(第二天)的更多相关文章
- MacOS下ElasticSearch学习(第一天)
ElasticSearch第一天 学于黑马和传智播客联合做的教学项目 感谢 黑马官网 传智播客官网 微信搜索"艺术行者",关注并回复关键词"elasticsearch&q ...
- Java并发包下锁学习第二篇Java并发基础框架-队列同步器介绍
Java并发包下锁学习第二篇队列同步器 还记得在第一篇文章中,讲到的locks包下的类结果图吗?如下图: 从图中,我们可以看到AbstractQueuedSynchronizer这个类很重要(在本 ...
- MacOS下Lucene学习
学于黑马和传智播客联合做的教学项目 感谢 黑马官网 传智播客官网 微信搜索"艺术行者",关注并回复关键词"lucene"获取视频和教程资料! b站在线视频 全文 ...
- Elasticsearch学习总结 (Centos7下Elasticsearch集群部署记录)
一. ElasticSearch简单介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- python学习第二讲,pythonIDE介绍以及配置使用
目录 python学习第二讲,pythonIDE介绍以及配置使用 一丶集成开发环境IDE简介,以及配置 1.简介 2.PyCharm 介绍 3.pycharm 的安装 二丶IDE 开发Python,以 ...
- Elasticsearch7.X 入门学习第二课笔记----基本api操作和CRUD
原文:Elasticsearch7.X 入门学习第二课笔记----基本api操作和CRUD 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链 ...
- 前端学习 第二弹: JavaScript中的一些函数与对象(1)
前端学习 第二弹: JavaScript中的一些函数与对象(1) 1.apply与call函数 每个函数都包含两个非继承而来的方法:apply()和call(). 他们的用途相同,都是在特定的作用域中 ...
- 二、Android学习第二天——初识Activity(转)
(转自:http://wenku.baidu.com/view/af39b3164431b90d6c85c72f.html) 一. Android学习第二天——初识Activity 昨天程序搭建成功以 ...
- Elasticsearch学习随笔(一)--原理理解与5.0核心插件部署过程
最近由于要涉及一些安全运维的工作,最近在研究Elasticsearch,为ELK做相关的准备.于是把自己学习的一些随笔分享给大家,进行学习,在部署常用插件的时候由于是5.0版本的Elasticsear ...
随机推荐
- TypeScript学习——数组、元组、接口(2)
数组 数组类型注解 const numberArr: (number | string)[] = [1, '2', 3]; //既可以是number 也可以是string const stringAr ...
- 洛谷 P3243 【[HNOI2015]菜肴制作】
先吐槽一下这个难度吧,评的有点高了,但是希望别降,毕竟这是我能做出来的不多的紫题了(狗头). 大家上来的第一反应应该都是啊,模板题,然后兴高采烈的打了拓补排序的板子,然后搞个小根堆,按照字典序输出就可 ...
- [SCOI2016]背单词 题解
背单词 https://www.luogu.com.cn/problem/P3294 前言: Trie树的省选题(瑟瑟发抖QAQ) 问题汇总:(请忽略) (1)对Trie字典树的运用不熟练 (2)没想 ...
- js写一个简单的日历
思路:先写一个结构和样式,然后写本月的时间,之后计算上下月份的关系 <!DOCTYPE html> <html lang="en"> <head> ...
- 什么是jsp?
1.什么是jsp? jsp就是java 服务器页面(java server page) 2.jsp有什么用? jsp的出现是为了解决Servlet页面显示方面的不足. 3.jsp的三种脚本: 4.js ...
- 12 . Kubernetes之Statefulset 和 Operator
Statefulset简介 k8s权威指南这样介绍的 "在Kubernetes系统中,Pod的管理对象RC.Deployment.DaemonSet和Job都面向无状态的服务.但现实中有很多 ...
- REST,RPC和GraphQL应用场景,WebHooks、WebSocket、HTTP Streaming应用场景。
一.请求--响应API. 请求--响应类的API的典型做法是,通过基于HTTP的Web服务器暴露一个/套接口.API定义一些端点,客户端发送数据的请求到这些端点,Web服务器处理这些请求,然后返回响应 ...
- C/C++编程语言制作《游戏内存外挂》
通过C/C++编程语言编写一个简单的外挂,通过 API 函数修改游戏数据,从而实现作弊功能 对象分析要用的 API 函数简单介绍编写测试效果. 下面是我整理好的全套C/C++资料,加入天狼QQ7269 ...
- springbean 生命周期
springbean 和java对象得区别: 1.对象:任何符合java语法规则实例化出来的对象 2.springbean: 是spring对普通对象进行了封装为BeanDefinition,bean ...
- 安装python包管理工具pip
安装步骤(必须已经安装过python) 1>curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py 2>python get-pip ...