Redis高频面试题总结
通过面试多家大型互联网企业,总结了如下的高频面试题目:
1、redis 过期键的删除策略?
(1)定时删除:在设置键的过期时间的同时,创建一个定时器 timer). 让定时器在键的过期时间来临时,立即执行对键的删除操作。

通过淘汰策略也能保证Redis中缓存的都是热点数据。
3、Redis分布式锁的实现
Redis的分布式缓存特性使其成为了分布式锁的一种基础实现。通过Redis中是否存在某个锁ID,则可以判断是否上锁。为了保证判断锁是否存在的原子性,保证只有一个线程获取同一把锁,Redis有SETNX(即SET if Note Exists)和GETSET(先写新值,返回旧值,原子性操作,可以用于分辨是不是首次操作)操作。
(1)关于setnx:
将key的值设为value,当且仅当key不存在,返回值为1。
若给定的key已经存在,则setnx不做任何动作,返回值为0。
(2)关于set:一般操作
- ex seconds - seconds:设置失效时长,单位秒
- px - milliseconds:设置失效时长,单位毫秒
- nx - key不存在时设置value,成功返回OK,失败返回(nil)
- xx - key存在时设置value,成功返回OK,失败返回(nil)
为了防止主机宕机或网络断开之后的死锁,Redis没有ZK那种天然的实现方式,只能依赖设置超时时间来规避。所以如果使用setnx来实现分布式锁,则实现步骤如下:
- 先拿
setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。 - 如果在
setnx之后,执行expire之前进程意外crash或重启维护, 那么就需要把setnx和expire合成一条指令来用。
Redis的setnx命令是当key不存在时设置key,但setnx不能同时完成expire设置失效时长,不能保证setnx和expire的原子性。我们可以使用set命令完成setnx和expire的操作,并且这种操作是原子操作。举个例子如下:
案例:设置name=p7+,失效时长100s,不存在时设置
1.1.1.1:6379> set name p7+ ex 100 nx
OK
1.1.1.1:6379> get name
"p7+"
1.1.1.1:6379> ttl name
(integer) 94
从上面可以看出,多个命令放在同一个redis连接中并且redis是单线程的,因此上面的操作可以看成setnx和expire的结合体,是原子性的。
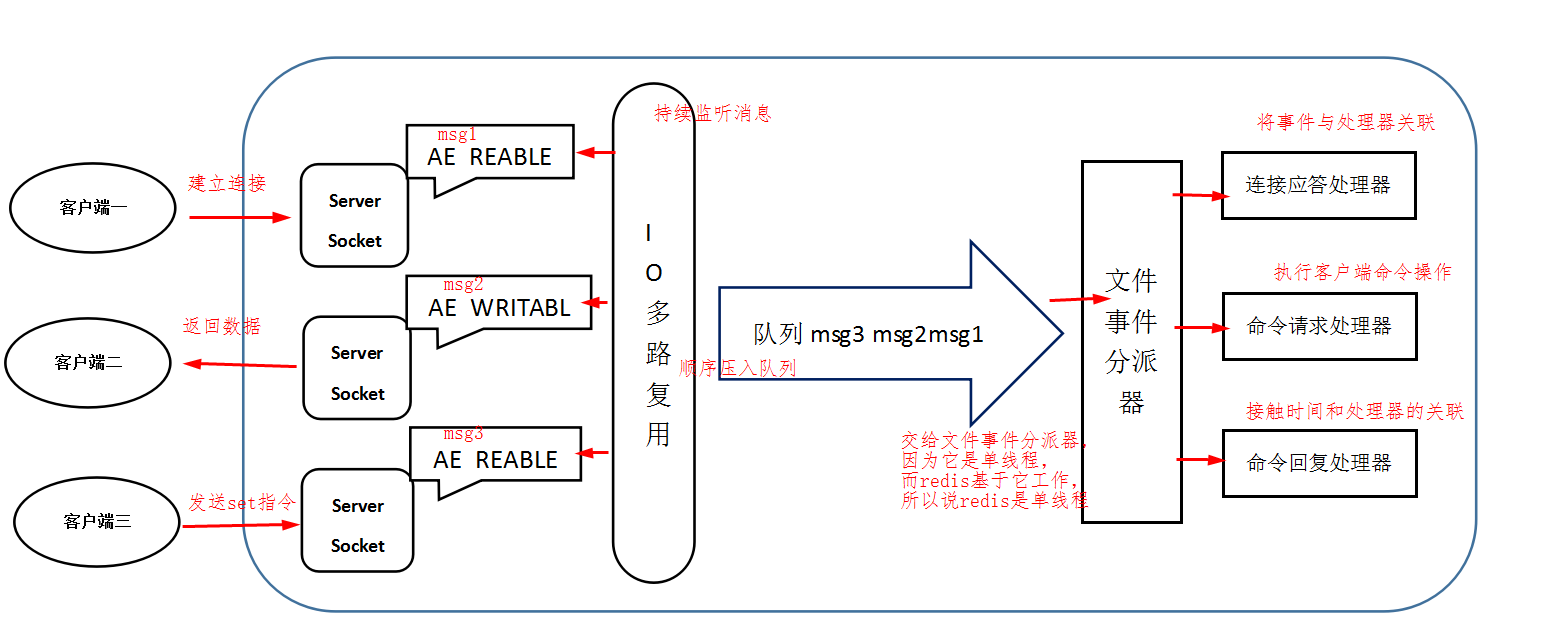
4、Redis的Reactor模式
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。
因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。
5、redis支持事务回滚吗?
“不支持回滚动作,redis是支持简单事务模式,只能discard,不能rollback”
Redis在执行事务命令的时候,在命令入队的时候, Redis 就会检测事务的命令是否正确,如果不正确则会产生错误。无论之前和之后的命令都会被事务所回滚,就变为什么都没有执行。
当命令格式正确,而因为操作数据结构引起的错误 ,则该命令执行出现错误,而其之前和之后的命令都会被正常执行。这点和数据库很不一样,这是需注意的地方。
对于一些重要的操作,我们必须通过程序去检测数据的正确性,以保证 Redis 事务的正确执行,避免出现数据不一致的情况。 Redis 之所以保持这样简易的事务,完全是为了保证移动互联网的核心问题一性能。
6、Redis的事务机制及CAS
watch指令在redis事物中提供了CAS的行为。为了检测被watch的keys在是否有多个clients同时改变引起冲突,这些keys将会被监控。如果至少有一个被监控的key在执行exec命令前被修改,整个事物将会回滚,不执行任何动作,从而保证原子性操作,并且执行exec会得到null的回复。
7、Redis和Memcached的区别
Redis的特性:
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持字符串、链表、哈希、集合和有序集合
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
与Memcached的区别在于:
(1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。Redis有部分存在硬盘上,这样能保证数据的持久性。
(2)、数据支持类型 Memcache对数据类型支持相对简单。Redis有复杂的数据类型。
(3)、使用底层模型不同 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。
Redis直接自己构建了VM(Virtual Memory)机制 ,因为一般的系统调用系统函数的话(例如java调用自己的API),会浪费一定的时间去移动和请求。
8、缓存穿透、缓存击穿和缓存雪崩
(1)缓存穿透
查询不存在的数据,缓存中没有数据,数据库也没有数据。因此所有的请求都访问到了数据库,给数据库造成了压力。解决方法如下:
- 采用布隆过滤器,将所有可能存在的数据,哈希到一个很大的 bitmap 中,一个一定不存在的数据会被 bitmap 拦截调,从而避免了对数据库的查询压力。
- 如果查询的数据为空,那么直接将空数据也缓存起来并设置较短的过期时间。这样下次访问的时候,就直接返回空值。
(2)缓存击穿
缓存击穿是指缓存过期之后,瞬时间并发客户端特别多查询同一条数据的情况下,导致数据库压力过大。业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,
而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,
再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。类似下面的代码:
public String get(String key) {
String value = redis.get(key);
if (value == null) { // 代表缓存值过期
// 设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { // 代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
}
// 这个时候代表同时候的其他线程已经load db并回设到缓存了,
// 这时候重试获取缓存值即可
else {
sleep(50);
get(key); // 重试
}
} else {
return value;
}
}
(3)缓存雪崩
雪崩就是指缓存中大批量热点数据过期后系统涌入大量查询请求,因为大部分数据在Redis层已经失效,请求渗透到数据库层,大批量请求犹如洪水一般涌入,引起数据库压力造成查询堵塞甚至宕机。
解决办法:
- 将缓存失效时间分散开,比如每个key的过期时间是随机,防止同一时间大量数据过期现象发生,这样不会出现同一时间全部请求都落在数据库层,如果缓存数据库是分布式部署,将热点数据均匀分布在不同Redis和数据库中,有效分担压力,别一个人扛。
- 让Redis数据永不过期(如果业务准许)。
9、Redis数据倾斜
1:存在bigkey:业务层避免创建bigkey,把集合类型的bigkey拆分成多个小集合,分散保存bigkey 保存了大量集合元素(集合类型),会导致这个实例的数据量增加,内存资源消耗也相应增加。bigkey 的操作一般都会造成实例 IO 线程阻塞,如果 bigkey 的访问量比较大,就会影响到这个实例上的其它请求被处理的速度。
2:slot手工分配不均匀:避免把较多的slot分配到一个实例上,进行槽的迁移
3、存在热点数据:采用带有不同key前缀的多副本方法。我们把热点数据复制多份,在每一个数据副本的 key 中增加一个随机前缀,让它和其它副本数据不会被映射到同一个 Slot 中。这样一来,热点数据既有多个副本可以同时服务请求,同时,这些副本数据的 key 又不一样,会被映射到不同的 Slot 中。在给这些 Slot 分配实例时,我们也要注意把它们分配到不同的实例上,那么,热点数据的访问压力就被分散到不同的实例上了。热点数据多副本方法只能针对只读的热点数据。如果热点数据是有读有写的话,就不适合采用多副本方法了,因为要保证多副本间的数据一致性,会带来额外的开销。
10、为什么Redis单线程模型也能效率这么高?
- 纯内存操作;
- 核心是基于非阻塞的IO多路复用机制;
- 底层使用C语言实现,一般来说,C 语言实现的程序"距离"操作系统更近,执行速度相对会更快;
- 单线程同时也避免了多线程的上下文频繁切换问题,预防了多线程可能产生的竞争问题。
11、Redis做异步和延时队列?
(2)Redis哨兵 在主从复制实现之后,如果想对master进行监控,Redis提供了一种哨兵机制,哨兵的含义就是监控Redis系统的运行状态,并做相应的响应。Redis Sentinal 着眼于高可用,在 master 宕机时会自动将 slave 提升为master,继续提供服务。
(3)Redis Cluster 着眼于扩展性,在单个 redis 内存不足时,使用 Cluster 进行分片存储。在redis-cluster架构中,redis-master节点一般用于接收读写,而redis-slave节点则一般只用于备份,其与对应的master拥有相同的slot集合,若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master。
13、Redis 的同步机制
Redis高频面试题总结的更多相关文章
- 熟悉这几道 Redis 高频面试题,面试不用愁
1.说说 Redis 都有哪些应用场景? 缓存:这应该是 Redis 最主要的功能了,也是大型网站必备机制,合理地使用缓存不仅可以加 快数据的访问速度,而且能够有效地降低后端数据源的压力. 共享Ses ...
- 从阿里、腾讯的面试真题中总结了这11个Redis高频面试题
前言 现在大家的工作生活基本已经是回归正轨了,最近也是迎来了跳槽面试季,有些人已经拿到了一两个offer了. 这段时间收集了阿里.腾讯.百度.京东.美团.字节跳动等公司的Java面试题,总结了Redi ...
- 100道Java高频面试题(阿里面试官整理)
我分享文章的时候,有个读者回复说他去年就关注了我的微信公众号,打算看完我的所有文章,然后去面试,结果我后来很长时间不更新了...所以为了弥补一直等我的娃儿们,给大家的金三银四准备了100道花时间准备的 ...
- 备战“金九银十”10道String高频面试题解析
前言 String 是我们实际开发中使用频率非常高的类,Java 可以通过 String 类来创建和操作字符串,使用频率越高的类,我们就越容易忽视它,因为见的多所以熟悉,因为熟悉所以认为它很简单,其实 ...
- Spring经典高频面试题,原来是长这个样子
Spring经典高频面试题,原来是长这个样子 2019年08月23日 15:01:32 博文视点 阅读数 719 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文 ...
- 02:Redis常见面试题
1.1 redis基础面试题 1.什么是Redis?简述它的优缺点? 1. Redis本质上是一个Key-Value类型的内存数据库,很像memcached. 2. 整个数据库统统加载在内存当中进行操 ...
- 一分钟搞定Java高频面试题
一分钟搞定Java高频面试题 一.变量赋值和计算 题目: public static void main(String[] args) { int i = 1; i = i++; int j = i+ ...
- 松哥整理了 15 道 Spring Boot 高频面试题,看完当面霸
什么是面霸?就是在面试中,神挡杀神佛挡杀佛,见招拆招,面到面试官自惭形秽自叹不如!松哥希望本文能成为你面霸路上的垫脚石! 做 Java 开发,没有人敢小觑 Spring Boot 的重要性,现在出去面 ...
- 15 道 Spring Boot 高频面试题,看完直接当面霸【入门实用】
前言 本文转自松哥(网名:江南一点雨)的一篇实用入门文章,写的挺好的,希望对各位有所帮助. 什么是面霸?就是在面试中,神挡杀神佛挡杀佛,见招拆招,面到面试官自惭形秽自叹不如!松哥希望本文能成为你面霸路 ...
随机推荐
- spark SQL (二) 聚合
聚合内置功能DataFrames提供共同聚合,例如count(),countDistinct(),avg(),max(),min(),等.虽然这些功能是专为DataFrames,spark SQL还拥 ...
- sqlite安装与封装后编译
========================安装sqlite=================官网下载安装包*.tar.gz格式./configure --prefix=/usr/server/s ...
- TypeScript 入门教程学习笔记
TypeScript 入门教程学习笔记 1. 数据类型定义 类型 实例 说明 Number let num: number = 1; 基本类型 String let myName: string = ...
- ASP.NET Core默认容器实现Controller的属性注入
仅针对Controller的属性注入: 使用默认容器,不依赖第三方库: 故事背景 闲来无事给项目做优化,发现大多数Controller里面都会用到Logger和AutoMapper,每个Contr ...
- C++ Socket 入门
Socket 入门 前置知识 :计算机网络基础(TCP/IP四层模型) Socket 原意是"插座",在计算机通信领域被翻译为"套接字",以\(\{IP:Por ...
- Codeforces Global Round 11 A. Avoiding Zero(前缀和)
题目链接:https://codeforces.com/contest/1427/problem/A 题意 将 \(n\) 个数重新排列使得不存在为 \(0\) 的前缀和. 题解 计算正.负前缀和,如 ...
- P3376 [模板] 网络最大流
https://www.luogu.org/blog/ONE-PIECE/wang-lao-liu-jiang-xie-zhi-dinic EK 292ms #include <bits/std ...
- HDU-6290 奢侈的旅行 (Dijkstra+堆优化)
高玩小Q不仅喜欢玩寻宝游戏,还喜欢一款升级养成类游戏.在这个游戏的世界地图中一共有nn个城镇,编号依次为11到nn.这些城镇之间有mm条单向道路,第ii 条单项道路包含四个参数ui,vi,ai,biu ...
- 牛客编程巅峰赛S1第11场 - 黄金&钻石 A.牛牛的01游戏 (模拟栈)
题意:有一个\(01\)串,两个相邻的\(0\)可以变成一个\(1\),两个相邻的\(1\)可以直接消除,问操作后的字符串. 题解:数组模拟栈直接撸,上代码吧. 代码: class Solution ...
- 找工作面试题记录与参考资料(Golang/C++/计算机网络/操作系统/算法等)
记录下去年(2020年)找工作的面试题及参考资料. C++ 智能指针的实现原理 多态的实现原理[2] C++11/14/17新特性[3] 手写memcpy和memmove[4] 介绍下boost库 计 ...